Puzzle 15: 축 합계
개요
2D 행렬 a의 각 행에 대해 합계를 계산하여 TileTensor를 사용해 output에
저장하는 커널을 구현하세요.
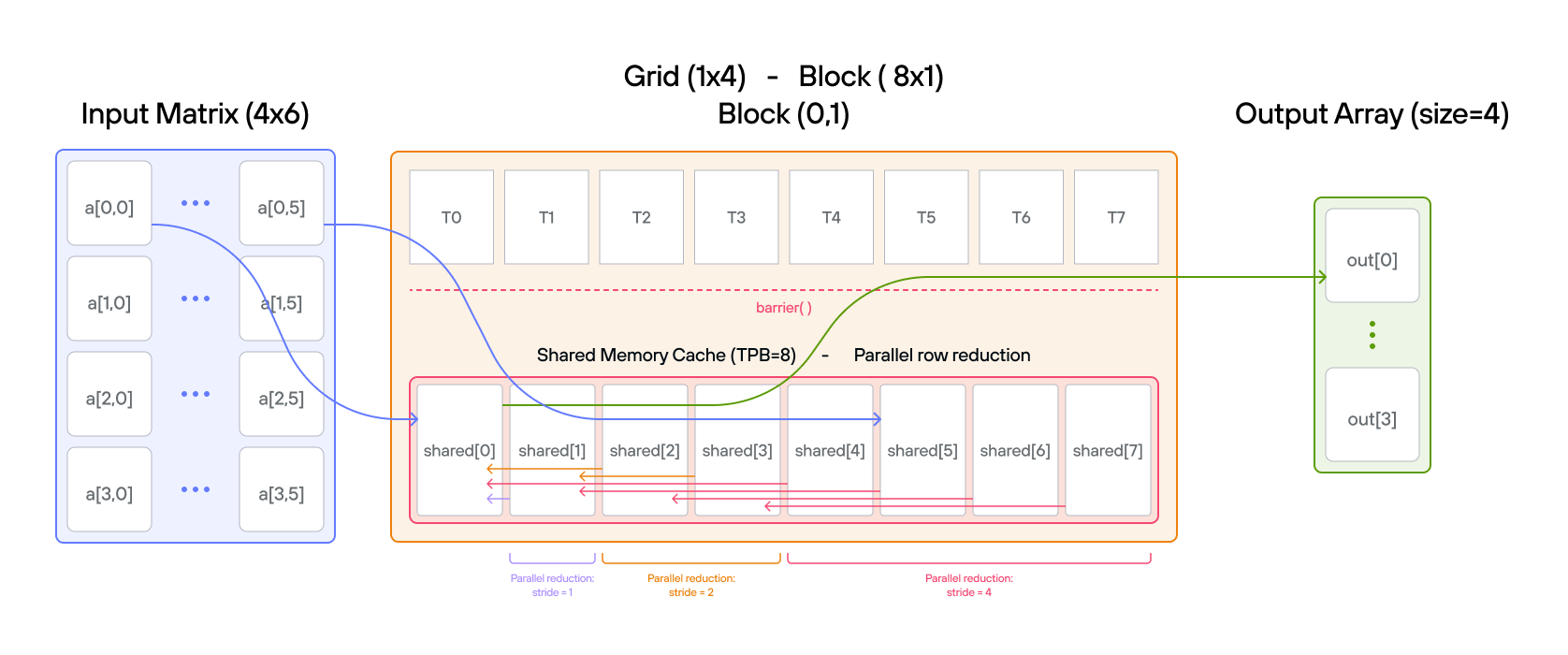
핵심 개념
이 퍼즐에서 다루는 내용:
- TileTensor를 활용한 행렬 차원 방향의 병렬 리덕션
- 블록 좌표를 이용한 데이터 분할
- 효율적인 공유 메모리 리덕션 패턴
- 다차원 텐서 레이아웃 다루기
핵심은 스레드 블록을 행렬의 행에 매핑하고, TileTensor의 차원별 인덱싱을 활용하면서 각 블록 내에서 효율적인 병렬 리덕션을 수행하는 방법을 이해하는 것입니다.
