Puzzle 8: 공유 메모리
개요
1D TileTensor a의 각 위치에 10을 더해 1D TileTensor output에 저장하는 커널을
구현해 보세요.
공유 메모리(shared memory) 는 같은 블록 안의 모든 스레드가 접근할 수 있는, 칩에 내장된 빠른 저장소입니다. 모든 블록이 접근할 수 있지만 느린 전역 메모리와 달리, 공유 메모리의 지연 시간은 CPU의 레지스터 캐시 수준입니다. 각 블록은 고유한 공유 메모리 영역을 가지므로, 한 블록의 스레드는 다른 블록의 공유 메모리를 볼 수 없습니다. 여러 스레드가 같은 공유 메모리 위치를 읽고 쓸 수 있기 때문에, 한 스레드가 다른 스레드의 쓰기가 끝나기 전에 값을 읽는 상황을 막으려면 barrier()를 통한 조율이 필요합니다.
참고: 블록당 스레드 수가 a의 크기보다 작습니다.
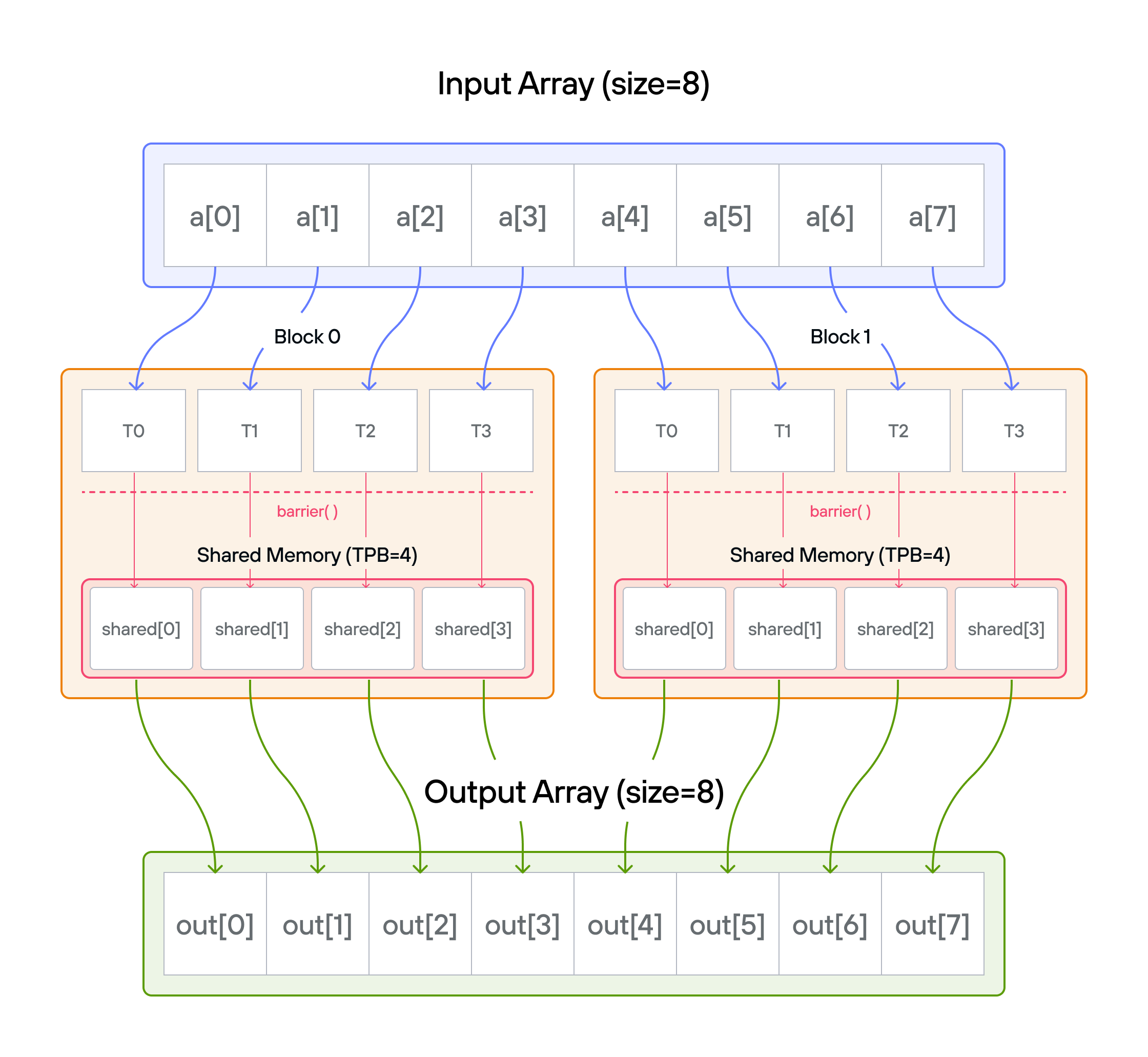
핵심 개념
이 퍼즐에서 배울 내용:
- address_space를 활용한 TileTensor의 공유 메모리 기능
- 공유 메모리를 사용할 때의 스레드 동기화
- TileTensor로 블록 로컬 데이터 관리하기
핵심은 TileTensor가 블록 로컬 저장소의 성능은 그대로 유지하면서 공유 메모리 관리를 얼마나 간소화하는지 이해하는 것입니다.
