Puzzle 12: 내적
개요
1D TileTensor a와 1D TileTensor b의 내적을 계산하여 1D TileTensor
output(단일 값)에 저장하는 커널을 구현하세요. 내적은 크기가 같은 두 벡터에서
대응하는 원소끼리 곱한 뒤, 그 결과를 모두 더해 하나의 숫자(스칼라)를 구하는
연산입니다.
예를 들어, 두 벡터가 다음과 같을 때:
\[a = [a_{1}, a_{2}, …, a_{n}] \] \[b = [b_{1}, b_{2}, …, b_{n}] \]
내적은 이렇게 구합니다: \[a \cdot b = a_{1}b_{1} + a_{2}b_{2} + … + a_{n}b_{n}\]
참고: 각 위치마다 스레드 1개가 있습니다. 스레드당 전역 읽기 2회, 블록당 전역 쓰기 1회만 필요합니다.
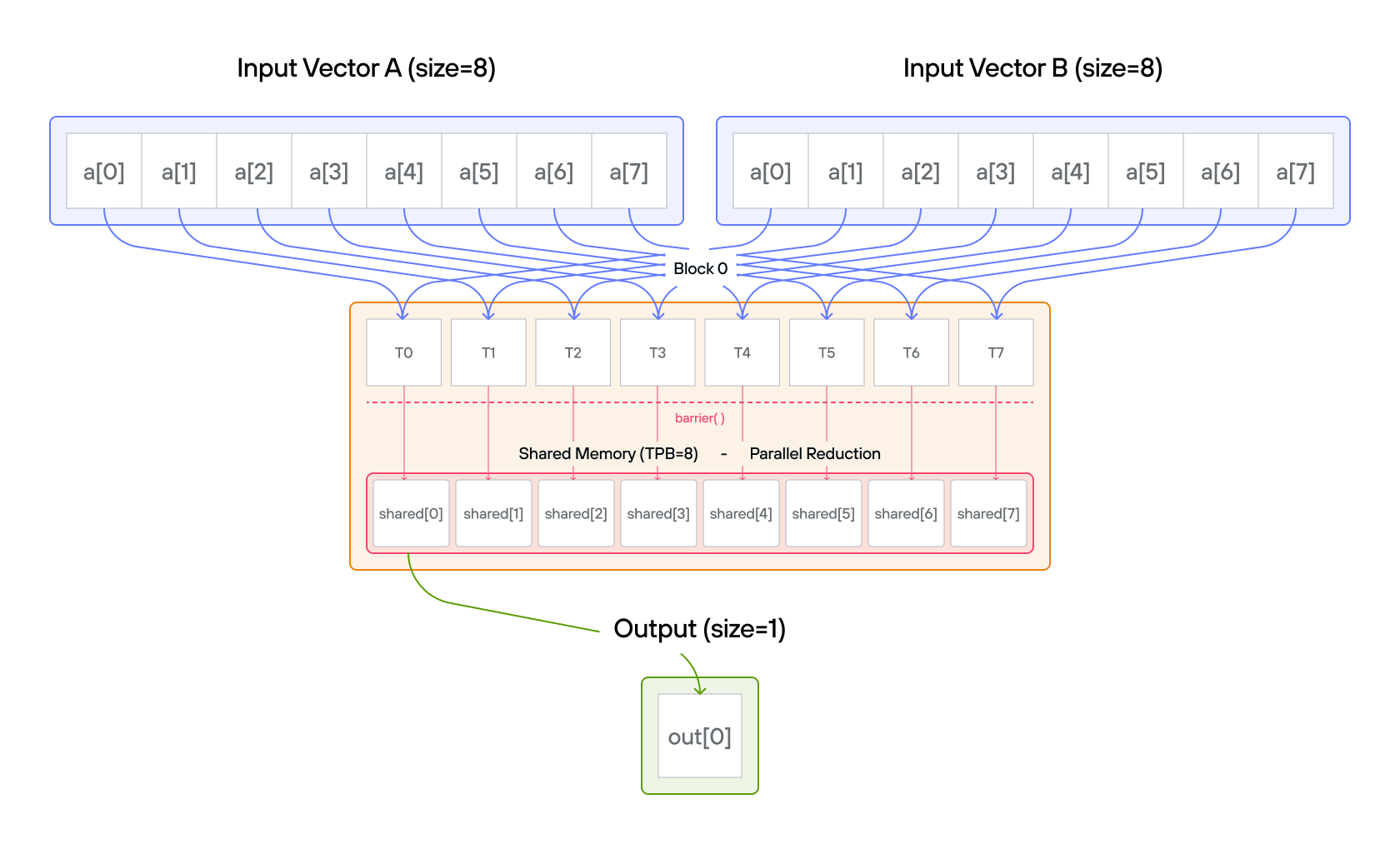
핵심 개념
병렬 리덕션(parallel reduction) 은 이항 연산(여기서는 덧셈)을 사용해 \(n\) 개의 값을 하나로 합치는 알고리즘으로, \(O(n)\) 번의 순차 처리 대신 \(O(\log n)\) 단계 만에 끝납니다. 각 단계에서 활성 스레드의 절반이 각자 하나의 값을 다른 값에 더하면서 남은 부분합의 개수를 절반으로 줄입니다. \(\log_2 n\) 단계가 지나면 스레드 0이 최종 합을 가지게 됩니다. 이 트리 모양의 계산은 한 스레드가 부분적으로만 갱신된 값을 읽지 않도록 단계 사이에 barrier()를 둬야 합니다.
이 퍼즐에서 배울 내용:
- Puzzle 8, Puzzle 11에서 이어지는 TileTensor 기반 병렬 리덕션