구성
- 행렬 크기: \(\text{BATCH} \times \text{SIZE} = 4 \times 6\)
- 블록당 스레드 수: \(\text{TPB} = 8\)
- 그리드 크기: \(1 \times \text{BATCH}\)
- 공유 메모리: 블록당 \(\text{TPB}\)개 원소
- 입력 레이아웃:
row_major[BATCH, SIZE]() - 출력 레이아웃:
row_major[BATCH, 1]()
행렬 시각화:
Row 0: [0, 1, 2, 3, 4, 5] → Block(0,0)
Row 1: [6, 7, 8, 9, 10, 11] → Block(0,1)
Row 2: [12, 13, 14, 15, 16, 17] → Block(0,2)
Row 3: [18, 19, 20, 21, 22, 23] → Block(0,3)
완성할 코드
def axis_sum(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
size: Int,
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
var batch = block_idx.y
# FILL ME IN (roughly 15 lines)
전체 파일 보기: problems/p15/p15.mojo
팁
batch = block_idx.y로 행 선택- 원소 로드:
cache[local_i] = a[batch, local_i] - 스트라이드를 절반씩 줄이며 병렬 리덕션 수행
- 스레드 0이 최종 합계를
output[batch]에 기록
코드 실행
솔루션을 테스트하려면 터미널에서 다음 명령어를 실행하세요:
pixi run p15
pixi run -e amd p15
pixi run -e apple p15
uv run poe p15
퍼즐을 아직 풀지 않았다면 출력은 다음과 같습니다:
out: DeviceBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([15.0, 51.0, 87.0, 123.0])
솔루션
def axis_sum(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
size: Int,
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
var batch = block_idx.y
var cache = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
# Visualize:
# Block(0,0): [T0,T1,T2,T3,T4,T5,T6,T7] -> Row 0: [0,1,2,3,4,5]
# Block(0,1): [T0,T1,T2,T3,T4,T5,T6,T7] -> Row 1: [6,7,8,9,10,11]
# Block(0,2): [T0,T1,T2,T3,T4,T5,T6,T7] -> Row 2: [12,13,14,15,16,17]
# Block(0,3): [T0,T1,T2,T3,T4,T5,T6,T7] -> Row 3: [18,19,20,21,22,23]
# each row is handled by each block bc we have grid_dim=(1, BATCH)
if local_i < size:
cache[local_i] = a[batch, local_i]
else:
# Add zero-initialize padding elements for later reduction
cache[local_i] = 0
barrier()
# do reduction sum per each block
var stride = TPB // 2
while stride > 0:
# Read phase: all threads read the values they need first to avoid race conditions
var temp_val: output.ElementType = 0
if local_i < stride:
temp_val = cache[local_i + stride]
barrier()
# Write phase: all threads safely write their computed values
if local_i < stride:
cache[local_i] += temp_val
barrier()
stride //= 2
# writing with local thread = 0 that has the sum for each batch
if local_i == 0:
output[batch, 0] = cache[0]
TileTensor를 활용해 2D 행렬의 행 방향 합계를 병렬로 구하는 리덕션 구현입니다. 단계별로 살펴보겠습니다:
행렬 레이아웃과 블록 매핑
Input Matrix (4×6) with TileTensor: Block Assignment:
[[ a[0,0] a[0,1] a[0,2] a[0,3] a[0,4] a[0,5] ] → Block(0,0)
[ a[1,0] a[1,1] a[1,2] a[1,3] a[1,4] a[1,5] ] → Block(0,1)
[ a[2,0] a[2,1] a[2,2] a[2,3] a[2,4] a[2,5] ] → Block(0,2)
[ a[3,0] a[3,1] a[3,2] a[3,3] a[3,4] a[3,5] ] → Block(0,3)
병렬 리덕션 과정
-
초기 데이터 로딩:
Block(0,0): cache = [a[0,0] a[0,1] a[0,2] a[0,3] a[0,4] a[0,5] * *] // * = 패딩 Block(0,1): cache = [a[1,0] a[1,1] a[1,2] a[1,3] a[1,4] a[1,5] * *] Block(0,2): cache = [a[2,0] a[2,1] a[2,2] a[2,3] a[2,4] a[2,5] * *] Block(0,3): cache = [a[3,0] a[3,1] a[3,2] a[3,3] a[3,4] a[3,5] * *] -
리덕션 단계 (Block 0,0 기준):
Initial: [0 1 2 3 4 5 * *] Stride 4: [4 5 6 7 4 5 * *] Stride 2: [10 12 6 7 4 5 * *] Stride 1: [15 12 6 7 4 5 * *]
주요 구현 특징
-
레이아웃 구성:
- 입력: 행 우선(row-major) 레이아웃 (BATCH × SIZE)
- 출력: 행 우선 레이아웃 (BATCH × 1)
- 각 블록이 하나의 행 전체를 처리
-
메모리 접근 패턴:
- 입력에 TileTensor 2D 인덱싱 사용:
a[batch, local_i] - 효율적인 리덕션을 위한 공유 메모리 활용
- 출력에 TileTensor 2D 인덱싱 사용:
output[batch, 0]
- 입력에 TileTensor 2D 인덱싱 사용:
-
병렬 리덕션 로직:
stride = TPB // 2 while stride > 0: if local_i < stride: cache[local_i] += cache[local_i + stride] barrier() stride //= 2참고: 이 구현에서는 같은 반복 내에서 스레드들이 공유 메모리를 동시에 읽고 쓰기 때문에 잠재적인 경쟁 상태가 발생할 수 있습니다. 더 안전한 방법은 읽기와 쓰기 단계를 분리하는 것입니다:
stride = TPB // 2 while stride > 0: var temp_val: output.element_type = 0 if local_i < stride: temp_val = cache[local_i + stride] # 읽기 단계 barrier() if local_i < stride: cache[local_i] += temp_val # 쓰기 단계 barrier() stride //= 2 -
출력 기록:
if local_i == 0: output[batch, 0] = cache[0] --> 배치당 결과 하나
성능 최적화
-
메모리 효율성:
- TileTensor를 통한 병합 메모리 접근
- 빠른 리덕션을 위한 공유 메모리 활용
- 행 결과당 한 번의 쓰기
-
스레드 활용:
- 행 간 완벽한 부하 균형
- 주요 연산에서 스레드 분기 없음
- 효율적인 병렬 리덕션 패턴
-
동기화:
- 최소한의 배리어 (리덕션 중에만 사용)
- 행 간 독립적인 처리
- 블록 간 통신 불필요
- 경쟁 상태 고려사항: 현재 구현에서는 병렬 리덕션 중에 읽기-쓰기 충돌이 발생할 수 있으며, 명시적인 읽기-쓰기 단계 분리로 해결할 수 있습니다
복잡도 분석
- 시간: 행당 \(O(\log n)\), n은 행의 길이
- 공간: 블록당 \(O(TPB)\) 공유 메모리
- 전체 병렬 시간: 스레드가 충분할 때 \(O(\log n)\)