Mojo 🔥 GPU Puzzles, Edition 1
“For the things we have to learn before we can do them, we learn by doing them.” Aristotle (Nicomachean Ethics)
Welcome to our hands-on guide to GPU programming using Mojo 🔥, the programming language that combines Python syntax with systems-level performance.
Start with this overview video, or continue reading below.
Why GPU programming?
GPU programming has evolved from a specialized skill into fundamental infrastructure for modern computing. From large language models processing billions of parameters to computer vision systems analyzing real-time video streams, GPU acceleration drives the computational breakthroughs we see today. Scientific advances in climate modeling, drug discovery, and quantum simulation depend on the massive parallel processing capabilities that GPUs uniquely provide. Financial institutions rely on GPU computing for real-time risk analysis and algorithmic trading, while autonomous vehicles process sensor data through GPU-accelerated neural networks for critical decision-making.
The economic implications are substantial. Organizations that effectively leverage GPU computing achieve significant competitive advantages: accelerated development cycles, reduced computational costs, and the capacity to address previously intractable computational challenges. In an era where computational capability directly correlates with business value, GPU programming skills represent a strategic differentiator for engineers, researchers, and organizations.
Why Mojo🔥 for GPU programming?
The computing industry has reached a critical point. CPU performance no longer increases through higher clock speeds due to power and heat constraints. Hardware manufacturers have shifted toward increasing physical cores. This multi-core approach reaches its peak in modern GPUs, which contain thousands of cores operating in parallel. The NVIDIA H100, for example, can run 16,896 threads simultaneously in a single clock cycle, with over 270,000 threads queued for execution.
Mojo provides a practical approach to GPU programming, making this parallelism more accessible:
- Python-like Syntax with systems programming capabilities
- Zero-cost Abstractions that compile to efficient machine code
- Strong Type System that catches errors at compile time
- Built-in Tensor Support with hardware-aware optimizations for GPU computation
- Direct Access to low-level CPU and GPU intrinsics
- Cross-Hardware Portability for code that runs on both CPUs and GPUs
- Improved Safety over traditional C/C++ GPU programming
- Lower Barrier to Entry for more programmers to access GPU power
Mojo🔥 aims to fuel innovation by democratizing GPU programming. >By expanding on Python’s familiar syntax while adding direct GPU access, Mojo allows programmers with minimal specialized knowledge to build high-performance, heterogeneous (CPU, GPU-enabled) applications.
Why learn through puzzles?
Most GPU programming resources start with extensive theory before practical implementation. This can overwhelm newcomers with abstract concepts that only become clear through direct application.
This book uses a different approach: immediate engagement with practical problems that progressively introduce concepts through guided discovery.
Advantages of puzzle-based learning:
- Direct experience: Immediate execution on GPU hardware provides concrete feedback
- Incremental complexity: Each challenge builds on previously established concepts
- Applied focus: Problems mirror real-world computational scenarios
- Diagnostic skills: Systematic debugging practice develops troubleshooting capabilities
- Knowledge retention: Active problem-solving reinforces understanding more effectively than passive consumption
The methodology emphasizes discovery over memorization. Concepts emerge naturally through experimentation, creating deeper understanding and practical competency.
Acknowledgement: The Part I and III of this book are heavily inspired by GPU Puzzles, an interactive NVIDIA GPU learning project. This adaptation reimplements these concepts using Mojo’s abstractions and performance capabilities, while expanding on advanced topics with Mojo-specific optimizations.
The GPU programming mindset
Effective GPU programming requires a fundamental shift in how we think about computation. Here are some key mental models that will guide your journey:
From sequential to parallel: Eliminating loops with threads
In traditional CPU programming, we process data sequentially through loops:
# CPU approach
for i in range(data_size):
result[i] = process(data[i])
GPU programming inverts this paradigm completely. Rather than iterating sequentially through data, we assign thousands of parallel threads to process data elements simultaneously:
# GPU approach (conceptual)
thread_id = get_global_id()
if thread_id < data_size:
result[thread_id] = process(data[thread_id])
Each thread handles a single data element, replacing explicit iteration with massive parallelism. This fundamental reframing—from sequential processing to concurrent execution across all data elements—represents the core conceptual shift in GPU programming.
Fitting a mesh of compute over data
Consider your data as a structured grid, with GPU threads forming a corresponding computational grid that maps onto it. Effective GPU programming involves designing this thread organization to optimally cover your data space:
- Threads: Individual processing units, each responsible for specific data elements
- Blocks: Coordinated thread groups with shared memory access and synchronization capabilities
- Grid: The complete thread hierarchy spanning the entire computational problem
Successful GPU programming requires balancing this thread organization to maximize parallel efficiency while managing memory access patterns and synchronization requirements.
Data movement vs. computation
In GPU programming, data movement is often more expensive than computation:
- Moving data between CPU and GPU is slow
- Moving data between global and shared memory is faster
- Operating on data already in registers or shared memory is extremely fast
This inverts another common assumption in programming: computation is no longer the bottleneck—data movement is.
Through the puzzles in this book, you’ll develop an intuitive understanding of these principles, transforming how you approach computational problems.
What you will learn
This book takes you on a journey from first principles to advanced GPU programming techniques. Rather than treating the GPU as a mysterious black box, the content builds understanding layer by layer—starting with how individual threads operate and culminating in sophisticated parallel algorithms. Learning both low-level memory management and high-level tensor abstractions provides the versatility to tackle any GPU programming challenge.
Your current learning path
| Essential Skill | Status | Puzzles |
|---|---|---|
| Thread/Block basics | ✅ Available | Part I (1-8) |
| Debugging GPU Programs | ✅ Available | Part II (9-10) |
| Core algorithms | ✅ Available | Part III (11-16) |
| MAX Graph integration | ✅ Available | Part IV (17-19) |
| PyTorch integration | ✅ Available | Part V (20-22) |
| Functional patterns & benchmarking | ✅ Available | Part VI (23) |
| Warp programming | ✅ Available | Part VII (24-26) |
| Block-level programming | ✅ Available | Part VIII (27) |
| Advanced memory operations | ✅ Available | Part IX (28-29) |
| Performance analysis | ✅ Available | Part X (30-32) |
| Modern GPU features | ✅ Available | Part XI (33-34) |
Detailed learning objectives
Part I: GPU fundamentals (Puzzles 1-8) ✅
- Learn thread indexing and block organization
- Understand memory access patterns and guards
- Work with both raw pointers and TileTensor abstractions
- Learn shared memory basics for inter-thread communication
Part II: Debugging GPU programs (Puzzles 9-10) ✅
- Learn GPU debugger and debugging techniques
- Learn to use sanitizers for catching memory errors and race conditions
- Develop systematic approaches to identifying and fixing GPU bugs
- Build confidence for tackling complex GPU programming challenges
Note: Debugging puzzles require
pixifor access to NVIDIA’s GPU debugging tools. These puzzles work exclusively on NVIDIA GPUs with CUDA support.
Part III: GPU algorithms (Puzzles 11-16) ✅
- Implement parallel reductions and pooling operations
- Build efficient convolution kernels
- Learn prefix sum (scan) algorithms
- Optimize matrix multiplication with tiling strategies
Part IV: MAX Graph integration (Puzzles 17-19) ✅
- Create custom MAX Graph operations
- Interface GPU kernels with Python code
- Build production-ready operations like softmax and attention
Part V: PyTorch integration (Puzzles 20-22) ✅
- Bridge Mojo GPU kernels with PyTorch tensors
- Use CustomOpLibrary for seamless tensor marshalling
- Integrate with torch.compile for optimized execution
- Learn kernel fusion and custom backward passes
Part VI: Mojo functional patterns & benchmarking (Puzzle 23) ✅
- Learn functional patterns: elementwise, tiled processing, vectorization
- Learn systematic performance optimization and trade-offs
- Develop quantitative benchmarking skills for performance analysis
- Understand GPU threading vs SIMD execution hierarchies
Part VII: Warp-level programming (Puzzles 24-26) ✅
- Learn warp fundamentals and SIMT execution models
- Learn essential warp operations: sum, shuffle_down, broadcast
- Implement advanced patterns with shuffle_xor and prefix_sum
- Combine warp programming with functional patterns effectively
Part VIII: Block-level programming (Puzzle 27) ✅
- Learn block-wide reductions with
block.sum()andblock.max() - Learn block-level prefix sum patterns and communication
- Implement efficient block.broadcast() for intra-block coordination
Part IX: Advanced memory systems (Puzzles 28-29) ✅
- Achieve optimal memory coalescing patterns
- Use async memory operations for overlapping compute with latency hiding
- Learn memory fences and synchronization primitives
- Learn prefetching and cache optimization strategies
Part X: Performance analysis & optimization (Puzzles 30-32) ✅
- Profile GPU kernels and identify bottlenecks
- Optimize occupancy and resource utilization
- Eliminate shared memory bank conflicts
Part XI: Advanced GPU features (Puzzles 33-34) ✅
- Program tensor cores for AI workloads
- Learn cluster programming in modern GPUs
The book uniquely challenges the status quo approach by first building understanding with low-level memory manipulation, then gradually transitioning to Mojo’s TileTensor abstractions. This provides both deep understanding of GPU memory patterns and practical knowledge of modern tensor-based approaches.
Ready to get started?
You now understand why GPU programming matters, why Mojo is suitable for this work, and how puzzle-based learning functions. You’re prepared to begin.
Next step: Head to How to Use This Book for setup instructions, system requirements, and guidance on running your first puzzle.
How to Use This Book
Each puzzle maintains a consistent structure to support systematic skill development:
- Overview: Problem definition and key concepts for each challenge
- Configuration: Technical setup and memory organization details
- Code to Complete: Implementation framework in
problems/pXX/with clearly marked sections to fill in - Tips: Strategic hints available when needed, without revealing complete solutions
- Solution: Comprehensive implementation analysis, including performance considerations and conceptual explanations
The puzzles increase in complexity systematically, building new concepts on established foundations. Working through them sequentially is recommended, as advanced puzzles assume familiarity with concepts from earlier challenges.
Running the code
All puzzles integrate with a testing framework that validates implementations against expected results. Each puzzle provides specific execution instructions and solution verification procedures.
Prerequisites
System requirements
Make sure your system meets our system requirements.
Compatible GPU
You’ll need a
compatible GPU to run the
puzzles. After setup, you can verify your GPU compatibility using the
gpu-specs command (see Quick Start section below).
Operating System
[!NOTE] Here is some documentation how to setup GPU support in your OS for
Windows WSL2 for Linux with NVIDIA
To setup NVIVIA GPU support on Windows Subsystem for Linux (WSL2) e.g. Unbuntu please follow the NVIDIA CUDA on WLS Guide.
The important information is to install the NVIDIA Windows CUDA Driver for Windows because they fully support WSL2. Once a Windows NVIDIA GPU driver is installed on the system, CUDA becomes available within WSL 2. The CUDA driver installed on Windows host will be stubbed inside the WSL 2 as libcuda.so, therefore users must not install any NVIDIA GPU Linux driver within WSL 2.
Once you have installed the drivers please test the installation
Verify from Windows: Open PowerShell (not WSL)
nvidia-smi
Verify from inside WSL: (first start WLS e.g. via wsl -d Ubuntu)
ls -l /usr/lib/wsl/lib/nvidia-smi
/usr/lib/wsl/lib/nvidia-smi
Check setup from Pixi optionally install missing requirements e.g. for cuda-gdb debugging
pixi run nvidia-smi
pixi run setup-cuda-gdb
pixi run mojo debug --help
pixi run cuda-gdb --version
For WSL you can install VSCode as your Editor
- Install VS Code on Windows from https://code.visualstudio.com/.
- Then install the Remote - WSL extension.
[!NOTE] All puzzles 1-15 are working on WSL and Linux.
Linux native with NVIDIA
Check GPU + Ubuntu version (Supported Ubuntu LTS: 20.04, 22.04, 24.04)
lspci | grep -i nvidia
lsb_release -a
Install NVIDIA driver (mandatory)
sudo ubuntu-drivers devices
sudo ubuntu-drivers autoinstall
sudo reboot
For Linux you can install VSCode as your Editor
- Install VS Code in Linux via VS Code APT repository
Import Microsoft GPG key
wget -qO- https://packages.microsoft.com/keys/microsoft.asc \
| gpg --dearmor \
| sudo tee /usr/share/keyrings/packages.microsoft.gpg > /dev/null
Add VS Code APT repository
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/packages.microsoft.gpg] \
https://packages.microsoft.com/repos/code stable main" \
| sudo tee /etc/apt/sources.list.d/vscode.list
Install VS Code and verify installation
sudo apt update
sudo apt install code
code --version
[!NOTE] All puzzles 1-15 are working on Linux.
macOS Apple Silicon
For osx-arm64 users, you’ll need:
- macOS 15.0 or later for optimal compatibility. Run
pixi run check-macosand if it fails you’d need to upgrade. - Xcode 16 or later (minimum required). Use
xcodebuild -versionto check.
If xcrun -sdk macosx metal outputs
cannot execute tool 'metal' due to missing Metal toolchain proceed by running
xcodebuild -downloadComponent MetalToolchain
and then xcrun -sdk macosx metal, should give you the no input files error.
[!NOTE] Currently the puzzles 1-8 and 11-15 are working on macOS. We’re working to enable more. Please stay tuned!
Programming knowledge
Basic knowledge of:
- Programming fundamentals (variables, loops, conditionals, functions)
- Parallel computing concepts (threads, synchronization, race conditions)
- Basic familiarity with Mojo (language basics parts and intro to pointers section)
- GPU programming fundamentals is helpful!
No prior GPU programming experience is necessary! We’ll build that knowledge through the puzzles.
Let’s begin our journey into the exciting world of GPU computing with Mojo🔥!
Setting up your environment
-
Clone the GitHub repository and navigate to the repository:
# Clone the repository git clone https://github.com/modular/mojo-gpu-puzzles cd mojo-gpu-puzzles -
Install a package manager to run the Mojo🔥 programs:
Option 1 (Highly recommended)
pixi is the recommended option for this project because:
- Easy access to Modular’s MAX/Mojo packages
- Handles GPU dependencies
- Full conda + PyPI ecosystem support
> **Note: Some puzzles only work with `pixi`**
**Install:**
```bash
curl -fsSL https://pixi.sh/install.sh | sh
```
**Update:**
```bash
pixi self-update
```
Option 2: uv
**Install:**
```bash
curl -fsSL https://astral.sh/uv/install.sh | sh
```
**Update:**
```bash
uv self update
```
**Create a virtual environment:**
```bash
uv venv && source .venv/bin/activate
```
- Verify setup and run your first puzzle:
# Check your GPU specifications
pixi run gpu-specs
# Run your first puzzle
# This fails waiting for your implementation! follow the content
pixi run p01
# Check your GPU specifications
pixi run gpu-specs
# Run your first puzzle
# This fails waiting for your implementation! follow the content
pixi run -e amd p01
# Check your GPU specifications
pixi run gpu-specs
# Run your first puzzle
# This fails waiting for your implementation! follow the content
pixi run -e apple p01
# Install GPU-specific dependencies
uv pip install -e ".[nvidia]" # For NVIDIA GPUs
# OR
uv pip install -e ".[amd]" # For AMD GPUs
# Check your GPU specifications
uv run poe gpu-specs
# Run your first puzzle
# This fails waiting for your implementation! follow the content
uv run poe p01
Working with puzzles
Project structure
problems/: Where you implement your solutions (this is where you work!)solutions/: Reference solutions for comparison and learning that we use throughout the book
Workflow
- Navigate to
problems/pXX/to find the puzzle template - Implement your solution in the provided framework
- Test your implementation:
pixi run pXXoruv run poe pXX(remember to include your platform with-e platformsuch as-e amd) - Compare with
solutions/pXX/to learn different approaches
Essential commands
# Run puzzles (remember to include your platform with -e if needed)
pixi run pXX # NVIDIA (default) same as `pixi run -e nvidia pXX`
pixi run -e amd pXX # AMD GPU
pixi run -e apple pXX # Apple GPU
# Test solutions
pixi run tests # Test all solutions
pixi run tests pXX # Test specific puzzle
# Run manually
pixi run mojo problems/pXX/pXX.mojo # Your implementation
pixi run mojo solutions/pXX/pXX.mojo # Reference solution
# Interactive shell
pixi shell # Enter environment
mojo problems/p01/p01.mojo # Direct execution
exit # Leave shell
# Development
pixi run format # Format code
pixi task list # Available commands
# Note: uv is limited and some chapters require pixi
# Install GPU-specific dependencies:
uv pip install -e ".[nvidia]" # For NVIDIA GPUs
uv pip install -e ".[amd]" # For AMD GPUs
# Test solutions
uv run poe tests # Test all solutions
uv run poe tests pXX # Test specific puzzle
# Run manually
uv run mojo problems/pXX/pXX.mojo # Your implementation
uv run mojo solutions/pXX/pXX.mojo # Reference solution
GPU support matrix
The following table shows GPU platform compatibility for each puzzle. Different puzzles require different GPU features and vendor-specific tools.
| Puzzle | NVIDIA GPU | AMD GPU | Apple GPU | Notes |
|---|---|---|---|---|
| Part I: GPU Fundamentals | ||||
| 1 - Map | ✅ | ✅ | ✅ | Basic GPU kernels |
| 2 - Zip | ✅ | ✅ | ✅ | Basic GPU kernels |
| 3 - Guard | ✅ | ✅ | ✅ | Basic GPU kernels |
| 4 - Map 2D | ✅ | ✅ | ✅ | Basic GPU kernels |
| 5 - Broadcast | ✅ | ✅ | ✅ | Basic GPU kernels |
| 6 - Blocks | ✅ | ✅ | ✅ | Basic GPU kernels |
| 7 - Shared Memory | ✅ | ✅ | ✅ | Basic GPU kernels |
| 8 - Stencil | ✅ | ✅ | ✅ | Basic GPU kernels |
| Part II: Debugging | ||||
| 9 - GPU Debugger | ✅ | ❌ | ❌ | NVIDIA-specific debugging tools |
| 10 - Sanitizer | ✅ | ❌ | ❌ | NVIDIA-specific debugging tools |
| Part III: GPU Algorithms | ||||
| 11 - Reduction | ✅ | ✅ | ✅ | Basic GPU kernels |
| 12 - Scan | ✅ | ✅ | ✅ | Basic GPU kernels |
| 13 - Pool | ✅ | ✅ | ✅ | Basic GPU kernels |
| 14 - Conv | ✅ | ✅ | ✅ | Basic GPU kernels |
| 15 - Matmul | ✅ | ✅ | ✅ | Basic GPU kernels |
| 16 - Flashdot | ✅ | ✅ | ✅ | Advanced memory patterns |
| Part IV: MAX Graph | ||||
| 17 - Custom Op | ✅ | ✅ | ✅ | MAX Graph integration |
| 18 - Softmax | ✅ | ✅ | ✅ | MAX Graph integration |
| 19 - Attention | ✅ | ✅ | ✅ | MAX Graph integration |
| Part V: PyTorch Integration | ||||
| 20 - Torch Bridge | ✅ | ✅ | ❌ | PyTorch integration |
| 21 - Autograd | ✅ | ✅ | ❌ | PyTorch integration |
| 22 - Fusion | ✅ | ✅ | ❌ | PyTorch integration |
| Part VI: Functional Patterns | ||||
| 23 - Functional | ✅ | ✅ | ✅ | Advanced Mojo patterns |
| Part VII: Warp Programming | ||||
| 24 - Warp Sum | ✅ | ✅ | ✅ | Warp-level operations |
| 25 - Warp Communication | ✅ | ✅ | ✅ | Warp-level operations |
| 26 - Advanced Warp | ✅ | ✅ | ✅ | Warp-level operations |
| Part VIII: Block Programming | ||||
| 27 - Block Operations | ✅ | ✅ | ✅ | Block-level patterns |
| Part IX: Memory Systems | ||||
| 28 - Async Memory | ✅ | ✅ | ✅ | Advanced memory operations |
| 29 - Barriers | ✅ | ❌ | ❌ | Advanced NVIDIA-only synchronization |
| Part X: Performance Analysis | ||||
| 30 - Profiling | ✅ | ❌ | ❌ | NVIDIA profiling tools (NSight) |
| 31 - Occupancy | ✅ | ❌ | ❌ | NVIDIA profiling tools |
| 32 - Bank Conflicts | ✅ | ❌ | ❌ | NVIDIA profiling tools |
| Part XI: Modern GPU Features | ||||
| 33 - Tensor Cores | ✅ | ❌ | ❌ | NVIDIA Tensor Core specific |
| 34 - Cluster | ✅ | ❌ | ❌ | NVIDIA cluster programming |
Legend
- ✅ Supported: Puzzle works on this platform
- ❌ Not Supported: Puzzle requires platform-specific features
Platform notes
NVIDIA GPUs (Complete Support)
- All puzzles (1-34) work on NVIDIA GPUs with CUDA support
- Requires CUDA toolkit and compatible drivers
- Best learning experience with access to all features
AMD GPUs (Extensive Support)
- Most puzzles (1-8, 11-29) work with ROCm support
- Missing only: Debugging tools (9-10), profiling (30-32), Tensor Cores (33-34)
- Excellent for learning GPU programming including advanced algorithms and memory patterns
Apple GPUs (Basic Support)
- A selection of fundamental (1-8, 11-18) and advanced (23-27) puzzles are supported
- Missing: All advanced features, debugging, profiling tools
- Suitable for learning basic GPU programming patterns
Future Support: We’re actively working to expand tooling and platform support for AMD and Apple GPUs. Missing features like debugging tools, profiling capabilities, and advanced GPU operations are planned for future releases. Check back for updates as we continue to broaden cross-platform compatibility.
GPU Resources
Free cloud GPU platforms
If you don’t have local GPU access, several cloud platforms offer free GPU resources for learning and experimentation:
Google Colab
Google Colab provides free GPU access with some limitations for Mojo GPU programming:
Available GPUs:
- Tesla T4 (older Turing architecture)
- Tesla V100 (limited availability)
Limitations for Mojo GPU Puzzles:
- Older GPU architecture: T4 GPUs may have limited compatibility with advanced Mojo GPU features
- Session limits: 12-hour maximum runtime, then automatic disconnect
- Limited debugging support: NVIDIA debugging tools (puzzles 9-10) may not be fully available
- Package installation restrictions: May require workarounds for Mojo/MAX installation
- Performance limitations: Shared infrastructure affects consistent benchmarking
Recommended for: Basic GPU programming concepts (puzzles 1-8, 11-15) and learning fundamental patterns.
Kaggle Notebooks
Kaggle offers more generous free GPU access:
Available GPUs:
- Tesla T4 (30 hours per week free)
- P100 (limited availability)
Advantages over Colab:
- More generous time limits: 30 hours per week compared to Colab’s daily session limits
- Better persistence: Notebooks save automatically
- Consistent environment: More reliable package installation
Limitations for Mojo GPU Puzzles:
- Same GPU architecture constraints: T4 compatibility issues with advanced features
- Limited debugging tools: NVIDIA profiling and debugging tools (puzzles 9-10, 30-32) unavailable
- Mojo installation complexity: Requires manual setup of Mojo environment
- No cluster programming support: Advanced puzzles (33-34) won’t work
Recommended for: Extended learning sessions on fundamental GPU programming (puzzles 1-16).
Recommendations
- Complete Learning Path: Use NVIDIA GPU for full curriculum access (all 34 puzzles)
- Comprehensive Learning: AMD GPUs work well for most content (27 of 34 puzzles)
- Basic Understanding: Apple GPUs suitable for fundamental concepts (13 of 34 puzzles)
- Free Platform Learning: Google Colab/Kaggle suitable for basic to intermediate concepts (puzzles 1-16)
- Debugging & Profiling: NVIDIA GPU required for debugging tools and performance analysis
- Modern GPU Features: NVIDIA GPU required for Tensor Cores and cluster programming
Development
Please see details in the README.
Join the community
Join our vibrant community to discuss GPU programming, share solutions, and get help!
🏆 Claim Your Rewards
Have you completed the available puzzles? We’re giving away free sticker packs to celebrate your achievement!
To claim your free stickers:
- Fork the GitHub repository https://github.com/modular/mojo-gpu-puzzles
- Add your solutions to the available puzzles
- Submit your solutions through this form and we’ll send you exclusive Modular stickers!
Currently, we can ship stickers to addresses within North America. If you’re located elsewhere, please still submit your solutions – we’re working on expanding our shipping reach and would love to recognize your achievements when possible.
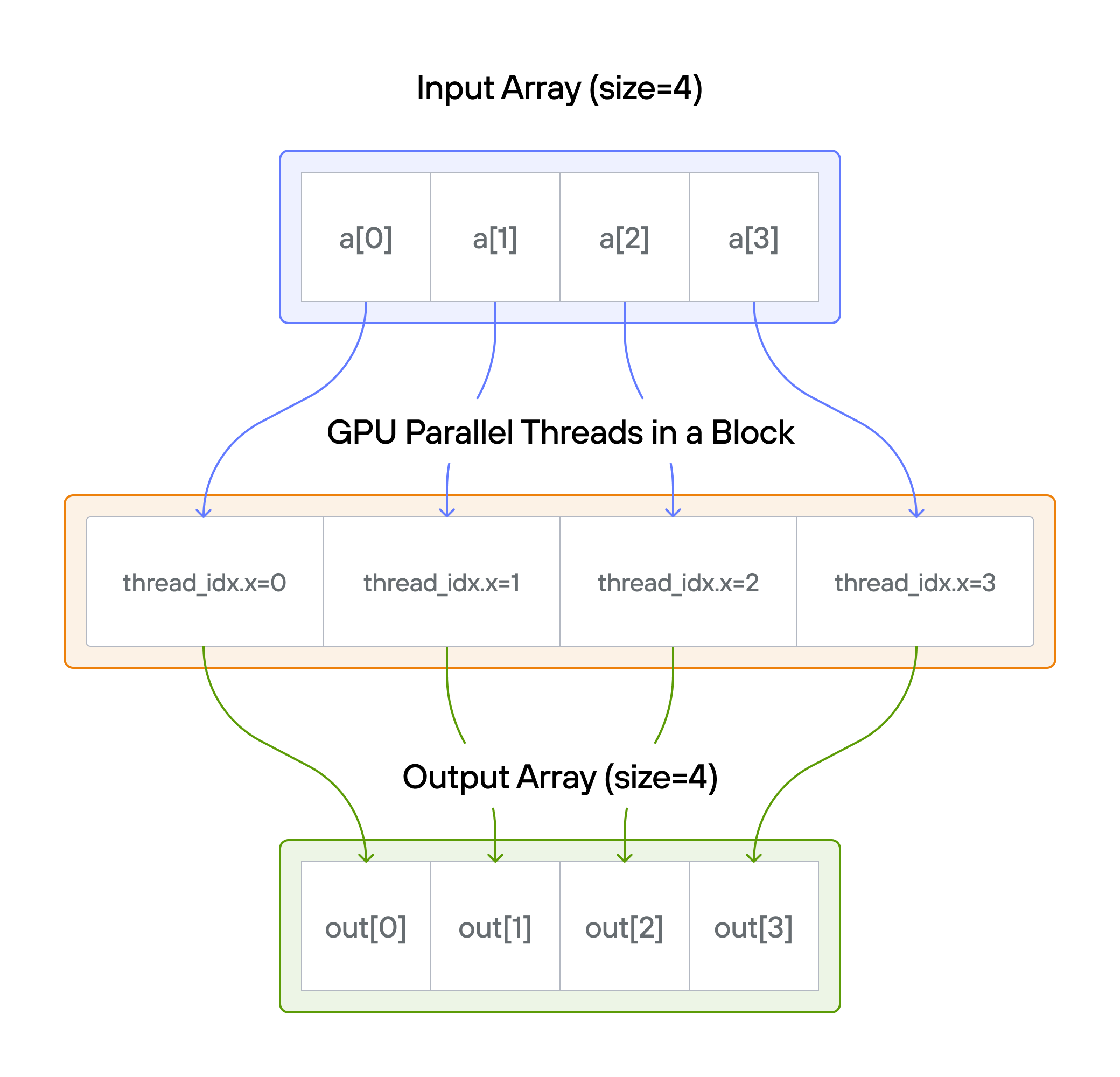
Puzzle 1: Map
Overview
This puzzle introduces the fundamental concept of GPU parallelism: mapping
individual threads to data elements for concurrent processing. Your task is to
implement a kernel that adds 10 to each element of vector a, storing the
results in vector output.
Note: You have 1 thread per position.
Key concepts
- Basic GPU kernel structure
- One-to-one thread to data mapping
- Memory access patterns
- Array operations on GPU
For each position \(i\): \[\Large output[i] = a[i] + 10\]
What we cover
🔰 Raw Memory Approach
Start with direct memory manipulation to understand GPU fundamentals.
💡 Preview: Modern Approach with TileTensor
See how TileTensor simplifies GPU programming with safer, cleaner code.
💡 Tip: Understanding both approaches leads to better appreciation of modern GPU programming patterns.
Key concepts
In this puzzle, you’ll learn about:
-
Basic GPU kernel structure
-
Thread indexing with
thread_idx.x -
Simple parallel operations
-
Parallelism: Each thread executes independently
-
Thread indexing: Access element at position
i = thread_idx.x -
Memory access: Read from
a[i]and write tooutput[i] -
Data independence: Each output depends only on its corresponding input
Code to complete
comptime SIZE = 4
comptime BLOCKS_PER_GRID = 1
comptime THREADS_PER_BLOCK = SIZE
comptime dtype = DType.float32
def add_10(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
):
var i = thread_idx.x
# FILL ME IN (roughly 1 line)
View full file: problems/p01/p01.mojo
Tips
- Store
thread_idx.xini - Add 10 to
a[i] - Store result in
output[i]
Running the code
To test your solution, run the following command in your terminal:
pixi run p01
pixi run -e amd p01
pixi run -e apple p01
uv run poe p01
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([10.0, 11.0, 12.0, 13.0])
Solution
def add_10(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
):
var i = thread_idx.x
output[i] = a[i] + 10.0
This solution:
- Gets thread index with
i = thread_idx.x - Adds 10 to input value:
output[i] = a[i] + 10.0
Why consider TileTensor?
Looking at our traditional implementation below, you might notice some potential issues:
Current approach
i = thread_idx.x
output[i] = a[i] + 10.0
This works for 1D arrays, but what happens when we need to:
- Handle 2D or 3D data?
- Deal with different memory layouts?
- Ensure coalesced memory access?
Preview of future challenges
As we progress through the puzzles, array indexing will become more complex:
# 2D indexing coming in later puzzles
idx = row * WIDTH + col
# 3D indexing
idx = (batch * HEIGHT + row) * WIDTH + col
# With padding
idx = (batch * padded_height + row) * padded_width + col
TileTensor preview
TileTensor will help us handle these cases more elegantly:
# Future preview - don't worry about this syntax yet!
output[i, j] = a[i, j] + 10.0 # 2D indexing
output[b, i, j] = a[b, i, j] + 10.0 # 3D indexing
We’ll learn about TileTensor in detail in Puzzle 4, where these concepts become essential. For now, focus on understanding:
- Basic thread indexing
- Simple memory access patterns
- One-to-one mapping of threads to data
💡 Key Takeaway: While direct indexing works for simple cases, we’ll soon need more sophisticated tools for complex GPU programming patterns.
Puzzle 2: Zip
Overview
Implement a kernel that adds together each position of vector a and vector b
and stores it in output.
Note: You have 1 thread per position.
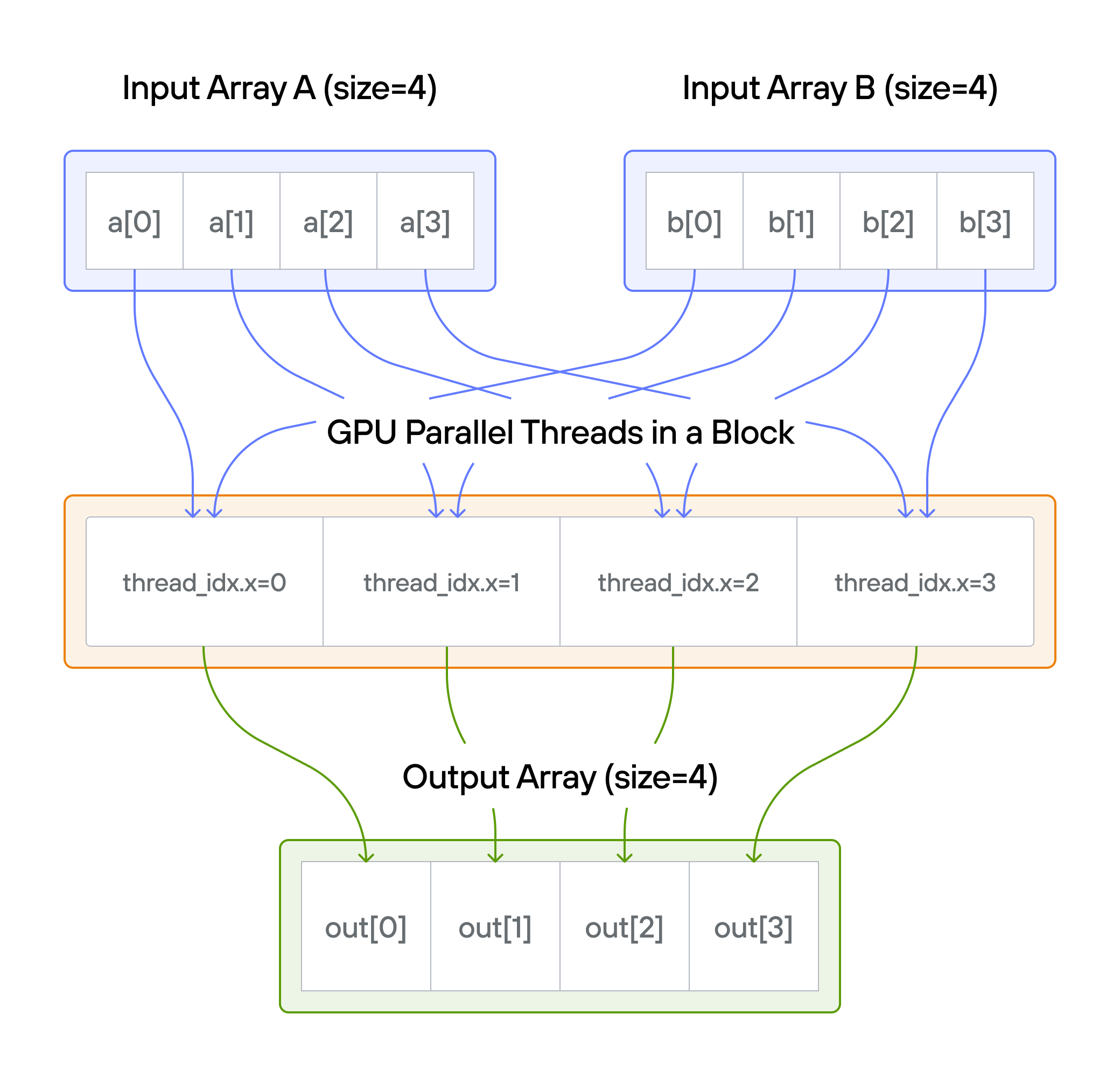
Key concepts
In this puzzle, you’ll learn about:
- Processing multiple input arrays in parallel
- Element-wise operations with multiple inputs
- Thread-to-data mapping across arrays
- Memory access patterns with multiple arrays
For each thread \(i\): \[\Large output[i] = a[i] + b[i]\]
Memory access pattern
Thread 0: a[0] + b[0] → output[0]
Thread 1: a[1] + b[1] → output[1]
Thread 2: a[2] + b[2] → output[2]
...
💡 Note: Notice how we’re now managing three arrays (a, b, output) in
our kernel. As we progress to more complex operations, managing multiple array
accesses will become increasingly challenging.
Code to complete
comptime SIZE = 4
comptime BLOCKS_PER_GRID = 1
comptime THREADS_PER_BLOCK = SIZE
comptime dtype = DType.float32
def add(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
b: UnsafePointer[Scalar[dtype], MutAnyOrigin],
):
var i = thread_idx.x
# FILL ME IN (roughly 1 line)
View full file: problems/p02/p02.mojo
Tips
- Store
thread_idx.xini - Add
a[i]andb[i] - Store result in
output[i]
Running the code
To test your solution, run the following command in your terminal:
pixi run p02
pixi run -e amd p02
pixi run -e apple p02
uv run poe p02
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([0.0, 2.0, 4.0, 6.0])
Solution
def add(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
b: UnsafePointer[Scalar[dtype], MutAnyOrigin],
):
var i = thread_idx.x
output[i] = a[i] + b[i]
This solution:
- Gets thread index with
i = thread_idx.x - Adds values from both arrays:
output[i] = a[i] + b[i]
Looking ahead
While this direct indexing works for simple element-wise operations, consider:
- What if arrays have different layouts?
- What if we need to broadcast one array to another?
- How to ensure coalesced access across multiple arrays?
These questions will be addressed when we introduce TileTensor in Puzzle 4.
Puzzle 3: Guards
Overview
Implement a kernel that adds 10 to each position of vector a and stores it in
vector output.
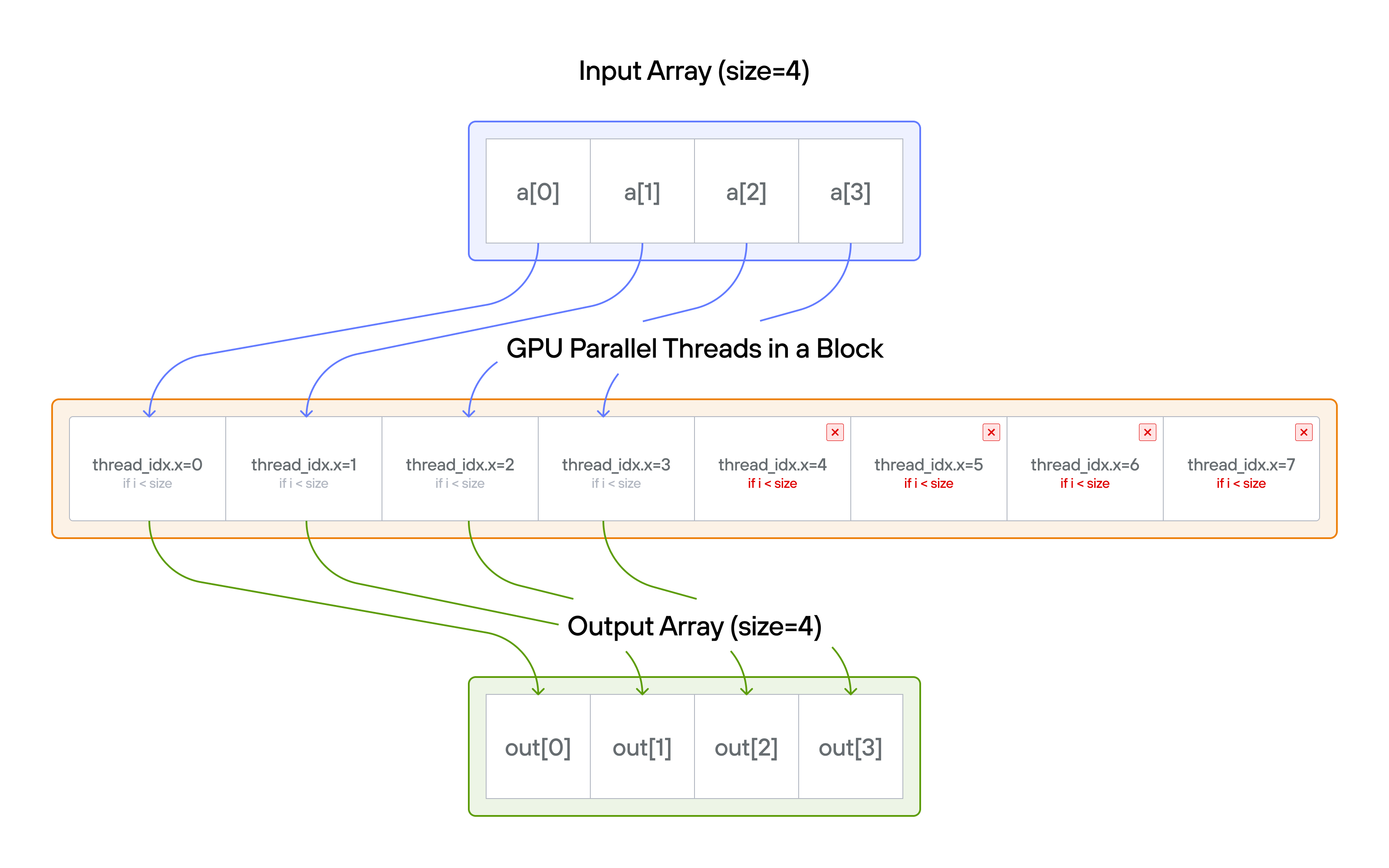
Note: You have more threads than positions. This means you need to protect against out-of-bounds memory access.
Key concepts
This puzzle covers:
- Handling thread/data size mismatches
- Preventing out-of-bounds memory access
- Using conditional execution in GPU kernels
- Safe memory access patterns
Mathematical description
For each thread \(i\): \[\Large \text{if}\ i < \text{size}: output[i] = a[i] + 10\]
Memory safety pattern
Thread 0 (i=0): if 0 < size: output[0] = a[0] + 10 ✓ Valid
Thread 1 (i=1): if 1 < size: output[1] = a[1] + 10 ✓ Valid
Thread 2 (i=2): if 2 < size: output[2] = a[2] + 10 ✓ Valid
Thread 3 (i=3): if 3 < size: output[3] = a[3] + 10 ✓ Valid
Thread 4 (i=4): if 4 < size: ❌ Skip (out of bounds)
Thread 5 (i=5): if 5 < size: ❌ Skip (out of bounds)
💡 Note: Boundary checking becomes increasingly complex with:
- Multi-dimensional arrays
- Different array shapes
- Complex access patterns
Code to complete
comptime SIZE = 4
comptime BLOCKS_PER_GRID = 1
comptime THREADS_PER_BLOCK = 8
comptime dtype = DType.float32
def add_10_guard(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
size: Int,
):
var i = thread_idx.x
# FILL ME IN (roughly 2 lines)
View full file: problems/p03/p03.mojo
Tips
- Store
thread_idx.xini - Add guard:
if i < size - Inside guard:
output[i] = a[i] + 10.0
Running the code
To test your solution, run the following command in your terminal:
pixi run p03
pixi run -e amd p03
pixi run -e apple p03
uv run poe p03
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([10.0, 11.0, 12.0, 13.0])
Solution
def add_10_guard(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
size: Int,
):
var i = thread_idx.x
if i < size:
output[i] = a[i] + 10.0
This solution:
- Gets thread index with
i = thread_idx.x - Guards against out-of-bounds access with
if i < size - Inside guard: adds 10 to input value
You might wonder why it passes the test even without the bound-check! Always remember that passing the tests doesn’t necessarily mean the code is sound and free of Undefined Behaviors. In puzzle 10 we’ll examine such cases and use some tools to catch such soundness bugs.
Looking ahead
While simple boundary checks work here, consider these challenges:
- What about 2D/3D array boundaries?