구성
- 배열 크기:
SIZE = 8원소 - 블록당 스레드 수:
TPB = 4 - 블록 수: 2
- 공유 메모리: 블록당
TPB개 원소
경고: 각 블록에는 해당 블록의 스레드들이 읽고 쓸 수 있는 공유 메모리의 양이 _상수_로 고정되어 있습니다. 이 값은 파이썬 리터럴 상수여야 하며 변수를 사용할 수 없습니다. 공유 메모리에 쓴 후에는 barrier를 호출해 스레드들이 교차하지 않도록 해야 합니다.
학습 참고: 이 퍼즐에서는 각 스레드가 자신의 공유 메모리 위치에만 접근하므로
barrier()가 엄밀히 필요하지 않습니다. 하지만 더 복잡한 상황에서 필요한 올바른
동기화 패턴을 익히기 위해 포함되어 있습니다.
완성할 코드
comptime TPB = 4
comptime SIZE = 8
comptime BLOCKS_PER_GRID = (2, 1)
comptime THREADS_PER_BLOCK = (TPB, 1)
comptime dtype = DType.float32
comptime layout = row_major[SIZE]()
comptime LayoutType = type_of(layout)
def add_10_shared_tile_tensor(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
# Allocate shared memory using stack_allocation
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
if global_i < size:
shared[local_i] = a[global_i]
# Note: barrier is not strictly needed here since each thread only accesses
# its own shared memory location. However, it's included to teach proper
# shared memory synchronization patterns for more complex scenarios where
# threads need to coordinate access to shared data.
barrier()
# FILL ME IN (roughly 2 lines)
전체 코드 보기: problems/p08/p08.mojo
팁
- address_space 파라미터로 TileTensor 공유 메모리 생성
- 자연스러운 인덱싱으로 데이터 로드:
shared[local_i] = a[global_i] barrier()로 동기화 (학습용 - 여기서는 엄밀히 필요하지 않음)- 공유 메모리 인덱스로 데이터 처리
- 범위를 벗어난 접근을 방지하는 가드
코드 실행
솔루션을 테스트하려면 터미널에서 다음 명령어를 실행하세요:
pixi run p08
pixi run -e amd p08
pixi run -e apple p08
uv run poe p08
퍼즐을 아직 풀지 않았다면 출력이 다음과 같이 나타납니다:
out: HostBuffer([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([11.0, 11.0, 11.0, 11.0, 11.0, 11.0, 11.0, 11.0])
솔루션
def add_10_shared_tile_tensor(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
# Allocate shared memory using stack_allocation
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
if global_i < size:
shared[local_i] = a[global_i]
# Note: barrier is not strictly needed here since each thread only accesses
# its own shared memory location. However, it's included to teach proper
# shared memory synchronization patterns for more complex scenarios where
# threads need to coordinate access to shared data.
barrier()
if global_i < size:
output[global_i] = shared[local_i] + 10
TileTensor가 성능을 유지하면서 공유 메모리 사용을 얼마나 간소화하는지 보여주는 솔루션입니다:
-
TileTensor를 사용한 메모리 계층 구조
-
전역 텐서:
a와output(느림, 모든 블록에서 보임) -
공유 텐서:
shared(빠름, 스레드 블록 로컬) -
블록당 4개 스레드로 8개 원소를 처리하는 예시:
전역 텐서 a: [1 1 1 1 | 1 1 1 1] # 입력: 모두 1 Block (0): Block (1): shared[0..3] shared[0..3] [1 1 1 1] [1 1 1 1]
-
-
스레드 조율
-
로드 단계 (자연스러운 인덱싱 사용):
Thread 0: shared[0] = a[0]=1 Thread 2: shared[2] = a[2]=1 Thread 1: shared[1] = a[1]=1 Thread 3: shared[3] = a[3]=1 barrier() ↓ ↓ ↓ ↓ # 모든 로드 완료 대기 -
처리 단계: 각 스레드가 자신의 공유 텐서 값에 10을 더함
-
결과:
output[global_i] = shared[local_i] + 10 = 11
-
참고: 이 경우에는 각 스레드가 자신의 공유 메모리 위치(shared[local_i])에만
쓰고 읽으므로 barrier()가 엄밀히 필요하지 않습니다. 하지만 스레드들이 서로의
데이터에 접근하는 상황에서 필수적인 동기화 패턴을 익히기 위해 포함되어 있습니다.
-
TileTensor의 장점
-
공유 메모리 할당:
# address_space를 사용한 깔끔한 TileTensor API shared = stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB]()) -
전역과 공유 메모리 모두 자연스러운 인덱싱:
Block 0 출력: [11 11 11 11] Block 1 출력: [11 11 11 11] -
내장된 레이아웃 관리와 타입 안전성
-
-
메모리 접근 패턴
- 로드: 전역 텐서 → 공유 텐서 (최적화됨)
- 동기화: 원시 메모리 버전과 동일한
barrier()필요 - 처리: 공유 메모리 값에 10 더하기
- 저장: 결과(11)를 전역 텐서에 쓰기
이 패턴은 TileTensor가 공유 메모리의 성능 이점을 유지하면서 더 편리한 API와 내장 기능을 제공하는 방법을 보여줍니다.