Puzzle 11: Pooling
Overview
Implement a kernel that compute the running sum of the last 3 positions of 1D
TileTensor a and stores it in 1D TileTensor output.
Pooling is an operation that condenses a region of values into a single summary value — for example, their sum, maximum, or average. A sliding window applies this condensation repeatedly by moving a fixed-size window one step at a time across the input, producing one output value per window position. Here the window is 3 elements wide and the summary function is a sum, so each output element equals the sum of the current element and the two preceding it (with special cases at the boundaries where fewer than 3 elements are available).
Note: You have 1 thread per position. You only need 1 global read and 1 global write per thread.
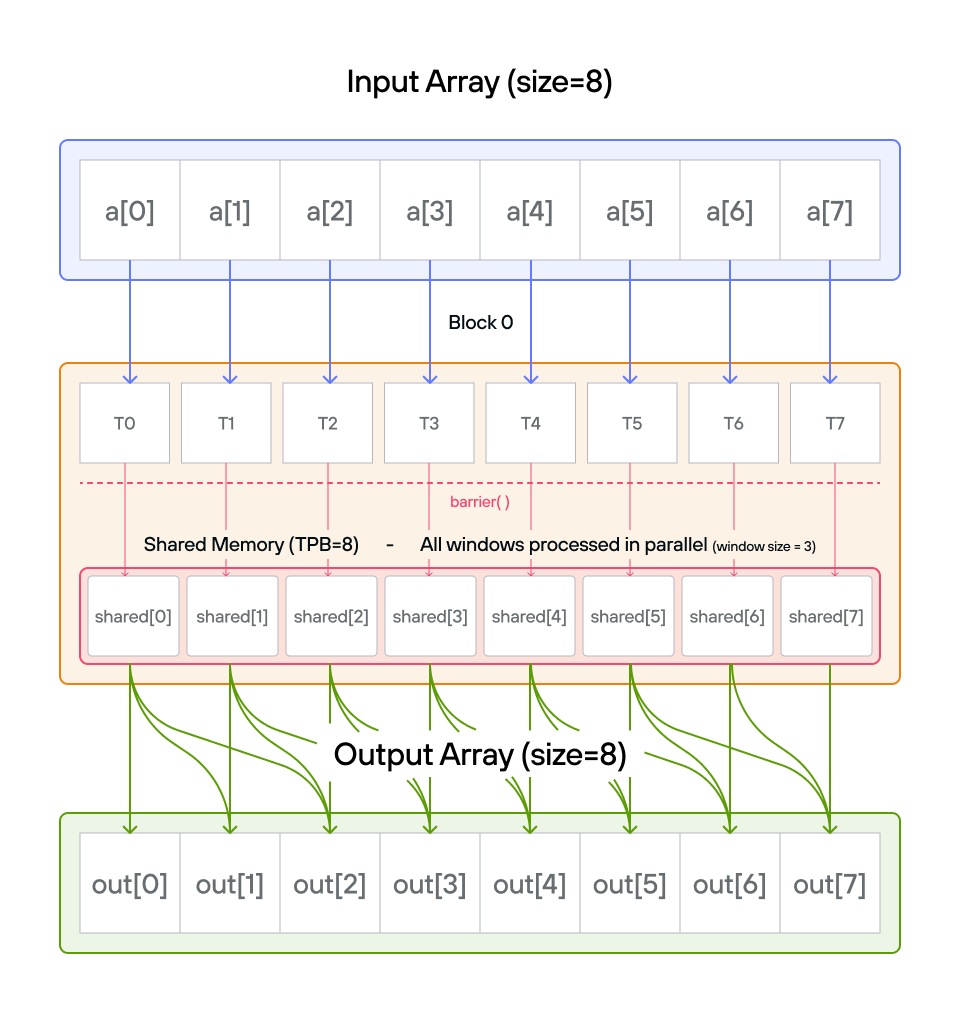
Key concepts
In this puzzle, you’ll learn about:
- Using TileTensor for sliding window operations
- Managing shared memory with TileTensor address_space that we saw in puzzle 8
- Efficient neighbor access patterns
- Boundary condition handling
The key insight is how TileTensor simplifies shared memory management while maintaining efficient window-based operations.