- How to handle different shapes efficiently?
- What if we need padding or edge handling?
Example of growing complexity:
# Current: 1D bounds check
if i < size: ...
# Coming soon: 2D bounds check
if i < height and j < width: ...
# Later: 3D with padding
if i < height and j < width and k < depth and
i >= padding and j >= padding: ...
These boundary handling patterns will become more elegant when we learn about TileTensor in Puzzle 4, which provides built-in shape management.
Puzzle 4: 2D Map
Overview
Implement a kernel that adds 10 to each position of 2D square matrix a and
stores it in 2D square matrix output.
Note: You have more threads than positions.
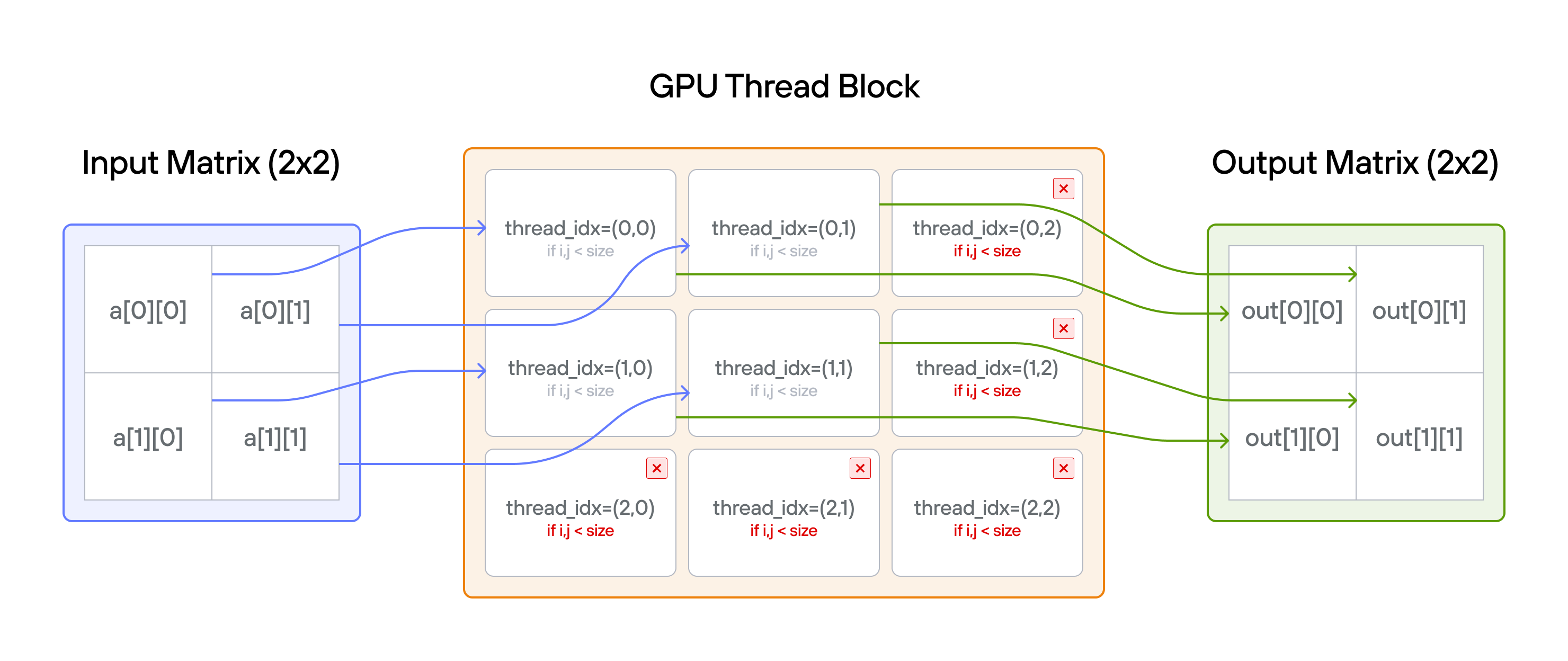
Key concepts
- 2D thread indexing
- Matrix operations on GPU
- Handling excess threads
- Memory layout patterns
For each position \((i,j)\): \[\Large output[i,j] = a[i,j] + 10\]
Thread indexing convention
When working with 2D matrices in GPU programming, we follow a natural mapping between thread indices and matrix coordinates:
thread_idx.ycorresponds to the row indexthread_idx.xcorresponds to the column index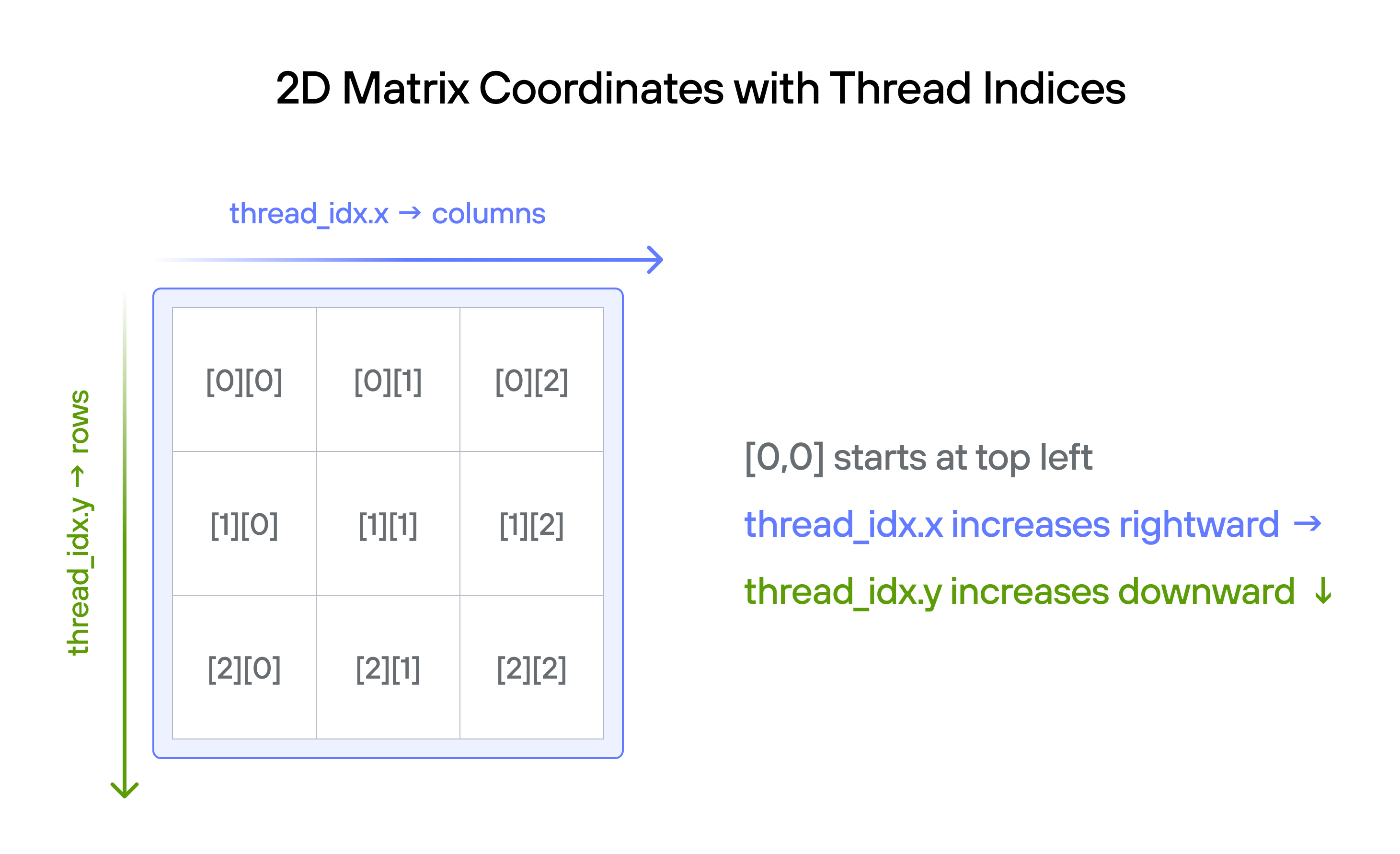
This convention aligns with:
- The standard mathematical notation where matrix positions are specified as (row, column)
- The visual representation of matrices where rows go top-to-bottom (y-axis) and columns go left-to-right (x-axis)
- Common GPU programming patterns where thread blocks are organized in a 2D grid matching the matrix structure
Historical origins
While graphics and image processing typically use \((x,y)\) coordinates, matrix operations in computing have historically used (row, column) indexing. This comes from how early computers stored and processed 2D data: line by line, top to bottom, with each line read left to right. This row-major memory layout proved efficient for both CPUs and GPUs, as it matches how they access memory sequentially. When GPU programming adopted thread blocks for parallel processing, it was natural to map
thread_idx.yto rows andthread_idx.xto columns, maintaining consistency with established matrix indexing conventions.
Implementation approaches
🔰 Raw memory approach
Learn how 2D indexing works with manual memory management.
📚 Learn about TileTensor
Discover a powerful abstraction that simplifies multi-dimensional array operations and memory management on GPU.
🚀 Modern 2D operations
Put TileTensor into practice with natural 2D indexing and automatic bounds checking.
💡 Note: From this puzzle onward, we’ll primarily use TileTensor for cleaner, safer GPU code.
Overview
Implement a kernel that adds 10 to each position of 2D square matrix a and
stores it in 2D square matrix output.
Note: You have more threads than positions.
Key concepts
In this puzzle, you’ll learn about:
- Working with 2D thread indices (
thread_idx.x,thread_idx.y) - Converting 2D coordinates to 1D memory indices
- Handling boundary checks in two dimensions
The key insight is understanding how to map from 2D thread coordinates \((i,j)\) to elements in a row-major matrix of size \(n \times n\), while ensuring thread indices are within bounds.
- 2D indexing: Each thread has a unique \((i,j)\) position
- Memory layout: Row-major ordering maps 2D to 1D memory
- Guard condition: Need bounds checking in both dimensions
- Thread bounds: More threads \((3 \times 3)\) than matrix elements \((2 \times 2)\)
Code to complete
comptime SIZE = 2
comptime BLOCKS_PER_GRID = 1
comptime THREADS_PER_BLOCK = (3, 3)
comptime dtype = DType.float32
def add_10_2d(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
# FILL ME IN (roughly 2 lines)
View full file: problems/p04/p04.mojo
Tips
- Get 2D indices:
row = thread_idx.y,col = thread_idx.x - Add guard:
if row < size and col < size - Inside guard add 10 in row-major way!
Running the code
To test your solution, run the following command in your terminal:
pixi run p04
pixi run -e amd p04
pixi run -e apple p04
uv run poe p04
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([10.0, 11.0, 12.0, 13.0])
Solution
def add_10_2d(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
if row < size and col < size:
output[row * size + col] = a[row * size + col] + 10.0
This solution:
- Get 2D indices:
row = thread_idx.y,col = thread_idx.x - Add guard:
if row < size and col < size - Inside guard:
output[row * size + col] = a[row * size + col] + 10.0
Introduction to TileTensor
Let’s take a quick break from solving puzzles to preview a powerful abstraction that will make our GPU programming journey more enjoyable: 🥁… the TileTensor.
💡 This is a motivational overview of TileTensor’s capabilities. Don’t worry about understanding everything now - we’ll explore each feature in depth as we progress through the puzzles.
The challenge: Growing complexity
Let’s look at the challenges we’ve faced so far:
# Puzzle 1: Simple indexing
output[i] = a[i] + 10.0
# Puzzle 2: Multiple array management
output[i] = a[i] + b[i]
# Puzzle 3: Bounds checking
if i < size:
output[i] = a[i] + 10.0
As dimensions grow, code becomes more complex:
# Traditional 2D indexing for row-major 2D matrix
idx = row * WIDTH + col
if row < height and col < width:
output[idx] = a[idx] + 10.0
The solution: A peek at TileTensor
TileTensor will help us tackle these challenges with elegant solutions. Here’s a glimpse of what’s coming:
- Natural Indexing: Use
tensor[i, j]instead of manual offset calculations - Flexible Memory Layouts: Support for row-major, column-major, and tiled organizations
- Performance Optimization: Efficient memory access patterns for GPU
A taste of what’s ahead
Let’s look at a few examples of what TileTensor can do. Don’t worry about understanding all the details now - we’ll cover each feature thoroughly in upcoming puzzles.
Basic usage example
from layout import TileTensor
from layout.tile_layout import row_major
# Define layout
comptime HEIGHT = 2
comptime WIDTH = 3
comptime layout = row_major[HEIGHT, WIDTH]()
comptime LayoutType = type_of(layout)
# Create tensor
tensor = TileTensor(buffer, layout)
# Access elements naturally
tensor[0, 0] = 1.0 # First element
tensor[1, 2] = 2.0 # Last element
To learn more about Layout and TileTensor, see these guides from the
Mojo manual
Quick example
Let’s put everything together with a simple example that demonstrates the basics of TileTensor:
# ===----------------------------------------------------------------------=== #
#
# This file is Modular Inc proprietary.
#
# ===----------------------------------------------------------------------=== #
from std.gpu.host import DeviceContext
from layout import TileTensor
from layout.tile_layout import row_major
comptime HEIGHT = 2
comptime WIDTH = 3
comptime dtype = DType.float32
comptime layout = row_major[HEIGHT, WIDTH]()
comptime LayoutType = type_of(layout)
def kernel(
tensor: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
):
print("Before:")
print(tensor)
tensor[0, 0] += 1
print("After:")
print(tensor)
def main() raises:
ctx = DeviceContext()
a = ctx.enqueue_create_buffer[dtype](HEIGHT * WIDTH)
a.enqueue_fill(0)
tensor = TileTensor(a, layout)
# Note: since `tensor` is a device tensor we can't print it without the kernel wrapper
ctx.enqueue_function[kernel, kernel](tensor, grid_dim=1, block_dim=1)
ctx.synchronize()
When we run this code with:
pixi run tile_tensor_intro
pixi run -e amd tile_tensor_intro
pixi run -e apple tile_tensor_intro
uv run poe tile_tensor_intro
Before:
0.0 0.0 0.0
0.0 0.0 0.0
After:
1.0 0.0 0.0
0.0 0.0 0.0
Let’s break down what’s happening:
- We create a
2 x 3tensor with row-major layout - Initially, all elements are zero
- Using natural indexing, we modify a single element
- The change is reflected in our output
This simple example demonstrates key TileTensor benefits:
- Clean syntax for tensor creation and access
- Automatic memory layout handling
- Natural multi-dimensional indexing
While this example is straightforward, the same patterns will scale to complex GPU operations in upcoming puzzles. You’ll see how these basic concepts extend to:
- Multi-threaded GPU operations
- Shared memory optimizations
- Complex tiling strategies
- Hardware-accelerated computations
Ready to start your GPU programming journey with TileTensor? Let’s dive into the puzzles!
💡 Tip: Keep this example in mind as we progress - we’ll build upon these fundamental concepts to create increasingly sophisticated GPU programs.
TileTensor Version
Overview
Implement a kernel that adds 10 to each position of 2D TileTensor a and
stores it in 2D TileTensor output.
Note: You have more threads than positions.
Key concepts
In this puzzle, you’ll learn about:
- Using
TileTensorfor 2D array access - Direct 2D indexing with
tensor[i, j] - Handling bounds checking with
TileTensor
The key insight is that TileTensor provides a natural 2D indexing interface,
abstracting away the underlying memory layout while still requiring bounds
checking.
- 2D access: Natural \((i,j)\) indexing with
TileTensor - Memory abstraction: No manual row-major calculation needed
- Guard condition: Still need bounds checking in both dimensions
- Thread bounds: More threads \((3 \times 3)\) than tensor elements \((2 \times 2)\)
Code to complete
comptime SIZE = 2
comptime BLOCKS_PER_GRID = 1
comptime THREADS_PER_BLOCK = (3, 3)
comptime dtype = DType.float32
comptime layout = row_major[SIZE, SIZE]()
comptime LayoutType = type_of(layout)
def add_10_2d(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
# FILL ME IN (roughly 2 lines)
View full file: problems/p04/p04_tile_tensor.mojo
Tips
- Get 2D indices:
row = thread_idx.y,col = thread_idx.x - Add guard:
if row < size and col < size - Inside guard add 10 to
a[row, col]
Running the code
To test your solution, run the following command in your terminal:
pixi run p04_tile_tensor
pixi run -e amd p04_tile_tensor
pixi run -e apple p04_tile_tensor
uv run poe p04_tile_tensor
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([10.0, 11.0, 12.0, 13.0])
Solution
def add_10_2d(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
if col < size and row < size:
output[row, col] = a[row, col] + 10.0
This solution:
- Gets 2D thread indices with
row = thread_idx.y,col = thread_idx.x - Guards against out-of-bounds with
if row < size and col < size - Uses
TileTensor’s 2D indexing:output[row, col] = a[row, col] + 10.0
Puzzle 5: Broadcast
Overview
Implement a kernel that broadcast adds 1D TileTensor a and 1D TileTensor b
and stores it in 2D TileTensor output.
Broadcasting in parallel programming refers to the operation where lower-dimensional arrays are automatically expanded to match the shape of higher-dimensional arrays during element-wise operations. Instead of physically replicating data in memory, values are logically repeated across the additional dimensions. For example, adding a 1D vector to each row (or column) of a 2D matrix applies the same vector elements repeatedly without creating multiple copies.
Note: You have more threads than positions.
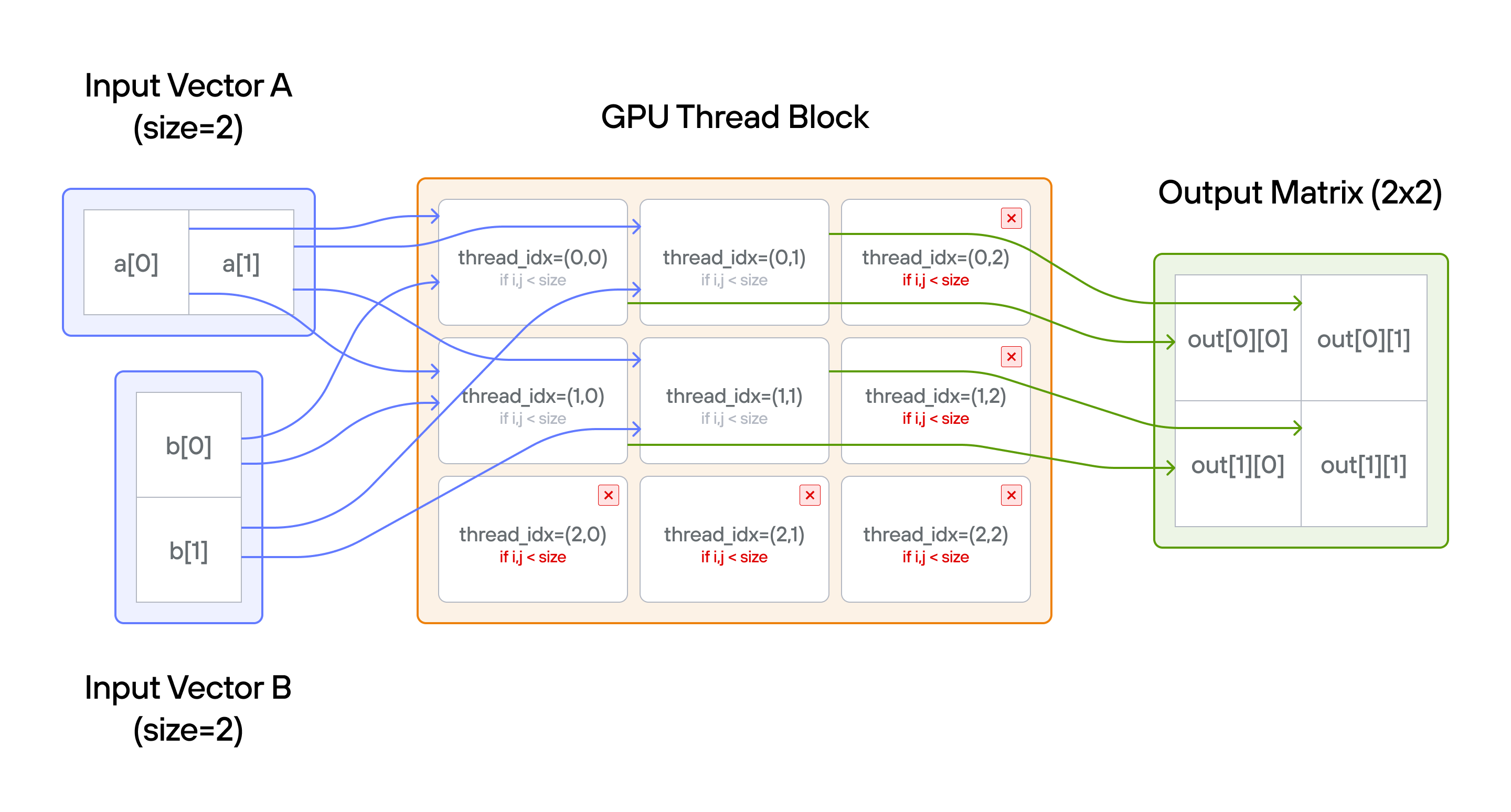
Key concepts
In this puzzle, you’ll learn about:
- Broadcasting 1D vectors across different dimensions with
TileTensor - Using 2D thread indices to map GPU threads to a 2D output matrix
- Working with different tensor shapes for mixed-dimension operations
- Handling boundary conditions in broadcast patterns
The key insight is that TileTensor allows natural broadcasting through
different tensor shapes: \((1, n)\) and \((n, 1)\) to \((n,n)\), while
still requiring bounds checking.
- Tensor shapes: Input vectors have shapes \((1, n)\) and \((n, 1)\)
- Broadcasting: Each element of
acombines with each element ofb; output expands both dimensions to \((n,n)\) - Access patterns:
a[0, col]broadcasts horizontally across rows;b[row, 0]broadcasts vertically across columns - Guard condition: Still need bounds checking for output size
- Thread bounds: More threads \((3 \times 3)\) than tensor elements \((2 \times 2)\)
Code to complete
comptime SIZE = 2
comptime BLOCKS_PER_GRID = 1
comptime THREADS_PER_BLOCK = (3, 3)
comptime dtype = DType.float32
comptime out_layout = row_major[SIZE, SIZE]()
comptime a_layout = row_major[1, SIZE]()
comptime b_layout = row_major[SIZE, 1]()
comptime OutLayout = type_of(out_layout)
comptime ALayout = type_of(a_layout)
comptime BLayout = type_of(b_layout)
def broadcast_add(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, ALayout, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, BLayout, ImmutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
# FILL ME IN (roughly 2 lines)
View full file: problems/p05/p05.mojo
Tips
- Get 2D indices:
row = thread_idx.y,col = thread_idx.x - Add guard:
if row < size and col < size - Inside guard: think about how to broadcast values of
aandbas TileTensors
Running the code
To test your solution, run the following command in your terminal:
pixi run p05
pixi run -e amd p05
pixi run -e apple p05
uv run poe p05
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([1.0, 2.0, 11.0, 12.0])
Solution
def broadcast_add(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, ALayout, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, BLayout, ImmutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
if row < size and col < size:
output[row, col] = a[0, col] + b[row, 0]
This solution demonstrates key concepts of TileTensor broadcasting and GPU thread mapping:
-
Thread to matrix mapping
- Uses
thread_idx.yfor row access andthread_idx.xfor column access - Natural 2D indexing matches the output matrix structure
- Excess threads (3×3 grid) are handled by bounds checking
- Uses
-
Broadcasting mechanics
- Input
ahas shape(1,n):a[0,col]broadcasts across rows - Input
bhas shape(n,1):b[row,0]broadcasts across columns - Output has shape
(n,n): Each element is sum of corresponding broadcasts
[ a0 a1 ] + [ b0 ] = [ a0+b0 a1+b0 ] [ b1 ] [ a0+b1 a1+b1 ] - Input
-
Bounds Checking
- Guard condition
row < size and col < sizeprevents out-of-bounds access - Handles both matrix bounds and excess threads efficiently
- No need for separate checks for
aandbdue to broadcasting
- Guard condition
This pattern forms the foundation for more complex tensor operations we’ll explore in later puzzles.
Puzzle 6: Blocks
Overview
Implement a kernel that adds 10 to each position of vector a and stores it in
output.
A thread block (or just block) is a group of threads that execute
together on a single GPU multiprocessor. All threads in a block share the same
shared memory and can synchronize with each other. When data is larger than one
block can handle, the GPU schedules multiple blocks — each block independently
processes its portion of the data. The global position of a thread is computed
from both its position within the block (thread_idx.x) and which block it
belongs to (block_idx.x):
global_i = block_dim.x * block_idx.x + thread_idx.x.
Note: You have fewer threads per block than the size of a.
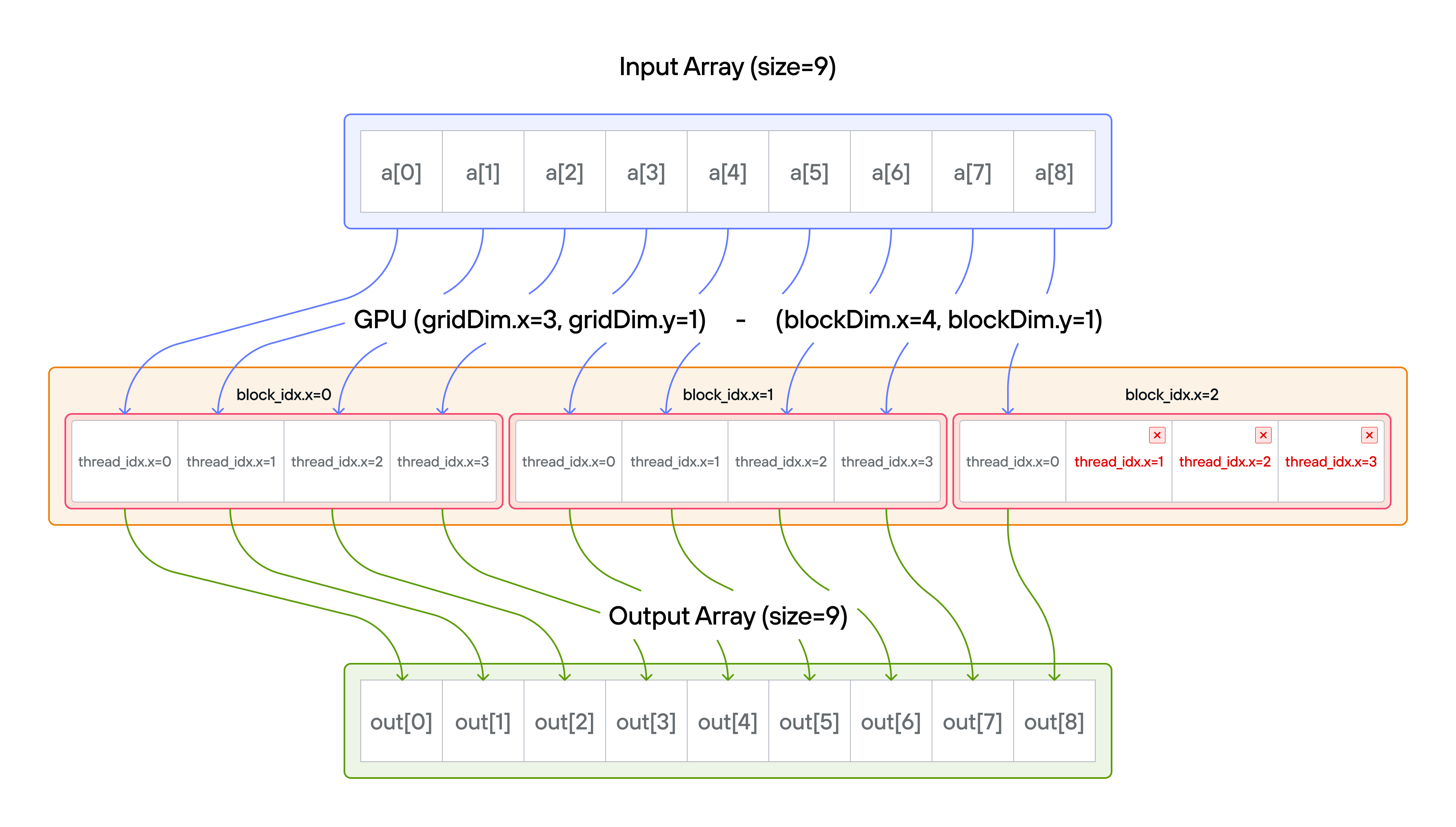
Key concepts
This puzzle covers:
- Processing data larger than thread block size
- Coordinating multiple blocks of threads
- Computing global thread positions
The key insight is understanding how blocks of threads work together to process data that’s larger than a single block’s capacity, while maintaining correct element-to-thread mapping.
Code to complete
comptime SIZE = 9
comptime BLOCKS_PER_GRID = (3, 1)
comptime THREADS_PER_BLOCK = (4, 1)
comptime dtype = DType.float32
def add_10_blocks(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
size: Int,
):
var i = block_dim.x * block_idx.x + thread_idx.x
# FILL ME IN (roughly 2 lines)
View full file: problems/p06/p06.mojo
Note: The
TileTensorvariant of this puzzle is very similar so we leave it to the reader.
Tips
- Calculate global index:
i = block_dim.x * block_idx.x + thread_idx.x - Add guard:
if i < size - Inside guard:
output[i] = a[i] + 10.0
Running the code
To test your solution, run the following command in your terminal:
pixi run p06
pixi run -e amd p06
pixi run -e apple p06
uv run poe p06
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0, 17.0, 18.0])
Solution
def add_10_blocks(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
size: Int,
):
var i = block_dim.x * block_idx.x + thread_idx.x
if i < size:
output[i] = a[i] + 10.0
This solution covers key concepts of block-based GPU processing:
-
Global thread indexing
-
Combines block and thread indices:
block_dim.x * block_idx.x + thread_idx.x -
Maps each thread to a unique global position
-
Example for 3 threads per block:
Block 0: [0 1 2] Block 1: [3 4 5] Block 2: [6 7 8]
-
-
Block coordination
-
Each block processes a contiguous chunk of data
-
Block size (3) < Data size (9) requires multiple blocks
-
Automatic work distribution across blocks:
Data: [0 1 2 3 4 5 6 7 8] Block 0: [0 1 2] Block 1: [3 4 5] Block 2: [6 7 8]
-
-
Bounds checking
- Guard condition
i < sizehandles edge cases - Prevents out-of-bounds access when size isn’t perfectly divisible by block size
- Essential for handling partial blocks at the end of data
- Guard condition
-
Memory access pattern
- Coalesced memory access: threads in a block access contiguous memory
- Each thread processes one element:
output[i] = a[i] + 10.0 - Block-level parallelism provides efficient memory bandwidth utilization
This pattern forms the foundation for processing large datasets that exceed the size of a single thread block.
Puzzle 7: 2D Blocks
Overview
Implement a kernel that adds 10 to each position of 2D TileTensor a and stores
it in 2D TileTensor output.
Note:
You have fewer threads per block than the size of a in both directions.
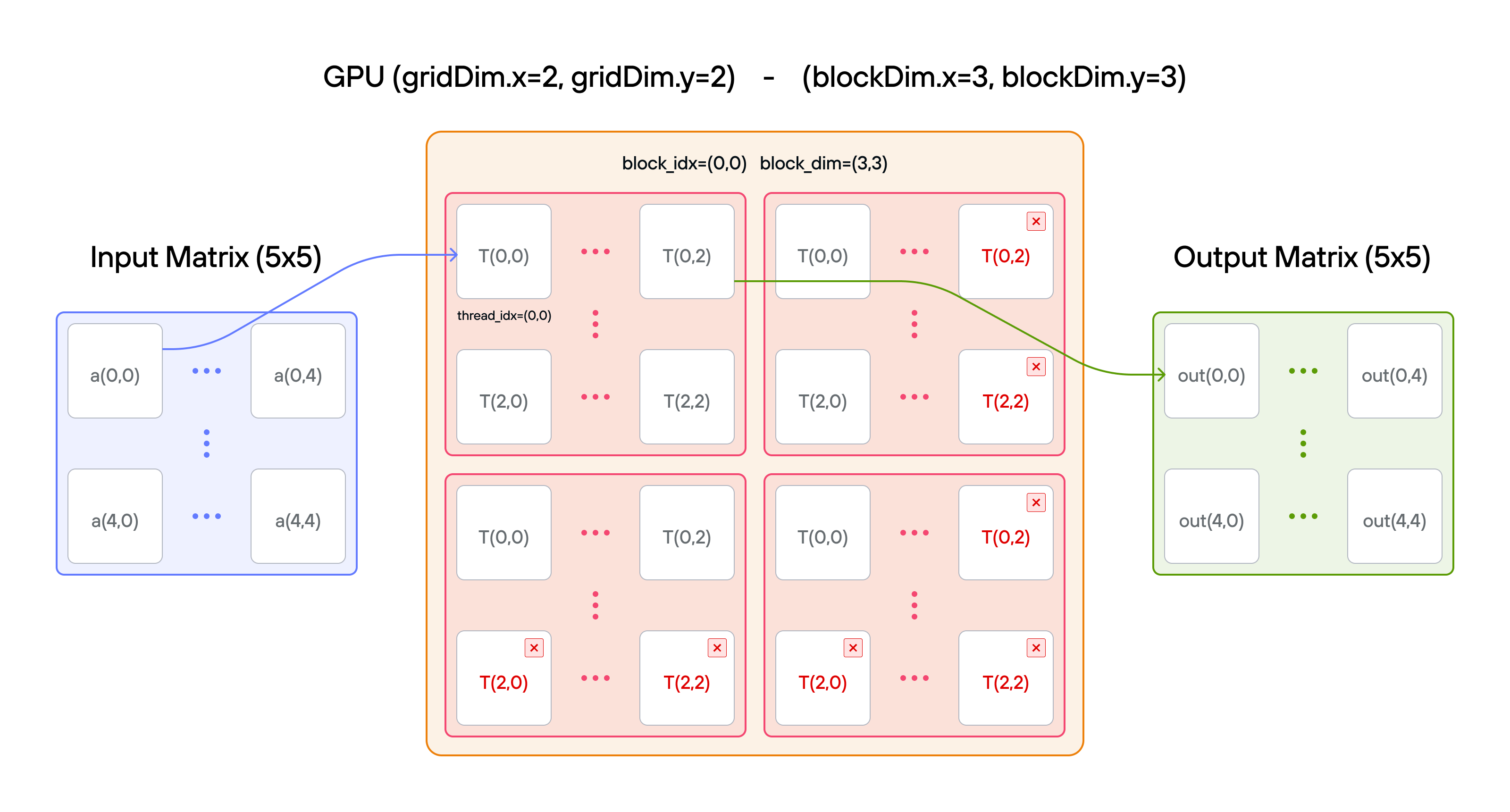
Key concepts
In this puzzle, you’ll learn about:
- Using
TileTensorwith multiple blocks - Handling large matrices with 2D block organization
- Combining block indexing with
TileTensoraccess
The key insight is that TileTensor simplifies 2D indexing while still
requiring proper block coordination for large matrices.
🔑 2D thread indexing convention
We extend the block-based indexing from puzzle 4 to 2D:
Global position calculation: row = block_dim.y * block_idx.y + thread_idx.y col = block_dim.x * block_idx.x + thread_idx.xFor example, with 2×2 blocks in a 4×4 grid:
Block (0,0): Block (1,0): [0,0 0,1] [0,2 0,3] [1,0 1,1] [1,2 1,3] Block (0,1): Block (1,1): [2,0 2,1] [2,2 2,3] [3,0 3,1] [3,2 3,3]Each position shows (row, col) for that thread’s global index. The block dimensions and indices work together to ensure:
- Continuous coverage of the 2D space
- No overlap between blocks
- Efficient memory access patterns
Configuration
- Matrix size: \(5 \times 5\) elements
- Layout handling:
TileTensormanages row-major organization - Block coordination: Multiple blocks cover the full matrix
- 2D indexing: Natural \((i,j)\) access with bounds checking
- Total threads: \(36\) for \(25\) elements
- Thread mapping: Each thread processes one matrix element
Code to complete
comptime SIZE = 5
comptime BLOCKS_PER_GRID = (2, 2)
comptime THREADS_PER_BLOCK = (3, 3)
comptime dtype = DType.float32
comptime out_layout = row_major[SIZE, SIZE]()
comptime a_layout = row_major[SIZE, SIZE]()
comptime OutLayout = type_of(out_layout)
comptime ALayout = type_of(a_layout)
def add_10_blocks_2d(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, ALayout, ImmutAnyOrigin],
size: Int,
):
var row = block_dim.y * block_idx.y + thread_idx.y
var col = block_dim.x * block_idx.x + thread_idx.x
# FILL ME IN (roughly 2 lines)
View full file: problems/p07/p07.mojo
Tips
- Calculate global indices:
row = block_dim.y * block_idx.y + thread_idx.y,col = block_dim.x * block_idx.x + thread_idx.x - Add guard:
if row < size and col < size - Inside guard: think about how to add 10 to 2D TileTensor
Running the code
To test your solution, run the following command in your terminal:
pixi run p07
pixi run -e amd p07
pixi run -e apple p07
uv run poe p07
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, ... , 0.0])
expected: HostBuffer([10.0, 11.0, 12.0, ... , 34.0])
Solution
def add_10_blocks_2d(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, ALayout, ImmutAnyOrigin],
size: Int,
):
var row = block_dim.y * block_idx.y + thread_idx.y
var col = block_dim.x * block_idx.x + thread_idx.x
if row < size and col < size:
output[row, col] = a[row, col] + 10.0
This solution demonstrates how TileTensor simplifies 2D block-based processing:
-
2D thread indexing
-
Global row:
block_dim.y * block_idx.y + thread_idx.y -
Global col:
block_dim.x * block_idx.x + thread_idx.x -
Maps thread grid to tensor elements:
5×5 tensor with 3×3 blocks: Block (0,0) Block (1,0) [(0,0) (0,1) (0,2)] [(0,3) (0,4) * ] [(1,0) (1,1) (1,2)] [(1,3) (1,4) * ] [(2,0) (2,1) (2,2)] [(2,3) (2,4) * ] Block (0,1) Block (1,1) [(3,0) (3,1) (3,2)] [(3,3) (3,4) * ] [(4,0) (4,1) (4,2)] [(4,3) (4,4) * ] [ * * * ] [ * * * ](* = thread exists but outside tensor bounds)
-
-
TileTensor benefits
-
Natural 2D indexing:
tensor[row, col]instead of manual offset calculation -
Automatic memory layout optimization
-
Example access pattern:
Raw memory: TileTensor: row * size + col tensor[row, col] (2,1) -> 11 (2,1) -> same element
-
-
Bounds checking
- Guard
row < size and col < sizehandles:- Excess threads in partial blocks
- Edge cases at tensor boundaries
- Automatic memory layout handling by TileTensor
- 36 threads (2×2 blocks of 3×3) for 25 elements
- Guard
-
Block coordination
- Each 3×3 block processes part of 5×5 tensor
- TileTensor handles:
- Memory layout optimization
- Efficient access patterns
- Block boundary coordination
- Cache-friendly data access
This pattern shows how TileTensor simplifies 2D block processing while maintaining optimal memory access patterns and thread coordination.
Puzzle 8: Shared Memory
Overview
Implement a kernel that adds 10 to each position of a 1D TileTensor a and
stores it in 1D TileTensor output.
Shared memory is fast, on-chip storage that is visible to all threads within
the same block. Unlike global memory (which all blocks can access but is slow),
shared memory has latency similar to a CPU register cache. Each block gets its
own private shared memory region — threads in one block cannot see the shared
memory of another block. Because threads can read and write to the same shared
memory locations, coordination via barrier() is required to prevent one thread
from reading a value before another thread has finished writing it.
Note: You have fewer threads per block than the size of a.
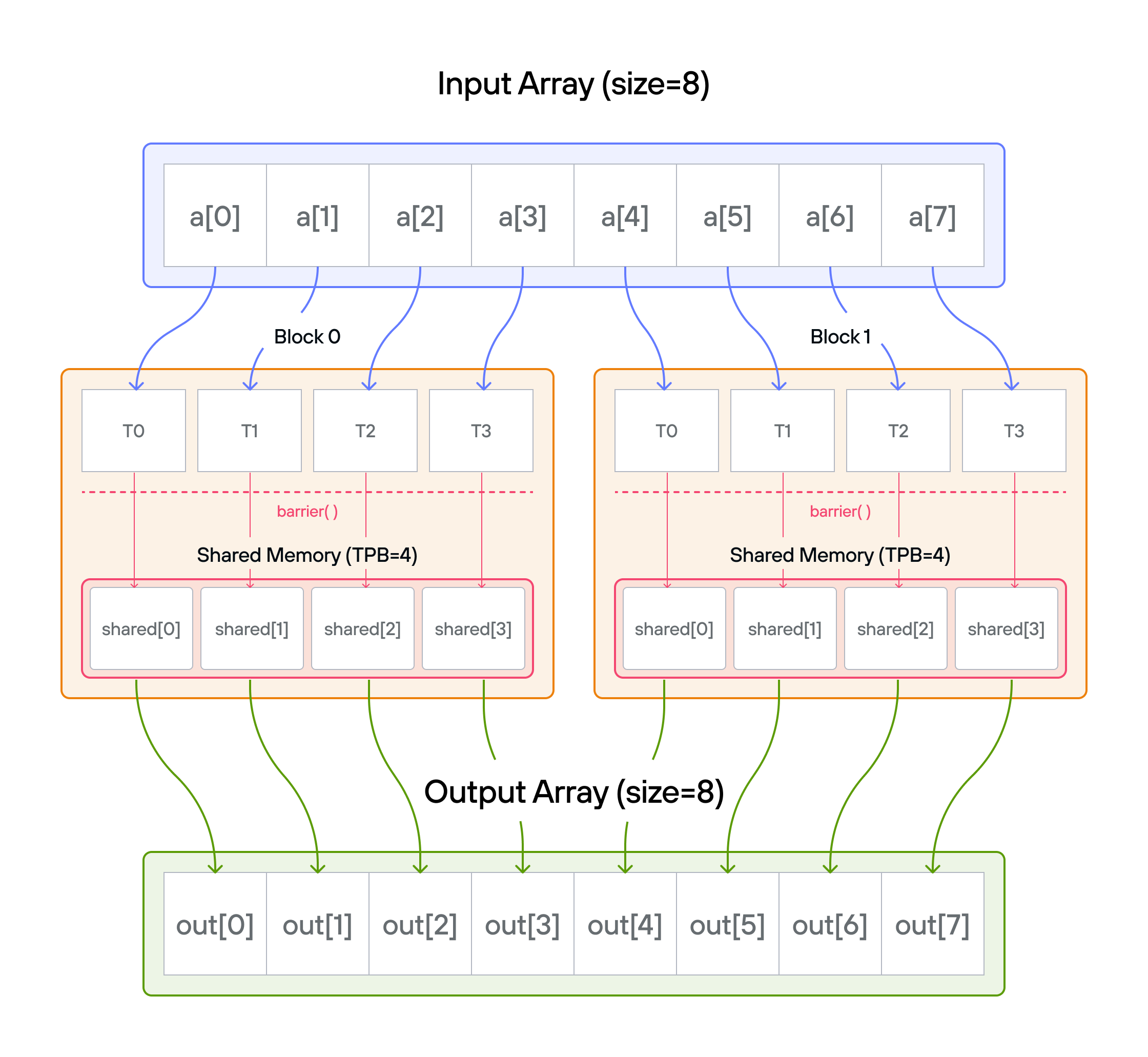
Key concepts
In this puzzle, you’ll learn about:
- Using TileTensor’s shared memory features with address_space
- Thread synchronization with shared memory
- Block-local data management with TileTensor
The key insight is how TileTensor simplifies shared memory management while maintaining the performance benefits of block-local storage.
