Puzzle 5: 브로드캐스트
개요
1D TileTensor a와 b를 브로드캐스트로 더해 2D TileTensor output에 저장하는
커널을 구현해 보세요.
병렬 프로그래밍에서 브로드캐스트(broadcasting) 는 요소별 연산을 할 때 저차원 배열을 고차원 배열의 형상에 맞게 자동으로 확장하는 것을 말합니다. 실제로 메모리에 데이터를 복제하지 않고, 추가 차원에 걸쳐 값을 논리적으로 반복하는 방식입니다. 예를 들어, 2D 행렬의 각 행(또는 열)에 1D 벡터를 더할 때 벡터를 여러 번 복사하지 않아도 같은 요소가 자동으로 반복 적용됩니다.
참고: 스레드 수가 행렬의 위치 수보다 많습니다.
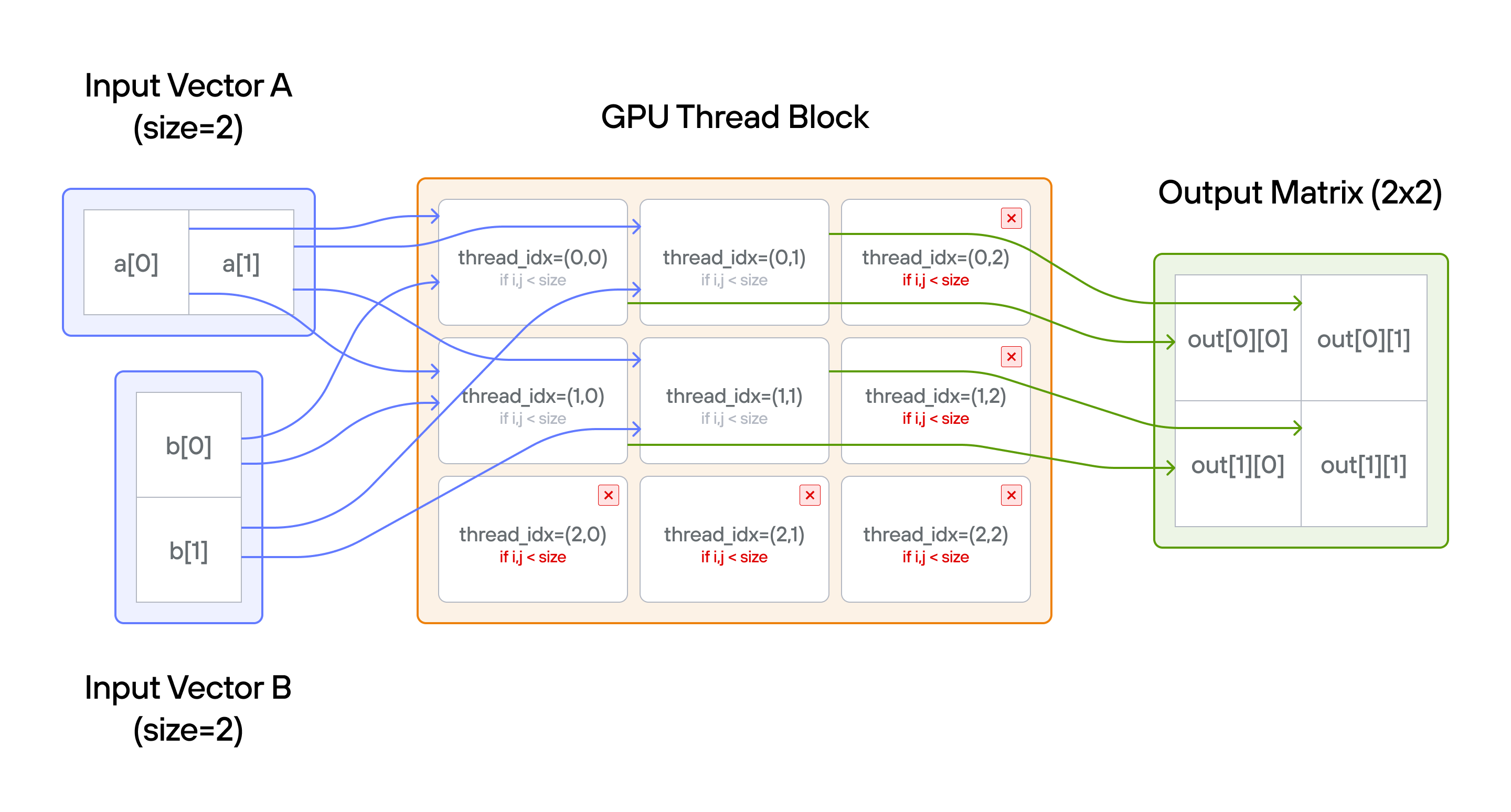
핵심 개념
이 퍼즐에서 배울 내용:
TileTensor로 서로 다른 차원에 1D 벡터 브로드캐스트하기- 2D 스레드 인덱스로 GPU 스레드를 2D 출력 행렬에 매핑하기
- 혼합 차원 연산을 위해 서로 다른 텐서 크기 다루기
- 브로드캐스트 패턴에서 경계 조건 처리하기
핵심은 TileTensor가 서로 다른 텐서 크기 \((1, n)\)와 \((n, 1)\)을
\((n,n)\)으로 자연스럽게 브로드캐스트할 수 있다는 점입니다. 그러면서도 경계
검사는 여전히 필요합니다.