Configuration
- Array size:
SIZE = 8elements - Threads per block:
TPB = 8 - Window size: 3 elements
- Shared memory:
TPBelements
Notes:
- TileTensor allocation: Use
stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB]()) - Window access: Natural indexing for 3-element windows
- Edge handling: Special cases for first two positions
- Memory pattern: One shared memory load per thread
Code to complete
comptime TPB = 8
comptime SIZE = 8
comptime BLOCKS_PER_GRID = (1, 1)
comptime THREADS_PER_BLOCK = (TPB, 1)
comptime dtype = DType.float32
comptime layout = row_major[SIZE]()
comptime LayoutType = type_of(layout)
def pooling(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
# Allocate shared memory using stack_allocation
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# FIX ME IN (roughly 10 lines)
View full file: problems/p11/p11.mojo
Tips
- Create shared memory with TileTensor using address_space
- Load data with natural indexing:
shared[local_i] = a[global_i] - Handle special cases for first two elements
- Use shared memory for window operations
- Guard against out-of-bounds access
Running the code
To test your solution, run the following command in your terminal:
pixi run p11
pixi run -e amd p11
pixi run -e apple p11
uv run poe p11
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([0.0, 1.0, 3.0, 6.0, 9.0, 12.0, 15.0, 18.0])
Solution
def pooling(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
# Allocate shared memory using stack_allocation
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Load data into shared memory
if global_i < size:
shared[local_i] = a[global_i]
# Synchronize threads within block
barrier()
# Handle first two special cases
if global_i == 0:
output[0] = shared[0]
elif global_i == 1:
output[1] = shared[0] + shared[1]
# Handle general case
elif 1 < global_i < size:
output[global_i] = (
shared[local_i - 2] + shared[local_i - 1] + shared[local_i]
)
The solution implements a sliding window sum using TileTensor with these key steps:
-
Shared memory setup
-
TileTensor creates block-local storage with address_space:
shared = stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB]()) -
Each thread loads one element:
Input array: [0.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0] Block shared: [0.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0] -
barrier()ensures all data is loaded
-
-
Boundary cases
-
Position 0: Single element
output[0] = shared[0] = 0.0 -
Position 1: Sum of first two elements
output[1] = shared[0] + shared[1] = 0.0 + 1.0 = 1.0
-
-
Main window operation
-
For positions 2 and beyond:
Position 2: shared[0] + shared[1] + shared[2] = 0.0 + 1.0 + 2.0 = 3.0 Position 3: shared[1] + shared[2] + shared[3] = 1.0 + 2.0 + 3.0 = 6.0 Position 4: shared[2] + shared[3] + shared[4] = 2.0 + 3.0 + 4.0 = 9.0 ... -
Natural indexing with TileTensor:
# Sliding window of 3 elements window_sum = shared[i-2] + shared[i-1] + shared[i]
-
Single-block assumption: This solution is correct because the puzzle is configured with
BLOCKS_PER_GRID = (1, 1)andSIZE == TPB = 8, guaranteeing every thread belongs to the same block soglobal_i == local_i. Under this constraint,local_i >= 2wheneverglobal_i > 1, soshared[local_i - 2]andshared[local_i - 1]are always valid.In a multi-block kernel the first two threads of each block beyond block 0 would have
local_i = 0orlocal_i = 1whileglobal_i > 1, causing out-of-bounds shared memory reads. The robust pattern for multi-block pooling guards withlocal_iand falls back to global reads for the halo elements:if local_i >= 2: output[global_i] = shared[local_i-2] + shared[local_i-1] + shared[local_i] elif local_i == 1 and global_i >= 2: output[global_i] = a[global_i-2] + shared[0] + shared[1] elif local_i == 0 and global_i >= 2: output[global_i] = a[global_i-2] + a[global_i-1] + shared[0]
- Memory access pattern
- One global read per thread into shared tensor
- Efficient neighbor access through shared memory
- TileTensor benefits:
- Automatic bounds checking
- Natural window indexing
- Layout-aware memory access
- Type safety throughout
This approach combines the performance of shared memory with TileTensor’s safety and ergonomics:
- Minimizes global memory access
- Simplifies window operations
- Handles boundaries cleanly
- Maintains coalesced access patterns
The final output shows the cumulative window sums:
[0.0, 1.0, 3.0, 6.0, 9.0, 12.0, 15.0, 18.0]