Configuration
- Array size:
SIZE = 8elements - Threads per block:
TPB = 4 - Number of blocks: 2
- Shared memory:
TPBelements per block
Warning: Each block can only have a constant amount of shared memory that threads in that block can read and write to. This needs to be a literal python constant, not a variable. After writing to shared memory you need to call barrier to ensure that threads do not cross.
Educational Note: In this specific puzzle, the barrier() isn’t strictly
necessary since each thread only accesses its own shared memory location.
However, it’s included to teach proper shared memory synchronization patterns
for more complex scenarios where threads need to coordinate access to shared
data.
Code to complete
comptime TPB = 4
comptime SIZE = 8
comptime BLOCKS_PER_GRID = (2, 1)
comptime THREADS_PER_BLOCK = (TPB, 1)
comptime dtype = DType.float32
comptime layout = row_major[SIZE]()
comptime LayoutType = type_of(layout)
def add_10_shared(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
# Allocate shared memory using stack_allocation
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
if global_i < size:
shared[local_i] = a[global_i]
barrier()
# FILL ME IN (roughly 2 lines)
View full file: problems/p08/p08.mojo
Tips
- Create shared memory with TileTensor using address_space parameter
- Load data with natural indexing:
shared[local_i] = a[global_i] - Synchronize with
barrier()(educational - not strictly needed here) - Process data using shared memory indices
- Guard against out-of-bounds access
Running the code
To test your solution, run the following command in your terminal:
pixi run p08
pixi run -e amd p08
pixi run -e apple p08
uv run poe p08
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([11.0, 11.0, 11.0, 11.0, 11.0, 11.0, 11.0, 11.0])
Solution
def add_10_shared_tile_tensor(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
# Allocate shared memory using stack_allocation
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
if global_i < size:
shared[local_i] = a[global_i]
# Note: barrier is not strictly needed here since each thread only accesses
# its own shared memory location. However, it's included to teach proper
# shared memory synchronization patterns for more complex scenarios where
# threads need to coordinate access to shared data.
barrier()
if global_i < size:
output[global_i] = shared[local_i] + 10
This solution demonstrates how TileTensor simplifies shared memory usage while maintaining performance:
-
Memory hierarchy with TileTensor
-
Global tensors:
aandoutput(slow, visible to all blocks) -
Shared tensor:
shared(fast, thread-block local) -
Example for 8 elements with 4 threads per block:
Global tensor a: [1 1 1 1 | 1 1 1 1] # Input: all ones Block (0): Block (1): shared[0..3] shared[0..3] [1 1 1 1] [1 1 1 1]
-
-
Thread coordination
-
Load phase with natural indexing:
Thread 0: shared[0] = a[0]=1 Thread 2: shared[2] = a[2]=1 Thread 1: shared[1] = a[1]=1 Thread 3: shared[3] = a[3]=1 barrier() ↓ ↓ ↓ ↓ # Wait for all loads -
Process phase: Each thread adds 10 to its shared tensor value
-
Result:
output[global_i] = shared[local_i] + 10 = 11
-
Note: In this specific case, the barrier() isn’t strictly necessary since
each thread only writes to and reads from its own shared memory location
(shared[local_i]). However, it’s included for educational purposes to
demonstrate proper shared memory synchronization patterns that are essential
when threads need to access each other’s data.
-
TileTensor benefits
-
Shared memory allocation:
# Clean TileTensor API with address_space shared = stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB]()) -
Natural indexing for both global and shared:
Block 0 output: [11 11 11 11] Block 1 output: [11 11 11 11] -
Built-in layout management and type safety
-
-
Memory access pattern
- Load: Global tensor → Shared tensor (optimized)
- Sync: Same
barrier()requirement as raw version - Process: Add 10 to shared values
- Store: Write 11s back to global tensor
This pattern shows how TileTensor maintains the performance benefits of shared memory while providing a more ergonomic API and built-in features.
Puzzle 9: GPU Debugging Workflow
⚠️ This puzzle works on compatible NVIDIA GPU only. We are working to enable tooling support for other GPU vendors.
When GPU programs fail
You’ve written GPU kernels, worked with shared memory, and coordinated thousands of parallel threads. Your code compiles. You run it expecting correct results, and then:
- CRASH
- Wrong results
- Infinite hang
This is GPU programming reality: debugging parallel code running on thousands of threads simultaneously. This is where theory meets practice, where algorithmic knowledge meets investigative skills.
Why GPU debugging is challenging
Unlike traditional CPU debugging where you follow a single thread through sequential execution, GPU debugging requires you to:
- Think in parallel: Thousands of threads executing simultaneously, each potentially doing something different
- Navigate multiple memory spaces: Global memory, shared memory, registers, constant memory
- Handle coordination failures: Race conditions, barrier deadlocks, memory access violations
- Debug optimized code: JIT compilation, variable optimization, limited symbol information
- Use specialized tools: CUDA-GDB for kernel inspection, thread navigation, parallel state analysis
GPU debugging skills provide deep understanding of parallel computing fundamentals.
What you’ll learn in this puzzle
This puzzle teaches you to debug GPU code systematically. You’ll learn the approaches, tools, and techniques that GPU developers use daily to solve complex parallel programming challenges.
Essential skills you’ll develop
- Professional debugging workflow - The systematic approach professionals use
- Tool proficiency - LLDB for host code, CUDA-GDB for GPU kernels
- Pattern recognition - Common GPU bug types and symptoms
- Investigation techniques - Finding root causes when variables are optimized out
- Thread coordination debugging - Advanced GPU debugging skills
Real-world debugging scenarios
You’ll tackle the three most common GPU programming failures:
- Memory crashes - Null pointers, illegal memory access, segmentation faults
- Logic bugs - Correct execution with wrong results, algorithmic errors
- Coordination deadlocks - Barrier synchronization failures, infinite hangs
Each scenario teaches different investigation techniques and builds debugging intuition.
Your debugging journey
This puzzle takes you through a carefully designed progression from basic debugging concepts to advanced parallel coordination failures:
📚 Step 1: Mojo GPU Debugging Essentials
Foundation building - Learn the tools and workflow
- Set up your debugging environment with
pixiand CUDA-GDB - Learn the four debugging approaches: JIT vs binary, CPU vs GPU
- Learn essential CUDA-GDB commands for GPU kernel inspection
- Practice with hands-on examples using familiar code from previous puzzles
- Understand when to use each debugging approach
Key outcome: Professional debugging workflow and tool proficiency
🧐 Step 2: Detective Work: First Case
Memory crash investigation - Debug a GPU program that crashes
- Investigate
CUDA_ERROR_ILLEGAL_ADDRESScrashes - Learn systematic pointer inspection techniques
- Learn null pointer detection and validation
- Practice professional crash analysis workflow
- Understand GPU memory access failures
Key outcome: Ability to debug GPU memory crashes and pointer issues
🔍 Step 3: Detective Work: Second Case
Logic bug investigation - Debug a program with wrong results
- Investigate TileTensor-based algorithmic errors
- Learn execution flow analysis when variables are optimized out
- Learn loop boundary analysis and iteration counting
- Practice pattern recognition in incorrect results
- Debug without direct variable inspection
Key outcome: Ability to debug algorithmic errors and logic bugs in GPU kernels
🕵️ Step 4: Detective Work: Third Case
Barrier deadlock investigation - Debug a program that hangs forever
- Investigate barrier synchronization failures
- Learn multi-thread state analysis across parallel execution
- Learn conditional execution path tracing
- Practice thread coordination debugging
- Understand the most challenging GPU debugging scenario
Key outcome: Advanced thread coordination debugging - the pinnacle of GPU debugging skills
The detective mindset
GPU debugging requires a different mindset than traditional programming. You become a detective investigating a crime scene where:
- The evidence is limited - Variables are optimized out, symbols are mangled
- Multiple suspects exist - Thousands of threads, any could be the culprit
- The timeline is complex - Parallel execution, race conditions, timing dependencies
- The tools are specialized - CUDA-GDB, thread navigation, GPU memory inspection
But like any good detective, you’ll learn to:
- Follow the clues systematically - Error messages, crash patterns, thread states
- Form hypotheses - What could cause this specific behavior?
- Test theories - Use debugging commands to verify or disprove ideas
- Trace back to root causes - From symptoms to the actual source of problems
Prerequisites and expectations
What you need to know:
- GPU programming concepts from Puzzles 1-8 (thread indexing, memory management, barriers)
- Basic command-line comfort (you’ll use terminal-based debugging tools)
- Patience and systematic thinking (GPU debugging requires methodical investigation)
What you’ll gain:
- Professional debugging skills used in GPU development teams
- Deep parallel computing understanding that comes from seeing execution at the thread level
- Problem-solving confidence for the most challenging GPU programming scenarios
- Tool proficiency that will serve you throughout your GPU programming career
Ready to begin?
GPU debugging is where you transition from writing GPU programs to understanding them deeply. Every professional GPU developer has spent countless hours debugging parallel code, learning to think in thousands of simultaneous threads, and developing the patience to investigate complex coordination failures.
This is your opportunity to join that elite group.
Start your debugging journey: Mojo GPU Debugging Essentials
“Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” - Brian Kernighan
In GPU programming, this wisdom is amplified by a factor of thousands - the number of parallel threads you’re debugging simultaneously.
📚 Mojo GPU Debugging Essentials
Welcome to the world of GPU debugging! After learning GPU programming concepts through puzzles 1-8, you’re now ready to learn the most critical skill for any GPU programmer: how to debug when things go wrong.
GPU debugging can seem intimidating at first - you’re dealing with thousands of threads running in parallel, different memory spaces, and hardware-specific behaviors. But with the right tools and workflow, debugging GPU code becomes systematic and manageable.
In this guide, you’ll learn to debug both the CPU host code (where you set up your GPU operations) and the GPU kernel code (where the parallel computation happens). We’ll use real examples, actual debugger output, and step-by-step workflows that you can immediately apply to your own projects.
Note: The following content focuses on command-line debugging for universal IDE compatibility. If you prefer VS Code debugging, refer to the Mojo debugging documentation for VS Code-specific setup and workflows.
Why GPU debugging is different
Before diving into tools, consider what makes GPU debugging unique:
- Traditional CPU debugging: One thread, sequential execution, straightforward memory model
- GPU debugging: Thousands of threads, parallel execution, multiple memory spaces, race conditions
This means you need specialized tools that can:
- Switch between different GPU threads
- Inspect thread-specific variables and memory
- Handle the complexity of parallel execution
- Debug both CPU setup code and GPU kernel code
Your debugging toolkit
Mojo’s GPU debugging capabilities currently is limited to NVIDIA GPUs. The Mojo debugging documentation explains that the Mojo package includes:
- LLDB debugger with Mojo plugin for CPU-side debugging
- CUDA-GDB integration for GPU kernel debugging
- Command-line interface via
mojo debugfor universal IDE compatibility
For GPU-specific debugging, the Mojo GPU debugging guide provides additional technical details.
This architecture provides the best of both worlds: familiar debugging commands with GPU-specific capabilities.
The debugging workflow: From problem to solution
When your GPU program crashes, produces wrong results, or behaves unexpectedly, follow this systematic approach:
- Prepare your code for debugging (disable optimizations, add debug symbols)
- Choose the right debugger (CPU host code vs GPU kernel debugging)
- Set strategic breakpoints (where you suspect the problem lies)
- Execute and inspect (step through code, examine variables)
- Analyze patterns (memory access, thread behavior, race conditions)
This workflow works whether you’re debugging a simple array operation from Puzzle 01 or complex shared memory code from Puzzle 08.
Step 1: Preparing your code for debugging
🥇 The golden rule: Never debug optimized code. Optimizations can reorder instructions, eliminate variables, and inline functions, making debugging nearly impossible.
Building with debug information
When building Mojo programs for debugging, always include debug symbols:
# Build with full debug information
mojo build -O0 -g your_program.mojo -o your_program_debug
What these flags do:
-O0: Disables all optimizations, preserving your original code structure-g: Includes debug symbols so the debugger can map machine code back to your Mojo source-o: Creates a named output file for easier identification
Why this matters
Without debug symbols, your debugging session looks like this:
(lldb) print my_variable
error: use of undeclared identifier 'my_variable'
With debug symbols, you get:
(lldb) print my_variable
(int) $0 = 42
Step 2: Choosing your debugging approach
Here’s where GPU debugging gets interesting. You have four different combinations to choose from, and picking the right one saves you time:
The four debugging combinations
Quick reference:
# 1. JIT + LLDB: Debug CPU host code directly from source
pixi run mojo debug your_gpu_program.mojo
# 2. JIT + CUDA-GDB: Debug GPU kernels directly from source
pixi run mojo debug --cuda-gdb --break-on-launch your_gpu_program.mojo
# 3. Binary + LLDB: Debug CPU host code from pre-compiled binary
pixi run mojo build -O0 -g your_gpu_program.mojo -o your_program_debug
pixi run mojo debug your_program_debug
# 4. Binary + CUDA-GDB: Debug GPU kernels from pre-compiled binary
pixi run mojo debug --cuda-gdb --break-on-launch your_program_debug
When to use each approach
For learning and quick experiments:
- Use JIT debugging - no build step required, faster iteration
For serious debugging sessions:
- Use binary debugging - more predictable, cleaner debugger output
For CPU-side issues (buffer allocation, host memory, program logic):
- Use LLDB mode - perfect for debugging your
main()function and setup code
For GPU kernel issues (thread behavior, GPU memory, kernel crashes):
- Use CUDA-GDB mode - the only way to inspect individual GPU threads
The beauty is that you can mix and match. Start with JIT + LLDB to debug your setup code, then switch to JIT + CUDA-GDB to debug the actual kernel.
Understanding GPU kernel debugging with CUDA-GDB
Next comes GPU kernel debugging - the most powerful (and complex) part of your debugging toolkit.
When you use --cuda-gdb, Mojo integrates with NVIDIA’s
CUDA-GDB debugger. This
isn’t just another debugger - it’s specifically designed for the parallel,
multi-threaded world of GPU computing.
What makes CUDA-GDB special
Regular GDB debugs one thread at a time, stepping through sequential code. CUDA-GDB debugs thousands of GPU threads simultaneously, each potentially executing different instructions.
This means you can:
- Set breakpoints inside GPU kernels - pause execution when any thread hits your breakpoint
- Switch between GPU threads - examine what different threads are doing at the same moment
- Inspect thread-specific data - see how the same variable has different values across threads
- Debug memory access patterns - catch out-of-bounds access, race conditions, and memory corruption (more on detecting such issues in the Puzzle 10)
- Analyze parallel execution - understand how your threads interact and synchronize
Connecting to concepts from previous puzzles
Remember the GPU programming concepts you learned in puzzles 1-8? CUDA-GDB lets you inspect all of them at runtime:
Thread hierarchy debugging
Back in puzzles 1-8, you wrote code like this:
# From puzzle 1: Basic thread indexing
i = thread_idx.x # Each thread gets a unique index
# From puzzle 7: 2D thread indexing
row = thread_idx.y # 2D grid of threads
col = thread_idx.x
With CUDA-GDB, you can actually see these thread coordinates in action:
(cuda-gdb) info cuda threads
outputs
BlockIdx ThreadIdx To BlockIdx To ThreadIdx Count PC Filename Line
Kernel 0
* (0,0,0) (0,0,0) (0,0,0) (3,0,0) 4 0x00007fffcf26fed0 /home/ubuntu/workspace/mojo-gpu-puzzles/solutions/p01/p01.mojo 13
and jump to a specific thread to see what it’s doing
(cuda-gdb) cuda thread (1,0,0)
shows
[Switching to CUDA thread (1,0,0)]
This is incredibly powerful - you can literally watch your parallel algorithm execute across different threads.
Memory space debugging
Remember puzzle 8 where you learned about different types of GPU memory? CUDA-GDB lets you inspect all of them:
# Examine global memory (the arrays from puzzles 1-5)
(cuda-gdb) print input_array[0]@4
$1 = {{1}, {2}, {3}, {4}} # Mojo scalar format
# Examine shared memory using local variables (thread_idx.x doesn't work)
(cuda-gdb) print shared_data[i] # Use local variable 'i' instead
$2 = {42}
The debugger shows you exactly what each thread sees in memory - perfect for catching race conditions or memory access bugs.
Strategic breakpoint placement
CUDA-GDB breakpoints are much more powerful than regular breakpoints because they work with parallel execution:
# Break when ANY thread enters your kernel
(cuda-gdb) break add_kernel
# Break only for specific threads (great for isolating issues)
(cuda-gdb) break add_kernel if thread_idx.x == 0
# Break on memory access violations
(cuda-gdb) watch input_array[thread_idx.x]
# Break on specific data conditions
(cuda-gdb) break add_kernel if input_array[thread_idx.x] > 100.0
This lets you focus on exactly the threads and conditions you care about, instead of drowning in output from thousands of threads.
Getting your environment ready
Before you can start debugging, ensure your development environment is properly configured. If you’ve been working through the earlier puzzles, most of this is already set up!
Note: Without pixi, you would need to manually install CUDA Toolkit from
NVIDIA’s official resources, manage
driver compatibility, configure environment variables, and handle version
conflicts between components. pixi eliminates this complexity by automatically
managing all CUDA dependencies, versions, and environment configuration for you.
Why pixi matters for debugging
The challenge: GPU debugging requires precise coordination between CUDA toolkit, GPU drivers, Mojo compiler, and debugger components. Version mismatches can lead to frustrating “debugger not found” errors.
The solution: Using pixi ensures all these components work together
harmoniously. When you run pixi run mojo debug --cuda-gdb, pixi automatically:
- Sets up CUDA toolkit paths
- Loads the correct GPU drivers
- Configures Mojo debugging plugins
- Manages environment variables consistently
Verifying your setup
Let’s check that everything is working:
# 1. Verify GPU hardware is accessible
pixi run nvidia-smi
# Should show your GPU(s) and driver version
# 2. Set up CUDA-GDB integration (required for GPU debugging)
pixi run setup-cuda-gdb
# Links system CUDA-GDB binaries to conda environment
# 3. Verify Mojo debugger is available
pixi run mojo debug --help
# Should show debugging options including --cuda-gdb
# 4. Test CUDA-GDB integration
pixi run cuda-gdb --version
# Should show NVIDIA CUDA-GDB version information
If any of these commands fail, double-check your pixi.toml configuration and
ensure the CUDA toolkit feature is enabled.
Important: The pixi run setup-cuda-gdb command is required because conda’s
cuda-gdb package only provides a wrapper script. This command auto-detects and
links the actual CUDA-GDB binaries from your system CUDA installation to the
conda environment, enabling full GPU debugging capabilities.
What this command does:
The script automatically detects CUDA from multiple common locations:
$CUDA_HOMEenvironment variable/usr/local/cuda(Ubuntu/Debian default)/opt/cuda(ArchLinux and other distributions)- System PATH (via
which cuda-gdb)
See
scripts/setup-cuda-gdb.sh
for implementation details.
Special note for WSL users: Both debug tools we will use in Part II (namely
cuda-gdb and compute-sanatizer) do support debugging CUDA applications on WSL,
but require you to add the registry key
HKEY_LOCAL_MACHINE\SOFTWARE\NVIDIA Corporation\GPUDebugger\EnableInterface and
set it to (DWORD) 1. More details on supported platforms and their OS specific
behavior can be found here:
cuda-gdb
and
compute-sanatizer
Hands-on tutorial: Your first GPU debugging session
Theory is great, but nothing beats hands-on experience. Let’s debug a real program using Puzzle 01 - the simple “add 10 to each array element” kernel you know well.
Why Puzzle 01? It’s the perfect debugging tutorial because:
- Simple enough to understand what should happen
- Real GPU code with actual kernel execution
- Contains both CPU setup code and GPU kernel code
- Short execution time so you can iterate quickly
By the end of this tutorial, you’ll have debugged the same program using all four debugging approaches, seen real debugger output, and learned the essential debugging commands you’ll use daily.
Learning path through the debugging approaches
We’ll explore the four debugging combinations using Puzzle 01 as our example. Learning path: We’ll start with JIT + LLDB (easiest), then progress to CUDA-GDB (most powerful).
⚠️ Important for GPU debugging:
- The
--break-on-launchflag is required for CUDA-GDB approaches - Pre-compiled binaries (Approaches 3 & 4) preserve local variables like
ifor debugging - JIT compilation (Approaches 1 & 2) optimizes away most local variables
- For serious GPU debugging, use Approach 4 (Binary + CUDA-GDB)
Tutorial step 1: CPU debugging with LLDB
Let’s begin with the most common debugging scenario: your program crashes or
behaves unexpectedly, and you need to see what’s happening in your main()
function.
The mission: Debug the CPU-side setup code in Puzzle 01 to understand how Mojo initializes GPU memory and launches kernels.
Launch the debugger
Fire up the LLDB debugger with JIT compilation:
# This compiles and debugs p01.mojo in one step
pixi run mojo debug solutions/p01/p01.mojo
You’ll see the LLDB prompt: (lldb). You’re now inside the debugger, ready to
inspect your program’s execution!
Your first debugging commands
Let’s trace through what happens when Puzzle 01 runs. Type these commands exactly as shown and observe the output:
Step 1: Set a breakpoint at the main function
(lldb) br set -n main
Output:
Breakpoint 1: where = mojo`main, address = 0x00000000027d7530
Or it may look like:
Breakpoint 1: no locations (pending).
WARNING: Unable to resolve breakpoint to any actual locations.
If the breakpoint appears as pending, this is expected. Mojo programs are JIT-compiled, which means the debugger may not be able to resolve symbols until the program begins execution. In this case the breakpoint is registered, but LLDB cannot yet bind it to a concrete instruction address.
Once execution starts and the module is compiled, LLDB resolves the breakpoint automatically.
In either case the breakpoint has been set successfully and execution will pause there once the program runs.
Step 2: Start your program
(lldb) run
Output:
Process 186951 launched: '/home/ubuntu/workspace/mojo-gpu-puzzles/.pixi/envs/default/bin/mojo' (x86_64)
Process 186951 stopped
* thread #1, name = 'mojo', stop reason = breakpoint 1.1
frame #0: 0x0000555557d2b530 mojo`main
mojo`main:
-> 0x555557d2b530 <+0>: pushq %rbp
0x555557d2b531 <+1>: movq %rsp, %rbp
...
The program has stopped at your breakpoint. You’re currently viewing assembly code, which is normal - the debugger starts at the low-level machine code before reaching your high-level Mojo source.
Step 3: Navigate through the startup process
# Try stepping through one instruction
(lldb) next
Output:
Process 186951 stopped
* thread #1, name = 'mojo', stop reason = instruction step over
frame #0: 0x0000555557d2b531 mojo`main + 1
mojo`main:
-> 0x555557d2b531 <+1>: movq %rsp, %rbp
0x555557d2b534 <+4>: pushq %r15
...
Stepping through assembly can be tedious. Let’s proceed to the more relevant parts.
Step 4: Continue to reach your Mojo source code
# Skip through the startup assembly to get to your actual code
(lldb) continue
Output:
Process 186951 resuming
Process 186951 stopped and restarted: thread 1 received signal: SIGCHLD
2 locations added to breakpoint 1
Process 186951 stopped
* thread #1, name = 'mojo', stop reason = breakpoint 1.3
frame #0: 0x00007fff5c01e841 JIT(0x7fff5c075000)`stdlib::builtin::_startup::__mojo_main_prototype(argc=([0] = 1), argv=0x00007fffffffa858) at _startup.mojo:95:4
Mojo’s runtime is initializing. The _startup.mojo indicates Mojo’s internal
startup code. The SIGCHLD signal is normal - it’s how Mojo manages its
internal processes.
Step 5: Continue to your actual code
# One more continue to reach your p01.mojo code!
(lldb) continue
Output:
Process 186951 resuming
Process 186951 stopped
* thread #1, name = 'mojo', stop reason = breakpoint 1.2
frame #0: 0x00007fff5c014040 JIT(0x7fff5c075000)`p01::main(__error__=<unavailable>) at p01.mojo:24:23
21
22
23 def main():
-> 24 with DeviceContext() as ctx:
25 out = ctx.enqueue_create_buffer[dtype](SIZE)
26 out.enqueue_fill(0)
27 a = ctx.enqueue_create_buffer[dtype](SIZE)
You can now view your actual Mojo source code. Notice:
- Line numbers 21-27 from your p01.mojo file
- Current line 24:
with DeviceContext() as ctx: - JIT compilation: The
JIT(0x7fff5c075000)indicates Mojo compiled your code just-in-time
Step 6: Let the program complete
# Let the program run to completion
(lldb) continue
Output:
Process 186951 resuming
out: HostBuffer([10.0, 11.0, 12.0, 13.0])
expected: HostBuffer([10.0, 11.0, 12.0, 13.0])
Process 186951 exited with status = 0 (0x00000000)
What you just learned
🎓 Congratulations! You’ve just completed your first GPU program debugging session. Here’s what happened:
The debugging journey you took:
- Started with assembly - Normal for low-level debugging, shows how the debugger works at machine level
- Navigated through Mojo startup - Learned that Mojo has internal initialization code
- Reached your source code - Saw your actual p01.mojo lines 21-27 with syntax highlighting
- Watched JIT compilation - Observed Mojo compiling your code on-the-fly
- Verified successful execution - Confirmed your program produces the expected output
LLDB debugging provides:
- ✅ CPU-side visibility: See your
main()function, buffer allocation, memory setup - ✅ Source code inspection: View your actual Mojo code with line numbers
- ✅ Variable examination: Check values of host-side variables (CPU memory)
- ✅ Program flow control: Step through your setup logic line by line
- ✅ Error investigation: Debug crashes in device setup, memory allocation, etc.
What LLDB cannot do:
- ❌ GPU kernel inspection: Cannot step into
add_10function execution - ❌ Thread-level debugging: Cannot see individual GPU thread behavior
- ❌ GPU memory access: Cannot examine data as GPU threads see it
- ❌ Parallel execution analysis: Cannot debug race conditions or synchronization
When to use LLDB debugging:
- Your program crashes before the GPU code runs
- Buffer allocation or memory setup issues
- Understanding program initialization and flow
- Learning how Mojo applications start up
- Quick prototyping and experimenting with code changes
Key insight: LLDB is perfect for host-side debugging - everything that happens on your CPU before and after GPU execution. For the actual GPU kernel debugging, you need our next approach…
Tutorial step 2: Binary debugging
You’ve learned JIT debugging - now let’s explore the professional approach used in production environments.
The scenario: You’re debugging a complex application with multiple files, or you need to debug the same program repeatedly. Building a binary first provides more control and faster debugging iterations.
Build your debug binary
Step 1: Compile with debug information
# Create a debug build (notice the clear naming)
pixi run mojo build -O0 -g solutions/p01/p01.mojo -o solutions/p01/p01_debug
What happens here:
- 🔧
-O0: Disables optimizations (critical for accurate debugging) - 🔍
-g: Includes debug symbols mapping machine code to source code - 📁
-o p01_debug: Creates a clearly named debug binary
Step 2: Debug the binary
# Debug the pre-built binary
pixi run mojo debug solutions/p01/p01_debug
What’s different (and better)
Startup comparison:
| JIT Debugging | Binary Debugging |
|---|---|
| Compile + debug in one step | Build once, debug many times |
| Slower startup (compilation overhead) | Faster startup |
| Compilation messages mixed with debug output | Clean debugger output |
| Debug symbols generated during debugging | Fixed debug symbols |
When you run the same LLDB commands (br set -n main, run, continue),
you’ll notice:
- Faster startup - no compilation delay
- Cleaner output - no JIT compilation messages
- More predictable - debug symbols don’t change between runs
- Professional workflow - this is how production debugging works
Tutorial step 3: Debugging the GPU kernel
So far, you’ve debugged the CPU host code - the setup, memory allocation, and initialization. But what about the actual GPU kernel where the parallel computation happens?
The challenge: Your add_10 kernel runs on the GPU with potentially
thousands of threads executing simultaneously. LLDB can’t reach into the GPU’s
parallel execution environment.
The solution: CUDA-GDB - a specialized debugger that understands GPU threads, GPU memory, and parallel execution.
Why you need CUDA-GDB
Let’s understand what makes GPU debugging fundamentally different:
CPU debugging (LLDB):
- One thread executing sequentially
- Single call stack to follow
- Straightforward memory model
- Variables have single values
GPU debugging (CUDA-GDB):
- Thousands of threads executing in parallel
- Multiple call stacks (one per thread)
- Complex memory hierarchy (global, shared, local, registers)
- Same variable has different values across threads
Real example: In your add_10 kernel, the variable thread_idx.x has a
different value in every thread - thread 0 sees 0, thread 1 sees 1, etc.
Only CUDA-GDB can show you this parallel reality.
Launch CUDA-GDB debugger
Step 1: Start GPU kernel debugging
Choose your approach:
# Make sure you've run this already (once is enough)
pixi run setup-cuda-gdb
# We'll use JIT + CUDA-GDB (Approach 2 from above)
pixi run mojo debug --cuda-gdb --break-on-launch solutions/p01/p01.mojo
We’ll use the JIT + CUDA-GDB approach since it’s perfect for learning and quick iterations.
Step 2: Launch and automatically stop at GPU kernel entry
The CUDA-GDB prompt looks like: (cuda-gdb). Start the program:
# Run the program - it automatically stops when the GPU kernel launches
(cuda-gdb) run
Output:
Starting program: /home/ubuntu/workspace/mojo-gpu-puzzles/.pixi/envs/default/bin/mojo...
[Thread debugging using libthread_db enabled]
...
[Switching focus to CUDA kernel 0, grid 1, block (0,0,0), thread (0,0,0)]
CUDA thread hit application kernel entry function breakpoint, p01_add_10_UnsafePointer...
<<<(1,1,1),(4,1,1)>>> (output=0x302000000, a=0x302000200) at p01.mojo:16
16 i = thread_idx.x
Success! You’re automatically stopped inside the GPU kernel! The
--break-on-launch flag caught the kernel launch and you’re now at line 16
where i = thread_idx.x executes.
Important: You don’t need to manually set breakpoints like
break add_10 - the kernel entry breakpoint is automatic. GPU kernel functions
have mangled names in CUDA-GDB (like p01_add_10_UnsafePointer...), but you’re
already inside the kernel and can start debugging immediately.
Step 3: Explore the parallel execution
# See all the GPU threads that are paused at your breakpoint
(cuda-gdb) info cuda threads
Output:
BlockIdx ThreadIdx To BlockIdx To ThreadIdx Count PC Filename Line
Kernel 0
* (0,0,0) (0,0,0) (0,0,0) (3,0,0) 4 0x00007fffd326fb70 /home/ubuntu/workspace/mojo-gpu-puzzles/solutions/p01/p01.mojo 16
Perfect! This shows you all 4 parallel GPU threads from Puzzle 01:
*marks your current thread:(0,0,0)- the thread you’re debugging- Thread range: From
(0,0,0)to(3,0,0)- all 4 threads in the block - Count:
4- matchesTHREADS_PER_BLOCK = 4from the code - Same location: All threads are paused at line 16 in
p01.mojo
Step 4: Step through the kernel and examine variables
# Use 'next' to step through code (not 'step' which goes into internals)
(cuda-gdb) next
Output:
p01_add_10_UnsafePointer... at p01.mojo:17
17 output[i] = a[i] + 10.0
# Local variables work with pre-compiled binaries!
(cuda-gdb) print i
Output:
$1 = 0 # This thread's index (captures thread_idx.x value)
# GPU built-ins don't work, but you don't need them
(cuda-gdb) print thread_idx.x
Output:
No symbol "thread_idx" in current context.
# Access thread-specific data using local variables
(cuda-gdb) print a[i] # This thread's input: a[0]
Output:
$2 = {0} # Input value (Mojo scalar format)
(cuda-gdb) print output[i] # This thread's output BEFORE computation
Output:
$3 = {0} # Still zero - computation hasn't executed yet!
# Execute the computation line
(cuda-gdb) next
Output:
13 fn add_10( # Steps to function signature line after computation
# Now check the result
(cuda-gdb) print output[i]
Output:
$4 = {10} # Now shows the computed result: 0 + 10 = 10
# Function parameters are still available
(cuda-gdb) print a
Output:
$5 = (!pop.scalar<f32> * @register) 0x302000200
Step 5: Navigate between parallel threads
# Switch to a different thread to see its execution
(cuda-gdb) cuda thread (1,0,0)
Output:
[Switching focus to CUDA kernel 0, grid 1, block (0,0,0), thread (1,0,0), device 0, sm 0, warp 0, lane 1]
13 fn add_10( # Thread 1 is also at function signature
# Check the thread's local variable
(cuda-gdb) print i
Output:
$5 = 1 # Thread 1's index (different from Thread 0!)
# Examine what this thread processes
(cuda-gdb) print a[i] # This thread's input: a[1]
Output:
$6 = {1} # Input value for thread 1
# Thread 1's computation is already done (parallel execution!)
(cuda-gdb) print output[i] # This thread's output: output[1]
Output:
$7 = {11} # 1 + 10 = 11 (already computed)
# BEST TECHNIQUE: View all thread results at once
(cuda-gdb) print output[0]@4
Output:
$8 = {{10}, {11}, {12}, {13}} # All 4 threads' results in one command!
(cuda-gdb) print a[0]@4
Output:
$9 = {{0}, {1}, {2}, {3}} # All input values for comparison
# Don't step too far or you'll lose CUDA context
(cuda-gdb) next
Output:
[Switching to Thread 0x7ffff7e25840 (LWP 306942)] # Back to host thread
0x00007fffeca3f831 in ?? () from /lib/x86_64-linux-gnu/libcuda.so.1
(cuda-gdb) print output[i]
Output:
No symbol "output" in current context. # Lost GPU context!
Key insights from this debugging session:
- 🤯 Parallel execution is real - when you switch to thread (1,0,0), its computation is already done!
- Each thread has different data -
i=0vsi=1,a[i]={0}vsa[i]={1},output[i]={10}vsoutput[i]={11} - Array inspection is powerful -
print output[0]@4shows all threads’ results:{{10}, {11}, {12}, {13}} - GPU context is fragile - stepping too far switches back to host thread and loses GPU variables
This demonstrates the fundamental nature of parallel computing: same code, different data per thread, executing simultaneously.
What you’ve learned with CUDA-GDB
You’ve completed GPU kernel execution debugging with pre-compiled binaries. Here’s what actually works:
GPU debugging capabilities you gained:
- ✅ Debug GPU kernels automatically -
--break-on-launchstops at kernel entry - ✅ Navigate between GPU threads - switch contexts with
cuda thread - ✅ Access local variables -
print iworks with-O0 -gcompiled binaries - ✅ Inspect thread-specific data - each thread shows different
i,a[i],output[i]values - ✅ View all thread results -
print output[0]@4shows{{10}, {11}, {12}, {13}}in one command - ✅ Step through GPU code -
nextexecutes computation and shows results - ✅ See parallel execution - threads execute simultaneously (other threads already computed when you switch)
- ✅ Access function parameters - examine
outputandapointers - ❌ GPU built-ins unavailable -
thread_idx.x,blockIdx.xetc. don’t work (but local variables do!) - 📊 Mojo scalar format - values display as
{10}instead of10.0 - ⚠️ Fragile GPU context - stepping too far loses access to GPU variables
Key insights:
- Pre-compiled binaries (
mojo build -O0 -g) are essential - local variables preserved - Array inspection with
@N- most efficient way to see all parallel results at once - GPU built-ins are missing - but local variables like
icapture what you need - Mojo uses
{value}format - scalars display as{10}instead of10.0 - Be careful with stepping - easy to lose GPU context and return to host thread
Real-world debugging techniques
Now let’s explore practical debugging scenarios you’ll encounter in real GPU programming:
Technique 1: Verifying thread boundaries
# Check if all 4 threads computed correctly
(cuda-gdb) print output[0]@4
Output:
$8 = {{10}, {11}, {12}, {13}} # All 4 threads computed correctly
# Check beyond valid range to detect out-of-bounds issues
(cuda-gdb) print output[0]@5
Output:
$9 = {{10}, {11}, {12}, {13}, {0}} # Element 4 is uninitialized (good!)
# Compare with input to verify computation
(cuda-gdb) print a[0]@4
Output:
$10 = {{0}, {1}, {2}, {3}} # Input values: 0+10=10, 1+10=11, etc.
Why this matters: Out-of-bounds access is the #1 cause of GPU crashes. These debugging steps catch it early.
Technique 2: Understanding thread organization
# See how your threads are organized into blocks
(cuda-gdb) info cuda blocks
Output:
BlockIdx To BlockIdx Count State
Kernel 0
* (0,0,0) (0,0,0) 1 running
# See all threads in the current block
(cuda-gdb) info cuda threads
Output shows which threads are active, stopped, or have errors.
Why this matters: Understanding thread block organization helps debug synchronization and shared memory issues.
Technique 3: Memory access pattern analysis
# Check GPU memory addresses:
(cuda-gdb) print a # Input array GPU pointer
Output:
$9 = (!pop.scalar<f32> * @register) 0x302000200
(cuda-gdb) print output # Output array GPU pointer
Output:
$10 = (!pop.scalar<f32> * @register) 0x302000000
# Verify memory access pattern using local variables:
(cuda-gdb) print a[i] # Each thread accesses its own element using 'i'
Output:
$11 = {0} # Thread's input data
Why this matters: Memory access patterns affect performance and correctness. Wrong patterns cause race conditions or crashes.
Technique 4: Results verification and completion
# After stepping through kernel execution, verify the final results
(cuda-gdb) print output[0]@4
Output:
$11 = {10.0, 11.0, 12.0, 13.0} # Perfect! Each element increased by 10
# Let the program complete normally
(cuda-gdb) continue
Output:
...Program output shows success...
# Exit the debugger
(cuda-gdb) exit
You’ve completed debugging a GPU kernel execution from setup to results.
Your GPU debugging progress: key insights
You’ve completed a comprehensive GPU debugging tutorial. Here’s what you discovered about parallel computing:
Deep insights about parallel execution
-
Thread indexing in action: You saw
thread_idx.xhave different values (0, 1, 2, 3…) across parallel threads - not just read about it in theory -
Memory access patterns revealed: Each thread accesses
a[thread_idx.x]and writes tooutput[thread_idx.x], creating perfect data parallelism with no conflicts -
Parallel execution demystified: Thousands of threads executing the same kernel code simultaneously, but each processing different data elements
-
GPU memory hierarchy: Arrays live in global GPU memory, accessible by all threads but with thread-specific indexing
Debugging techniques that transfer to all puzzles
From Puzzle 01 to Puzzle 08 and beyond, you now have techniques that work universally:
- Start with LLDB for CPU-side issues (device setup, memory allocation)
- Switch to CUDA-GDB for GPU kernel issues (thread behavior, memory access)
- Use conditional breakpoints to focus on specific threads or data conditions
- Navigate between threads to understand parallel execution patterns
- Verify memory access patterns to catch race conditions and out-of-bounds errors
Scalability: These same techniques work whether you’re debugging:
- Puzzle 01: 4-element arrays with simple addition
- Puzzle 08: Complex shared memory operations with thread synchronization
- Production code: Million-element arrays with sophisticated algorithms
Essential debugging commands reference
Now that you’ve learned the debugging workflow, here’s your quick reference guide for daily debugging sessions. Bookmark this section!
GDB command abbreviations (save time!)
Most commonly used shortcuts for faster debugging:
| Abbreviation | Full Command | Function |
|---|---|---|
r | run | Start/launch the program |
c | continue | Resume execution |
n | next | Step over (same level) |
s | step | Step into functions |
b | break | Set breakpoint |
p | print | Print variable value |
l | list | Show source code |
q | quit | Exit debugger |
Examples:
(cuda-gdb) r # Instead of 'run'
(cuda-gdb) b 39 # Instead of 'break 39'
(cuda-gdb) p thread_id # Instead of 'print thread_id'
(cuda-gdb) n # Instead of 'next'
(cuda-gdb) c # Instead of 'continue'
⚡ Pro tip: Use abbreviations for 3-5x faster debugging sessions!
LLDB commands (CPU host code debugging)
When to use: Debugging device setup, memory allocation, program flow, host-side crashes
Execution control
(lldb) run # Launch your program
(lldb) continue # Resume execution (alias: c)
(lldb) step # Step into functions (source level)
(lldb) next # Step over functions (source level)
(lldb) finish # Step out of current function
Breakpoint management
(lldb) br set -n main # Set breakpoint at main function
(lldb) br set -n function_name # Set breakpoint at any function
(lldb) br list # Show all breakpoints
(lldb) br delete 1 # Delete breakpoint #1
(lldb) br disable 1 # Temporarily disable breakpoint #1
Variable inspection
(lldb) print variable_name # Show variable value
(lldb) print pointer[offset] # Dereference pointer
(lldb) print array[0]@4 # Show first 4 array elements
CUDA-GDB commands (GPU kernel debugging)
When to use: Debugging GPU kernels, thread behavior, parallel execution, GPU memory issues
GPU state inspection
(cuda-gdb) info cuda threads # Show all GPU threads and their state
(cuda-gdb) info cuda blocks # Show all thread blocks
(cuda-gdb) cuda kernel # List active GPU kernels
Thread navigation (The most powerful feature!)
(cuda-gdb) cuda thread (0,0,0) # Switch to specific thread coordinates
(cuda-gdb) cuda block (0,0) # Switch to specific block
(cuda-gdb) cuda thread # Show current thread coordinates
Thread-specific variable inspection
# Local variables and function parameters:
(cuda-gdb) print i # Local thread index variable
(cuda-gdb) print output # Function parameter pointers
(cuda-gdb) print a # Function parameter pointers
GPU memory access
# Array inspection using local variables (what actually works):
(cuda-gdb) print array[i] # Thread-specific array access using local variable
(cuda-gdb) print array[0]@4 # View multiple elements: {{val1}, {val2}, {val3}, {val4}}
Advanced GPU debugging
# Memory watching
(cuda-gdb) watch array[i] # Break on memory changes
(cuda-gdb) rwatch array[i] # Break on memory reads
Quick reference: Debugging decision tree
🤔 What type of issue are you debugging?