- 텐서 크기: 입력 벡터의 크기는 \((1, n)\)과 \((n, 1)\)
- 브로드캐스트:
a의 각 원소가b의 각 원소와 결합되어 두 차원이 확장된 \((n,n)\) 출력 생성 - 접근 패턴:
a[0, col]은 행을 따라 수평으로 브로드캐스트되고,b[row, 0]은 열을 따라 수직으로 브로드캐스트됨 - 가드 조건: 출력 크기에 대한 경계 검사는 여전히 필요
- 스레드 범위: 텐서 원소 \((2 \times 2)\)보다 스레드 \((3 \times 3)\)가 많음
완성할 코드
comptime SIZE = 2
comptime BLOCKS_PER_GRID = 1
comptime THREADS_PER_BLOCK = (3, 3)
comptime dtype = DType.float32
comptime out_layout = row_major[SIZE, SIZE]()
comptime a_layout = row_major[1, SIZE]()
comptime b_layout = row_major[SIZE, 1]()
comptime OutLayout = type_of(out_layout)
comptime ALayout = type_of(a_layout)
comptime BLayout = type_of(b_layout)
def broadcast_add(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, ALayout, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, BLayout, ImmutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
# FILL ME IN (roughly 2 lines)
전체 코드 보기: problems/p05/p05.mojo
팁
- 2D 인덱스 가져오기:
row = thread_idx.y,col = thread_idx.x - 가드 추가:
if row < size and col < size - 가드 내부: TileTensor로
a와b값을 어떻게 브로드캐스트할지 생각해 보세요
코드 실행
솔루션을 테스트하려면 터미널에서 다음 명령어를 실행하세요:
pixi run p05
pixi run -e amd p05
pixi run -e apple p05
uv run poe p05
퍼즐을 아직 풀지 않았다면 출력이 다음과 같이 나타납니다:
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([1.0, 2.0, 11.0, 12.0])
솔루션
def broadcast_add(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, ALayout, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, BLayout, ImmutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
if row < size and col < size:
output[row, col] = a[0, col] + b[row, 0]
TileTensor 브로드캐스트와 GPU 스레드 매핑의 핵심 개념을 보여주는 솔루션입니다:
-
스레드에서 행렬로 매핑
thread_idx.y로 행,thread_idx.x로 열에 접근- 자연스러운 2D 인덱싱이 출력 행렬 구조와 일치
- 초과 스레드(3×3 그리드)는 경계 검사로 처리
-
브로드캐스트 작동 방식
- 입력
a의 크기는(1,n):a[0,col]이 행을 가로질러 브로드캐스트 - 입력
b의 크기는(n,1):b[row,0]이 열을 가로질러 브로드캐스트 - 출력의 크기는
(n,n): 각 원소는 해당 브로드캐스트 값들의 합
[ a0 a1 ] + [ b0 ] = [ a0+b0 a1+b0 ] [ b1 ] [ a0+b1 a1+b1 ] - 입력
-
경계 검사
- 가드 조건
row < size and col < size로 범위 초과 접근 방지 - 행렬 범위와 초과 스레드를 효율적으로 처리
- 브로드캐스트 덕분에
a와b에 대한 별도 검사 불필요
- 가드 조건
이 패턴은 이후 퍼즐에서 다룰 더 복잡한 텐서 연산의 기초가 됩니다.