address_space를 활용한 공유 메모리 관리- 여러 스레드가 협력해 하나의 결과를 만들어가는 과정
- 레이아웃을 인식하는 텐서 연산
핵심은 TileTensor가 메모리 관리를 간소화하면서도, 병렬 리덕션의 효율은 그대로 살리는 방식을 이해하는 것입니다.
구성
- 벡터 크기:
SIZE = 8 - 블록당 스레드 수:
TPB = 8 - 블록 수: 1
- 출력 크기: 1
- 공유 메모리:
TPB개
참고:
- TileTensor 할당:
stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB]())사용 - 요소 접근: 경계 검사가 자동으로 따라오는 자연스러운 인덱싱
- 레이아웃 처리: 입력용과 출력용 레이아웃을 따로 구성
- 스레드 조율: 동일한 동기화 패턴으로
barrier()사용
완성할 코드
comptime TPB = 8
comptime SIZE = 8
comptime BLOCKS_PER_GRID = (1, 1)
comptime THREADS_PER_BLOCK = (TPB, 1)
comptime dtype = DType.float32
comptime layout = row_major[SIZE]()
comptime out_layout = row_major[1]()
comptime LayoutType = type_of(layout)
comptime OutLayout = type_of(out_layout)
def dot_product(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
# FILL ME IN (roughly 13 lines)
...