Program crashes before GPU code runs
→ Use LLDB debugging
pixi run mojo debug your_program.mojo
GPU kernel produces wrong results
→ Use CUDA-GDB with conditional breakpoints
pixi run mojo debug --cuda-gdb --break-on-launch your_program.mojo
Performance issues or race conditions
→ Use binary debugging for repeatability
pixi run mojo build -O0 -g your_program.mojo -o debug_binary
pixi run mojo debug --cuda-gdb --break-on-launch debug_binary
You’ve learned the essentials of GPU debugging
You’ve completed a comprehensive tutorial on GPU debugging fundamentals. Here’s what you’ve accomplished:
Skills you’ve learned
Multi-level debugging knowledge:
- ✅ CPU host debugging with LLDB - debug device setup, memory allocation, program flow
- ✅ GPU kernel debugging with CUDA-GDB - debug parallel threads, GPU memory, race conditions
- ✅ JIT vs binary debugging - choose the right approach for different scenarios
- ✅ Environment management with pixi - ensure consistent, reliable debugging setups
Real parallel programming insights:
- Saw threads in action - witnessed
thread_idx.xhaving different values across parallel threads - Understood memory hierarchy - debugged global GPU memory, shared memory, thread-local variables
- Learned thread navigation - jumped between thousands of parallel threads efficiently
From theory to practice
You didn’t just read about GPU debugging - you experienced it:
- Debugged real code: Puzzle 01’s
add_10kernel with actual GPU execution - Saw real debugger output: LLDB assembly, CUDA-GDB thread states, memory addresses
- Used professional tools: The same CUDA-GDB used in production GPU development
- Solved real scenarios: Out-of-bounds access, race conditions, kernel launch failures
Your debugging toolkit
Quick decision guide (keep this handy!):
| Problem Type | Tool | Command |
|---|---|---|
| Program crashes before GPU | LLDB | pixi run mojo debug program.mojo |
| GPU kernel issues | CUDA-GDB | pixi run mojo debug --cuda-gdb --break-on-launch program.mojo |
| Race conditions | CUDA-GDB + thread nav | (cuda-gdb) cuda thread (0,0,0) |
Essential commands (for daily debugging):
# GPU thread inspection
(cuda-gdb) info cuda threads # See all threads
(cuda-gdb) cuda thread (0,0,0) # Switch threads
(cuda-gdb) print i # Local thread index (thread_idx.x equivalent)
# Smart breakpoints (using local variables since GPU built-ins don't work)
(cuda-gdb) break kernel if i == 0 # Focus on thread 0
(cuda-gdb) break kernel if array[i] > 100 # Focus on data conditions
# Memory debugging
(cuda-gdb) print array[i] # Thread-specific data using local variable
(cuda-gdb) print array[0]@4 # Array segments: {{val1}, {val2}, {val3}, {val4}}
Summary
GPU debugging involves thousands of parallel threads, complex memory hierarchies, and specialized tools. You now have:
- Systematic workflows that work for any GPU program
- Professional tools familiarity with LLDB and CUDA-GDB
- Real experience debugging actual parallel code
- Practical strategies for handling complex scenarios
- Foundation to tackle GPU debugging challenges
Additional resources
- Mojo Debugging Documentation
- Mojo GPU Debugging Guide
- NVIDIA CUDA-GDB User Guide
- CUDA-GDB Command Reference
Note: GPU debugging requires patience and systematic investigation. The workflow and commands in this puzzle provide the foundation for debugging complex GPU issues you’ll encounter in real applications.
🧐 Detective Work: First Case
Overview
This puzzle presents a crashing GPU program where your task is to identify the
issue using only (cuda-gdb) debugging tools, without examining the source
code. Apply your debugging skills to solve the mystery!
Prerequisites: Complete Mojo GPU Debugging Essentials to understand CUDA-GDB setup and basic debugging commands. Make sure you’ve run:
pixi run -e nvidia setup-cuda-gdb
This auto-detects your CUDA installation and sets up the necessary links for GPU debugging.
Key concepts
In this debugging challenge, you’ll learn about:
- Systematic debugging: Using error messages as clues to find root causes
- Error analysis: Reading crash messages and stack traces
- Hypothesis formation: Making educated guesses about the problem
- Debugging workflow: Step-by-step investigation process
Running the code
First, examine the kernel without looking at the complete code:
def add_10(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
):
var i = thread_idx.x
output[i] = a[i] + 10.0
To experience the bug firsthand, run the following command in your terminal
(pixi only):
pixi run -e nvidia p09 --first-case
You’ll see output like this when the program crashes:
First Case: Try to identify what's wrong without looking at the code!
stack trace was not collected. Enable stack trace collection with environment variable `MOJO_ENABLE_STACK_TRACE_ON_ERROR`
Unhandled exception caught during execution: At open-source/max/mojo/stdlib/stdlib/gpu/host/device_context.mojo:2082:17: CUDA call failed: CUDA_ERROR_INVALID_IMAGE (device kernel image is invalid)
To get more accurate error information, set MODULAR_DEVICE_CONTEXT_SYNC_MODE=true.
/home/ubuntu/workspace/mojo-gpu-puzzles/.pixi/envs/nvidia/bin/mojo: error: execution exited with a non-zero result: 1
Your task: detective work
Challenge: Without looking at the code yet, what would be your debugging strategy to investigate this crash?
Start with:
pixi run -e nvidia mojo debug --cuda-gdb --break-on-launch problems/p09/p09.mojo --first-case
Tips
- Read the crash message carefully -
CUDA_ERROR_ILLEGAL_ADDRESSmeans the GPU tried to access invalid memory - Check the breakpoint information - Look at the function parameters shown when CUDA-GDB stops
- Inspect all pointers systematically - Use
printto examine each pointer parameter - Look for suspicious addresses - Valid GPU addresses are typically large
hex numbers (what does
0x0mean?) - Test memory access - Try accessing the data through each pointer to see which one fails
- Apply the systematic approach - Like a detective, follow the evidence from symptom to root cause
- Compare valid vs invalid patterns - If one pointer works and another doesn’t, focus on the broken one
💡 Investigation & Solution
Step-by-Step Investigation with CUDA-GDB
Launch the Debugger
pixi run -e nvidia mojo debug --cuda-gdb --break-on-launch problems/p09/p09.mojo --first-case
Examine the Breakpoint Information
When CUDA-GDB stops, it immediately shows valuable clues:
(cuda-gdb) run
CUDA thread hit breakpoint, p09_add_10_... (output=0x302000000, a=0x0)
at /home/ubuntu/workspace/mojo-gpu-puzzles/problems/p09/p09.mojo:31
31 i = thread_idx.x
🔍 First Clue: The function signature shows (output=0x302000000, a=0x0)
outputhas a valid GPU memory addressais0x0- this is a null pointer!
Systematic variable inspection
(cuda-gdb) next
32 output[i] = a[i] + 10.0
(cuda-gdb) print i
$1 = 0
(cuda-gdb) print output
$2 = (!pop.scalar<f32> * @register) 0x302000000
(cuda-gdb) print a
$3 = (!pop.scalar<f32> * @register) 0x0
Evidence Gathering:
- ✅ Thread index
i=0is valid - ✅ Result pointer
0x302000000is a proper GPU address - ❌ Input pointer
0x0is null
Confirm the Problem
(cuda-gdb) print a[i]
Cannot access memory at address 0x0
Smoking Gun: Cannot access memory at null address - this confirms the crash cause!
Root cause analysis
The Problem: Now if we look at the code
for --first-crash, we see that the host code creates a null pointer instead of
allocating proper GPU memory:
input_buf = ctx.enqueue_create_buffer[dtype](0) # Creates a `DeviceBuffer` with 0 elements. Since there are zero elements, no memory is allocated, which results in a NULL pointer!
Why This Crashes:
ctx.enqueue_create_buffer[dtype](0)creates aDeviceBufferwith zero (0) elements.- since there are no elements for which to allocate memory, this returns a null pointer.
- This null pointer gets passed to the GPU kernel
- When kernel tries
a[i], it dereferences null →CUDA_ERROR_ILLEGAL_ADDRESS
The fix
Replace null pointer creation with proper buffer allocation:
# Wrong: Creates null pointer
input_buf = ctx.enqueue_create_buffer[dtype](0)
# Correct: Allocates and initialize actual GPU memory for safe processing
input_buf = ctx.enqueue_create_buffer[dtype](SIZE)
input_buf.enqueue_fill(0)
Key debugging lessons
Pattern Recognition:
0x0addresses are always null pointers- Valid GPU addresses are large hex numbers (e.g.,
0x302000000)
Debugging Strategy:
- Read crash messages - They often hint at the problem type
- Check function parameters - CUDA-GDB shows them at breakpoint entry
- Inspect all pointers - Compare addresses to identify null/invalid ones
- Test memory access - Try dereferencing suspicious pointers
- Trace back to allocation - Find where the problematic pointer was created
💡 Key Insight: This type of null pointer bug is extremely common in GPU programming. The systematic CUDA-GDB investigation approach you learned here applies to debugging many other GPU memory issues, race conditions, and kernel crashes.
Next steps: from crashes to silent bugs
You’ve learned crash debugging! You can now:
- Systematically investigate GPU crashes using error messages as clues
- Identify null pointer bugs through pointer address inspection
- Use CUDA-GDB effectively for memory-related debugging
Your next challenge: Detective Work: Second Case
But what if your program doesn’t crash? What if it runs perfectly but produces wrong results?
The Second Case presents a completely different debugging challenge:
- No crash messages to guide you
- No obvious pointer problems to investigate
- No stack traces pointing to the issue
- Just wrong results that need systematic investigation
New skills you’ll develop:
- Logic bug detection - Finding algorithmic errors without crashes
- Pattern analysis - Using incorrect output to trace back to root causes
- Execution flow debugging - When variable inspection fails due to optimizations
The systematic investigation approach you learned here - reading clues, forming hypotheses, testing systematically - forms the foundation for debugging the more subtle logic errors ahead.
🔍 Detective Work: Second Case
Overview
Building on your crash debugging skills from the First Case, you’ll now face a completely different challenge: a logic bug that produces incorrect results without crashing.
The debugging shift:
- First Case: Clear crash signals
(
CUDA_ERROR_ILLEGAL_ADDRESS) guided your investigation - Second Case: No crashes, no error messages - just subtly wrong results that require detective work
This intermediate-level debugging challenge covers investigating
algorithmic errors using TileTensor operations, where the program runs
successfully but produces wrong output - a much more common (and trickier)
real-world debugging scenario.
Prerequisites: Complete Mojo GPU Debugging Essentials and Detective Work: First Case to understand CUDA-GDB workflow and systematic debugging techniques. Make sure you run the setup:
pixi run -e nvidia setup-cuda-gdb
Key concepts
In this debugging challenge, you’ll learn about:
- TileTensor debugging: Investigating structured data access patterns
- Logic bug detection: Finding algorithmic errors that don’t crash
- Loop boundary analysis: Understanding iteration count problems
- Result pattern analysis: Using output data to trace back to root causes
Running the code
First, examine the kernel without looking at the complete code:
def process_sliding_window(
output: TileTensor[mut=True, dtype, VectorLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, VectorLayout, ImmutAnyOrigin],
):
var thread_id = thread_idx.x
# Each thread processes a sliding window of 3 elements
var window_sum = Scalar[dtype](0.0)
# Sum elements in sliding window: [i-1, i, i+1]
for offset in range(ITER):
var idx = Int(thread_id) + offset - 1
if 0 <= idx < SIZE:
var value = rebind[Scalar[dtype]](a[idx])
window_sum += value
output[thread_id] = window_sum
To experience the bug firsthand, run the following command in your terminal
(pixi only):
pixi run -e nvidia p09 --second-case
You’ll see output like this - no crash, but wrong results:
This program computes sliding window sums for each position...
Input array: [0, 1, 2, 3]
Computing sliding window sums (window size = 3)...
Each position should sum its neighbors: [left + center + right]
stack trace was not collected. Enable stack trace collection with environment variable `MOJO_ENABLE_STACK_TRACE_ON_ERROR`
Unhandled exception caught during execution: At open-source/max/mojo/stdlib/stdlib/gpu/host/device_context.mojo:2082:17: CUDA call failed: CUDA_ERROR_INVALID_IMAGE (device kernel image is invalid)
To get more accurate error information, set MODULAR_DEVICE_CONTEXT_SYNC_MODE=true.
/home/ubuntu/workspace/mojo-gpu-puzzles/.pixi/envs/nvidia/bin/mojo: error: execution exited with a non-zero result: 1
Your task: detective work
Challenge: The program runs without crashing but produces consistently wrong results. Without looking at the code, what would be your systematic approach to investigate this logic bug?
Think about:
- What pattern do you see in the wrong results?
- How would you investigate a loop that might not be running correctly?
- What debugging strategy works when you can’t inspect variables directly?
- How can you apply the systematic investigation approach from First Case when there are no crash signals to guide you?
Start with:
pixi run -e nvidia mojo debug --cuda-gdb --break-on-launch problems/p09/p09.mojo --second-case
GDB command shortcuts (faster debugging)
Use these abbreviations to speed up your debugging session:
| Short | Full | Usage Example |
|---|---|---|
r | run | (cuda-gdb) r |
n | next | (cuda-gdb) n |
c | continue | (cuda-gdb) c |
b | break | (cuda-gdb) b 39 |
p | print | (cuda-gdb) p thread_id |
q | quit | (cuda-gdb) q |
All debugging commands below use these shortcuts for efficiency!
Tips
- Pattern analysis first - Look at the relationship between expected and actual results (what’s the mathematical pattern in the differences?)
- Focus on execution flow - Count loop iterations when variables aren’t accessible
- Use simple breakpoints - Complex debugging commands often fail with optimized code
- Mathematical reasoning - Work out what each thread should access vs what it actually accesses
- Missing data investigation - If results are consistently smaller than expected, what might be missing?
- Host output verification - The final results often reveal the pattern of the bug
- Algorithm boundary analysis - Check if loops are processing the right number of elements
- Cross-validate with working cases - Why does thread 3 work correctly but others don’t?
💡 Investigation & Solution
Step-by-step investigation with CUDA-GDB
Phase 1: Launch and initial analysis
Step 1: Start the debugger
pixi run -e nvidia mojo debug --cuda-gdb --break-on-launch problems/p09/p09.mojo --second-case
Step 2: analyze the symptoms first
Before diving into the debugger, examine what we know:
Actual result: [0.0, 1.0, 3.0, 5.0]
Expected: [1.0, 3.0, 6.0, 5.0]
🔍 Pattern Recognition:
- Thread 0: Got 0.0, Expected 1.0 → Missing 1.0
- Thread 1: Got 1.0, Expected 3.0 → Missing 2.0
- Thread 2: Got 3.0, Expected 6.0 → Missing 3.0
- Thread 3: Got 5.0, Expected 5.0 → ✅ Correct
Initial Hypothesis: Each thread is missing some data, but thread 3 works correctly.
Phase 2: Entering the kernel
Step 3: Observe the breakpoint entry
Based on the real debugging session, here’s what happens:
(cuda-gdb) r
Starting program: .../mojo run problems/p09/p09.mojo --second-case
This program computes sliding window sums for each position...
Input array: [0, 1, 2, 3]
Computing sliding window sums (window size = 3)...
Each position should sum its neighbors: [left + center + right]
[Switching focus to CUDA kernel 0, grid 1, block (0,0,0), thread (0,0,0), device 0, sm 0, warp 0, lane 0]
CUDA thread hit application kernel entry function breakpoint, p09_process_sliding_window_...
<<<(1,1,1),(4,1,1)>>> (output=..., a=...)
at /home/ubuntu/workspace/mojo-gpu-puzzles/problems/p09/p09.mojo:36
36 a: TileTensor[mut=False, dtype, VectorLayout, ImmutAnyOrigin],
Step 4: Navigate to the main logic
(cuda-gdb) n
35 output: TileTensor[mut=True, dtype, VectorLayout, MutAnyOrigin],
(cuda-gdb) n
38 var thread_id = thread_idx.x
(cuda-gdb) n
44 for offset in range(ITER):
Step 5: Test variable accessibility - crucial discovery
(cuda-gdb) p thread_id
$1 = 0
✅ Good: Thread ID is accessible.
(cuda-gdb) p window_sum
Cannot access memory at address 0x0
❌ Problem: window_sum is not accessible.
(cuda-gdb) p a[0]
Attempt to take address of value not located in memory.
❌ Problem: Direct TileTensor indexing doesn’t work.
(cuda-gdb) p a.ptr[0]
$2 = {0}
(cuda-gdb) p a.ptr[0]@4
$3 = {{0}, {1}, {2}, {3}}
🎯 BREAKTHROUGH: a.ptr[0]@4 shows the full input array! This is how we can
inspect TileTensor data.
Phase 3: The critical loop investigation
Step 6: Set up loop monitoring
(cuda-gdb) b 45
Breakpoint 1 at 0x7fffd326ffd0: file problems/p09/p09.mojo, line 45.
(cuda-gdb) c
Continuing.
CUDA thread hit Breakpoint 1, p09_process_sliding_window_...
<<<(1,1,1),(4,1,1)>>> (output=..., a=...)
at /home/ubuntu/workspace/mojo-gpu-puzzles/problems/p09/p09.mojo:45
45 var idx = Int(thread_id) + offset - 1
🔍 We’re now inside the loop body. Let’s count iterations manually.
Step 7: First loop iteration (offset = 0)
(cuda-gdb) n
46 if 0 <= idx < SIZE:
(cuda-gdb) n
44 for offset in range(ITER):
First iteration complete: Loop went from line 45 → 46 → back to 44. The loop continues.
Step 8: Second loop iteration (offset = 1)
(cuda-gdb) n
CUDA thread hit Breakpoint 1, p09_process_sliding_window_...
45 var idx = Int(thread_id) + offset - 1
(cuda-gdb) n
46 if 0 <= idx < SIZE:
(cuda-gdb) n
47 var value = rebind[Scalar[dtype]](a[idx])
(cuda-gdb) n
48 window_sum += value
(cuda-gdb) n
46 if 0 <= idx < SIZE:
(cuda-gdb) n
44 for offset in range(ITER):
Second iteration complete: This time it went through the if-block (lines 47-48).
Step 9: testing for third iteration
(cuda-gdb) n
50 output[thread_id] = window_sum
CRITICAL DISCOVERY: The loop exited after only 2 iterations! It went directly to line 50 instead of hitting our breakpoint at line 45 again.
Conclusion: The loop ran exactly 2 iterations and then exited.
Step 10: Complete kernel execution and context loss
(cuda-gdb) n
34 def process_sliding_window(
(cuda-gdb) n
[Switching to Thread 0x7ffff7cc0e00 (LWP 110927)]
0x00007ffff064f84a in ?? () from /lib/x86_64-linux-gnu/libcuda.so.1
(cuda-gdb) p output.ptr[0]@4
No symbol "output" in current context.
(cuda-gdb) p offset
No symbol "offset" in current context.
🔍 Context Lost: After kernel completion, we lose access to kernel variables. This is normal behavior.
Phase 4: Root cause analysis
Step 11: Algorithm analysis from observed execution
From our debugging session, we observed:
- Loop Iterations: Only 2 iterations (offset = 0, offset = 1)
- Expected: A sliding window of size 3 should require 3 iterations (offset = 0, 1, 2)
- Missing: The third iteration (offset = 2)
Looking at what each thread should compute:
- Thread 0: window_sum = a[-1] + a[0] + a[1] = (boundary) + 0 + 1 = 1.0
- Thread 1: window_sum = a[0] + a[1] + a[2] = 0 + 1 + 2 = 3.0
- Thread 2: window_sum = a[1] + a[2] + a[3] = 1 + 2 + 3 = 6.0
- Thread 3: window_sum = a[2] + a[3] + a[4] = 2 + 3 + (boundary) = 5.0
Step 12: Trace the actual execution for thread 0
With only 2 iterations (offset = 0, 1):
Iteration 1 (offset = 0):
idx = thread_id + offset - 1 = 0 + 0 - 1 = -1if 0 <= idx < SIZE:→if 0 <= -1 < 4:→ False- Skip the sum operation
Iteration 2 (offset = 1):
idx = thread_id + offset - 1 = 0 + 1 - 1 = 0if 0 <= idx < SIZE:→if 0 <= 0 < 4:→ Truewindow_sum += a[0]→window_sum += 0
Missing Iteration 3 (offset = 2):
idx = thread_id + offset - 1 = 0 + 2 - 1 = 1if 0 <= idx < SIZE:→if 0 <= 1 < 4:→ Truewindow_sum += a[1]→window_sum += 1← THIS NEVER HAPPENS
Result: Thread 0 gets window_sum = 0 instead of window_sum = 0 + 1 = 1
Phase 5: Bug confirmation
Looking at the problem code, we find:
comptime ITER = 2 # ← BUG: Should be 3!
for offset in range(ITER): # ← Only 2 iterations: [0, 1]
idx = Int(thread_id) + offset - 1 # ← Missing offset = 2
if 0 <= idx < SIZE:
value = rebind[Scalar[dtype]](a[idx])
window_sum += value
🎯 ROOT CAUSE IDENTIFIED: ITER = 2 should be ITER = 3 for a sliding
window of size 3.
The Fix: Change comptime ITER = 2 to comptime ITER = 3 in the source
code.
Key debugging lessons
When Variables Are Inaccessible:
- Focus on execution flow - Count breakpoint hits and loop iterations
- Use mathematical reasoning - Work out what should happen vs what does happen
- Pattern analysis - Let the wrong results guide your investigation
- Cross-validation - Test your hypothesis against multiple data points
Professional GPU Debugging Reality:
- Variable inspection often fails due to compiler optimizations
- Execution flow analysis is more reliable than data inspection
- Host output patterns provide crucial debugging clues
- Source code reasoning complements limited debugger capabilities
TileTensor Debugging:
- Even with TileTensor abstractions, underlying algorithmic bugs still manifest
- Focus on the algorithm logic rather than trying to inspect tensor contents
- Use systematic reasoning to trace what each thread should vs actually accesses
Key Insight: This type of off-by-one loop bug is extremely common in GPU programming. The systematic approach you learned here - combining limited debugger info with mathematical analysis and pattern recognition - is exactly how professional GPU developers debug when tools have limitations.
Next steps: from logic bugs to coordination deadlocks
You’ve learned logic bug debugging! You can now:
- ✅ Investigate algorithmic errors without crashes or obvious symptoms
- ✅ Use pattern analysis to trace wrong results back to root causes
- ✅ Debug with limited variable access using execution flow analysis
- ✅ Apply mathematical reasoning when debugger tools have limitations
Your final challenge: Detective Work: Third Case
But what if your program doesn’t crash AND doesn’t finish? What if it just hangs forever?
The Third Case presents the ultimate debugging challenge:
- ❌ No crash messages (like First Case)
- ❌ No wrong results (like Second Case)
- ❌ No completion at all - just infinite hanging
- ✅ Silent deadlock requiring advanced thread coordination analysis
New skills you’ll develop:
- Barrier deadlock detection - Finding coordination failures in parallel threads
- Multi-thread state analysis - Examining all threads simultaneously
- Synchronization debugging - Understanding thread cooperation breakdowns
The debugging evolution:
- First Case: Follow crash signals → Find memory bugs
- Second Case: Analyze result patterns → Find logic bugs
- Third Case: Investigate thread states → Find coordination bugs
The systematic investigation skills from both previous cases - hypothesis formation, evidence gathering, pattern analysis - become crucial when debugging the most challenging GPU issue: threads that coordinate incorrectly and wait forever.
🕵 Detective Work: Third Case
Overview
You’ve learned debugging memory crashes and logic bugs. Now face the ultimate GPU debugging challenge: a barrier deadlock that causes the program to hang indefinitely with no error messages, no wrong results - just eternal silence.
The complete debugging journey:
- First Case: Program crashes → Follow error signals → Find memory bugs
- Second Case: Program produces wrong results → Analyze patterns → Find logic bugs
- Third Case: Program hangs forever → Investigate thread states → Find coordination bugs
This advanced-level debugging challenge teaches you to investigate thread coordination failures using shared memory, TileTensor operations, and barrier synchronization - combining all the systematic investigation skills from the previous cases.
Prerequisites: Complete Mojo GPU Debugging Essentials, Detective Work: First Case, and Detective Work: Second Case to understand CUDA-GDB workflow, variable inspection limitations, and systematic debugging approaches. Make sure you run the setup:
pixi run -e nvidia setup-cuda-gdb
Key concepts
In this debugging challenge, you’ll learn about:
- Barrier deadlock detection: Identifying when threads wait forever at synchronization points
- Shared memory coordination: Understanding thread cooperation patterns with TileTensor
- Conditional execution analysis: Debugging when some threads take different code paths
- Thread coordination debugging: Using CUDA-GDB to analyze multi-thread synchronization failures
Running the code
First, examine the kernel without looking at the complete code:
def collaborative_filter(
output: TileTensor[mut=True, dtype, VectorLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, VectorLayout, ImmutAnyOrigin],
):
var thread_id = thread_idx.x
# Shared memory workspace for collaborative processing
var shared_workspace = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[SIZE - 1]())
# Phase 1: Initialize shared workspace (all threads participate)
if thread_id < SIZE - 1:
shared_workspace[thread_id] = rebind[Scalar[dtype]](a[thread_id])
barrier()
# Phase 2: Collaborative processing
if thread_id < SIZE - 1:
# Apply collaborative filter with neighbors
if thread_id > 0:
shared_workspace[thread_id] += shared_workspace[thread_id - 1] * 0.5
barrier()
# Phase 3: Final synchronization and output
barrier()
# Write filtered results back to output
if thread_id < SIZE - 1:
output[thread_id] = shared_workspace[thread_id]
else:
output[thread_id] = rebind[Scalar[dtype]](a[thread_id])
To experience the bug firsthand, run the following command in your terminal
(pixi only):
pixi run -e nvidia p09 --third-case
You’ll see output like this - the program hangs indefinitely:
Third Case: Advanced collaborative filtering with shared memory...
WARNING: This may hang - use Ctrl+C to stop if needed
Input array: [1, 2, 3, 4]
Applying collaborative filter using shared memory...
Each thread cooperates with neighbors for smoothing...
Waiting for GPU computation to complete...
[HANGS FOREVER - Use Ctrl+C to stop]
⚠️ Warning: This program will hang and never complete. Use Ctrl+C to stop
it.
Your task: detective work
Challenge: The program launches successfully but hangs during GPU computation and never returns. Without looking at the complete code, what would be your systematic approach to investigate this deadlock?
Think about:
- What could cause a GPU kernel to never complete?
- How would you investigate thread coordination issues?
- What debugging strategy works when the program just “freezes” with no error messages?
- How do you debug when threads might not be cooperating correctly?
- How can you combine systematic investigation (First Case) with execution flow analysis (Second Case) to debug coordination failures?
Start with:
pixi run -e nvidia mojo debug --cuda-gdb --break-on-launch problems/p09/p09.mojo --third-case
GDB command shortcuts (faster debugging)
Use these abbreviations to speed up your debugging session:
| Short | Full | Usage Example |
|---|---|---|
r | run | (cuda-gdb) r |
n | next | (cuda-gdb) n |
c | continue | (cuda-gdb) c |
b | break | (cuda-gdb) b 62 |
p | print | (cuda-gdb) p thread_id |
q | quit | (cuda-gdb) q |
All debugging commands below use these shortcuts for efficiency!
Tips
- Silent hang investigation - When programs freeze without error messages, what GPU primitives could cause infinite waiting?
- Thread state inspection - Use
info cuda threadsto see where different threads are stopped - Conditional execution analysis - Check which threads execute which code paths (do all threads follow the same path?)
- Synchronization point investigation - Look for places where threads might need to coordinate
- Thread divergence detection - Are all threads at the same program location, or are some elsewhere?
- Coordination primitive analysis - What happens if threads don’t all participate in the same synchronization operations?
- Execution flow tracing - Follow the path each thread takes through conditional statements
- Thread ID impact analysis - How do different thread IDs affect which code paths execute?
💡 Investigation & Solution
Step-by-step investigation with CUDA-GDB
Phase 1: launch and initial setup
Step 1: start the debugger
pixi run -e nvidia mojo debug --cuda-gdb --break-on-launch problems/p09/p09.mojo --third-case
Step 2: analyze the hanging behavior
Before diving into debugging, let’s understand what we know:
Expected: Program completes and shows filtered results
Actual: Program hangs at "Waiting for GPU computation to complete..."
🔍 Initial Hypothesis: The GPU kernel is deadlocked - some synchronization primitive is causing threads to wait forever.
Phase 2: entering the kernel
Step 3: launch and observe kernel entry
(cuda-gdb) r
Starting program: .../mojo run problems/p09/p09.mojo --third-case
Third Case: Advanced collaborative filtering with shared memory...
WARNING: This may hang - use Ctrl+C to stop if needed
Input array: [1, 2, 3, 4]
Applying collaborative filter using shared memory...
Each thread cooperates with neighbors for smoothing...
Waiting for GPU computation to complete...
[Switching focus to CUDA kernel 0, grid 1, block (0,0,0), thread (0,0,0), device 0, sm 0, warp 0, lane 0]
CUDA thread hit application kernel entry function breakpoint, p09_collaborative_filter_Orig6A6AcB6A6A_1882ca334fc2d34b2b9c4fa338df6c07<<<(1,1,1),(4,1,1)>>> (
output=..., a=...)
at /home/ubuntu/workspace/mojo-gpu-puzzles/problems/p09/p09.mojo:56
56 a: TileTensor[mut=False, dtype, vector_layout],
🔍 Key Observations:
- Grid: (1,1,1) - single block
- Block: (4,1,1) - 4 threads total (0, 1, 2, 3)
- Current thread: (0,0,0) - debugging thread 0
- Function: collaborative_filter with shared memory operations
Step 4: navigate through initialization
(cuda-gdb) n
55 output: TileTensor[mut=True, dtype, vector_layout],
(cuda-gdb) n
58 thread_id = thread_idx.x
(cuda-gdb) n
66 ].stack_allocation()
(cuda-gdb) n
69 if thread_id < SIZE - 1:
(cuda-gdb) p thread_id
$1 = 0
✅ Thread 0 state: thread_id = 0, about to check condition 0 < 3 →
True
Step 5: trace through phase 1
(cuda-gdb) n
70 shared_workspace[thread_id] = rebind[Scalar[dtype]](a[thread_id])
(cuda-gdb) n
69 if thread_id < SIZE - 1:
(cuda-gdb) n
71 barrier()
Phase 1 Complete: Thread 0 executed the initialization and reached the first barrier.
Phase 3: the critical barrier investigation
Step 6: examine the first barrier
(cuda-gdb) n
74 if thread_id < SIZE - 1:
(cuda-gdb) info cuda threads
BlockIdx ThreadIdx To BlockIdx To ThreadIdx Count PC Filename Line
Kernel 0
* (0,0,0) (0,0,0) (0,0,0) (3,0,0) 4 0x00007fffd3272180 /home/ubuntu/workspace/mojo-gpu-puzzles/problems/p09/p09.mojo 74
✅ Good: All 4 threads are at line 74 (after the first barrier). The first barrier worked correctly.
🔍 Critical Point: Now we’re entering Phase 2 with another conditional statement.
Step 7: trace through phase 2 - thread 0 perspective
(cuda-gdb) n
76 if thread_id > 0:
Thread 0 Analysis: 0 < 3 → True → Thread 0 enters the Phase 2 block
(cuda-gdb) n
78 barrier()
Thread 0 Path: 0 > 0 → False → Thread 0 skips the inner computation
but reaches the barrier at line 78
CRITICAL MOMENT: Thread 0 is now waiting at the barrier on line 78.
(cuda-gdb) n # <-- if you run it the program hangs!
[HANGS HERE - Program never proceeds beyond this point]
Step 8: investigate other threads
(cuda-gdb) cuda thread (1,0,0)
[Switching focus to CUDA kernel 0, grid 1, block (0,0,0), thread (1,0,0), device 0, sm 0, warp 0, lane 1]
78 barrier()
(cuda-gdb) p thread_id
$2 = 1
(cuda-gdb) info cuda threads
BlockIdx ThreadIdx To BlockIdx To ThreadIdx Count PC Filename Line
Kernel 0
* (0,0,0) (0,0,0) (0,0,0) (2,0,0) 3 0x00007fffd3273aa0 /home/ubuntu/workspace/mojo-gpu-puzzles/problems/p09/p09.mojo 78
(0,0,0) (3,0,0) (0,0,0) (3,0,0) 1 0x00007fffd3273b10 /home/ubuntu/workspace/mojo-gpu-puzzles/problems/p09/p09.mojo 81
SMOKING GUN DISCOVERED:
- Threads 0, 1, 2: All waiting at line 78 (barrier inside the conditional block)
- Thread 3: At line 81 (after the conditional block, never reached the barrier!)
Step 9: analyze thread 3’s execution path
🔍 Thread 3 Analysis from the info output:
- Thread 3: Located at line 81 (PC: 0x00007fffd3273b10)
- Phase 2 condition:
thread_id < SIZE - 1→3 < 3→ False - Result: Thread 3 NEVER entered the Phase 2 block (lines 74-78)
- Consequence: Thread 3 NEVER reached the barrier at line 78
- Current state: Thread 3 is at line 81 (final barrier), while threads 0,1,2 are stuck at line 78
Phase 4: root cause analysis
Step 10: deadlock mechanism identified
# Phase 2: Collaborative processing
if thread_id < SIZE - 1: # ← Only threads 0, 1, 2 enter this block
# Apply collaborative filter with neighbors
if thread_id > 0:
shared_workspace[thread_id] += shared_workspace[thread_id - 1] * 0.5
barrier() # ← DEADLOCK: Only 3 out of 4 threads reach here!
💀 Deadlock Mechanism:
- Thread 0:
0 < 3→ True → Enters block → Waits at barrier (line 69) - Thread 1:
1 < 3→ True → Enters block → Waits at barrier (line 69) - Thread 2:
2 < 3→ True → Enters block → Waits at barrier (line 69) - Thread 3:
3 < 3→ False → NEVER enters block → Continues to line 72
Result: 3 threads wait forever for the 4th thread, but thread 3 never arrives at the barrier.
Phase 5: bug confirmation and solution
Step 11: the fundamental barrier rule violation
GPU Barrier Rule: ALL threads in a thread block must reach the SAME barrier for synchronization to complete.
What went wrong:
# ❌ WRONG: Barrier inside conditional
if thread_id < SIZE - 1: # Not all threads enter
# ... some computation ...
barrier() # Only some threads reach this
# ✅ CORRECT: Barrier outside conditional
if thread_id < SIZE - 1: # Not all threads enter
# ... some computation ...
barrier() # ALL threads reach this
The Fix: Move the barrier outside the conditional block:
def collaborative_filter(
output: TileTensor[mut=True, dtype, vector_layout],
a: TileTensor[mut=False, dtype, vector_layout],
):
thread_id = thread_idx.x
shared_workspace = TileTensor[
dtype,
row_major[SIZE-1](),
MutAnyOrigin,
address_space = AddressSpace.SHARED,
].stack_allocation()
# Phase 1: Initialize shared workspace (all threads participate)
if thread_id < SIZE - 1:
shared_workspace[thread_id] = rebind[Scalar[dtype]](a[thread_id])
barrier()
# Phase 2: Collaborative processing
if thread_id < SIZE - 1:
if thread_id > 0:
shared_workspace[thread_id] += shared_workspace[thread_id - 1] * 0.5
# ✅ FIX: Move barrier outside conditional so ALL threads reach it
barrier()
# Phase 3: Final synchronization and output
barrier()
if thread_id < SIZE - 1:
output[thread_id] = shared_workspace[thread_id]
else:
output[thread_id] = rebind[Scalar[dtype]](a[thread_id])
Key debugging lessons
Barrier deadlock detection:
- Use
info cuda threads- Shows which threads are at which lines - Look for thread state divergence - Some threads at different program locations
- Trace conditional execution paths - Check if all threads reach the same barriers
- Verify barrier reachability - Ensure no thread can skip a barrier that others reach
Professional GPU debugging reality:
- Deadlocks are silent killers - programs just hang with no error messages
- Thread coordination debugging requires patience - systematic analysis of each thread’s path
- Conditional barriers are the #1 deadlock cause - always verify all threads reach the same sync points
- CUDA-GDB thread inspection is essential - the only way to see thread coordination failures
Advanced GPU synchronization:
- Barrier rule: ALL threads in a block must reach the SAME barrier
- Conditional execution pitfalls: Any if-statement can cause thread divergence
- Shared memory coordination: Requires careful barrier placement for correct synchronization
- TileTensor doesn’t prevent deadlocks: Higher-level abstractions still need correct synchronization
💡 Key Insight: Barrier deadlocks are among the hardest GPU bugs to debug because:
- No visible error - just infinite waiting
- Requires multi-thread analysis - can’t debug by examining one thread
- Silent failure mode - looks like performance issue, not correctness bug
- Complex thread coordination - need to trace execution paths across all threads
This type of debugging - using CUDA-GDB to analyze thread states, identify divergent execution paths, and verify barrier reachability - is exactly what professional GPU developers do when facing deadlock issues in production systems.
Next steps: GPU debugging skills complete
You’ve completed the GPU debugging trilogy!
Your complete GPU debugging arsenal
From the First Case - Crash debugging:
- ✅ Systematic crash investigation using error messages as guides
- ✅ Memory bug detection through pointer address inspection
- ✅ CUDA-GDB fundamentals for memory-related issues
From the Second Case - Logic bug debugging:
- ✅ Algorithm error investigation without obvious symptoms
- ✅ Pattern analysis techniques for tracing wrong results to root causes
- ✅ Execution flow debugging when variable inspection fails
From the Third Case - Coordination debugging:
- ✅ Barrier deadlock investigation for thread coordination failures
- ✅ Multi-thread state analysis using advanced CUDA-GDB techniques
- ✅ Synchronization verification for complex parallel programs
The professional GPU debugging methodology
You’ve learned the systematic approach used by professional GPU developers:
- Read the symptoms - Crashes? Wrong results? Infinite hangs?
- Form hypotheses - Memory issue? Logic error? Coordination problem?
- Gather evidence - Use CUDA-GDB strategically based on the bug type
- Test systematically - Verify each hypothesis through targeted investigation
- Trace to root cause - Follow the evidence chain to the source
Achievement Unlocked: You can now debug the three most common GPU programming issues:
- Memory crashes (First Case) - null pointers, out-of-bounds access
- Logic bugs (Second Case) - algorithmic errors, incorrect results
- Coordination deadlocks (Third Case) - barrier synchronization failures
Puzzle 10: Memory Error Detection & Race Conditions with Sanitizers
⚠️ This puzzle works on compatible NVIDIA GPU only. We are working to enable tooling support for other GPU vendors.
The moment every GPU developer dreads
You’ve written what looks like perfect GPU code. Your algorithm is sound, your memory management seems correct, and your thread coordination appears flawless. You run your tests with confidence and…
- ✅ ALL TESTS PASS
- ✅ Performance looks great
- ✅ Output matches expected results
You ship your code to production, feeling proud of your work. Then weeks later, you get the call:
- “The application crashed in production”
- “Results are inconsistent between runs”
- “Memory corruption detected”
Welcome to the insidious world of silent GPU bugs - errors that hide in the shadows of massive parallelism, waiting to strike when you least expect them. These bugs can pass all your tests, produce correct results 99% of the time, and then catastrophically fail when it matters most.
Important note: This puzzle requires NVIDIA GPU hardware and is only
available through pixi, as compute-sanitizer is part of NVIDIA’s CUDA
toolkit.
Why GPU bugs are uniquely sinister
Unlike CPU programs where bugs usually announce themselves with immediate crashes or wrong results, GPU bugs are experts at hiding:
Silent corruption patterns:
- Memory violations that don’t crash: Out-of-bounds access to “lucky” memory locations
- Race conditions that work “most of the time”: Timing-dependent bugs that appear random
- Thread coordination failures: Deadlocks that only trigger under specific load conditions
Massive scale amplification:
- One thread’s bug affects thousands: A single memory violation can corrupt entire warps
- Race conditions multiply exponentially: More threads = more opportunities for corruption
- Hardware variations mask problems: Same bug behaves differently across GPU architectures
But here’s the exciting part: once you learn GPU sanitization tools, you’ll catch these elusive bugs before they ever reach production.
Your sanitization toolkit: NVIDIA compute-sanitizer
NVIDIA compute-sanitizer is your specialized weapon against GPU bugs. It can detect:
- Memory violations: Out-of-bounds access, invalid pointers, memory leaks
- Race conditions: Shared memory hazards between threads
- Synchronization bugs: Deadlocks, barrier misuse, improper thread coordination
- And more: Check
pixi run compute-sanitizer --help
📖 Official documentation: NVIDIA Compute Sanitizer User Guide
Think of it as X-ray vision for your GPU programs - revealing hidden problems that normal testing can’t see.
What you’ll learn in this puzzle
This puzzle teaches you to systematically find and fix the most elusive GPU bugs. You’ll learn the detective skills that distinguish competent GPU developers from exceptional ones.
Critical skills you’ll develop
- Silent bug detection - Find problems that tests don’t catch
- Memory corruption investigation - Track down undefined behavior before it strikes
- Race condition detection - Identify and eliminate concurrency hazards
- Tool selection expertise - Know exactly which sanitizer to use when
- Production debugging confidence - Catch bugs before they reach users
Real-world bug hunting scenarios
You’ll investigate the two most dangerous classes of GPU bugs:
- Memory violations - The silent killers that corrupt data without warning
- Race conditions - The chaos creators that make results unpredictable
Each scenario teaches you to think like a GPU bug detective, following clues that are invisible to normal testing.
Your bug hunting journey
This puzzle takes you through a carefully designed progression from discovering silent corruption to learning parallel debugging:
👮🏼♂️ The Silent Corruption Mystery
Memory violation investigation - When tests pass but memory lies
- Investigate programs that pass tests while committing memory crimes
- Learn to spot the telltale signs of undefined behavior (UB)
- Learn
memcheck- your memory violation detector - Understand why GPU hardware masks memory errors
- Practice systematic memory access validation
Key outcome: Ability to detect memory violations that would otherwise go unnoticed until production
🏁 The Race Condition Hunt
Concurrency bug investigation - When threads turn against each other
- Investigate programs that fail randomly due to thread timing
- Learn to identify shared memory hazards before they corrupt data
- Learn
racecheck- your race condition detector - Compare
racecheckvssynccheckfor different concurrency bugs - Practice thread synchronization strategies
Key outcome: Advanced concurrency debugging - the ability to tame thousands of parallel threads
The GPU detective mindset
GPU sanitization requires you to become a parallel program detective investigating crimes where:
- The evidence is hidden - Bugs occur in parallel execution you can’t directly observe
- Multiple suspects exist - Thousands of threads, any combination could be guilty
- The crime is intermittent - Race conditions and timing-dependent failures
- The tools are specialized - Sanitizers that see what normal debugging can’t
But like any good detective, you’ll learn to:
- Follow invisible clues - Memory access patterns, thread timing, synchronization points
- Think in parallel - Consider how thousands of threads interact simultaneously
- Prevent future crimes - Build sanitization into your development workflow
- Trust your tools - Let sanitizers reveal what manual testing cannot
Prerequisites and expectations
What you need to know:
- GPU programming concepts from Puzzles 1-8 (memory management, thread coordination, barriers)
- Compatible NVIDIA GPU hardware
- Environment setup with
pixipackage manager for accessingcompute-sanitizer - Prior puzzles: Familiarity with Puzzle 4 and Puzzle 8 are recommended
What you’ll gain:
- Production-ready debugging skills used by professional GPU development teams
- Silent bug detection skills that prevent costly production failures
- Parallel debugging confidence for the most challenging concurrency scenarios
- Tool expertise that will serve you throughout your GPU programming career
👮🏼♂️ The Silent Memory Corruption
Overview
Learn how to detect memory violations that can silently corrupt GPU programs,
even when tests appear to pass. Using NVIDIA’s compute-sanitizer (available
through pixi) with the memcheck tool, you’ll discover hidden memory bugs
that could cause unpredictable behavior in your GPU code.
Key insight: A GPU program can produce “correct” results while simultaneously performing illegal memory accesses.
Prerequisites: Understanding of Puzzle 4 TileTensor and basic GPU memory concepts.
The silent memory bug discovery
Test passes, but is my code actually correct?
Let’s start with a seemingly innocent program that appears to work perfectly (this is Puzzle 04 without guards):
def add_10_2d(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
output[row, col] = a[row, col] + 10.0
View full file: problems/p10/p10.mojo
When you run this program normally, everything looks fine:
pixi run p10 --memory-bug
out shape: 2 x 2
Running memory bug example (bounds checking issue)...
out: HostBuffer([10.0, 11.0, 12.0, 13.0])
expected: HostBuffer([10.0, 11.0, 12.0, 13.0])
✅ Memory test PASSED! (memcheck may find bounds violations)
✅ Test PASSED! The output matches expected results perfectly. Case closed, right?
Wrong! Let’s see what compute-sanitizer reveals:
MODULAR_DEVICE_CONTEXT_MEMORY_MANAGER_SIZE_PERCENT=0 pixi run compute-sanitizer --tool memcheck mojo problems/p10/p10.mojo --memory-bug
Note: MODULAR_DEVICE_CONTEXT_MEMORY_MANAGER_SIZE_PERCENT=0 is a
command-line environment variable setting that disables a device context’s
buffer cache. This setting can reveal memory issues, like bounds violations,
that are otherwise masked by the normal caching behavior.
========= COMPUTE-SANITIZER
out shape: 2 x 2
Running memory bug example (bounds checking issue)...
========= Invalid __global__ read of size 4 bytes
========= at p10_add_10_2d_...+0x80
========= by thread (2,1,0) in block (0,0,0)
========= Access at 0xe0c000210 is out of bounds
========= and is 513 bytes after the nearest allocation at 0xe0c000000 of size 16 bytes
========= Invalid __global__ read of size 4 bytes
========= at p10_add_10_2d_...+0x80
========= by thread (0,2,0) in block (0,0,0)
========= Access at 0xe0c000210 is out of bounds
========= and is 513 bytes after the nearest allocation at 0xe0c000000 of size 16 bytes
========= Invalid __global__ read of size 4 bytes
========= at p10_add_10_2d_...+0x80
========= by thread (1,2,0) in block (0,0,0)
========= Access at 0xe0c000214 is out of bounds
========= and is 517 bytes after the nearest allocation at 0xe0c000000 of size 16 bytes
========= Invalid __global__ read of size 4 bytes
========= at p10_add_10_2d_...+0x80
========= by thread (2,2,0) in block (0,0,0)
========= Access at 0xe0c000218 is out of bounds
========= and is 521 bytes after the nearest allocation at 0xe0c000000 of size 16 bytes
========= Program hit CUDA_ERROR_LAUNCH_FAILED (error 719) due to "unspecified launch failure" on CUDA API call to cuStreamSynchronize.
========= Program hit CUDA_ERROR_LAUNCH_FAILED (error 719) due to "unspecified launch failure" on CUDA API call to cuEventCreate.
========= Program hit CUDA_ERROR_LAUNCH_FAILED (error 719) due to "unspecified launch failure" on CUDA API call to cuMemFreeAsync.
========= ERROR SUMMARY: 7 errors
The program has 7 total errors despite passing all tests:
- 4 memory violations (Invalid global read)
- 3 runtime errors (caused by the memory violations)
Understanding the hidden bug
Root cause analysis
The Problem:
- Tensor size: 2×2 (valid indices: 0, 1)
- Thread grid: 3×3 (thread indices: 0, 1, 2)
- Out-of-bounds threads:
(2,1),(0,2),(1,2),(2,2)access invalid memory - Missing bounds check: No validation of
thread_idxagainst tensor dimensions
Understanding the 7 total errors
4 Memory Violations:
- Each out-of-bounds thread
(2,1),(0,2),(1,2),(2,2)caused an “Invalid global read”
3 CUDA Runtime Errors:
cuStreamSynchronizefailed due to kernel launch failurecuEventCreatefailed during cleanupcuMemFreeAsyncfailed during memory deallocation
Key Insight: Memory violations have cascading effects - one bad memory access causes multiple downstream CUDA API failures.
Why tests still passed:
- Valid threads
(0,0),(0,1),(1,0),(1,1)wrote correct results - Test only checked valid output locations
- Out-of-bounds accesses didn’t immediately crash the program
Understanding undefined behavior (UB)
What is undefined behavior?
Undefined Behavior (UB) occurs when a program performs operations that have no defined meaning according to the language specification. Out-of-bounds memory access is a classic example of undefined behavior.
Key characteristics of UB:
- The program can do literally anything: crash, produce wrong results, appear to work, or corrupt memory
- No guarantees: Behavior may change between compilers, hardware, drivers, or even different runs
Why undefined behavior is especially dangerous
Correctness issues:
- Unpredictable results: Your program may work during testing but fail in production
- Non-deterministic behavior: Same code can produce different results on different runs
- Silent corruption: UB can corrupt data without any visible errors
- Compiler optimizations: Compilers assume no UB occurs and may optimize in unexpected ways
Security vulnerabilities:
- Buffer overflows: Classic source of security exploits in systems programming
- Memory corruption: Can lead to privilege escalation and code injection attacks
- Information leakage: Out-of-bounds reads can expose sensitive data
- Control flow hijacking: UB can be exploited to redirect program execution
GPU-specific undefined behavior dangers
Massive scale impact:
- Thread divergence: One thread’s UB can affect entire warps (32 threads)
- Memory coalescing: Out-of-bounds access can corrupt neighboring threads’ data
- Kernel failures: UB can cause entire GPU kernels to fail catastrophically
Hardware variations:
- Different GPU architectures: UB may manifest differently on different GPU models
- Driver differences: Same UB may behave differently across driver versions
- Memory layout changes: GPU memory allocation patterns can change UB manifestation
Fixing the memory violation
The solution
As we saw in Puzzle 04, we need to bound-check as follows:
def add_10_2d(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
if col < size and row < size:
output[row, col] = a[row, col] + 10.0
The fix is simple: always validate thread indices against data dimensions before accessing memory.
Verification with compute-sanitizer
# Fix the bounds checking in your copy of p10.mojo, then run:
MODULAR_DEVICE_CONTEXT_MEMORY_MANAGER_SIZE_PERCENT=0 pixi run compute-sanitizer --tool memcheck mojo problems/p10/p10.mojo --memory-bug
========= COMPUTE-SANITIZER
[...]:WARNING close_multiple.cc:66] close: Bad file descriptor (9)
[...]:WARNING close_multiple.cc:66] close: Bad file descriptor (9)
Please submit a bug report to https://github.com/modular/modular/issues and include the crash backtrace along with all the relevant source codes.
Stack dump:
0. Program arguments: .../.pixi/envs/default/bin/mojo problems/p10/p10.mojo --memory-bug
#0 0x... (/.../.pixi/envs/default/bin/mojo+0x...)
...
[...] intermediate process terminated by signal 11 (Segmentation fault) (core dumped)
out shape: 2 x 2
Running memory bug example (bounds checking issue)...
out: HostBuffer([10.0, 11.0, 12.0, 13.0])
expected: HostBuffer([10.0, 11.0, 12.0, 13.0])
✅ Memory test PASSED! (memcheck may find bounds violations)
========= ERROR SUMMARY: 0 errors
✅ SUCCESS: No memory violations detected!
Note on the segfault: The crash lines above (“intermediate process terminated by signal 11”) are a known compatibility issue between Mojo’s process initialization and compute-sanitizer’s injection libraries. They appear before the GPU kernel runs and do not affect the sanitizer’s analysis. See the note at the end of this page for details.
Key learning points
Why manual bounds checking matters
- Clarity: Makes the safety requirements explicit in the code
- Control: You decide exactly what happens for out-of-bounds cases
- Debugging: Easier to reason about when memory violations occur
GPU memory safety rules
- Always validate thread indices against data dimensions
- Avoid undefined behavior (UB) at all costs - out-of-bounds access is UB and can break everything
- Use compute-sanitizer during development and testing
- Never assume “it works” without memory checking
- Test with different grid/block configurations to catch undefined behavior (UB) that manifests inconsistently
Compute-sanitizer best practices
MODULAR_DEVICE_CONTEXT_MEMORY_MANAGER_SIZE_PERCENT=0 pixi run compute-sanitizer --tool memcheck mojo your_code.mojo
Note on Mojo + compute-sanitizer compatibility: You may see a crash at the
start of the sanitizer output — lines like close: Bad file descriptor, a stack
dump, and intermediate process terminated by signal 11 (Segmentation fault).
This is a known issue where compute-sanitizer’s injection libraries conflict
with Mojo’s process initialization. Despite the crash, the sanitizer completes
its GPU kernel analysis correctly. Always use the ========= ERROR SUMMARY line
at the end as the authoritative result, and look for ========= Invalid lines
for specific memory violations.
🏁 Debugging Race Conditions
Overview
Debug failing GPU programs using NVIDIA’s compute-sanitizer to identify race
conditions that cause incorrect results. You’ll learn to use the racecheck
tool to find concurrency bugs in shared memory operations.
You have a GPU kernel that should accumulate values from multiple threads using shared memory. The test fails, but the logic seems correct. Your task is to identify and fix the race condition causing the failure.
Configuration
comptime SIZE = 2
comptime BLOCKS_PER_GRID = 1
comptime THREADS_PER_BLOCK = (3, 3) # 9 threads, but only 4 are active
comptime dtype = DType.float32
The failing kernel
comptime SIZE = 2
comptime BLOCKS_PER_GRID = 1
comptime THREADS_PER_BLOCK = (3, 3)
comptime dtype = DType.float32
comptime layout = row_major[SIZE, SIZE]()
comptime LayoutType = type_of(layout)
def shared_memory_race(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
var shared_sum = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[1]())
if row < size and col < size:
shared_sum[0] += a[row, col]
barrier()
if row < size and col < size:
output[row, col] = shared_sum[0]
View full file: problems/p10/p10.mojo
Running the code
pixi run p10 --race-condition
and the output will look like
out shape: 2 x 2
Running race condition example...
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([6.0, 6.0, 6.0, 6.0])
stack trace was not collected. Enable stack trace collection with environment variable `MOJO_ENABLE_STACK_TRACE_ON_ERROR`
Unhandled exception caught during execution: At /home/ubuntu/workspace/mojo-gpu-puzzles/problems/p10/p10.mojo:122:33: AssertionError: `left == right` comparison failed:
left: 0.0
right: 6.0
Let’s see how compute-sanitizer can help us detection issues in our GPU code.
Debugging with compute-sanitizer
Step 1: Identify the race condition with racecheck
Use compute-sanitizer with the racecheck tool to identify race conditions:
pixi run compute-sanitizer --tool racecheck mojo problems/p10/p10.mojo --race-condition
the output will look like
========= COMPUTE-SANITIZER
out shape: 2 x 2
Running race condition example...
========= Error: Race reported between Write access at p10_shared_memory_race_...+0x140
========= and Read access at p10_shared_memory_race_...+0xe0 [4 hazards]
========= and Write access at p10_shared_memory_race_...+0x140 [5 hazards]
=========
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([6.0, 6.0, 6.0, 6.0])
AssertionError: `left == right` comparison failed:
left: 0.0
right: 6.0
========= RACECHECK SUMMARY: 1 hazard displayed (1 error, 0 warnings)
Analysis: The program has 1 race condition with 9 individual hazards:
- 4 read-after-write hazards (threads reading while others write)
- 5 write-after-write hazards (multiple threads writing simultaneously)
Step 2: Compare with synccheck
Verify this is a race condition, not a synchronization issue:
pixi run compute-sanitizer --tool synccheck mojo problems/p10/p10.mojo --race-condition
and the output will be like
========= COMPUTE-SANITIZER
out shape: 2 x 2
Running race condition example...
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([6.0, 6.0, 6.0, 6.0])
AssertionError: `left == right` comparison failed:
left: 0.0
right: 6.0
========= ERROR SUMMARY: 0 errors
Key insight: synccheck found 0 errors - there are no synchronization
issues like deadlocks. The problem is race conditions, not synchronization
bugs.
Deadlock vs Race Condition: Understanding the Difference
| Aspect | Deadlock | Race Condition |
|---|---|---|
| Symptom | Program hangs forever | Program produces wrong results |
| Execution | Never completes | Completes successfully |
| Timing | Deterministic hang | Non-deterministic results |
| Root Cause | Synchronization logic error | Unsynchronized data access |
| Detection Tool | synccheck | racecheck |
| Example | Puzzle 09: Third case barrier deadlock | Our shared memory += operation |
In our specific case:
- Program completes → No deadlock (threads don’t get stuck)
- Wrong results → Race condition (threads corrupt each other’s data)
- Tool confirms →
synccheckreports 0 errors,racecheckreports 9 hazards
Why this distinction matters for debugging:
- Deadlock debugging: Focus on barrier placement, conditional synchronization, thread coordination
- Race condition debugging: Focus on shared memory access patterns, atomic operations, data dependencies
Challenge
Equiped with these tools, fix the kernel failing kernel.
Tips
Understanding the hazard breakdown
The shared_sum[0] += a[row, col] operation creates hazards because it’s
actually three separate memory operations:
- READ
shared_sum[0] - ADD
a[row, col]to the read value - WRITE the result back to
shared_sum[0]
With 4 active threads (positions (0,0), (0,1), (1,0), (1,1)), these operations can interleave:
- Thread timing overlap → Multiple threads read the same initial value (0.0)
- Lost updates → Each thread writes back
0.0 + their_value, overwriting others’ work - Non-atomic operation → The
+=compound assignment isn’t atomic in GPU shared memory
Why we get exactly 9 hazards:
- Each thread tries to perform read-modify-write
- 4 threads × 2-3 hazards per thread = 9 total hazards
compute-sanitizertracks every conflicting memory access pair
Race condition debugging tips
- Use racecheck for data races: Detects shared memory hazards and data corruption
- Use synccheck for deadlocks: Detects synchronization bugs (barrier issues, deadlocks)
- Focus on shared memory access: Look for unsynchronized
+=,=operations to shared variables - Identify the pattern: Read-modify-write operations are common race condition sources
- Check barrier placement: Barriers must be placed BEFORE conflicting operations, not after
Why this distinction matters for debugging:
- Deadlock debugging: Focus on barrier placement, conditional synchronization, thread coordination
- Race condition debugging: Focus on shared memory access patterns, atomic operations, data dependencies
Common race condition patterns to avoid:
- Multiple threads writing to the same shared memory location
- Unsynchronized read-modify-write operations (
+=,++, etc.) - Barriers placed after the race condition instead of before
Solution
comptime SIZE = 2
comptime BLOCKS_PER_GRID = 1
comptime THREADS_PER_BLOCK = (3, 3)
comptime dtype = DType.float32
comptime layout = row_major[SIZE, SIZE]()
comptime LayoutType = type_of(layout)
def shared_memory_race(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
"""Fixed: sequential access with barriers eliminates race conditions."""
var row = thread_idx.y
var col = thread_idx.x
var shared_sum = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[1]())
# Only thread 0 does all the accumulation work to prevent races
if row == 0 and col == 0:
# Use local accumulation first, then single write to shared memory
var local_sum = Scalar[dtype](0.0)
for r in range(size):
for c in range(size):
local_sum += rebind[Scalar[dtype]](a[r, c])
shared_sum[0] = local_sum # Single write operation
barrier() # Ensure thread 0 completes before others read
# All threads read the safely accumulated result after synchronization
if row < size and col < size:
output[row, col] = shared_sum[0]
Understanding what went wrong
The race condition problem pattern
The original failing code had this critical line:
shared_sum[0] += a[row, col] # RACE CONDITION!
This single line creates multiple hazards among the 4 valid threads:
- Thread (0,0) reads
shared_sum[0](value: 0.0) - Thread (0,1) reads
shared_sum[0](value: 0.0) ← Read-after-write hazard! - Thread (0,0) writes back
0.0 + 0 - Thread (1,0) writes back
0.0 + 2← Write-after-write hazard!
Why the test failed
- Multiple threads corrupt each other’s writes during the
+=operation - The
+=operation gets interrupted, causing lost updates - Expected sum of 6.0 (0+1+2+3), but race conditions resulted in 0.0
- The
barrier()comes too late - after the race condition already occurred
What are race conditions?
Race conditions occur when multiple threads access shared data concurrently, and the result depends on the unpredictable timing of thread execution.
Key characteristics:
- Non-deterministic behavior: Same code can produce different results on different runs
- Timing-dependent: Results depend on which thread “wins the race”
- Hard to reproduce: May only manifest under specific conditions or hardware
GPU-specific dangers
Massive parallelism impact:
- Warp-level corruption: Race conditions can affect entire warps (32 threads)
- Memory coalescing issues: Races can disrupt efficient memory access patterns
- Kernel-wide failures: Shared memory corruption can affect the entire GPU kernel
Hardware variations:
- Different GPU architectures: Race conditions may manifest differently across GPU models
- Memory hierarchy: L1 cache, L2 cache, and global memory can all exhibit different race behaviors
- Warp scheduling: Different thread scheduling can expose different race condition scenarios
Strategy: Single writer pattern
The key insight is to eliminate concurrent writes to shared memory:
- Single writer: Only one thread (thread at position (0,0)) does all accumulation work
- Local accumulation: Thread at position (0,0) uses a local variable to avoid repeated shared memory access
- Single shared memory write: One write operation eliminates write-write races
- Barrier synchronization: Ensures writer completes before others read
- Multiple readers: All threads safely read the final result
Step-by-step solution breakdown
Step 1: Thread identification
if row == 0 and col == 0:
Use direct coordinate check to identify thread at position (0,0).
Step 2: Single-threaded accumulation
if row == 0 and col == 0:
local_sum = Scalar[dtype](0.0)
for r in range(size):
for c in range(size):
local_sum += rebind[Scalar[dtype]](a[r, c])
shared_sum[0] = local_sum # Single write operation
Only thread at position (0,0) performs all accumulation work, eliminating race conditions.
Step 3: Synchronization barrier
barrier() # Ensure thread (0,0) completes before others read
All threads wait for thread at position (0,0) to finish accumulation.
Step 4: Safe parallel reads
if row < size and col < size:
output[row, col] = shared_sum[0]
All threads can safely read the result after synchronization.
Important note on efficiency
This solution prioritizes correctness over efficiency. While it eliminates race conditions, using only thread at position (0,0) for accumulation is not optimal for GPU performance - we’re essentially doing serial computation on a massively parallel device.
Coming up in Puzzle 11: Pooling: You’ll learn efficient parallel reduction algorithms that leverage all threads for high-performance summation operations while maintaining race-free execution. This puzzle teaches the foundation of correctness first - once you understand how to avoid race conditions, Puzzle 11 will show you how to achieve both correctness AND performance.
Verification
pixi run compute-sanitizer --tool racecheck mojo solutions/p10/p10.mojo --race-condition
Expected output:
========= COMPUTE-SANITIZER
out shape: 2 x 2
Running race condition example...
out: HostBuffer([6.0, 6.0, 6.0, 6.0])
expected: HostBuffer([6.0, 6.0, 6.0, 6.0])
✅ Race condition test PASSED! (racecheck will find hazards)
========= RACECHECK SUMMARY: 0 hazards displayed (0 errors, 0 warnings)
✅ SUCCESS: Test passes and no race conditions detected!
Puzzle 11: Pooling
Overview
Implement a kernel that compute the running sum of the last 3 positions of 1D
TileTensor a and stores it in 1D TileTensor output.
Pooling is an operation that condenses a region of values into a single summary value — for example, their sum, maximum, or average. A sliding window applies this condensation repeatedly by moving a fixed-size window one step at a time across the input, producing one output value per window position. Here the window is 3 elements wide and the summary function is a sum, so each output element equals the sum of the current element and the two preceding it (with special cases at the boundaries where fewer than 3 elements are available).
Note: You have 1 thread per position. You only need 1 global read and 1 global write per thread.
Key concepts
In this puzzle, you’ll learn about:
- Using TileTensor for sliding window operations
- Managing shared memory with TileTensor address_space that we saw in puzzle 8
- Efficient neighbor access patterns
- Boundary condition handling
The key insight is how TileTensor simplifies shared memory management while maintaining efficient window-based operations.
Configuration
- Array size:
SIZE = 8elements - Threads per block:
TPB = 8 - Window size: 3 elements
- Shared memory:
TPBelements
Notes:
- TileTensor allocation: Use
stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB]()) - Window access: Natural indexing for 3-element windows
- Edge handling: Special cases for first two positions
- Memory pattern: One shared memory load per thread
Code to complete
comptime TPB = 8
comptime SIZE = 8
comptime BLOCKS_PER_GRID = (1, 1)
comptime THREADS_PER_BLOCK = (TPB, 1)
comptime dtype = DType.float32
comptime layout = row_major[SIZE]()
comptime LayoutType = type_of(layout)
def pooling(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
# Allocate shared memory using stack_allocation
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# FIX ME IN (roughly 10 lines)
View full file: problems/p11/p11.mojo
Tips
- Create shared memory with TileTensor using address_space
- Load data with natural indexing:
shared[local_i] = a[global_i] - Handle special cases for first two elements
- Use shared memory for window operations
- Guard against out-of-bounds access
Running the code
To test your solution, run the following command in your terminal:
pixi run p11
pixi run -e amd p11
pixi run -e apple p11
uv run poe p11
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([0.0, 1.0, 3.0, 6.0, 9.0, 12.0, 15.0, 18.0])
Solution
def pooling(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
# Allocate shared memory using stack_allocation
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Load data into shared memory
if global_i < size:
shared[local_i] = a[global_i]
# Synchronize threads within block
barrier()
# Handle first two special cases
if global_i == 0:
output[0] = shared[0]
elif global_i == 1:
output[1] = shared[0] + shared[1]
# Handle general case
elif 1 < global_i < size:
output[global_i] = (
shared[local_i - 2] + shared[local_i - 1] + shared[local_i]
)
The solution implements a sliding window sum using TileTensor with these key steps:
-
Shared memory setup
-
TileTensor creates block-local storage with address_space:
shared = stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB]()) -
Each thread loads one element:
Input array: [0.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0] Block shared: [0.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0] -
barrier()ensures all data is loaded
-
-
Boundary cases
-
Position 0: Single element
output[0] = shared[0] = 0.0 -
Position 1: Sum of first two elements
output[1] = shared[0] + shared[1] = 0.0 + 1.0 = 1.0
-
-
Main window operation
-
For positions 2 and beyond:
Position 2: shared[0] + shared[1] + shared[2] = 0.0 + 1.0 + 2.0 = 3.0 Position 3: shared[1] + shared[2] + shared[3] = 1.0 + 2.0 + 3.0 = 6.0 Position 4: shared[2] + shared[3] + shared[4] = 2.0 + 3.0 + 4.0 = 9.0 ... -
Natural indexing with TileTensor:
# Sliding window of 3 elements window_sum = shared[i-2] + shared[i-1] + shared[i]
-
Single-block assumption: This solution is correct because the puzzle is configured with
BLOCKS_PER_GRID = (1, 1)andSIZE == TPB = 8, guaranteeing every thread belongs to the same block soglobal_i == local_i. Under this constraint,local_i >= 2wheneverglobal_i > 1, soshared[local_i - 2]andshared[local_i - 1]are always valid.In a multi-block kernel the first two threads of each block beyond block 0 would have
local_i = 0orlocal_i = 1whileglobal_i > 1, causing out-of-bounds shared memory reads. The robust pattern for multi-block pooling guards withlocal_iand falls back to global reads for the halo elements:if local_i >= 2: output[global_i] = shared[local_i-2] + shared[local_i-1] + shared[local_i] elif local_i == 1 and global_i >= 2: output[global_i] = a[global_i-2] + shared[0] + shared[1] elif local_i == 0 and global_i >= 2: output[global_i] = a[global_i-2] + a[global_i-1] + shared[0]
- Memory access pattern
- One global read per thread into shared tensor
- Efficient neighbor access through shared memory
- TileTensor benefits:
- Automatic bounds checking
- Natural window indexing
- Layout-aware memory access
- Type safety throughout
This approach combines the performance of shared memory with TileTensor’s safety and ergonomics:
- Minimizes global memory access
- Simplifies window operations
- Handles boundaries cleanly
- Maintains coalesced access patterns
The final output shows the cumulative window sums:
[0.0, 1.0, 3.0, 6.0, 9.0, 12.0, 15.0, 18.0]
Puzzle 12: Dot Product
Overview
Implement a kernel that computes the dot product of 1D TileTensor a and 1D
TileTensor b and stores it in 1D TileTensor output (single number). The dot
product is an operation that takes two vectors of the same size and returns a
single number (a scalar). It is calculated by multiplying corresponding elements
from each vector and then summing those products.
For example, if you have two vectors:
\[a = [a_{1}, a_{2}, …, a_{n}] \] \[b = [b_{1}, b_{2}, …, b_{n}] \]
Their dot product is: \[a \cdot b = a_{1}b_{1} + a_{2}b_{2} + … + a_{n}b_{n}\]
Note: You have 1 thread per position. You only need 2 global reads per thread and 1 global write per thread block.
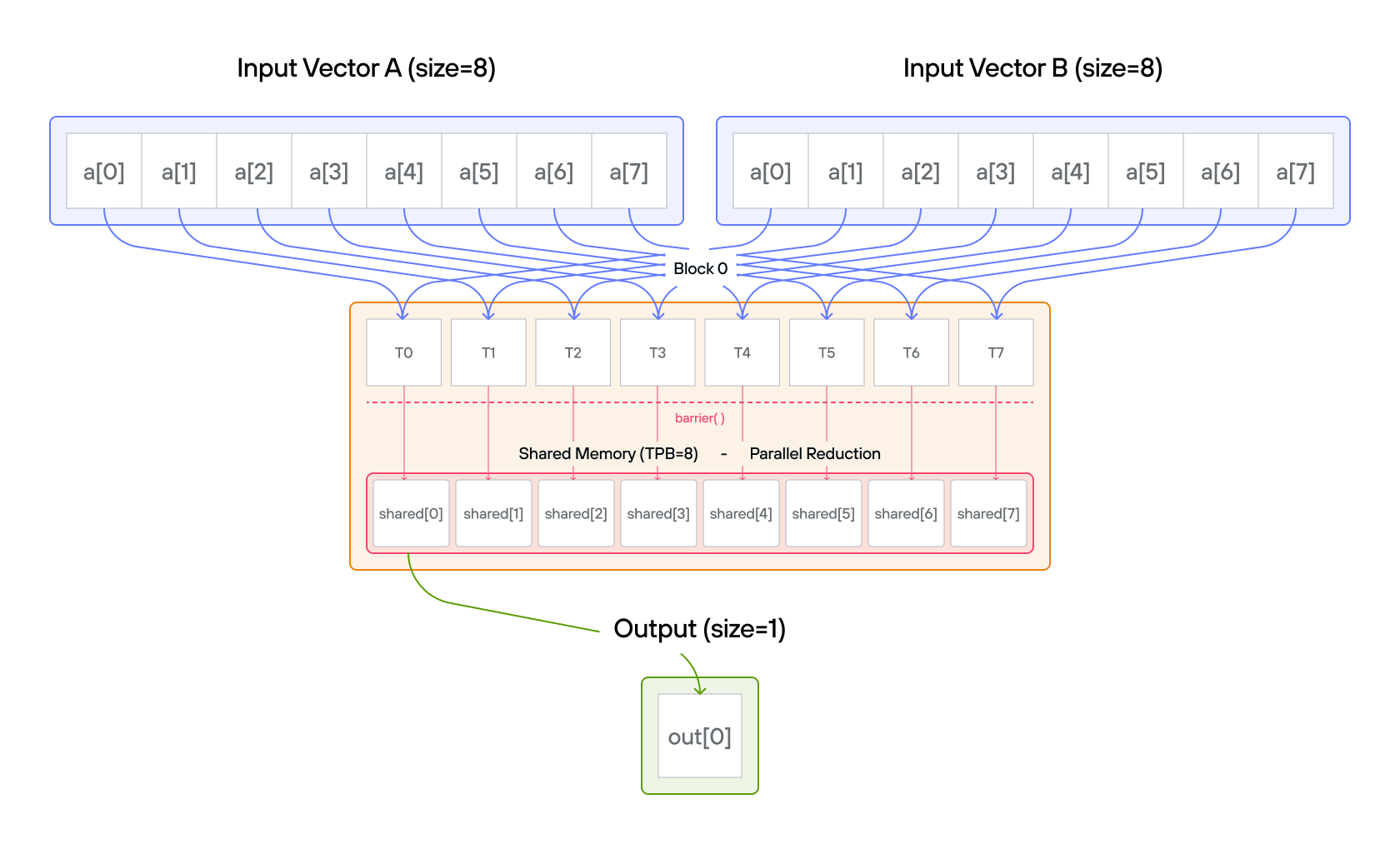
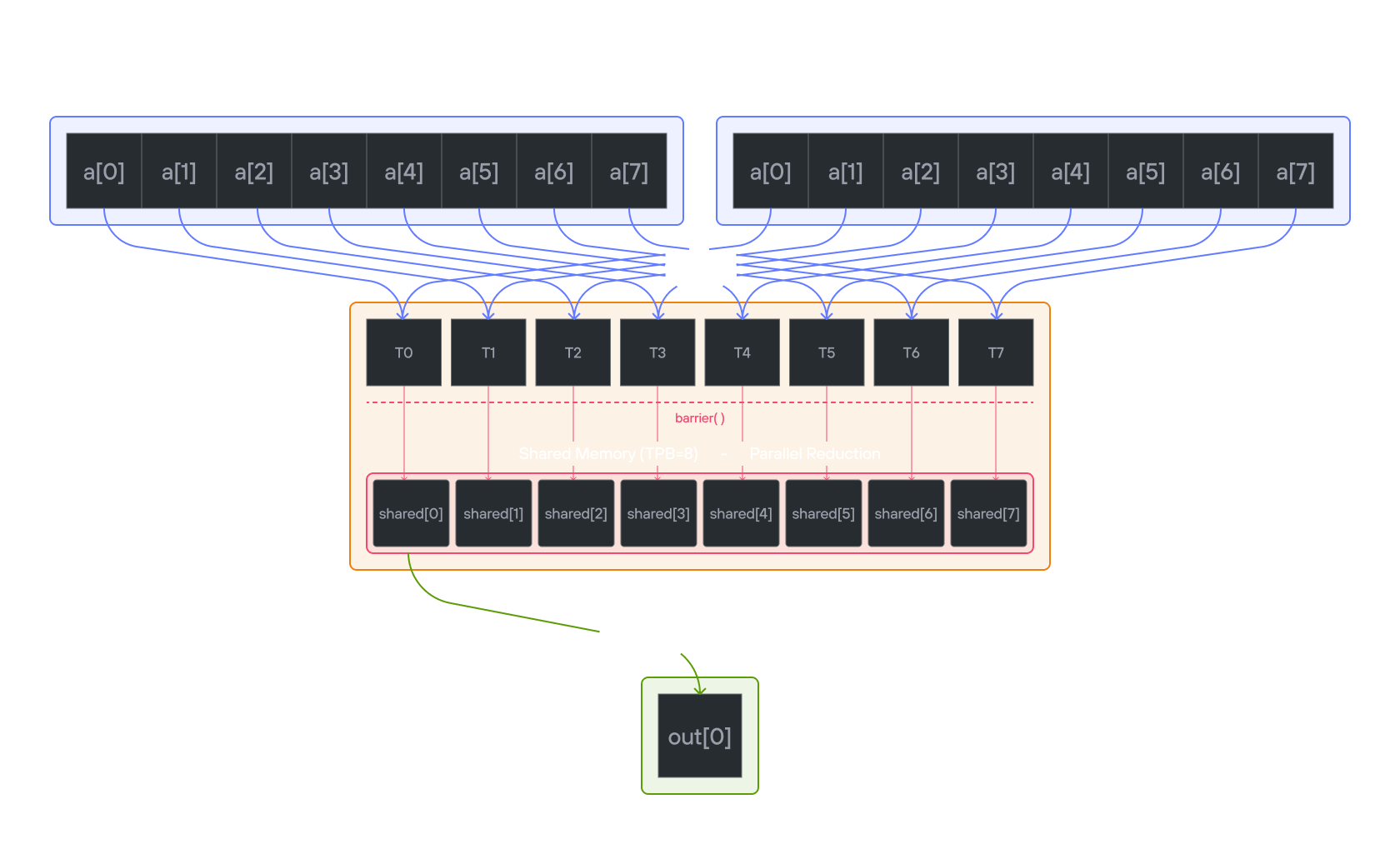
Key concepts
Parallel reduction is an algorithm that combines \(n\) values into one
using a binary operation (here, addition) in \(O(\log n)\) steps instead of
\(O(n)\) sequential steps. In each step, half the active threads each add one
value into another, halving the number of remaining partial results. After
\(\log_2 n\) steps, thread 0 holds the final sum. This tree-shaped computation
requires a barrier() between steps so no thread reads a partially-updated
value.
This puzzle covers:
- Similar to puzzle 8 and puzzle 11, implementing parallel reduction with TileTensor
- Managing shared memory using TileTensor with address_space
- Coordinating threads for collective operations
- Using layout-aware tensor operations
The key insight is how TileTensor simplifies memory management while maintaining efficient parallel reduction patterns.
Configuration
- Vector size:
SIZE = 8elements - Threads per block:
TPB = 8 - Number of blocks: 1
- Output size: 1 element
- Shared memory:
TPBelements
Notes:
- TileTensor allocation: Use
stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB]()) - Element access: Natural indexing with bounds checking
- Layout handling: Separate layouts for input and output
- Thread coordination: Same synchronization patterns with
barrier()
Code to complete
from std.gpu import thread_idx, block_idx, block_dim, barrier
from std.gpu.memory import AddressSpace
from layout import TileTensor
from layout.tile_layout import row_major
from layout.tile_tensor import stack_allocation
comptime TPB = 8
comptime SIZE = 8
comptime BLOCKS_PER_GRID = (1, 1)
comptime THREADS_PER_BLOCK = (TPB, 1)
comptime dtype = DType.float32
comptime layout = row_major[SIZE]()
comptime out_layout = row_major[1]()
comptime LayoutType = type_of(layout)
comptime OutLayout = type_of(out_layout)
def dot_product(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
# FILL ME IN (roughly 13 lines)
...
View full file: problems/p12/p12.mojo
Tips
- Create shared memory with TileTensor using address_space
- Store
a[global_i] * b[global_i]inshared[local_i] - Use parallel reduction pattern with
barrier() - Let thread 0 write final result to
output[0]
Running the code
To test your solution, run the following command in your terminal:
pixi run p12
pixi run -e amd p12
pixi run -e apple p12
uv run poe p12
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0])
expected: HostBuffer([140.0])
Solution
def dot_product(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Compute element-wise multiplication into shared memory
if global_i < size:
shared[local_i] = a[global_i] * b[global_i]
# Synchronize threads within block
barrier()
# Parallel reduction in shared memory
var stride = TPB // 2
while stride > 0:
if local_i < stride:
shared[local_i] += shared[local_i + stride]
barrier()
stride //= 2
# Only thread 0 writes the final result
if local_i == 0:
output[0] = shared[0]
The solution implements a parallel reduction for dot product using TileTensor. Here’s the detailed breakdown:
Phase 1: Element-wise Multiplication
Each thread performs one multiplication with natural indexing:
shared[local_i] = a[global_i] * b[global_i]
Phase 2: Parallel Reduction
Tree-based reduction with layout-aware operations:
Initial: [0*0 1*1 2*2 3*3 4*4 5*5 6*6 7*7]
= [0 1 4 9 16 25 36 49]
Step 1: [0+16 1+25 4+36 9+49 16 25 36 49]
= [16 26 40 58 16 25 36 49]
Step 2: [16+40 26+58 40 58 16 25 36 49]
= [56 84 40 58 16 25 36 49]
Step 3: [56+84 84 40 58 16 25 36 49]
= [140 84 40 58 16 25 36 49]
Key implementation features
-
Memory Management:
- Clean shared memory allocation with TileTensor address_space parameter
- Type-safe operations with TileTensor
- Automatic bounds checking
- Layout-aware indexing
-
Thread Synchronization:
barrier()after initial multiplicationbarrier()between reduction steps- Safe thread coordination
-
Reduction Logic:
stride = TPB // 2 while stride > 0: if local_i < stride: shared[local_i] += shared[local_i + stride] barrier() stride //= 2 -
Performance Benefits:
- \(O(\log n)\) time complexity
- Coalesced memory access
- Minimal thread divergence
- Efficient shared memory usage
The TileTensor version maintains the same efficient parallel reduction while providing:
- Better type safety
- Cleaner memory management
- Layout awareness
- Natural indexing syntax
Barrier synchronization importance
The barrier() between reduction steps is critical for correctness. Here’s why:
Without barrier(), race conditions occur:
Initial shared memory: [0 1 4 9 16 25 36 49]
Step 1 (stride = 4):
Thread 0 reads: shared[0] = 0, shared[4] = 16
Thread 1 reads: shared[1] = 1, shared[5] = 25
Thread 2 reads: shared[2] = 4, shared[6] = 36
Thread 3 reads: shared[3] = 9, shared[7] = 49
Without barrier:
- Thread 0 writes: shared[0] = 0 + 16 = 16
- Thread 1 starts next step (stride = 2) before Thread 0 finishes
and reads old value shared[0] = 0 instead of 16!
With barrier():
Step 1 (stride = 4):
All threads write their sums:
[16 26 40 58 16 25 36 49]
barrier() ensures ALL threads see these values
Step 2 (stride = 2):
Now threads safely read the updated values:
Thread 0: shared[0] = 16 + 40 = 56
Thread 1: shared[1] = 26 + 58 = 84
The barrier() ensures:
- All writes from current step complete
- All threads see updated values
- No thread starts next iteration early
- Consistent shared memory state
Without these synchronization points, we could get:
- Memory race conditions
- Threads reading stale values
- Non-deterministic results
- Incorrect final sum
Puzzle 13: 1D Convolution
Moving to TileTensor
So far in our GPU puzzle journey, we’ve been exploring two parallel approaches to GPU memory management:
- Raw memory management with direct pointer manipulation using UnsafePointer
- The more structured TileTensor with its powerful address_space parameter for memory allocation
Starting from this puzzle, we’re transitioning exclusively to using
TileTensor. This abstraction provides several benefits:
- Type-safe memory access patterns
- Clear representation of data layouts
- Better code maintainability
- Reduced chance of memory-related bugs
- More expressive code that better represents the underlying computations
- A lot more … that we’ll uncover gradually!
This transition aligns with best practices in modern GPU programming in Mojo 🔥, where higher-level abstractions help manage complexity without sacrificing performance.
Overview
In signal processing and image analysis, convolution is a fundamental operation that combines two sequences to produce a third sequence. This puzzle challenges you to implement a 1D convolution on the GPU, where each output element is computed by sliding a kernel over an input array.
Implement a kernel that computes a 1D convolution between vector a and vector
b and stores it in output using the TileTensor abstraction.
Note: You need to handle the general case. You only need 2 global reads and 1 global write per thread.