전체 파일 보기: problems/p12/p12.mojo
팁
- TileTensor와
address_space로 공유 메모리 생성 shared[local_i]에a[global_i] * b[global_i]를 저장barrier()와 함께 병렬 리덕션 패턴 적용- 스레드 0이 최종 결과를
output[0]에 기록
코드 실행
솔루션을 테스트하려면 터미널에서 다음 명령어를 실행하세요:
pixi run p12
pixi run -e amd p12
pixi run -e apple p12
uv run poe p12
퍼즐을 아직 풀지 않았다면 출력은 다음과 같습니다:
out: HostBuffer([0.0])
expected: HostBuffer([140.0])
솔루션
def dot_product(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Compute element-wise multiplication into shared memory
if global_i < size:
shared[local_i] = a[global_i] * b[global_i]
# Synchronize threads within block
barrier()
# Parallel reduction in shared memory
var stride = TPB // 2
while stride > 0:
if local_i < stride:
shared[local_i] += shared[local_i + stride]
barrier()
stride //= 2
# Only thread 0 writes the final result
if local_i == 0:
output[0] = shared[0]
TileTensor를 활용한 병렬 리덕션으로 내적을 계산하는 솔루션입니다. 단계별로 살펴보겠습니다:
1단계: 요소별 곱셈
각 스레드가 직관적인 인덱싱으로 곱셈 연산을 하나씩 처리합니다:
shared[local_i] = a[global_i] * b[global_i]
2단계: 병렬 리덕션
레이아웃을 인식하는 트리 기반 리덕션입니다:
초기값: [0*0 1*1 2*2 3*3 4*4 5*5 6*6 7*7]
= [0 1 4 9 16 25 36 49]
Step 1: [0+16 1+25 4+36 9+49 16 25 36 49]
= [16 26 40 58 16 25 36 49]
Step 2: [16+40 26+58 40 58 16 25 36 49]
= [56 84 40 58 16 25 36 49]
Step 3: [56+84 84 40 58 16 25 36 49]
= [140 84 40 58 16 25 36 49]
구현의 핵심 특징
-
메모리 관리:
address_space파라미터 하나로 공유 메모리를 깔끔하게 할당- 타입 안전한 연산이 보장되고
- 경계 검사가 자동으로 따라오며
- 인덱싱도 레이아웃을 인식
-
스레드 동기화:
- 초기 곱셈이 끝나면
barrier() - 리덕션 단계 사이마다
barrier() - 스레드 간 안전한 조율 보장
- 초기 곱셈이 끝나면
-
리덕션 로직:
stride = TPB // 2 while stride > 0: if local_i < stride: shared[local_i] += shared[local_i + stride] barrier() stride //= 2 -
성능상 이점:
- \(O(\log n)\) 시간 복잡도
- 병합 메모리 접근
- 최소한의 스레드 분기
- 공유 메모리의 효율적 활용
TileTensor 버전은 병렬 리덕션의 효율은 그대로 유지하면서, 여기에 더해:
- 타입 안전성이 한층 강화되고
- 메모리 관리가 더 깔끔해지며
- 레이아웃을 자동으로 인식하고
- 인덱싱 문법도 자연스러워집니다
배리어 동기화의 중요성
리덕션 단계 사이의 barrier()는 정확한 결과를 위해 반드시 필요합니다. 그 이유를
살펴보겠습니다:
barrier()가 없으면 경쟁 상태가 발생합니다:
초기 공유 메모리: [0 1 4 9 16 25 36 49]
Step 1 (stride = 4):
Thread 0 읽기: shared[0] = 0, shared[4] = 16
Thread 1 읽기: shared[1] = 1, shared[5] = 25
Thread 2 읽기: shared[2] = 4, shared[6] = 36
Thread 3 읽기: shared[3] = 9, shared[7] = 49
barrier 없이:
- Thread 0 쓰기: shared[0] = 0 + 16 = 16
- Thread 1이 Thread 0보다 먼저 다음 단계(stride = 2)로 넘어가서
16이 아닌 이전 값 shared[0] = 0을 읽어버립니다!
barrier()가 있으면:
Step 1 (stride = 4):
모든 스레드가 합을 기록:
[16 26 40 58 16 25 36 49]
barrier()가 모든 스레드에게 이 값들이 보이도록 보장
Step 2 (stride = 2):
이제 업데이트된 값을 안전하게 읽을 수 있음:
Thread 0: shared[0] = 16 + 40 = 56
Thread 1: shared[1] = 26 + 58 = 84
barrier()는 다음을 보장합니다:
- 현재 단계의 모든 쓰기가 끝난 뒤에야 다음으로 넘어감
- 모든 스레드가 최신 값을 볼 수 있음
- 어떤 스레드도 앞서 나가지 않음
- 공유 메모리가 항상 일관된 상태를 유지
이런 동기화 지점이 없으면:
- 경쟁 상태가 발생하고
- 스레드가 이미 지난 값을 읽게 되며
- 실행할 때마다 결과가 달라지고
- 최종 합계가 틀어질 수 있습니다