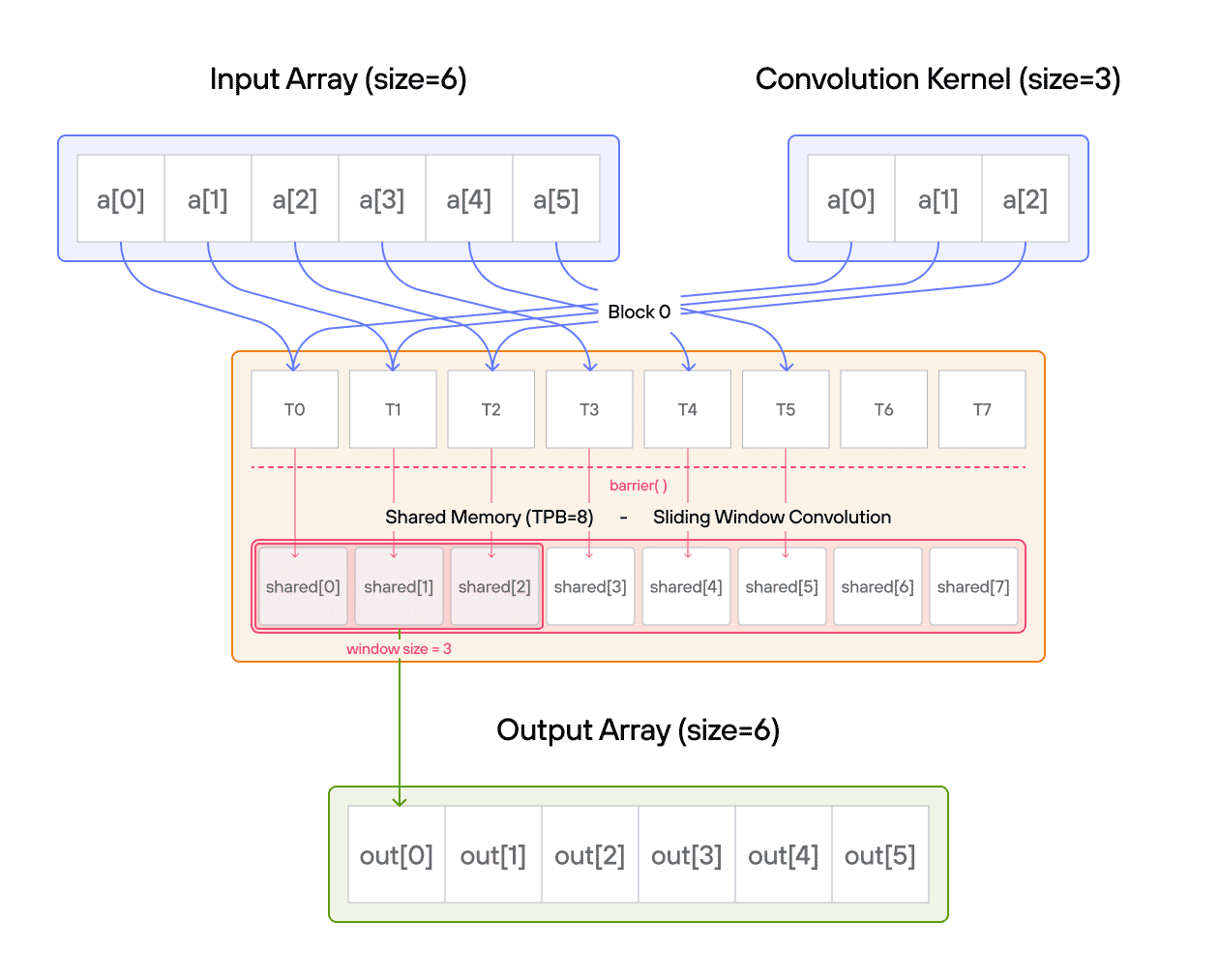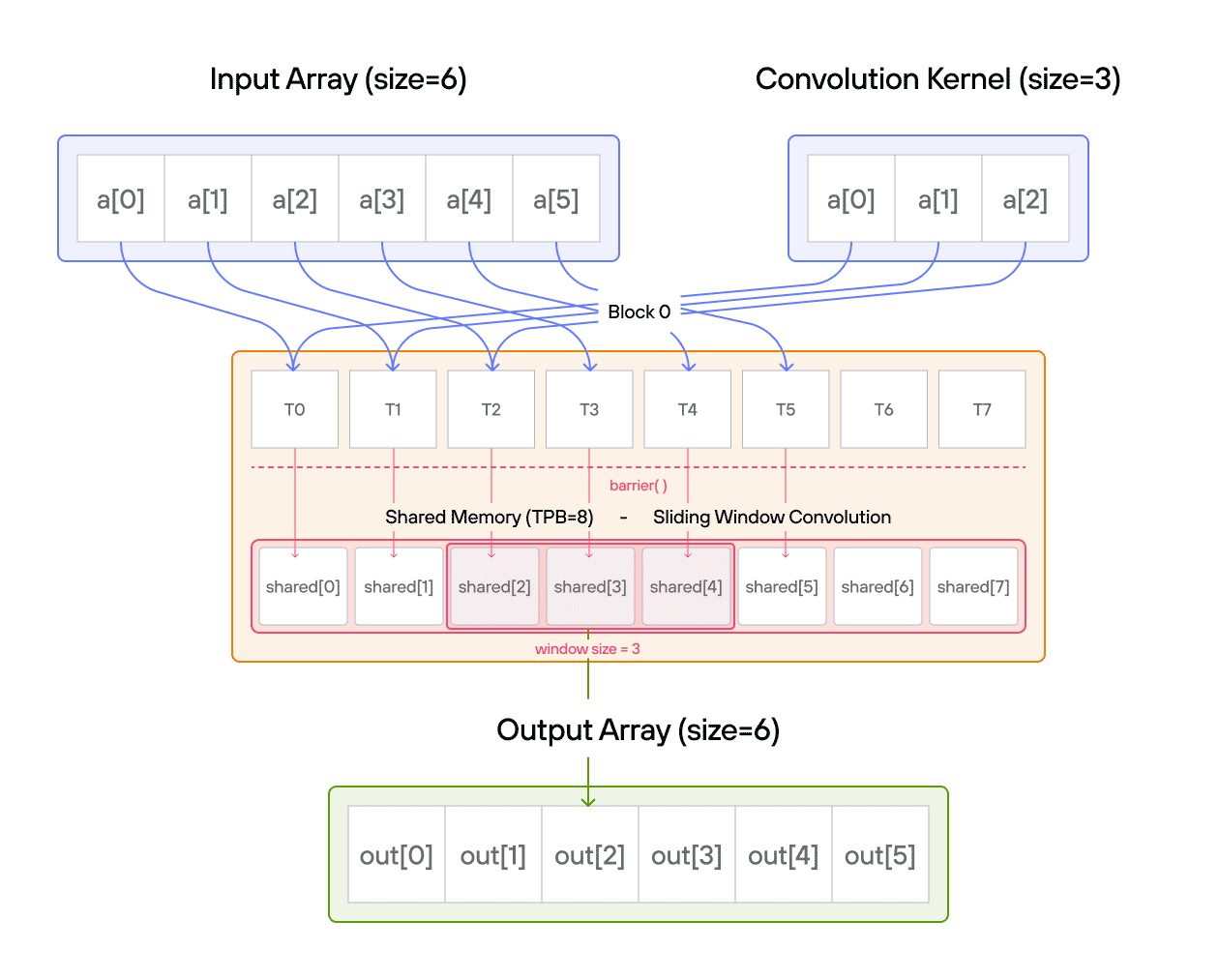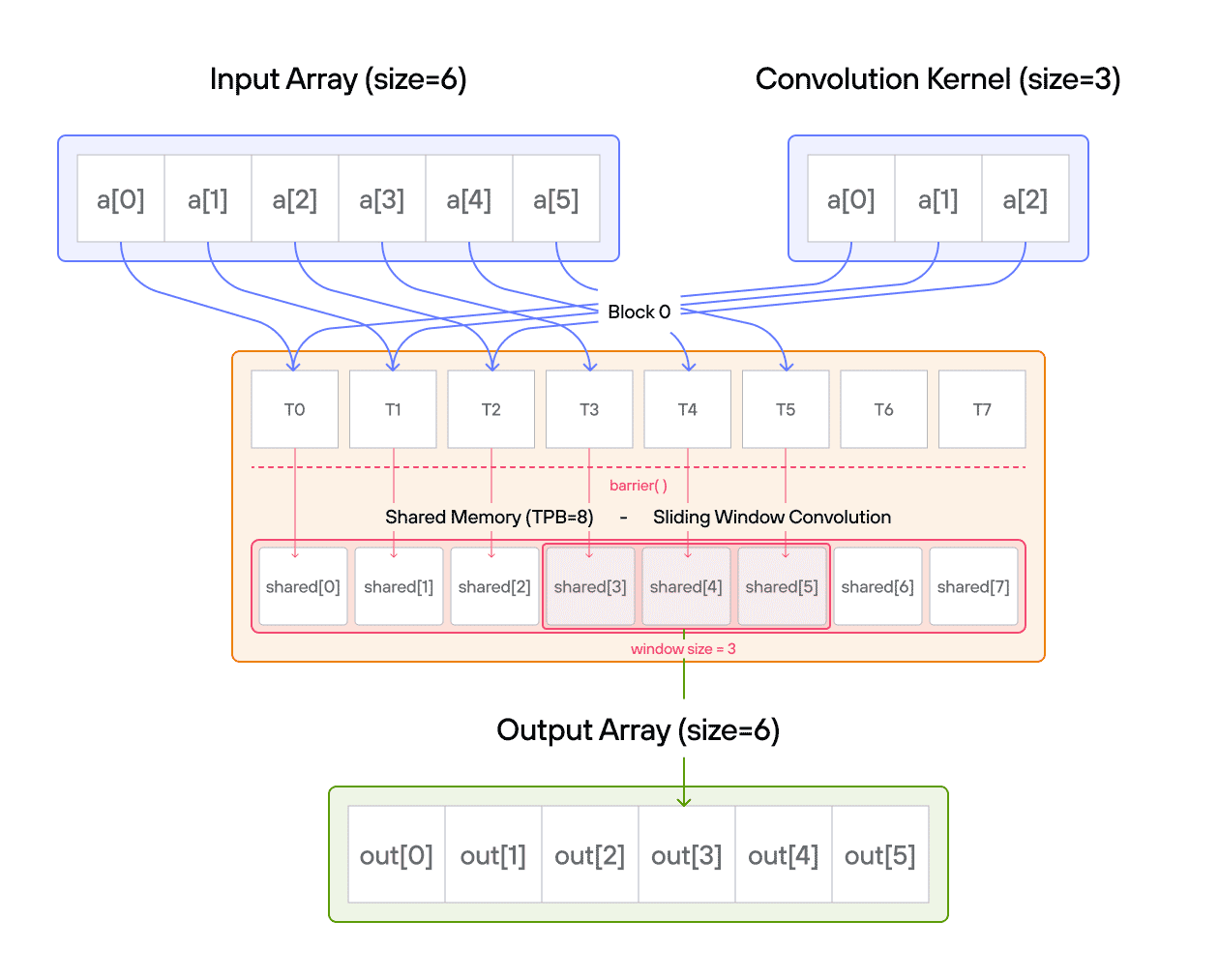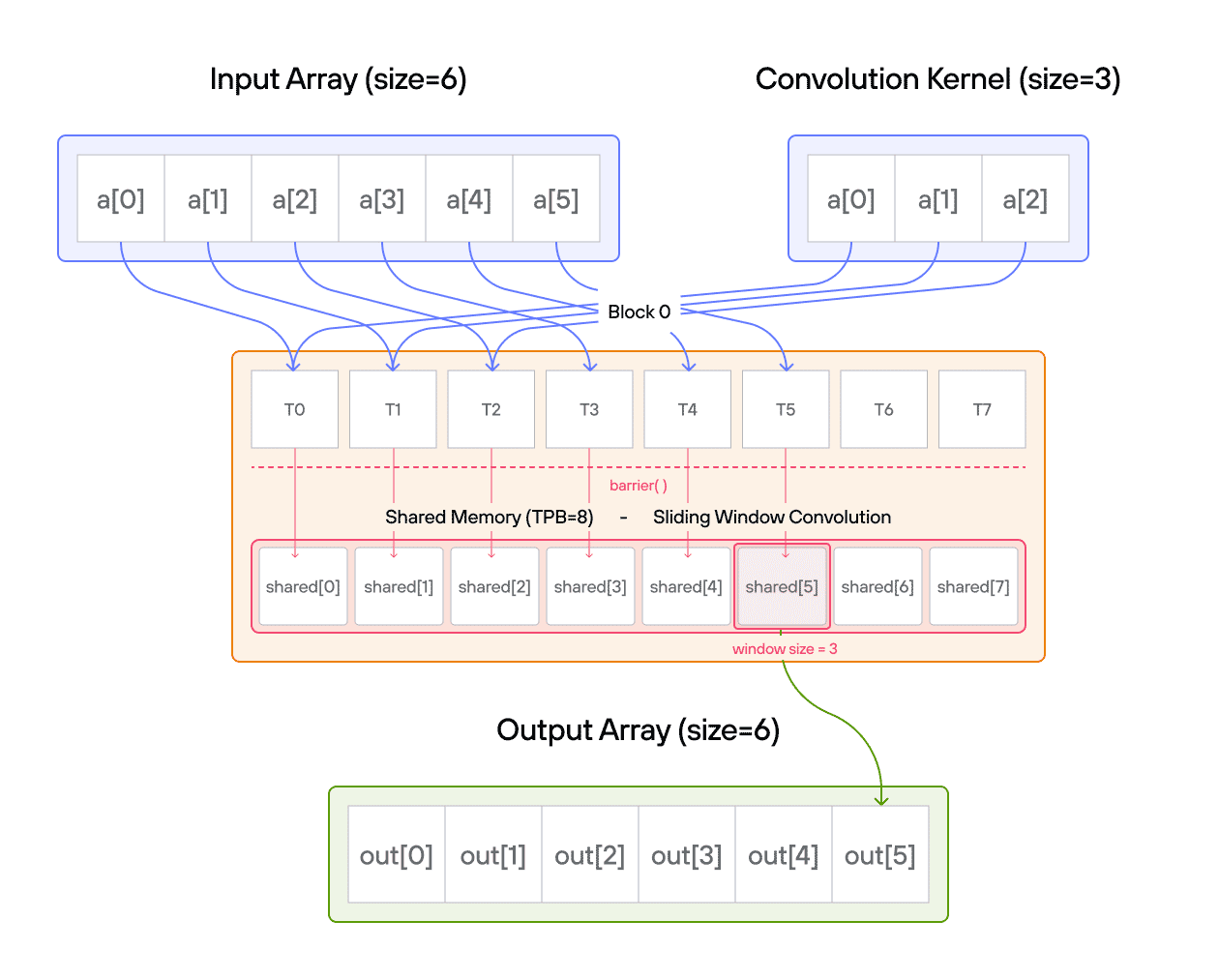
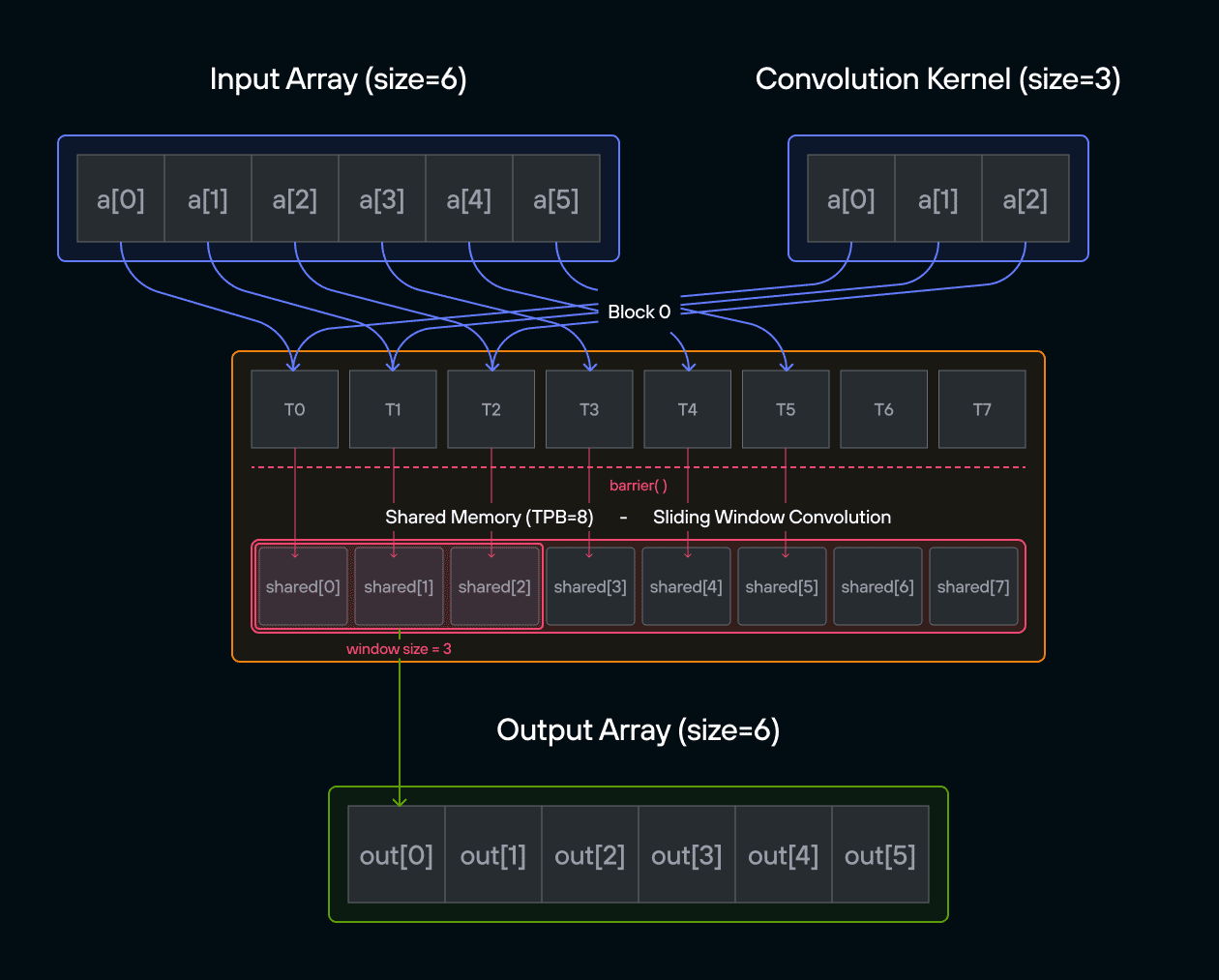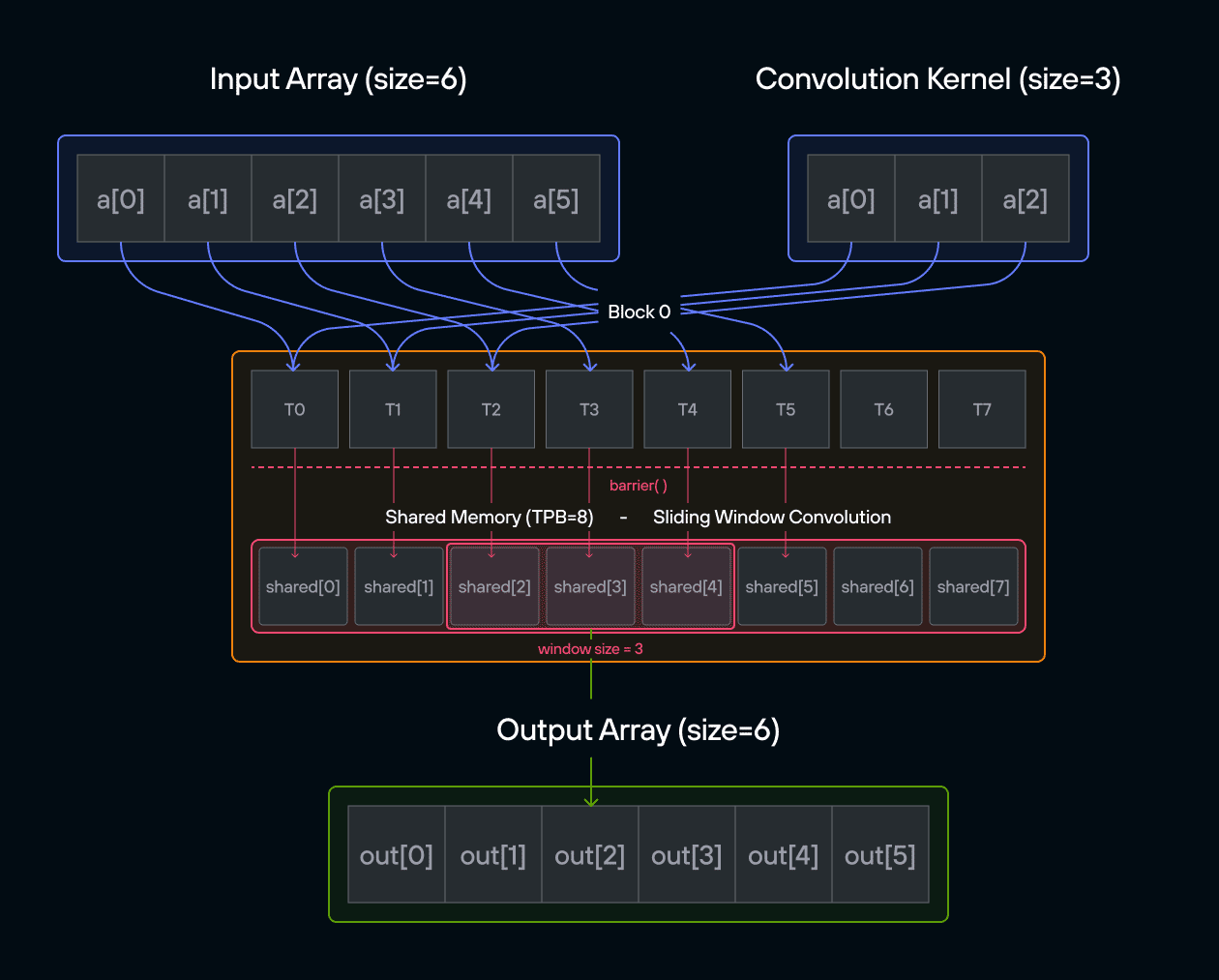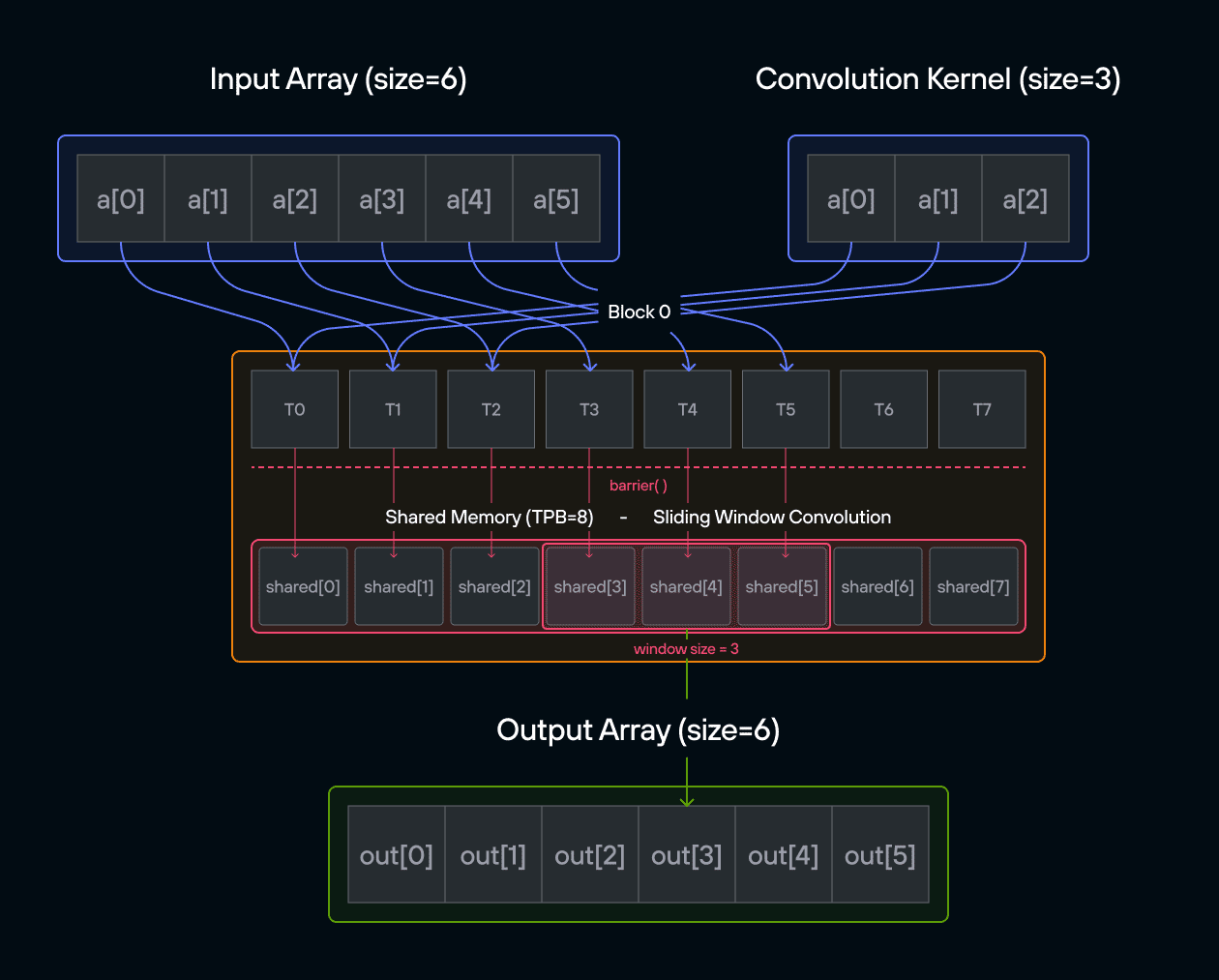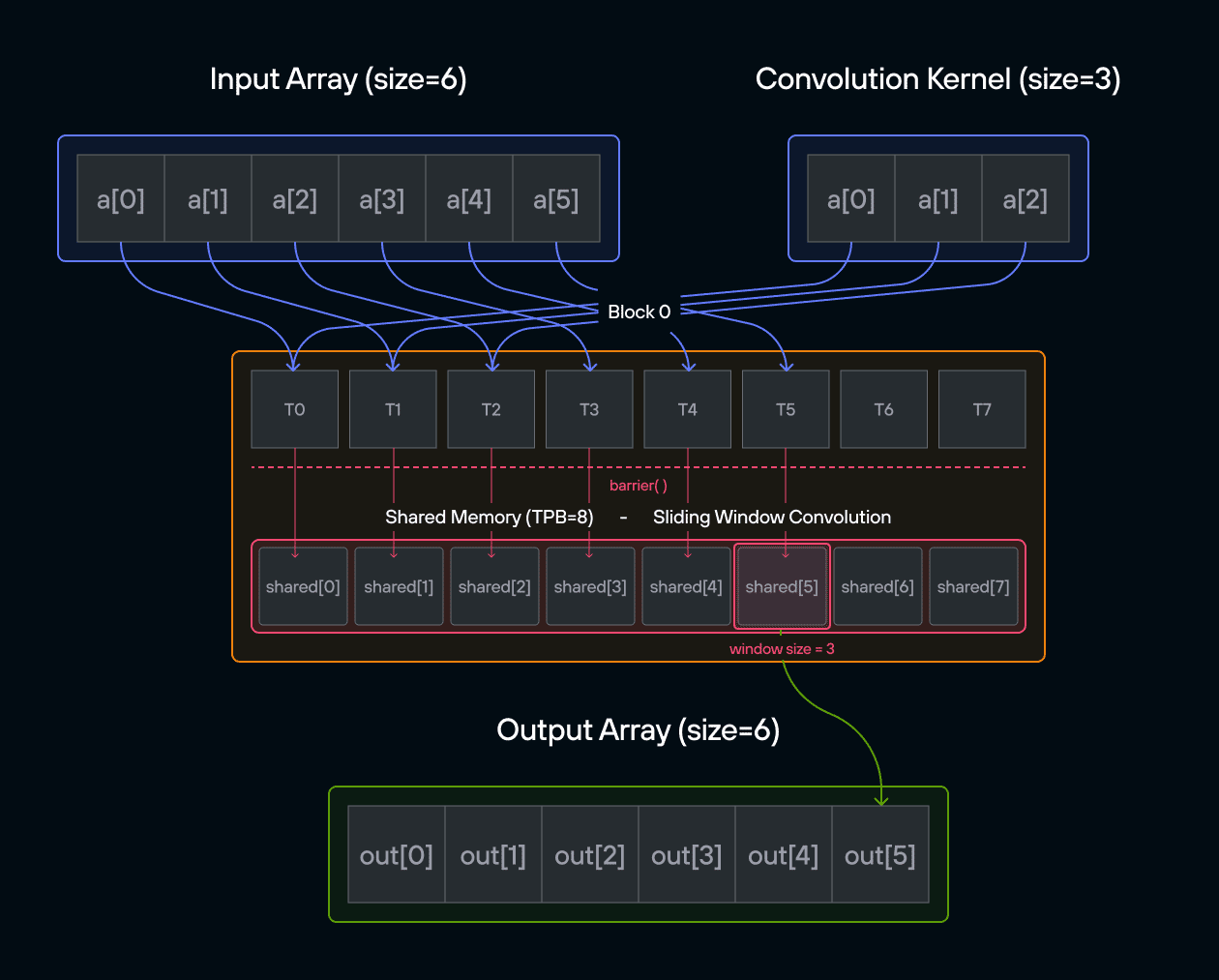
For those new to convolution, think of it as a weighted sliding window operation. At each position, we multiply the kernel values with the corresponding input values and sum the results. In mathematical notation, this is often written as:
\[\Large output[i] = \sum_{j=0}^{\text{CONV}-1} a[i+j] \cdot b[j] \]
In pseudocode, 1D convolution is:
for i in range(SIZE):
for j in range(CONV):
if i + j < SIZE:
ret[i] += a_host[i + j] * b_host[j]
This puzzle is split into two parts to help you build understanding progressively:
-
Simple Version with Single Block Start here to learn the basics of implementing convolution with shared memory in a single block using TileTensor.
-
Block Boundary Version Then tackle the more challenging case where data needs to be shared across block boundaries, leveraging TileTensor’s capabilities.
Each version presents unique challenges in terms of memory access patterns and thread coordination. The simple version helps you understand the basic convolution operation, while the complete version tests your ability to handle more complex scenarios that arise in real-world GPU programming.
Simple Case with Single Block
Implement a kernel that computes a 1D convolution between 1D TileTensor a and
1D TileTensor b and stores it in 1D TileTensor output.
Note: You need to handle the general case. You only need 2 global reads and 1 global write per thread.
Key concepts
This puzzle covers:
- Implementing sliding window operations on GPUs
- Managing data dependencies across threads
- Using shared memory for overlapping regions
The key insight is understanding how to efficiently access overlapping elements while maintaining correct boundary conditions.
Configuration
- Input array size:
SIZE = 6elements - Kernel size:
CONV = 3elements - Threads per block:
TPB = 8 - Number of blocks: 1
- Shared memory: Two arrays of size
SIZEandCONV
Notes:
- Data loading: Each thread loads one element from input and kernel
- Memory pattern: Shared arrays for input and convolution kernel
- Thread sync: Coordination before computation
Code to complete
comptime TPB = 8
comptime SIZE = 6
comptime CONV = 3
comptime BLOCKS_PER_GRID = (1, 1)
comptime THREADS_PER_BLOCK = (TPB, 1)
comptime dtype = DType.float32
comptime in_layout = row_major[SIZE]()
comptime InLayout = type_of(in_layout)
comptime out_layout = row_major[SIZE]()
comptime OutLayout = type_of(out_layout)
comptime conv_layout = row_major[CONV]()
comptime ConvLayout = type_of(conv_layout)
def conv_1d_simple(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, ConvLayout, ImmutAnyOrigin],
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# FILL ME IN (roughly 14 lines)
View full file: problems/p13/p13.mojo
Tips
- Use
stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[SIZE]())for shared memory allocation - Load input to
shared_a[local_i]and kernel toshared_b[local_i] - Call
barrier()after loading - Sum products within bounds:
if local_i + j < SIZE - Write result if
global_i < SIZE
Running the code
To test your solution, run the following command in your terminal:
pixi run p13 --simple
pixi run -e amd p13 --simple
pixi run -e apple p13 --simple
uv run poe p13 --simple
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([5.0, 8.0, 11.0, 14.0, 5.0, 0.0])
Solution
def conv_1d_simple(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, ConvLayout, ImmutAnyOrigin],
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
var shared_a = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[SIZE]())
var shared_b = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[CONV]())
if global_i < SIZE:
shared_a[local_i] = a[global_i]
if global_i < CONV:
shared_b[local_i] = b[global_i]
barrier()
# Note: this is unsafe as it enforces no guard so could access `shared_a` beyond its bounds
# local_sum = Scalar[dtype](0)
# for j in range(CONV):
# if local_i + j < SIZE:
# local_sum += shared_a[local_i + j] * shared_b[j]
# if global_i < SIZE:
# out[global_i] = local_sum
# Safe and correct:
if global_i < SIZE:
# Note: using `var` allows us to include the type in the type inference
# `out.ElementType` is available in TileTensor
var local_sum: output.ElementType = 0
# Note: `@parameter` decorator unrolls the loop at compile time given `CONV` is a compile-time constant
# See: https://docs.modular.com/mojo/manual/decorators/parameter/#parametric-for-statement
comptime for j in range(CONV):
# Bonus: do we need this check for this specific example with fixed SIZE, CONV
if local_i + j < SIZE:
local_sum += shared_a[local_i + j] * shared_b[j]
output[global_i] = local_sum
The solution implements a 1D convolution using shared memory for efficient access to overlapping elements. Here’s a detailed breakdown:
Memory layout
Input array a: [0 1 2 3 4 5]
Kernel b: [0 1 2]
Computation steps
-
Data Loading:
shared_a: [0 1 2 3 4 5] // Input array shared_b: [0 1 2] // Convolution kernel -
Convolution Process for each position i:
output[0] = a[0]*b[0] + a[1]*b[1] + a[2]*b[2] = 0*0 + 1*1 + 2*2 = 5 output[1] = a[1]*b[0] + a[2]*b[1] + a[3]*b[2] = 1*0 + 2*1 + 3*2 = 8 output[2] = a[2]*b[0] + a[3]*b[1] + a[4]*b[2] = 2*0 + 3*1 + 4*2 = 11 output[3] = a[3]*b[0] + a[4]*b[1] + a[5]*b[2] = 3*0 + 4*1 + 5*2 = 14 output[4] = a[4]*b[0] + a[5]*b[1] + 0*b[2] = 4*0 + 5*1 + 0*2 = 5 output[5] = a[5]*b[0] + 0*b[1] + 0*b[2] = 5*0 + 0*1 + 0*2 = 0
Implementation details
- Thread Participation and Efficiency Considerations:
-
The inefficient approach without proper thread guard:
# Inefficient version - all threads compute even when results won't be used local_sum = Scalar[dtype](0) for j in range(CONV): if local_i + j < SIZE: local_sum += shared_a[local_i + j] * shared_b[j] # Only guard the final write if global_i < SIZE: output[global_i] = local_sum -
The efficient and correct implementation:
if global_i < SIZE: var local_sum: output.element_type = 0 # Using var allows type inference @parameter # Unrolls loop at compile time since CONV is constant for j in range(CONV): if local_i + j < SIZE: local_sum += shared_a[local_i + j] * shared_b[j] output[global_i] = local_sum
-
The key difference is that the inefficient version has
all threads perform the convolution computation (including those where
global_i >= SIZE), and only the final write is guarded. This leads to:
- Wasteful computation: Threads beyond the valid range still perform unnecessary work
- Reduced efficiency: Extra computations that won’t be used
- Poor resource utilization: GPU cores working on meaningless calculations
The efficient version ensures that only threads with valid global_i values
perform any computation, making better use of GPU resources.
-
Key Implementation Features:
- Uses
varfor proper type inference withoutput.element_type - Employs
@parameterdecorator to unroll the convolution loop at compile time - Maintains strict bounds checking for memory safety
- Leverages TileTensor’s type system for better code safety
- Uses
-
Memory Management:
- Uses shared memory for both input array and kernel
- Single load per thread from global memory
- Efficient reuse of loaded data
-
Thread Coordination:
barrier()ensures all data is loaded before computation- Each thread computes one output element
- Maintains coalesced memory access pattern
-
Performance Optimizations:
- Minimizes global memory access
- Uses shared memory for fast data access
- Avoids thread divergence in main computation loop
- Loop unrolling through
@parameterdecorator
Block Boundary Version
Implement a kernel that computes a 1D convolution between 1D TileTensor a and
1D TileTensor b and stores it in 1D TileTensor output.
Note: You need to handle the general case. You only need 2 global reads and 1 global write per thread.
Configuration
- Input array size:
SIZE_2 = 15elements - Kernel size:
CONV_2 = 4elements - Threads per block:
TPB = 8 - Number of blocks: 2
- Shared memory:
TPB + CONV_2 - 1elements for input
Notes:
- Extended loading: Account for boundary overlap
- Block edges: Handle data across block boundaries
- Memory layout: Efficient shared memory usage
- Synchronization: Proper thread coordination
Code to complete
comptime SIZE_2 = 15
comptime CONV_2 = 4
comptime BLOCKS_PER_GRID_2 = (2, 1)
comptime THREADS_PER_BLOCK_2 = (TPB, 1)
comptime in_2_layout = row_major[SIZE_2]()
comptime In2Layout = type_of(in_2_layout)
comptime out_2_layout = row_major[SIZE_2]()
comptime Out2Layout = type_of(out_2_layout)
comptime conv_2_layout = row_major[CONV_2]()
comptime Conv2Layout = type_of(conv_2_layout)
def conv_1d_block_boundary(
output: TileTensor[mut=True, dtype, Out2Layout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, In2Layout, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, Conv2Layout, ImmutAnyOrigin],
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# FILL ME IN (roughly 18 lines)
View full file: problems/p13/p13.mojo
Tips
- Use
stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB + CONV_2 - 1]())for shared memory - Load main data:
shared_a[local_i] = a[global_i] - Load boundary:
if local_i < CONV_2 - 1handle next block data - Load kernel:
shared_b[local_i] = b[local_i] - Sum within input bounds:
if global_i + j < SIZE_2
Running the code
To test your solution, run the following command in your terminal:
pixi run p13 --block-boundary
pixi run -e amd p13 --block-boundary
pixi run -e apple p13 --block-boundary
uv run poe p13 --block-boundary
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([14.0, 20.0, 26.0, 32.0, 38.0, 44.0, 50.0, 56.0, 62.0, 68.0, 74.0, 80.0, 41.0, 14.0, 0.0])
Solution
def conv_1d_block_boundary(
output: TileTensor[mut=True, dtype, Out2Layout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, In2Layout, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, Conv2Layout, ImmutAnyOrigin],
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# first: need to account for padding
var shared_a = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB + CONV_2 - 1]())
var shared_b = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[CONV_2]())
if global_i < SIZE_2:
shared_a[local_i] = a[global_i]
else:
shared_a[local_i] = 0
# second: load elements needed for convolution at block boundary
if local_i < CONV_2 - 1:
# indices from next block
var next_idx = global_i + TPB
if next_idx < SIZE_2:
shared_a[TPB + local_i] = a[next_idx]
else:
# Initialize out-of-bounds elements to 0 to avoid reading from uninitialized memory
# which is an undefined behavior
shared_a[TPB + local_i] = 0
if local_i < CONV_2:
shared_b[local_i] = b[local_i]
barrier()
if global_i < SIZE_2:
var local_sum: output.ElementType = 0
comptime for j in range(CONV_2):
if global_i + j < SIZE_2:
local_sum += shared_a[local_i + j] * shared_b[j]
output[global_i] = local_sum
The solution handles block boundary cases in 1D convolution using extended shared memory. Here’s a detailed analysis:
Memory layout and sizing
Test Configuration:
- Full array size: SIZE_2 = 15 elements
- Grid: 2 blocks × 8 threads
- Convolution kernel: CONV_2 = 4 elements
Block 0 shared memory: [0 1 2 3 4 5 6 7|8 9 10] // TPB(8) + (CONV_2-1)(3) padding
Block 1 shared memory: [8 9 10 11 12 13 14 0|0 0 0] // Second block. data(7) + padding to fill grid(1) + (CONV_2-1)(3) padding
Size calculation:
- Main data: TPB elements (8)
- Overlap: CONV_2 - 1 elements (4 - 1 = 3)
- Total: TPB + CONV_2 - 1 = 8 + 4 - 1 = 11 elements
Implementation details
-
Shared Memory Allocation:
# First: account for padding needed for convolution window shared_a = stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB + CONV_2 - 1]()) shared_b = stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[CONV_2]())This allocation pattern ensures we have enough space for both the block’s data and the overlap region.
-
Data Loading Strategy:
# Main block data if global_i < SIZE_2: shared_a[local_i] = a[global_i] else: shared_a[local_i] = 0 # Boundary data from next block if local_i < CONV_2 - 1: next_idx = global_i + TPB if next_idx < SIZE_2: shared_a[TPB + local_i] = a[next_idx] else: # Initialize out-of-bounds elements to 0 to avoid reading from uninitialized memory # which is an undefined behavior shared_a[TPB + local_i] = 0- Only threads with
local_i < CONV_2 - 1load boundary data - Prevents unnecessary thread divergence
- Maintains memory coalescing for main data load
- Explicitly zeroes out-of-bounds elements to avoid undefined behavior
- Only threads with
-
Kernel Loading:
if local_i < b_size: shared_b[local_i] = b[local_i]- Single load per thread
- Bounded by kernel size
-
Convolution Computation:
if global_i < SIZE_2: var local_sum: output.element_type = 0 @parameter for j in range(CONV_2): if global_i + j < SIZE_2: local_sum += shared_a[local_i + j] * shared_b[j]- Uses
@parameterfor compile-time loop unrolling - Proper type inference with
output.element_type - Semantically correct bounds check: only compute convolution for valid input positions
- Uses
Memory access pattern analysis
-
Block 0 Access Pattern:
Thread 0: [0 1 2 3] × [0 1 2 3] Thread 1: [1 2 3 4] × [0 1 2 3] Thread 2: [2 3 4 5] × [0 1 2 3] ... Thread 7: [7 8 9 10] × [0 1 2 3] // Uses overlap data -
Block 1 Access Pattern: Note how starting from thread 4,
global_i + j < SIZE_2evaluates toFalseand hence iterations are skipped.Thread 0: [8 9 10 11] × [0 1 2 3] Thread 1: [9 10 11 12] × [0 1 2 3] ... Thread 4: [12 13 14] × [0 1 2] // Zero padding at end Thread 5: [13 14] × [0 1] Thread 6: [14] × [0] Thread 7: skipped // global_i + j < SIZE_2 evaluates to false for all j, no computation
Performance optimizations
-
Memory Coalescing:
- Main data load: Consecutive threads access consecutive memory
- Boundary data: Only necessary threads participate
- Single barrier synchronization point
-
Thread Divergence Minimization:
- Clean separation of main and boundary loading
- Uniform computation pattern within warps
- Efficient bounds checking
-
Shared Memory Usage:
- Optimal sizing to handle block boundaries
- No bank conflicts in access pattern
- Efficient reuse of loaded data
-
Boundary Handling:
- Explicit zero initialization for out-of-bounds elements which prevents reading from uninitialized shared memory
- Semantically correct boundary checking using
global_i + j < SIZE_2instead of shared memory bounds - Proper handling of edge cases without over-computation
Boundary condition improvement
The solution uses if global_i + j < SIZE_2: rather than checking shared memory
bounds. This pattern is:
- Mathematically correct: Only computes convolution where input data actually exists
- More efficient: Avoids unnecessary computations for positions beyond the input array
- Safer: Prevents reliance on zero-padding behavior in shared memory
This implementation achieves efficient cross-block convolution while maintaining:
- Memory safety through proper bounds checking
- High performance through optimized memory access
- Clean code structure using TileTensor abstractions
- Minimal synchronization overhead
- Mathematically sound boundary handling
Puzzle 14: Prefix Sum
Overview
Prefix sum (also known as scan) is a fundamental parallel algorithm that computes running totals of a sequence. Found at the heart of many parallel applications - from sorting algorithms to scientific simulations - it transforms a sequence of numbers into their running totals. While simple to compute sequentially, making this efficient on a GPU requires clever parallel thinking!
Implement a kernel that computes a prefix-sum over 1D TileTensor a and stores
it in 1D TileTensor output.
Note: If the size of a is greater than the block size, only store the sum
of each block.
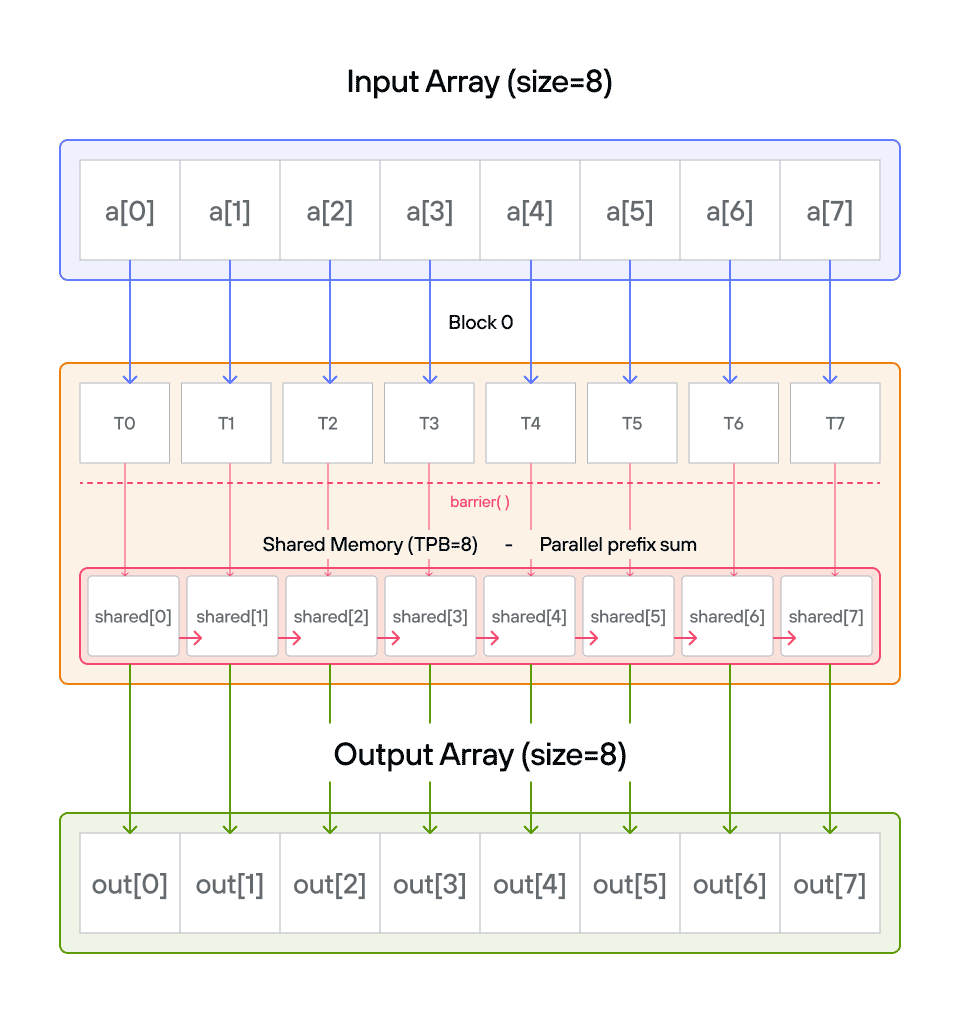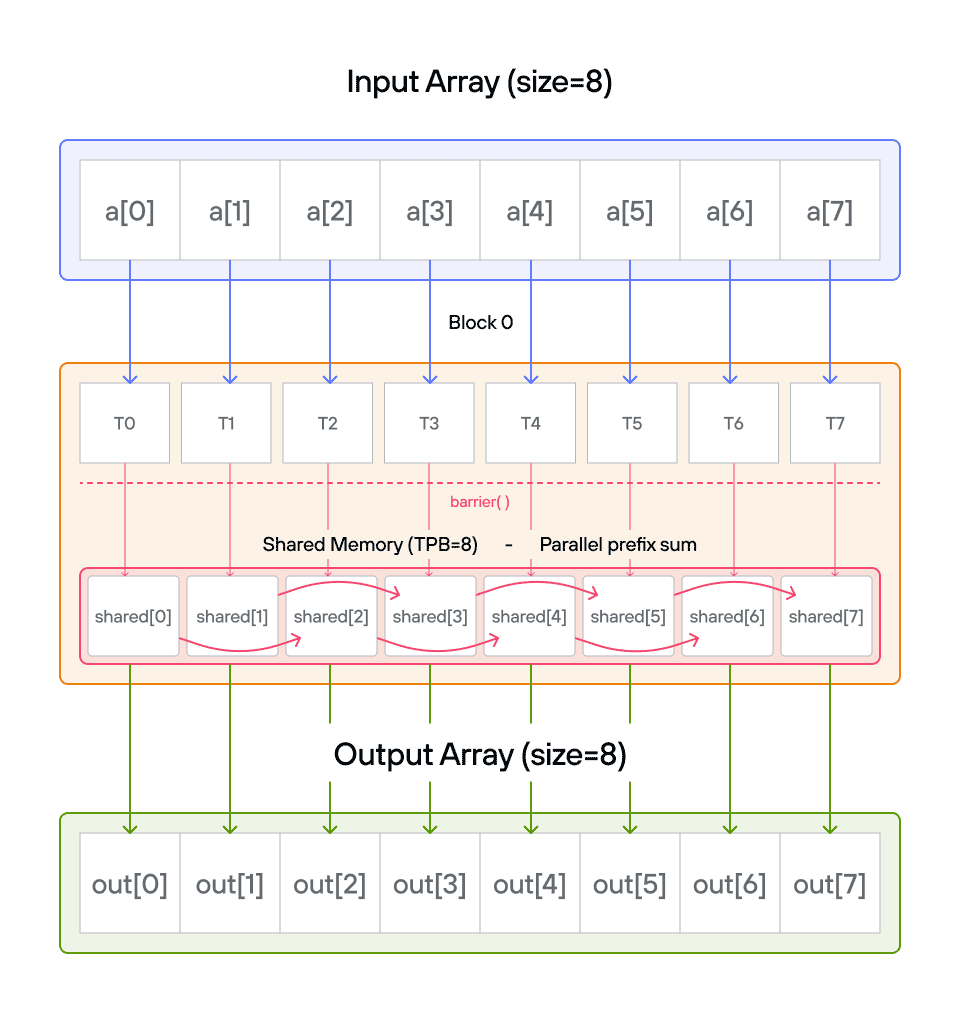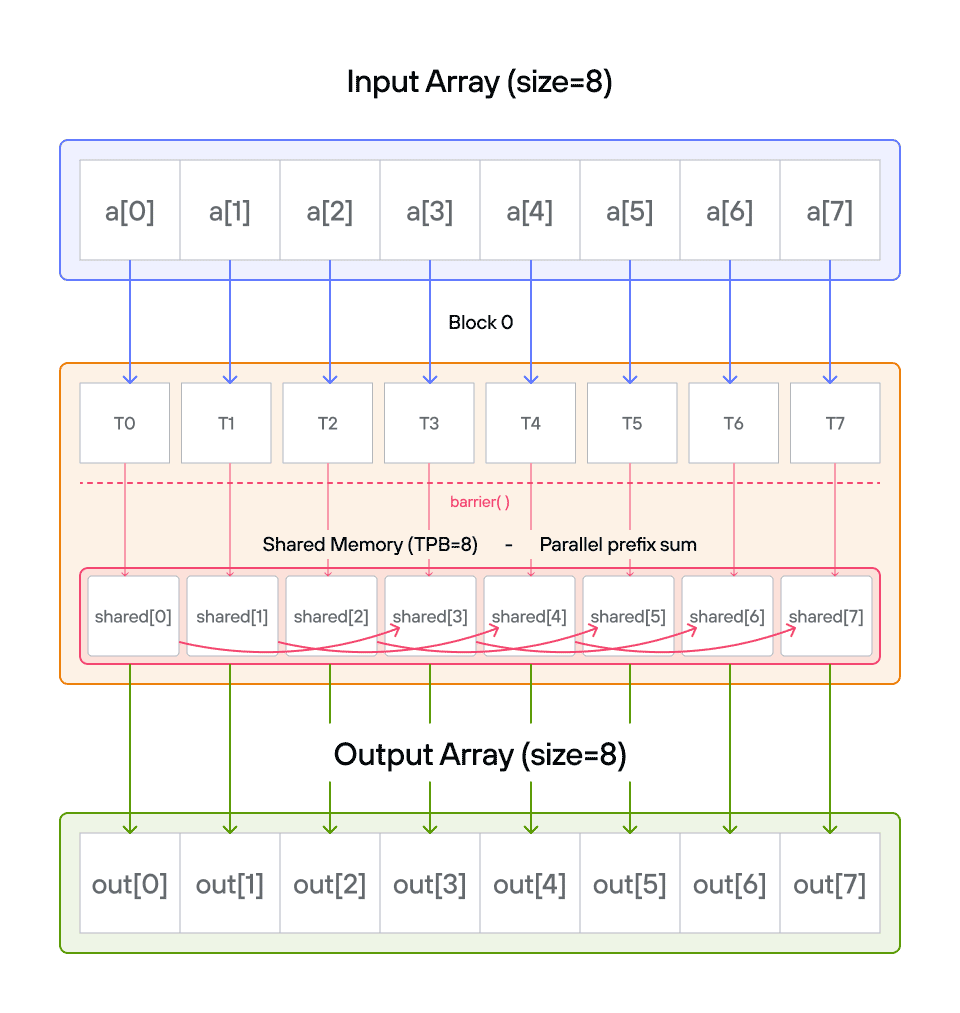
Key concepts
In this puzzle, you’ll learn about:
- Parallel algorithms with logarithmic complexity
- Shared memory coordination patterns
- Multi-phase computation strategies
The key insight is understanding how to transform a sequential operation into an efficient parallel algorithm using shared memory.
For example, given an input sequence \([3, 1, 4, 1, 5, 9]\), the prefix sum would produce:
- \([3]\) (just the first element)
- \([3, 4]\) (3 + 1)
- \([3, 4, 8]\) (previous sum + 4)
- \([3, 4, 8, 9]\) (previous sum + 1)
- \([3, 4, 8, 9, 14]\) (previous sum + 5)
- \([3, 4, 8, 9, 14, 23]\) (previous sum + 9)
Mathematically, for a sequence \([x_0, x_1, …, x_n]\), the prefix sum produces: \[[x_0, x_0+x_1, x_0+x_1+x_2, …, \sum_{i=0}^n x_i] \]
While a sequential algorithm would need \(O(n)\) steps, our parallel approach will use a clever two-phase algorithm that completes in \(O(\log n)\) steps! Here’s a visualization of this process:
This puzzle is split into two parts to help you learn the concept:
-
Simple Version Start with a single block implementation where all data fits in shared memory. This helps understand the core parallel algorithm.
-
Complete Version Then tackle the more challenging case of handling larger arrays that span multiple blocks, requiring coordination between blocks.
Each version builds on the previous one, helping you develop a deep understanding of parallel prefix sum computation. The simple version establishes the fundamental algorithm, while the complete version shows how to scale it to larger datasets - a common requirement in real-world GPU applications.
Simple Version
Implement a kernel that computes a prefix-sum over 1D TileTensor a and stores
it in 1D TileTensor output.
Note: If the size of a is greater than the block size, only store the sum
of each block.
Configuration
- Array size:
SIZE = 8elements - Threads per block:
TPB = 8 - Number of blocks: 1
- Shared memory:
TPBelements
Notes:
- Data loading: Each thread loads one element using TileTensor access
- Memory pattern: Shared memory for intermediate results using TileTensor with address_space
- Thread sync: Coordination between computation phases
- Access pattern: Stride-based parallel computation
- Type safety: Leveraging TileTensor’s type system
Code to complete
comptime TPB = 8
comptime SIZE = 8
comptime BLOCKS_PER_GRID = (1, 1)
comptime THREADS_PER_BLOCK = (TPB, 1)
comptime dtype = DType.float32
comptime layout = row_major[SIZE]()
comptime LayoutType = type_of(layout)
def prefix_sum_simple(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# FILL ME IN (roughly 18 lines)
View full file: problems/p14/p14.mojo
Tips
- Load data into
shared[local_i] - Use
offset = 1and double it each step - Add elements where
local_i >= offset - Call
barrier()between steps
Running the code
To test your solution, run the following command in your terminal:
pixi run p14 --simple
pixi run -e amd p14 --simple
pixi run -e apple p14 --simple
uv run poe p14 --simple
Your output will look like this if the puzzle isn’t solved yet:
out: DeviceBuffer([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([0.0, 1.0, 3.0, 6.0, 10.0, 15.0, 21.0, 28.0])
Solution
def prefix_sum_simple(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
if global_i < size:
shared[local_i] = a[global_i]
barrier()
var offset = 1
for _ in range(Int(log2(Scalar[dtype](TPB)))):
var current_val: output.ElementType = 0
if local_i >= offset and local_i < size:
current_val = shared[local_i - offset] # read
barrier()
if local_i >= offset and local_i < size:
shared[local_i] += current_val
barrier()
offset *= 2
if global_i < size:
output[global_i] = shared[local_i]
The parallel (inclusive) prefix-sum algorithm works as follows:
Setup & Configuration
TPB(Threads Per Block) = 8SIZE(Array Size) = 8
Race condition prevention
The algorithm uses explicit synchronization to prevent read-write hazards:
- Read Phase: All threads first read the values they need into a local
variable
current_val - Synchronization:
barrier()ensures all reads complete before any writes begin - Write Phase: All threads then safely write their computed values back to shared memory
This prevents the race condition that would occur if threads simultaneously read from and write to the same shared memory locations.
Alternative approach: Another solution to prevent race conditions is through double buffering, where you allocate twice the shared memory and alternate between reading from one buffer and writing to another. While this approach eliminates race conditions completely, it requires more shared memory and adds complexity. For educational purposes, we use the explicit synchronization approach as it’s more straightforward to understand.
Thread mapping
thread_idx.x: \([0, 1, 2, 3, 4, 5, 6, 7]\) (local_i)block_idx.x: \([0, 0, 0, 0, 0, 0, 0, 0]\)global_i: \([0, 1, 2, 3, 4, 5, 6, 7]\) (block_idx.x * TPB + thread_idx.x)
Initial load to shared memory
Threads: T₀ T₁ T₂ T₃ T₄ T₅ T₆ T₇
Input array: [0 1 2 3 4 5 6 7]
shared: [0 1 2 3 4 5 6 7]
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
T₀ T₁ T₂ T₃ T₄ T₅ T₆ T₇
Offset = 1: First Parallel Step
Active threads: \(T_1 \ldots T_7\) (where local_i ≥ 1)
Read Phase: Each thread reads the value it needs:
T₁ reads shared[0] = 0 T₅ reads shared[4] = 4
T₂ reads shared[1] = 1 T₆ reads shared[5] = 5
T₃ reads shared[2] = 2 T₇ reads shared[6] = 6
T₄ reads shared[3] = 3
Synchronization: barrier() ensures all reads complete
Write Phase: Each thread adds its read value to its current position:
Before: [0 1 2 3 4 5 6 7]
Add: +0 +1 +2 +3 +4 +5 +6
| | | | | | |
Result: [0 1 3 5 7 9 11 13]
↑ ↑ ↑ ↑ ↑ ↑ ↑
T₁ T₂ T₃ T₄ T₅ T₆ T₇
Offset = 2: Second Parallel Step
Active threads: \(T_2 \ldots T_7\) (where local_i ≥ 2)
Read Phase: Each thread reads the value it needs:
T₂ reads shared[0] = 0 T₅ reads shared[3] = 5
T₃ reads shared[1] = 1 T₆ reads shared[4] = 7
T₄ reads shared[2] = 3 T₇ reads shared[5] = 9
Synchronization: barrier() ensures all reads complete
Write Phase: Each thread adds its read value:
Before: [0 1 3 5 7 9 11 13]
Add: +0 +1 +3 +5 +7 +9
| | | | | |
Result: [0 1 3 6 10 14 18 22]
↑ ↑ ↑ ↑ ↑ ↑
T₂ T₃ T₄ T₅ T₆ T₇
Offset = 4: Third Parallel Step
Active threads: \(T_4 \ldots T_7\) (where local_i ≥ 4)
Read Phase: Each thread reads the value it needs:
T₄ reads shared[0] = 0 T₆ reads shared[2] = 3
T₅ reads shared[1] = 1 T₇ reads shared[3] = 6
Synchronization: barrier() ensures all reads complete
Write Phase: Each thread adds its read value:
Before: [0 1 3 6 10 14 18 22]
Add: +0 +1 +3 +6
| | | |
Result: [0 1 3 6 10 15 21 28]
↑ ↑ ↑ ↑
T₄ T₅ T₆ T₇
Final write to output
Threads: T₀ T₁ T₂ T₃ T₄ T₅ T₆ T₇
global_i: 0 1 2 3 4 5 6 7
output: [0 1 3 6 10 15 21 28]
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
T₀ T₁ T₂ T₃ T₄ T₅ T₆ T₇
Key implementation details
Synchronization Pattern: Each iteration follows a strict read → sync → write pattern:
var current_val: out.element_type = 0- Initialize local variablecurrent_val = shared[local_i - offset]- Read phase (if conditions met)barrier()- Explicit synchronization to prevent race conditionsshared[local_i] += current_val- Write phase (if conditions met)barrier()- Standard synchronization before next iteration
Race Condition Prevention: Without the explicit read-write separation, multiple threads could simultaneously access the same shared memory location, leading to undefined behavior. The two-phase approach with explicit synchronization ensures correctness.
Memory Safety: The algorithm maintains memory safety through:
- Bounds checking with
if local_i >= offset and local_i < size - Proper initialization of the temporary variable
- Coordinated access patterns that prevent data races
The solution ensures correct synchronization between phases using barrier()
and handles array bounds checking with if global_i < size. The final result
produces the inclusive prefix sum where each element \(i\) contains
\(\sum_{j=0}^{i} a[j]\).
Complete Version
Implement a kernel that computes a prefix-sum over 1D TileTensor a and stores
it in 1D TileTensor output.
Note: If the size of a is greater than the block size, we need to
synchronize across multiple blocks to get the correct result.
Configuration
- Array size:
SIZE_2 = 15elements - Threads per block:
TPB = 8 - Number of blocks: 2
- Shared memory:
TPBelements per block
Notes:
- Multiple blocks: When the input array is larger than one block, we need a multi-phase approach
- Block-level sync: Within a block, use
barrier()to synchronize threads - Host-level sync: Between blocks, Mojo’s
DeviceContextensures kernel launches are ordered, which means they start in the order they where scheduled and wait for the previous kernel to finish before starting. You may need to usectx.synchronize()to ensure all GPU work is complete before reading results back to the host. - Auxiliary storage: Use extra space to store block sums for cross-block communication
Code to complete
You need to complete two separate kernel functions for the multi-block prefix sum:
- First kernel (
prefix_sum_local_phase): Computes local prefix sums within each block and stores block sums - Second kernel (
prefix_sum_block_sum_phase): Adds previous block sums to elements in subsequent blocks
The main function will handle the necessary host-side synchronization between these kernels.
comptime SIZE_2 = 15
comptime BLOCKS_PER_GRID_2 = (2, 1)
comptime THREADS_PER_BLOCK_2 = (TPB, 1)
comptime EXTENDED_SIZE = SIZE_2 + 2 # up to 2 blocks
comptime layout_2 = row_major[SIZE_2]()
comptime Layout2Type = type_of(layout_2)
comptime extended_layout = row_major[EXTENDED_SIZE]()
comptime ExtendedLayoutType = type_of(extended_layout)
# Kernel 1: Compute local prefix sums and store block sums in out
def prefix_sum_local_phase(
output: TileTensor[mut=True, dtype, ExtendedLayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, Layout2Type, ImmutAnyOrigin],
size: Int,
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# FILL ME IN (roughly 20 lines)
# Kernel 2: Add block sums to their respective blocks
def prefix_sum_block_sum_phase(
output: TileTensor[mut=True, dtype, ExtendedLayoutType, MutAnyOrigin],
size: Int,
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
# FILL ME IN (roughly 3 lines)
View full file: problems/p14/p14.mojo
The key to this puzzle is understanding that barrier only synchronizes threads within a block, not across blocks. For cross-block synchronization, you need to enqueue multiple kernels that run sequentially on the device:
# Phase 1: Local prefix sums
ctx.enqueue_function[
prefix_sum_local_phase, prefix_sum_local_phase
](
out_tensor,
a_tensor,
size,
grid_dim=BLOCKS_PER_GRID_2,
block_dim=THREADS_PER_BLOCK_2,
)
# Phase 2: Add block sums
ctx.enqueue_function[
prefix_sum_block_sum_phase, prefix_sum_block_sum_phase
](
out_tensor,
size,
grid_dim=BLOCKS_PER_GRID_2,
block_dim=THREADS_PER_BLOCK_2,
)
Note how the two kernels are enqueued sequentially, but out_tensor is not
transferred back to the host until both kernels complete their work. It’s Mojo’s
DeviceContext using a single execution stream that ensures all enqueued
kernels execute sequentially. You can use ctx.synchronize() to explicitly wait
for all GPU work to finish, for example before reading results back to the host.
Tips
1. Build on the simple prefix sum
The Simple Version shows how to implement a single-block prefix sum. You’ll need to extend that approach to work across multiple blocks:
Simple version (single block): [0,1,2,3,4,5,6,7] → [0,1,3,6,10,15,21,28]
Complete version (two blocks):
Block 0: [0,1,2,3,4,5,6,7] → [0,1,3,6,10,15,21,28]
Block 1: [8,9,10,11,12,13,14] → [8,17,27,38,50,63,77]
But how do we handle the second block’s values? They need to include sums from the first block!
2. Two-phase approach
The simple prefix sum can’t synchronize across blocks, so split the work:
- First phase: Each block computes its own local prefix sum (just like the simple version)
- Second phase: Blocks incorporate the sums from previous blocks
Remember: barrier() only synchronizes threads within one block. You need
host-level synchronization between phases.
3. Extended memory strategy
Since blocks can’t directly communicate, you need somewhere to store block sums:
- Allocate extra memory at the end of your output buffer
- Last thread in each block stores its final sum in this extra space
- Subsequent blocks can read these sums and add them to their elements
4. Key implementation insights
- Different layouts: Input and output may have different shapes
- Boundary handling: Always check
global_i < sizefor array bounds - Thread role specialization: Only specific threads (e.g., last thread) should store block sums
- Two kernel synchronization: It must be ensured that the second kernel runs only after the first kernel completes.
5. Debugging Strategy
If you encounter issues, try visualizing the intermediate state after the first phase:
After first phase: [0,1,3,6,10,15,21,28, 8,17,27,38,50,63,77, ???,???]
Where ??? should contain your block sums that will be used in the second
phase.
Remember, to inspect intermediate results you need to explicitly ensure that the device has completed its work.
Running the code
To test your solution, run the following command in your terminal:
pixi run p14 --complete
pixi run -e amd p14 --complete
pixi run -e apple p14 --complete
uv run poe p14 --complete
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([0.0, 1.0, 3.0, 6.0, 10.0, 15.0, 21.0, 28.0, 36.0, 45.0, 55.0, 66.0, 78.0, 91.0, 105.0])
Solution
# Kernel 1: Compute local prefix sums and store block sums in out
def prefix_sum_local_phase(
output: TileTensor[mut=True, dtype, ExtendedLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, Layout2Type, ImmutAnyOrigin],
size: Int,
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
# Load data into shared memory
# Example with SIZE_2=15, TPB=8, BLOCKS=2:
# Block 0 shared mem: [0,1,2,3,4,5,6,7]
# Block 1 shared mem: [8,9,10,11,12,13,14,uninitialized]
# Note: The last position remains uninitialized since global_i >= size,
# but this is safe because that thread doesn't participate in computation
if global_i < size:
shared[local_i] = a[global_i]
barrier()
# Compute local prefix sum using parallel reduction
# This uses a tree-based algorithm with log(TPB) iterations
# Iteration 1 (offset=1):
# Block 0: [0,0+1,2+1,3+2,4+3,5+4,6+5,7+6] = [0,1,3,5,7,9,11,13]
# Iteration 2 (offset=2):
# Block 0: [0,1,3+0,5+1,7+3,9+5,11+7,13+9] = [0,1,3,6,10,14,18,22]
# Iteration 3 (offset=4):
# Block 0: [0,1,3,6,10+0,14+1,18+3,22+6] = [0,1,3,6,10,15,21,28]
# Block 1 follows same pattern to get [8,17,27,38,50,63,77,???]
var offset = 1
for _ in range(Int(log2(Scalar[dtype](TPB)))):
var current_val: output.ElementType = 0
if local_i >= offset and local_i < TPB:
current_val = shared[local_i - offset] # read
barrier()
if local_i >= offset and local_i < TPB:
shared[local_i] += current_val # write
barrier()
offset *= 2
# Write local results to output
# Block 0 writes: [0,1,3,6,10,15,21,28]
# Block 1 writes: [8,17,27,38,50,63,77,???]
if global_i < size:
output[global_i] = shared[local_i]
# Store block sums in auxiliary space
# Block 0: Thread 7 stores shared[7] == 28 at position size+0 (position 15)
# Block 1: Thread 7 stores shared[7] == ??? at position size+1 (position 16). This sum is not needed for the final output.
# This gives us: [0,1,3,6,10,15,21,28, 8,17,27,38,50,63,77, 28,???]
# ↑ ↑
# Block sums here
if local_i == TPB - 1:
output[size + block_idx.x] = shared[local_i]
# Kernel 2: Add block sums to their respective blocks
def prefix_sum_block_sum_phase(
output: TileTensor[mut=True, dtype, ExtendedLayout, MutAnyOrigin],
size: Int,
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
# Second pass: add previous block's sum to each element
# Block 0: No change needed - already correct
# Block 1: Add Block 0's sum (28) to each element
# Before: [8,17,27,38,50,63,77]
# After: [36,45,55,66,78,91,105]
# Final result combines both blocks:
# [0,1,3,6,10,15,21,28, 36,45,55,66,78,91,105]
if block_idx.x > 0 and global_i < size:
var prev_block_sum = output[size + block_idx.x - 1]
output[global_i] += prev_block_sum
This solution implements a multi-block prefix sum using a two-kernel approach to handle an array that spans multiple thread blocks. Let’s break down each aspect in detail:
The challenge of cross-block communication
The fundamental limitation in GPU programming is that threads can only
synchronize within a block using barrier(). When data spans multiple blocks,
we face the challenge: How do we ensure blocks can communicate their partial
results to other blocks?
Memory layout visualization
For our test case with SIZE_2 = 15 and TPB = 8:
Input array: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
Block 0 processes: [0, 1, 2, 3, 4, 5, 6, 7]
Block 1 processes: [8, 9, 10, 11, 12, 13, 14] (7 valid elements)
We extend the output buffer to include space for block sums:
Extended buffer: [data values (15 elements)] + [block sums (2 elements)]
[0...14] + [block0_sum, block1_sum]
The size of this extended buffer is:
EXTENDED_SIZE = SIZE_2 + num_blocks = 15 + 2 = 17
Phase 1 kernel: Local prefix sums
Race condition prevention in local phase
The local phase uses the same explicit synchronization pattern as the simple version to prevent read-write hazards:
- Read Phase: All threads first read the values they need into a local
variable
current_val - Synchronization:
barrier()ensures all reads complete before any writes begin - Write Phase: All threads then safely write their computed values back to shared memory
This prevents race conditions that could occur when multiple threads simultaneously access the same shared memory locations during the parallel reduction.
Step-by-step execution for Block 0
-
Load values into shared memory:
shared = [0, 1, 2, 3, 4, 5, 6, 7] -
Iterations of parallel reduction (\(\log_2(TPB) = 3\) iterations):
Iteration 1 (offset=1):
Read Phase: Each active thread reads the value it needs:
T₁ reads shared[0] = 0 T₅ reads shared[4] = 4 T₂ reads shared[1] = 1 T₆ reads shared[5] = 5 T₃ reads shared[2] = 2 T₇ reads shared[6] = 6 T₄ reads shared[3] = 3Synchronization:
barrier()ensures all reads completeWrite Phase: Each thread adds its read value:
shared[0] = 0 (unchanged) shared[1] = 1 + 0 = 1 shared[2] = 2 + 1 = 3 shared[3] = 3 + 2 = 5 shared[4] = 4 + 3 = 7 shared[5] = 5 + 4 = 9 shared[6] = 6 + 5 = 11 shared[7] = 7 + 6 = 13After barrier:
shared = [0, 1, 3, 5, 7, 9, 11, 13]Iteration 2 (offset=2):
Read Phase: Each active thread reads the value it needs:
T₂ reads shared[0] = 0 T₅ reads shared[3] = 5 T₃ reads shared[1] = 1 T₆ reads shared[4] = 7 T₄ reads shared[2] = 3 T₇ reads shared[5] = 9Synchronization:
barrier()ensures all reads completeWrite Phase: Each thread adds its read value:
shared[0] = 0 (unchanged) shared[1] = 1 (unchanged) shared[2] = 3 + 0 = 3 (unchanged) shared[3] = 5 + 1 = 6 shared[4] = 7 + 3 = 10 shared[5] = 9 + 5 = 14 shared[6] = 11 + 7 = 18 shared[7] = 13 + 9 = 22After barrier:
shared = [0, 1, 3, 6, 10, 14, 18, 22]Iteration 3 (offset=4):
Read Phase: Each active thread reads the value it needs:
T₄ reads shared[0] = 0 T₆ reads shared[2] = 3 T₅ reads shared[1] = 1 T₇ reads shared[3] = 6Synchronization:
barrier()ensures all reads completeWrite Phase: Each thread adds its read value:
shared[0] = 0 (unchanged) shared[1] = 1 (unchanged) shared[2] = 3 (unchanged) shared[3] = 6 (unchanged) shared[4] = 10 + 0 = 10 (unchanged) shared[5] = 14 + 1 = 15 shared[6] = 18 + 3 = 21 shared[7] = 22 + 6 = 28After barrier:
shared = [0, 1, 3, 6, 10, 15, 21, 28] -
Write local results back to global memory:
output[0...7] = [0, 1, 3, 6, 10, 15, 21, 28] -
Store block sum in auxiliary space (only last thread):
output[15] = 28 // at position size + block_idx.x = 15 + 0
Step-by-step execution for Block 1
-
Load values into shared memory:
shared = [8, 9, 10, 11, 12, 13, 14, uninitialized]Note: Thread 7 doesn’t load anything since
global_i = 15 >= SIZE_2, leavingshared[7]uninitialized. This is safe because Thread 7 won’t participate in the final output. -
Iterations of parallel reduction (\(\log_2(TPB) = 3\) iterations):
Only the first 7 threads participate in meaningful computation. After all three iterations:
shared = [8, 17, 27, 38, 50, 63, 77, uninitialized] -
Write local results back to global memory:
output[8...14] = [8, 17, 27, 38, 50, 63, 77] // Only 7 valid outputs -
Store block sum in auxiliary space (only last thread in block):
output[16] = shared[7] // Thread 7 (TPB-1) stores whatever is in shared[7]Note: Even though Thread 7 doesn’t load valid input data, it still participates in the prefix sum computation within the block. The
shared[7]position gets updated during the parallel reduction iterations, but since it started uninitialized, the final value is unpredictable. However, this doesn’t affect correctness because Block 1 is the last block, so this block sum is never used in Phase 2.
After Phase 1, the output buffer contains:
[0, 1, 3, 6, 10, 15, 21, 28, 8, 17, 27, 38, 50, 63, 77, 28, ???]
^ ^
Block sums stored here
Note: The last block sum (???) is unpredictable since it’s based on uninitialized memory, but this doesn’t affect the final result.
Host-device synchronization: When it’s actually needed
The two kernel phases execute sequentially without any explicit synchronization between them:
# Phase 1: Local prefix sums
ctx.enqueue_function[prefix_sum_local_phase[...], prefix_sum_local_phase[...]](...)
# Phase 2: Add block sums (automatically waits for Phase 1)
ctx.enqueue_function[prefix_sum_block_sum_phase[...], prefix_sum_block_sum_phase[...]](...)
Key insight: Mojo’s DeviceContext uses a single execution stream (CUDA
stream on NVIDIA GPUs, HIP stream on AMD ROCm GPUs), which guarantees that
kernel launches execute in the exact order they are enqueued. No explicit
synchronization is needed between kernels.
When ctx.synchronize() is needed:
# After both kernels complete, before reading results on host
ctx.synchronize() # Host waits for GPU to finish
with out.map_to_host() as out_host: # Now safe to read GPU results
print("out:", out_host)
The ctx.synchronize() call serves its traditional purpose:
- Host-device synchronization: Ensures the host waits for all GPU work to complete before accessing results
- Memory safety: Prevents reading GPU memory before computations finish
Execution model: Unlike barrier() which synchronizes threads within a
block, kernel ordering comes from Mojo’s single-stream execution model, while
ctx.synchronize() handles host-device coordination.
Phase 2 kernel: Block sum addition
-
Block 0: No changes needed (it’s already correct).
-
Block 1: Each thread adds Block 0’s sum to its element:
prev_block_sum = output[size + block_idx.x - 1] = output[15] = 28 output[global_i] += prev_block_sumBlock 1 values are transformed:
Before: [8, 17, 27, 38, 50, 63, 77] After: [36, 45, 55, 66, 78, 91, 105]
Performance and optimization considerations
Key implementation details
Local phase synchronization pattern: Each iteration within a block follows a strict read → sync → write pattern:
var current_val: out.element_type = 0- Initialize local variablecurrent_val = shared[local_i - offset]- Read phase (if conditions met)barrier()- Explicit synchronization to prevent race conditionsshared[local_i] += current_val- Write phase (if conditions met)barrier()- Standard synchronization before next iteration
Cross-block synchronization: The algorithm uses two levels of synchronization:
- Intra-block:
barrier()synchronizes threads within each block during local prefix sum computation - Inter-block: The
DeviceContextcontext manager that launches enqueued kernels sequentially to ensure Phase 1 completes before Phase 2 begins. To explicitly enforce host-device synchronization before reading results,ctx.synchronize()is used.
Race condition prevention: The explicit read-write separation in the local phase prevents the race condition that would occur if threads simultaneously read from and write to the same shared memory locations during parallel reduction.
-
Work efficiency: This implementation has \(O(n \log n)\) work complexity, while the sequential algorithm is \(O(n)\). This is a classic space-time tradeoff in parallel algorithms.
-
Memory overhead: The extra space for block sums is minimal (just one element per block).
This two-kernel approach is a fundamental pattern in GPU programming for algorithms that require cross-block communication. The same strategy can be applied to other parallel algorithms like radix sort, histogram calculation, and reduction operations.
Puzzle 15: Axis Sum
Overview
Implement a kernel that computes a sum over each row of 2D matrix a and stores
it in output using TileTensor.
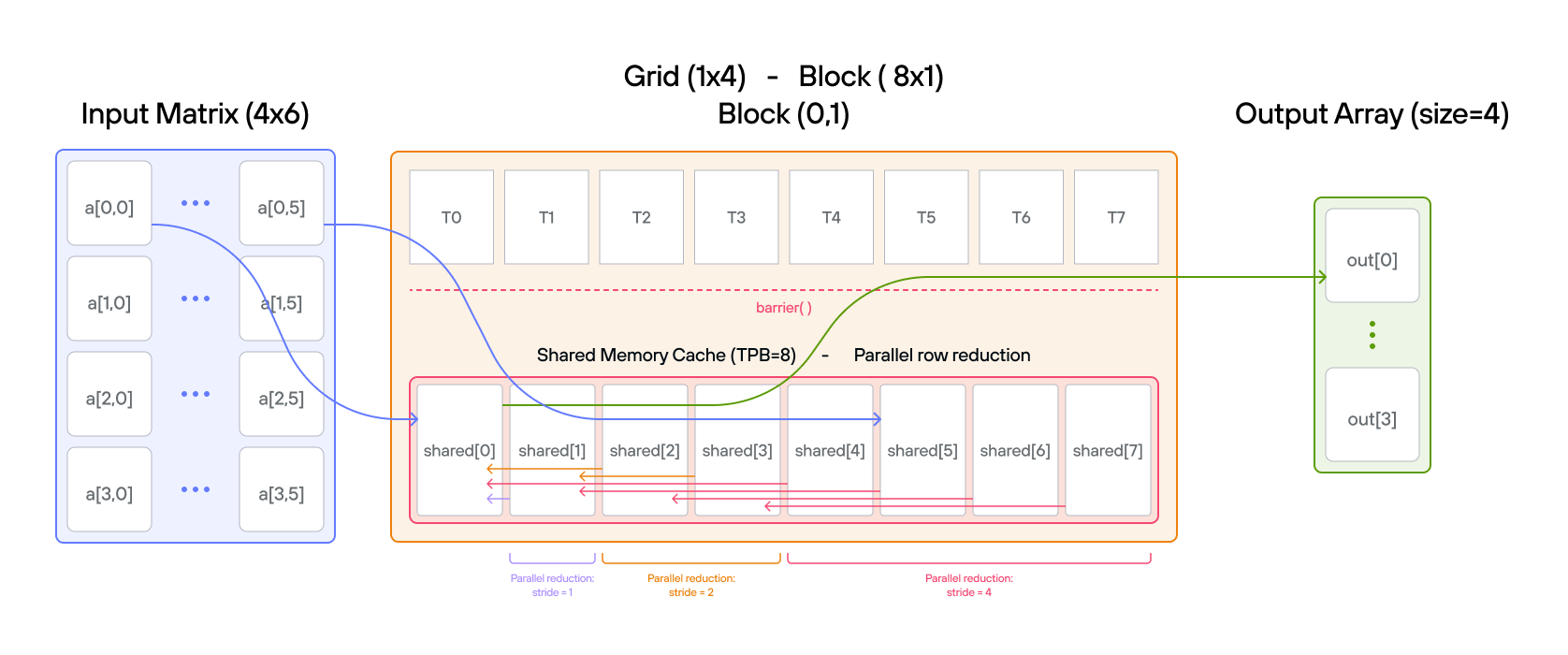
Key concepts
This puzzle covers:
- Parallel reduction along matrix dimensions using TileTensor
- Using block coordinates for data partitioning
- Efficient shared memory reduction patterns
- Working with multi-dimensional tensor layouts
The key insight is understanding how to map thread blocks to matrix rows and perform efficient parallel reduction within each block while leveraging TileTensor’s dimensional indexing.
Configuration
- Matrix dimensions: \(\text{BATCH} \times \text{SIZE} = 4 \times 6\)
- Threads per block: \(\text{TPB} = 8\)
- Grid dimensions: \(1 \times \text{BATCH}\)
- Shared memory: \(\text{TPB}\) elements per block
- Input layout:
row_major[BATCH, SIZE]() - Output layout:
row_major[BATCH, 1]()
Matrix visualization:
Row 0: [0, 1, 2, 3, 4, 5] → Block(0,0)
Row 1: [6, 7, 8, 9, 10, 11] → Block(0,1)
Row 2: [12, 13, 14, 15, 16, 17] → Block(0,2)
Row 3: [18, 19, 20, 21, 22, 23] → Block(0,3)
Code to Complete
from std.gpu import thread_idx, block_idx, block_dim, barrier
from std.gpu.memory import AddressSpace
from layout import TileTensor
from layout.tile_layout import row_major
from layout.tile_tensor import stack_allocation
comptime TPB = 8
comptime BATCH = 4
comptime SIZE = 6
comptime BLOCKS_PER_GRID = (1, BATCH)
comptime THREADS_PER_BLOCK = (TPB, 1)
comptime dtype = DType.float32
comptime in_layout = row_major[BATCH, SIZE]()
comptime InLayout = type_of(in_layout)
comptime out_layout = row_major[BATCH, 1]()
comptime OutLayout = type_of(out_layout)
def axis_sum(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
size: Int,
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
var batch = block_idx.y
# FILL ME IN (roughly 15 lines)
View full file: problems/p15/p15.mojo
Tips
- Use
batch = block_idx.yto select row - Load elements:
cache[local_i] = a[batch, local_i] - Perform parallel reduction with halving stride
- Thread 0 writes final sum to
output[batch]
Running the Code
To test your solution, run the following command in your terminal:
pixi run p15
pixi run -e amd p15
pixi run -e apple p15
uv run poe p15
Your output will look like this if the puzzle isn’t solved yet:
out: DeviceBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([15.0, 51.0, 87.0, 123.0])
Solution
def axis_sum(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
size: Int,
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
var batch = block_idx.y
var cache = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
# Visualize:
# Block(0,0): [T0,T1,T2,T3,T4,T5,T6,T7] -> Row 0: [0,1,2,3,4,5]
# Block(0,1): [T0,T1,T2,T3,T4,T5,T6,T7] -> Row 1: [6,7,8,9,10,11]
# Block(0,2): [T0,T1,T2,T3,T4,T5,T6,T7] -> Row 2: [12,13,14,15,16,17]
# Block(0,3): [T0,T1,T2,T3,T4,T5,T6,T7] -> Row 3: [18,19,20,21,22,23]
# each row is handled by each block bc we have grid_dim=(1, BATCH)
if local_i < size:
cache[local_i] = a[batch, local_i]
else:
# Add zero-initialize padding elements for later reduction
cache[local_i] = 0
barrier()
# do reduction sum per each block
var stride = TPB // 2
while stride > 0:
# Read phase: all threads read the values they need first to avoid race conditions
var temp_val: output.ElementType = 0
if local_i < stride:
temp_val = cache[local_i + stride]
barrier()
# Write phase: all threads safely write their computed values
if local_i < stride:
cache[local_i] += temp_val
barrier()
stride //= 2
# writing with local thread = 0 that has the sum for each batch
if local_i == 0:
output[batch, 0] = cache[0]
The solution implements a parallel row-wise sum reduction for a 2D matrix using TileTensor. Here’s a comprehensive breakdown:
Matrix layout and block mapping
Input Matrix (4×6) with TileTensor: Block Assignment:
[[ a[0,0] a[0,1] a[0,2] a[0,3] a[0,4] a[0,5] ] → Block(0,0)
[ a[1,0] a[1,1] a[1,2] a[1,3] a[1,4] a[1,5] ] → Block(0,1)
[ a[2,0] a[2,1] a[2,2] a[2,3] a[2,4] a[2,5] ] → Block(0,2)
[ a[3,0] a[3,1] a[3,2] a[3,3] a[3,4] a[3,5] ] → Block(0,3)
Parallel reduction process
-
Initial Data Loading:
Block(0,0): cache = [a[0,0] a[0,1] a[0,2] a[0,3] a[0,4] a[0,5] * *] // * = padding Block(0,1): cache = [a[1,0] a[1,1] a[1,2] a[1,3] a[1,4] a[1,5] * *] Block(0,2): cache = [a[2,0] a[2,1] a[2,2] a[2,3] a[2,4] a[2,5] * *] Block(0,3): cache = [a[3,0] a[3,1] a[3,2] a[3,3] a[3,4] a[3,5] * *] -
Reduction Steps (for Block 0,0):
Initial: [0 1 2 3 4 5 * *] Stride 4: [4 5 6 7 4 5 * *] Stride 2: [10 12 6 7 4 5 * *] Stride 1: [15 12 6 7 4 5 * *]
Key implementation features
-
Layout Configuration:
- Input: row-major layout (BATCH × SIZE)
- Output: row-major layout (BATCH × 1)
- Each block processes one complete row
-
Memory Access Pattern:
- TileTensor 2D indexing for input:
a[batch, local_i] - Shared memory for efficient reduction
- TileTensor 2D indexing for output:
output[batch, 0]
- TileTensor 2D indexing for input:
-
Parallel Reduction Logic:
stride = TPB // 2 while stride > 0: if local_i < stride: cache[local_i] += cache[local_i + stride] barrier() stride //= 2Note: This implementation has a potential race condition where threads simultaneously read from and write to shared memory during the same iteration. A safer approach would separate the read and write phases:
stride = TPB // 2 while stride > 0: var temp_val: output.element_type = 0 if local_i < stride: temp_val = cache[local_i + stride] # Read phase barrier() if local_i < stride: cache[local_i] += temp_val # Write phase barrier() stride //= 2 -
Output Writing:
if local_i == 0: output[batch, 0] = cache[0] --> One result per batch
Performance optimizations
-
Memory Efficiency:
- Coalesced memory access through TileTensor
- Shared memory for fast reduction
- Single write per row result
-
Thread Utilization:
- Perfect load balancing across rows
- No thread divergence in main computation
- Efficient parallel reduction pattern
-
Synchronization:
- Minimal barriers (only during reduction)
- Independent processing between rows
- No inter-block communication needed
- Race condition consideration: The current implementation may have read-write hazards during parallel reduction that could be resolved with explicit read-write phase separation
Complexity analysis
- Time: \(O(\log n)\) per row, where n is row length
- Space: \(O(TPB)\) shared memory per block
- Total parallel time: \(O(\log n)\) with sufficient threads
Puzzle 16: Matrix Multiplication (MatMul)
Overview
Matrix multiplication is a fundamental operation in scientific computing, machine learning, and graphics. Given two matrices \(A\) and \(B\), we want to compute their product \(C = A \times B.\)
For matrices \(A_{m\times k}\) and \(B_{k\times n}\), each element of the result \(C_{m\times n}\) is computed as:
\[\Large C_{ij} = \sum_{l=0}^{k-1} A_{il} \cdot B_{lj} \]
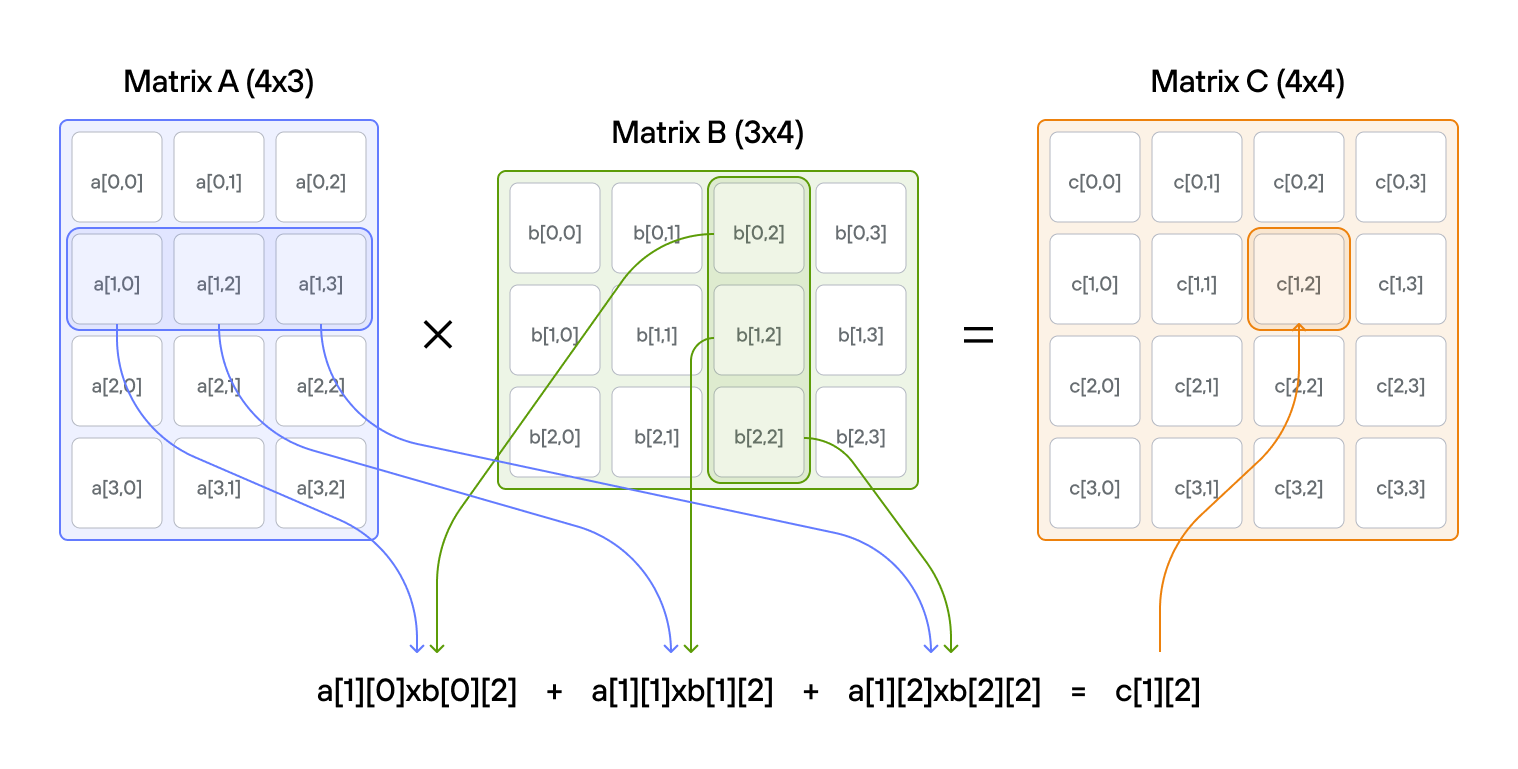
This puzzle explores different approaches to implementing matrix multiplication on GPUs, each with its own performance characteristics:
-
Naive Version The straightforward implementation where each thread computes one element of the output matrix. While simple to understand, this approach makes many redundant memory accesses.
-
Shared Memory Version Improves performance by loading blocks of input matrices into fast shared memory, reducing global memory accesses. Each thread still computes one output element but reads from shared memory.
-
Tiled Version Further optimizes by dividing the computation into tiles, allowing threads to cooperate on loading and computing blocks of the output matrix. This approach better utilizes memory hierarchy and thread cooperation.
Each version builds upon the previous one, introducing new optimization techniques common in GPU programming. You’ll learn how different memory access patterns and thread cooperation strategies affect performance.
The progression illustrates a common pattern in GPU optimization:
- Start with a correct but naive implementation
- Reduce global memory access with shared memory
- Improve data locality and thread cooperation with tiling
- Use high-level abstractions while maintaining performance
Choose a version to begin your matrix multiplication journey!
Naïve Matrix Multiplication
Overview
Implement a kernel that multiplies square matrices \(A\) and \(B\) and stores the result in \(\text{output}\). This is the most straightforward implementation where each thread computes one element of the output matrix.
Key concepts
This puzzle covers:
- 2D thread organization for matrix operations
- Global memory access patterns
- Matrix indexing in row-major layout
- Thread-to-output element mapping
The key insight is understanding how to map 2D thread indices to matrix elements and compute dot products in parallel.
Configuration
- Matrix size: \(\text{SIZE} \times \text{SIZE} = 2 \times 2\)
- Threads per block: \(\text{TPB} \times \text{TPB} = 3 \times 3\)
- Grid dimensions: \(1 \times 1\)
Layout configuration:
- Input A:
row_major[SIZE, SIZE]() - Input B:
row_major[SIZE, SIZE]() - Output:
row_major[SIZE, SIZE]()
Code to complete
from std.gpu import thread_idx, block_idx, block_dim, barrier
from std.gpu.memory import AddressSpace
from layout import TileTensor
from layout.tile_layout import row_major
from layout.tile_tensor import stack_allocation
comptime TPB = 3
comptime SIZE = 2
comptime BLOCKS_PER_GRID = (1, 1)
comptime THREADS_PER_BLOCK = (TPB, TPB)
comptime dtype = DType.float32
comptime layout = row_major[SIZE, SIZE]()
comptime LayoutType = type_of(layout)
def naive_matmul(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
var row = block_dim.y * block_idx.y + thread_idx.y
var col = block_dim.x * block_idx.x + thread_idx.x
# FILL ME IN (roughly 6 lines)
View full file: problems/p16/p16.mojo
Tips
- Calculate
rowandcolfrom thread indices - Check if indices are within
size - Accumulate products in a local variable
- Write final sum to correct output position
Running the code
To test your solution, run the following command in your terminal:
pixi run p16 --naive
pixi run -e amd p16 --naive
pixi run -e apple p16 --naive
uv run poe p16 --naive
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([4.0, 6.0, 12.0, 22.0])
Solution
def naive_matmul[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
var row = block_dim.y * block_idx.y + thread_idx.y
var col = block_dim.x * block_idx.x + thread_idx.x
if row < size and col < size:
var acc: output.ElementType = 0
comptime for k in range(size):
acc += a[row, k] * b[k, col]
output[row, col] = acc
The naive matrix multiplication using TileTensor follows this basic approach:
Matrix layout (2×2 example)
Matrix A: Matrix B: Output C:
[a[0,0] a[0,1]] [b[0,0] b[0,1]] [c[0,0] c[0,1]]
[a[1,0] a[1,1]] [b[1,0] b[1,1]] [c[1,0] c[1,1]]
Implementation details
-
Thread mapping:
row = block_dim.y * block_idx.y + thread_idx.y col = block_dim.x * block_idx.x + thread_idx.x -
Memory access pattern:
- Direct 2D indexing:
a[row, k] - Transposed access:
b[k, col] - Output writing:
output[row, col]
- Direct 2D indexing:
-
Computation flow:
# Use var for mutable accumulator with tensor's element type var acc: output.element_type = 0 # @parameter for compile-time loop unrolling @parameter for k in range(size): acc += a[row, k] * b[k, col]
Key language features
-
Variable declaration:
- The use of
varinvar acc: output.element_type = 0allows for type inference withoutput.element_typeensures type compatibility with the output tensor - Initialized to zero before accumulation
- The use of
-
Loop pptimization:
@parameterdecorator unrolls the loop at compile time- Improves performance for small, known matrix sizes
- Enables better instruction scheduling
Performance characteristics
-
Memory access:
- Each thread makes
2 x SIZEglobal memory reads - One global memory write per thread
- No data reuse between threads
- Each thread makes
-
Computational efficiency:
- Simple implementation but suboptimal performance
- Many redundant global memory accesses
- No use of fast shared memory
-
Limitations:
- High global memory bandwidth usage
- Poor data locality
- Limited scalability for large matrices
This naive implementation serves as a baseline for understanding matrix multiplication on GPUs, highlighting the need for optimization in memory access patterns.
Understanding GPU Performance: The Roofline Model
Having implemented the naive matrix multiplication, you might be wondering: How well is our kernel actually performing? Is it limited by the GPU’s computational power, or is something else holding it back?
The roofline model is your compass for GPU optimization—it reveals which hardware bottleneck limits your kernel’s performance and guides you toward the most impactful optimizations. Rather than guessing at improvements, the roofline model shows you exactly where to focus your efforts.
1. Two ceilings for every GPU kernel
Every GPU kernel operates under two fundamental constraints:
- Compute ceiling – how quickly the cores can execute floating-point operations (peak FLOPs/s)
- Memory ceiling – how quickly the memory system can feed those cores with data (peak bytes/s)
Understanding which ceiling constrains your kernel is crucial for optimization strategy. The roofline model visualizes this relationship by plotting two key metrics:
X-axis: Arithmetic Intensity – How much computation you extract per byte of data
\[\Large I = \frac{\text{Total FLOPs}}{\text{Total Bytes from Memory}} \quad [\text{FLOP/B}]\]
Y-axis: Sustained Performance – How fast your kernel actually runs
\[\Large P_{\text{sustained}} = \frac{\text{Total FLOPs}}{\text{Elapsed Time}} \quad [\text{GFLOP/s}]\]
Two “roofs” bound all achievable performance:
| Roof | Equation | Meaning |
|---|---|---|
| Memory roof | \(P = B_{\text{peak}} \cdot I\) | Sloped line; performance limited by memory bandwidth |
| Compute roof | \(P = P_{\text{peak}}\) | Horizontal line; performance limited by compute throughput |
The critical intensity
\[\Large I^* = \frac{P_{\text{peak}}}{B_{\text{peak}}}\]
marks where a kernel transitions from memory-bound (\(I < I^* \)) to compute-bound (\(I > I^* \)).
2. Hardware example: NVIDIA A100 specifications
Let’s ground this theory in concrete numbers using the NVIDIA A100:
Peak FP32 throughput \[\Large P_{\text{peak}} = 19.5 \text{ TFLOP/s} = 19{,}500 \text{ GFLOP/s}\]
Peak HBM2 bandwidth \[\Large B_{\text{peak}} = 1{,}555 \text{ GB/s}\]
Critical intensity \[\Large I^* = \frac{19{,}500}{1{,}555} \approx 12.5 \text{ FLOP/B}\]
Source: NVIDIA A100 Tensor Core GPU Architecture
This means kernels with arithmetic intensity below 12.5 FLOP/B are memory-bound, while those above are compute-bound.
3. Visualizing our matrix multiplication implementations
The animation below shows how our puzzle implementations map onto the A100’s roofline model:

The visualization demonstrates the optimization journey we’ll take in this puzzle:
- Hardware constraints – The red memory roof and blue compute roof define performance limits
- Our starting point – The naive implementation (orange dot) sitting firmly on the memory roof
- Optimization target – The shared memory version (teal dot) with improved arithmetic intensity
- Ultimate goal – The golden arrow pointing toward the critical intensity where kernels become compute-bound
4. Analyzing our naive implementation
Let’s examine why our naive kernel from the previous section performs as it does. For our \(2 \times 2\) matrix multiplication:
Computation per output element: \(\text{SIZE} + (\text{SIZE}-1) = 3 \text{ FLOPs }\)
Each element requires \(\text{SIZE}\) multiplications and \(\text{SIZE} - 1\) additions: \[C_{00} = A_{00} \cdot B_{00} + A_{01} \cdot B_{10}\] For \(\text{SIZE} = 2\) it is 2 multiplications + 1 addition = 3 FLOPs
Memory accesses per output element:
- Row from matrix A: \(2 \times 4 = 8\) bytes (FP32)
- Column from matrix B: \(2 \times 4 = 8\) bytes (FP32)
- Total: \(16\) bytes per output element
Arithmetic intensity: \[\Large I_{\text{naive}} = \frac{3 \text{ FLOPs}}{16 \text{ bytes}} = 0.1875 \text{ FLOP/B}\]
This arithmetic intensity is far below the compute roof of an A100, indicating that our naive kernel is severely memory-bound.
\[\Large I_{\text{naive}} = 0.1875 \ll I^* = 12.5\]
Expected performance: \[\Large P \approx B_{\text{peak}} \times I_{\text{naive}} = 1{,}555 \times 0.1875 \approx 292 \text{ GFLOP/s}\]
This represents only \(\frac{292}{19{,}500} \approx 1.5\%\) of the GPU’s computational potential! The visualization clearly shows this as the yellow dot sitting squarely on the memory roof—we’re nowhere near the compute ceiling.
5. The path forward: shared memory optimization
The roofline model reveals our optimization strategy: increase arithmetic intensity by reducing redundant memory accesses. This is exactly what the shared memory approach accomplishes:
Shared memory benefits:
- Cooperative loading: Threads work together to load matrix blocks into fast shared memory
- Data reuse: Each loaded element serves multiple computations
- Reduced global memory traffic: Fewer accesses to slow global memory
Expected arithmetic intensity improvement: \[\Large I_{\text{shared}} = \frac{12 \text{ FLOPs}}{32 \text{ bytes}} = 0.375 \text{ FLOP/B}\]
While still memory-bound for our small \(2 \times 2\) case, this 2× improvement in arithmetic intensity scales dramatically for larger matrices where shared memory tiles can be reused many more times.
6. Optimization strategies revealed by the roofline
The roofline model not only diagnoses current performance but also illuminates optimization paths. Here are the key techniques we’ll explore in later puzzles:
| Technique | Roofline effect | Implementation approach |
|---|---|---|
| Shared memory tiling | ↑ Arithmetic intensity through data reuse | Cooperative loading, block-wise computation |
| Register blocking | Reduce memory traffic with register accumulation | Loop unrolling with register variables |
| Kernel fusion | More FLOPs per byte by combining operations | Single kernel handling multiple computation stages |
| Memory coalescing | Maximize effective bandwidth utilization | Structured access patterns, proper thread organization |
| Asynchronous memory copies | Dedicated copy engine enables compute-memory overlap | copy_dram_to_sram_async with computation overlap |
| Mixed precision | Smaller data types reduce memory pressure | FP16/BF16 input with FP32 accumulation |
Each technique moves kernels along the roofline—either up the memory roof (better bandwidth utilization) or rightward toward the compute roof (higher arithmetic intensity).
Note on asynchronous operations: Standard GPU memory loads (ld.global) are
already asynchronous - warps continue executing until they need the loaded data.
Specialized async copy instructions like cp.async (CUDA) or
copy_dram_to_sram_async
(Mojo) provide additional benefits by using dedicated copy engines, bypassing
registers, and enabling better resource utilization rather than simply making
synchronous operations asynchronous.
7. Beyond simple rooflines
Multi-level memory: Advanced rooflines include separate ceilings for L2 cache, shared memory, and register bandwidth to identify which memory hierarchy level constrains performance.
Communication rooflines: For multi-GPU applications, replace memory bandwidth with interconnect bandwidth (NVLink, InfiniBand) to analyze scaling efficiency.
Specialized units: Modern GPUs include tensor cores with their own performance characteristics, requiring specialized roofline analysis.
8. Using the roofline in practice
- Profile your kernel: Use tools like Nsight Compute to measure actual FLOPs and memory traffic
- Plot the data point: Calculate arithmetic intensity and sustained performance
- Identify the bottleneck: Memory-bound kernels sit on the memory roof; compute-bound kernels approach the compute roof
- Choose optimizations: Focus on bandwidth improvements for memory-bound kernels, algorithmic changes for compute-bound ones
- Measure and iterate: Verify that optimizations move kernels in the expected direction
Connection to our shared memory puzzle
In the next section, we’ll implement the shared memory optimization that begins moving our kernel up the roofline. As the visualization shows, this takes us from the orange dot (naive) to the teal dot (shared memory)—a clear performance improvement through better data reuse.
While our \(2 \times 2\) example won’t reach the compute roof, you’ll see how the same principles scale to larger matrices where shared memory becomes crucial for performance. The roofline model provides the theoretical foundation for understanding why shared memory helps and how much improvement to expect.
Understanding the roofline model transforms GPU optimization from guesswork into systematic engineering. Every optimization technique in this book can be understood through its effect on this simple but powerful performance model.
Shared Memory Matrix Multiplication
Overview
This puzzle implements matrix multiplication for square matrices \(A\) and \(B\), storing results in \(\text{output}\) while leveraging shared memory to optimize memory access patterns. The implementation preloads matrix blocks into shared memory before performing computations.
Key concepts
This puzzle covers:
- Block-local memory management with TileTensor
- Thread synchronization patterns
- Memory access optimization using shared memory
- Collaborative data loading with 2D indexing
- Efficient use of TileTensor for matrix operations
The central concept involves utilizing fast shared memory through TileTensor to minimize costly global memory accesses.
Configuration
- Matrix size: \(\text{SIZE} \times \text{SIZE} = 2 \times 2\)
- Threads per block: \(\text{TPB} \times \text{TPB} = 3 \times 3\)
- Grid dimensions: \(1 \times 1\)
Layout configuration:
- Input A:
row_major[SIZE, SIZE]() - Input B:
row_major[SIZE, SIZE]() - Output:
row_major[SIZE, SIZE]() - Shared Memory: Two
TPB × TPBTileTensors
Memory organization:
Global Memory (TileTensor): Shared Memory (TileTensor):
A[i,j]: Direct access a_shared[local_row, local_col]
B[i,j]: Direct access b_shared[local_row, local_col]
Code to complete
def single_block_matmul(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
var row = block_dim.y * block_idx.y + thread_idx.y
var col = block_dim.x * block_idx.x + thread_idx.x
var local_row = thread_idx.y
var local_col = thread_idx.x
# FILL ME IN (roughly 12 lines)
View full file: problems/p16/p16.mojo
Tips
- Load matrices to shared memory using global and local indices
- Call
barrier()after loading - Compute dot product using shared memory indices
- Check array bounds for all operations
Running the code
To test your solution, run the following command in your terminal:
pixi run p16 --single-block
pixi run -e amd p16 --single-block
pixi run -e apple p16 --single-block
uv run poe p16 --single-block
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([4.0, 6.0, 12.0, 22.0])
Solution
def single_block_matmul[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
var row = block_dim.y * block_idx.y + thread_idx.y
var col = block_dim.x * block_idx.x + thread_idx.x
var local_row = thread_idx.y
var local_col = thread_idx.x
var a_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB, TPB]())
var b_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB, TPB]())
if row < size and col < size:
a_shared[local_row, local_col] = a[row, col]
b_shared[local_row, local_col] = b[row, col]
barrier()
if row < size and col < size:
var acc: output.ElementType = 0
comptime for k in range(size):
acc += a_shared[local_row, k] * b_shared[k, local_col]
output[row, col] = acc
The shared memory implementation with TileTensor improves performance through efficient memory access patterns:
Memory organization
Input Tensors (2×2): Shared Memory (3×3):
Matrix A: a_shared:
[a[0,0] a[0,1]] [s[0,0] s[0,1] s[0,2]]
[a[1,0] a[1,1]] [s[1,0] s[1,1] s[1,2]]
[s[2,0] s[2,1] s[2,2]]
Matrix B: b_shared: (similar layout)
[b[0,0] b[0,1]] [t[0,0] t[0,1] t[0,2]]
[b[1,0] b[1,1]] [t[1,0] t[1,1] t[1,2]]
[t[2,0] t[2,1] t[2,2]]
Implementation phases
-
Shared Memory Setup:
# Create 2D shared memory tensors using TileTensor with address_space a_shared = stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB, TPB]()) b_shared = stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB, TPB]()) -
Thread Indexing:
# Global indices for matrix access row = block_dim.y * block_idx.y + thread_idx.y col = block_dim.x * block_idx.x + thread_idx.x # Local indices for shared memory local_row = thread_idx.y local_col = thread_idx.x -
Data Loading:
# Load data into shared memory using TileTensor indexing if row < size and col < size: a_shared[local_row, local_col] = a[row, col] b_shared[local_row, local_col] = b[row, col] -
Computation with Shared Memory:
# Guard ensures we only compute for valid matrix elements if row < size and col < size: # Initialize accumulator with output tensor's type var acc: output.element_type = 0 # Compile-time unrolled loop for matrix multiplication @parameter for k in range(size): acc += a_shared[local_row, k] * b_shared[k, local_col] # Write result only for threads within matrix bounds output[row, col] = accKey aspects:
-
Boundary check:
if row < size and col < size- Prevents out-of-bounds computation
- Only valid threads perform work
- Essential because TPB (3×3) > SIZE (2×2)
-
Accumulator Type:
var acc: output.element_type- Uses output tensor’s element type for type safety
- Ensures consistent numeric precision
- Initialized to zero before accumulation
-
Loop Optimization:
@parameter for k in range(size)- Unrolls the loop at compile time
- Enables better instruction scheduling
- Efficient for small, known matrix sizes
-
Result Writing:
output[row, col] = acc- Protected by the same guard condition
- Only valid threads write results
- Maintains matrix bounds safety
-
Thread safety and synchronization
-
Guard conditions:
- Input Loading:
if row < size and col < size - Computation: Same guard ensures thread safety
- Output Writing: Protected by the same condition
- Prevents invalid memory access and race conditions
- Input Loading:
-
Memory access safety:
- Shared memory: Accessed only within TPB bounds
- Global memory: Protected by size checks
- Output: Guarded writes prevent corruption
Key language features
-
TileTensor benefits:
- Direct 2D indexing simplifies code
- Type safety through
element_type - Efficient memory layout handling
-
Shared memory allocation:
- TileTensor with address_space for structured allocation
- Row-major layout matching input tensors
- Proper alignment for efficient access
-
Synchronization:
barrier()ensures shared memory consistency- Proper synchronization between load and compute
- Thread cooperation within block
Performance optimizations
-
Memory Access Efficiency:
- Single global memory load per element
- Multiple reuse through shared memory
- Coalesced memory access patterns
-
Thread cooperation:
- Collaborative data loading
- Shared data reuse
- Efficient thread synchronization
-
Computational benefits:
- Reduced global memory traffic
- Better cache utilization
- Improved instruction throughput
This implementation significantly improves performance over the naive version by:
- Reducing global memory accesses
- Enabling data reuse through shared memory
- Using efficient 2D indexing with TileTensor
- Maintaining proper thread synchronization
Tiled Matrix Multiplication
Overview
Implement a kernel that multiplies square matrices \(A\) and \(B\) using tiled matrix multiplication with TileTensor. This approach handles large matrices by processing them in smaller chunks (tiles).
Key concepts
- Matrix tiling with TileTensor for efficient computation
- Multi-block coordination with proper layouts
- Efficient shared memory usage through TensorBuilder
- Boundary handling for tiles with TileTensor indexing
Configuration
- Matrix size: \(\text{SIZE_TILED} = 9\)
- Threads per block: \(\text{TPB} \times \text{TPB} = 3 \times 3\)
- Grid dimensions: \(3 \times 3\) blocks
- Shared memory: Two \(\text{TPB} \times \text{TPB}\) TileTensors per block
Layout configuration:
- Input A:
row_major[SIZE_TILED, SIZE_TILED]() - Input B:
row_major[SIZE_TILED, SIZE_TILED]() - Output:
row_major[SIZE_TILED, SIZE_TILED]() - Shared Memory: Two
TPB × TPBTileTensors using TensorBuilder
Tiling strategy
Block organization
Grid Layout (3×3): Thread Layout per Block (3×3):
[B00][B01][B02] [T00 T01 T02]
[B10][B11][B12] [T10 T11 T12]
[B20][B21][B22] [T20 T21 T22]
Each block processes a tile using TileTensor indexing
Tile processing steps
- Calculate global and local indices for thread position
- Allocate shared memory for A and B tiles
- For each tile:
- Load tile from matrix A and B
- Compute partial products
- Accumulate results in registers
- Write final accumulated result
Memory access pattern
Matrix A (8×8) Matrix B (8×8) Matrix C (8×8)
+---+---+---+ +---+---+---+ +---+---+---+
|T00|T01|T02| ... |T00|T01|T02| ... |T00|T01|T02| ...
+---+---+---+ +---+---+---+ +---+---+---+
|T10|T11|T12| |T10|T11|T12| |T10|T11|T12|
+---+---+---+ +---+---+---+ +---+---+---+
|T20|T21|T22| |T20|T21|T22| |T20|T21|T22|
+---+---+---+ +---+---+---+ +---+---+---+
... ... ...
Tile Processing (for computing C[T11]):
1. Load tiles from A and B:
+---+ +---+
|A11| × |B11| For each phase k:
+---+ +---+ C[T11] += A[row, k] × B[k, col]
2. Tile movement:
Phase 1 Phase 2 Phase 3
A: [T10] A: [T11] A: [T12]
B: [T01] B: [T11] B: [T21]
3. Each thread (i,j) in tile computes:
C[i,j] = Σ (A[i,k] × B[k,j]) for k in tile width
Synchronization required:
* After loading tiles to shared memory
* After computing each phase
Code to complete
comptime SIZE_TILED = 9
comptime BLOCKS_PER_GRID_TILED = (3, 3) # each block convers 3x3 elements
comptime THREADS_PER_BLOCK_TILED = (TPB, TPB)
comptime layout_tiled = row_major[SIZE_TILED, SIZE_TILED]()
comptime LayoutTiledType = type_of(layout_tiled)
def matmul_tiled(
output: TileTensor[mut=True, dtype, LayoutTiledType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutTiledType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutTiledType, ImmutAnyOrigin],
):
var local_row = thread_idx.y
var local_col = thread_idx.x
var tiled_row = block_idx.y * TPB + thread_idx.y
var tiled_col = block_idx.x * TPB + thread_idx.x
# FILL ME IN (roughly 20 lines)
View full file: problems/p16/p16.mojo
Tips
-
Use the standard indexing convention:
local_row = thread_idx.yandlocal_col = thread_idx.x -
Calculate global positions:
global_row = block_idx.y * TPB + local_rowand
global_col = block_idx.x * TPB + local_colUnderstanding the global indexing formula:
-
Each block processes a
TPB × TPBtile of the matrix -
block_idx.ytells us which row of blocks we’re in (0, 1, 2…) -
block_idx.y * TPBgives us the starting row of our block’s tile -
local_row(0 to TPB-1) is our thread’s offset within the block -
Adding them gives our thread’s actual row in the full matrix
Example with TPB=3:
Block Layout: Global Matrix (9×9): [B00][B01][B02] [0 1 2 | 3 4 5 | 6 7 8] [B10][B11][B12] → [9 A B | C D E | F G H] [B20][B21][B22] [I J K | L M N | O P Q] —————————————————————— [R S T | U V W | X Y Z] [a b c | d e f | g h i] [j k l | m n o | p q r] —————————————————————— [s t u | v w x | y z α] [β γ δ | ε ζ η | θ ι κ] [λ μ ν | ξ ο π | ρ σ τ] Thread(1,2) in Block(1,0): - block_idx.y = 1, local_row = 1 - global_row = 1 * 3 + 1 = 4 - This thread handles row 4 of the matrix ```text
-
-
Allocate shared memory (now pre-initialized with
.fill(0)) -
With 9×9 perfect tiling, no bounds checking needed!
-
Accumulate results across tiles with proper synchronization
Running the code
To test your solution, run the following command in your terminal:
pixi run p16 --tiled
pixi run -e amd p16 --tiled
pixi run -e apple p16 --tiled
uv run poe p16 --tiled
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([3672.0, 3744.0, 3816.0, 3888.0, 3960.0, 4032.0, 4104.0, 4176.0, 4248.0, 9504.0, 9738.0, 9972.0, 10206.0, 10440.0, 10674.0, 10908.0, 11142.0, 11376.0, 15336.0, 15732.0, 16128.0, 16524.0, 16920.0, 17316.0, 17712.0, 18108.0, 18504.0, 21168.0, 21726.0, 22284.0, 22842.0, 23400.0, 23958.0, 24516.0, 25074.0, 25632.0, 27000.0, 27720.0, 28440.0, 29160.0, 29880.0, 30600.0, 31320.0, 32040.0, 32760.0, 32832.0, 33714.0, 34596.0, 35478.0, 36360.0, 37242.0, 38124.0, 39006.0, 39888.0, 38664.0, 39708.0, 40752.0, 41796.0, 42840.0, 43884.0, 44928.0, 45972.0, 47016.0, 44496.0, 45702.0, 46908.0, 48114.0, 49320.0, 50526.0, 51732.0, 52938.0, 54144.0, 50328.0, 51696.0, 53064.0, 54432.0, 55800.0, 57168.0, 58536.0, 59904.0, 61272.0])
Solution: Manual tiling
def matmul_tiled[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutTiledType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutTiledType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutTiledType, ImmutAnyOrigin],
):
var local_row = thread_idx.y
var local_col = thread_idx.x
var tiled_row = block_idx.y * TPB + local_row
var tiled_col = block_idx.x * TPB + local_col
var a_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB, TPB]())
var b_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB, TPB]())
var acc: output.ElementType = 0
# Iterate over tiles to compute matrix product
comptime for tile in range((size + TPB - 1) // TPB):
# Load A tile - global row stays the same, col determined by tile
if tiled_row < size and (tile * TPB + local_col) < size:
a_shared[local_row, local_col] = a[
tiled_row, tile * TPB + local_col
]
# Load B tile - row determined by tile, global col stays the same
if (tile * TPB + local_row) < size and tiled_col < size:
b_shared[local_row, local_col] = b[
tile * TPB + local_row, tiled_col
]
barrier()
# Matrix multiplication within the tile
if tiled_row < size and tiled_col < size:
comptime for k in range(min(Int(TPB), Int(size - tile * TPB))):
acc += a_shared[local_row, k] * b_shared[k, local_col]
barrier()
# Write out final result
if tiled_row < size and tiled_col < size:
output[tiled_row, tiled_col] = acc
The tiled matrix multiplication implementation demonstrates efficient handling of matrices \((9 \times 9)\) using small tiles \((3 \times 3)\). Here’s how it works:
-
Shared memory allocation
Input matrices (9×9) - Perfect fit for (3×3) tiling: A = [0 1 2 3 4 5 6 7 8 ] B = [0 2 4 6 8 10 12 14 16] [9 10 11 12 13 14 15 16 17] [18 20 22 24 26 28 30 32 34] [18 19 20 21 22 23 24 25 26] [36 38 40 42 44 46 48 50 52] [27 28 29 30 31 32 33 34 35] [54 56 58 60 62 64 66 68 70] [36 37 38 39 40 41 42 43 44] [72 74 76 78 80 82 84 86 88] [45 46 47 48 49 50 51 52 53] [90 92 94 96 98 100 102 104 106] [54 55 56 57 58 59 60 61 62] [108 110 112 114 116 118 120 122 124] [63 64 65 66 67 68 69 70 71] [126 128 130 132 134 136 138 140 142] [72 73 74 75 76 77 78 79 80] [144 146 148 150 152 154 156 158 160] Shared memory per block (3×3): a_shared[TPB, TPB] b_shared[TPB, TPB] -
Tile processing loop
Number of tiles = 9 // 3 = 3 tiles (perfect division!) For each tile: 1. Load tile from A and B 2. Compute partial products 3. Accumulate in register -
Memory loading pattern
-
With perfect \((9 \times 9)\) tiling, bounds check is technically unnecessary but included for defensive programming and consistency with other matrix sizes.
# Load A tile - global row stays the same, col determined by tile if tiled_row < size and (tile * TPB + local_col) < size: a_shared[local_row, local_col] = a[ tiled_row, tile * TPB + local_col ] # Load B tile - row determined by tile, global col stays the same if (tile * TPB + local_row) < size and tiled_col < size: b_shared[local_row, local_col] = b[ tile * TPB + local_row, tiled_col ]
-
-
Computation within tile
for k in range(min(TPB, size - tile * TPB)): acc += a_shared[local_row, k] * b_shared[k, local_col]-
Avoids shared memory bank conflicts:
Bank Conflict Free (Good): Bank Conflicts (Bad): Thread0: a_shared[0,k] b_shared[k,0] Thread0: a_shared[k,0] b_shared[0,k] Thread1: a_shared[0,k] b_shared[k,1] Thread1: a_shared[k,0] b_shared[1,k] Thread2: a_shared[0,k] b_shared[k,2] Thread2: a_shared[k,0] b_shared[2,k] ↓ ↓ Parallel access to different banks Serialized access to same bank of b_shared (or broadcast for a_shared) if shared memory was column-majorShared memory bank conflicts explained:
- Left (Good):
b_shared[k,threadIdx.x]accesses different banks,a_shared[0,k]broadcasts to all threads - Right (Bad): If b_shared were column-major, threads would access same bank simultaneously
- Key insight: This is about shared memory access patterns, not global memory coalescing
- Bank structure: Shared memory has 32 banks; conflicts occur when multiple threads access different addresses in the same bank simultaneously
- Left (Good):
-
-
Synchronization points
barrier() after: 1. Tile loading 2. Tile computation
Key performance features:
- Processes \((9 \times 9)\) matrix using \((3 \times 3)\) tiles (perfect fit!)
- Uses shared memory for fast tile access
- Minimizes global memory transactions with coalesced memory access
- Optimized shared memory layout and access pattern to avoid shared memory bank conflicts
-
Result writing:
if tiled_row < size and tiled_col < size: output[tiled_row, tiled_col] = acc- Defensive bounds checking included for other matrix sizes and tiling strategies
- Direct assignment to output matrix
- All threads write valid results
Key optimizations
-
Layout optimization:
- Row-major layout for all tensors
- Efficient 2D indexing
-
Memory access:
- Coalesced global memory loads
- Efficient shared memory usage
-
Computation:
- Register-based accumulation i.e.
var acc: output.element_type = 0 - Compile-time loop unrolling via
@parameter
- Register-based accumulation i.e.
This implementation achieves high performance through:
- Efficient use of TileTensor for memory access
- Optimal tiling strategy
- Proper thread synchronization
- Careful boundary handling
Solution: Idiomatic TileTensor tiling
from std.gpu.memory import async_copy_wait_all
from layout.layout_tensor import copy_dram_to_sram_async
from layout import Layout as IntTupleLayout
comptime NUM_THREADS = TPB * TPB
comptime BLOCK_DIM_COUNT = 2
def matmul_idiomatic_tiled[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutTiledType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutTiledType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutTiledType, ImmutAnyOrigin],
):
var local_row = thread_idx.y
var local_col = thread_idx.x
var tiled_row = block_idx.y * TPB + local_row
var tiled_col = block_idx.x * TPB + local_col
# Get the tile of the output matrix that this thread block is responsible for
var out_tile = output.tile[TPB, TPB](block_idx.y, block_idx.x)
var a_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB, TPB]())
var b_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB, TPB]())
var acc: output.ElementType = 0
comptime load_a_layout = IntTupleLayout.row_major(
1, TPB
) # Coalesced loading
comptime load_b_layout = IntTupleLayout.row_major(
1, TPB
) # Coalesced loading
# Note: Both matrices stored in same orientation for correct matrix multiplication
# Transposed loading would be useful if B were pre-transposed in global memory
comptime for idx in range(
size // TPB
): # Perfect division: 9 // 3 = 3 tiles
# Get tiles from A and B matrices
var a_tile = a.tile[TPB, TPB](block_idx.y, Int(idx))
var b_tile = b.tile[TPB, TPB](Int(idx), block_idx.x)
# Asynchronously copy tiles to shared memory with consistent orientation
copy_dram_to_sram_async[
thread_layout=load_a_layout,
num_threads=NUM_THREADS,
block_dim_count=BLOCK_DIM_COUNT,
](a_shared.to_layout_tensor(), a_tile.to_layout_tensor())
copy_dram_to_sram_async[
thread_layout=load_b_layout,
num_threads=NUM_THREADS,
block_dim_count=BLOCK_DIM_COUNT,
](b_shared.to_layout_tensor(), b_tile.to_layout_tensor())
# Wait for all async copies to complete
async_copy_wait_all()
barrier()
# Compute partial matrix multiplication for this tile
comptime for k in range(TPB):
acc += a_shared[local_row, k] * b_shared[k, local_col]
barrier()
# Write final result to output tile
if tiled_row < size and tiled_col < size:
out_tile[local_row, local_col] = acc
The idiomatic tiled matrix multiplication leverages Mojo’s TileTensor API and asynchronous memory operations for a beautifully clean implementation.
🔑 Key Point: This implementation performs standard matrix multiplication A × B using coalesced loading for both matrices.
What this implementation does:
- Matrix operation: Standard \(A \times B\) multiplication (not \(A \times B^T\))
- Loading pattern: Both matrices use
row_major[1, TPB]()for coalesced access - Computation:
acc += a_shared[local_row, k] * b_shared[k, local_col] - Data layout: No transposition during loading - both matrices loaded in same orientation
What this implementation does NOT do:
- Does NOT perform \(A \times B^T\) multiplication
- Does NOT use transposed loading patterns
- Does NOT transpose data during copy operations
With the \((9 \times 9)\) matrix size, we get perfect tiling that eliminates all boundary checks:
-
TileTensor tile API
out_tile = output.tile[TPB, TPB](block_idx.y, block_idx.x) a_tile = a.tile[TPB, TPB](block_idx.y, idx) b_tile = b.tile[TPB, TPB](idx, block_idx.x)This directly expresses “get the tile at position (block_idx.y, block_idx.x)” without manual coordinate calculation. See the documentation for more details.
-
Asynchronous memory operations
copy_dram_to_sram_async[ thread_layout = load_a_layout, num_threads = NUM_THREADS, block_dim_count = BLOCK_DIM_COUNT ](a_shared,a_tile) copy_dram_to_sram_async[ thread_layout = load_b_layout, num_threads = NUM_THREADS, block_dim_count = BLOCK_DIM_COUNT ](b_shared, b_tile) async_copy_wait_all()These operations:
- Use dedicated copy engines that bypass registers and enable compute-memory overlap via copy_dram_to_sram_async
- Use specialized thread layouts for optimal memory access patterns
- Eliminate the need for manual memory initialization
- Important:
- Standard GPU loads are already asynchronous; these provide better resource utilization and register bypass
copy_dram_to_sram_asyncassumes that you are using a 1d thread block (block_dim.y == block_dim.z == 1) and all the threads from a thread block participate in the copy unless you specify otherwise. This behaviour in overridden by specifying:block_dim_count: the dimensionality of the thread block (2for the 2d thread blockTHREADS_PER_BLOCK_TILED = (TPB, TPB))num_threads: the number of threads in the thread block (TPB*TPB == 9)
-
Optimized memory access layouts
comptime load_a_layout = row_major[1, TPB]() # Coalesced loading comptime load_b_layout = row_major[1, TPB]() # Coalesced loading # Note: Both matrices use the same layout for standard A × B multiplicationMemory Access Analysis for Current Implementation:
Both matrices use
row_major[1, TPB]()for coalesced loading from global memory:load_a_layout: Threads cooperate to load consecutive elements from matrix A rowsload_b_layout: Threads cooperate to load consecutive elements from matrix B rows- Key insight: Thread layout determines how threads cooperate during copy, not the final data layout
Actual Computation Pattern (proves this is A × B):
# This is the actual computation in the current implementation acc += a_shared[local_row, k] * b_shared[k, local_col] # This corresponds to: C[i,j] = Σ(A[i,k] * B[k,j]) # Which is standard matrix multiplication A × BWhy both matrices use the same coalesced loading pattern:
Loading tiles from global memory: - Matrix A tile: threads load A[block_row, k], A[block_row, k+1], A[block_row, k+2]... (consecutive) - Matrix B tile: threads load B[k, block_col], B[k, block_col+1], B[k, block_col+2]... (consecutive) Both patterns are coalesced with row_major[1, TPB]()Three separate memory concerns:
- Global-to-shared coalescing:
row_major[1, TPB]()ensures coalesced global memory access - Shared memory computation:
a_shared[local_row, k] * b_shared[k, local_col]avoids bank conflicts - Matrix operation: The computation pattern determines this is A × B, not A × B^T
-
Perfect tiling eliminates boundary checks
@parameter for idx in range(size // TPB): # Perfect division: 9 // 3 = 3With \((9 \times 9)\) matrices and \((3 \times 3)\) tiles, every tile is exactly full-sized. No boundary checking needed!
-
Clean tile processing with defensive bounds checking
# Defensive bounds checking included even with perfect tiling if tiled_row < size and tiled_col < size: out_tile[local_row, local_col] = accWith perfect \((9 \times 9)\) tiling, this bounds check is technically unnecessary but included for defensive programming and consistency with other matrix sizes.
Performance considerations
The idiomatic implementation maintains the performance benefits of tiling while providing cleaner abstractions:
- Memory locality: Exploits spatial and temporal locality through tiling
- Coalesced access: Specialized load layouts ensure coalesced memory access patterns
- Compute-memory overlap: Potential overlap through asynchronous memory operations
- Shared memory efficiency: No redundant initialization of shared memory
- Register pressure: Uses accumulation registers for optimal compute throughput
This implementation shows how high-level abstractions can express complex GPU algorithms without sacrificing performance. It’s a prime example of Mojo’s philosophy: combining high-level expressiveness with low-level performance control.
Key differences from manual tiling
| Feature | Manual Tiling | Idiomatic Tiling |
|---|---|---|
| Memory access | Direct indexing with bounds checks | TileTensor tile API |
| Tile loading | Explicit element-by-element copying | Dedicated copy engine bulk transfers |
| Shared memory | Manual initialization (defensive) | Managed by copy functions |
| Code complexity | More verbose with explicit indexing | More concise with higher-level APIs |
| Bounds checking | Multiple checks during loading and computing | Single defensive check at final write |
| Matrix orientation | Both A and B in same orientation (standard A × B) | Both A and B in same orientation (standard A × B) |
| Performance | Explicit control over memory patterns | Optimized layouts with register bypass |
The idiomatic approach is not just cleaner but also potentially more performant due to the use of specialized memory layouts and asynchronous operations.
Educational: When would transposed loading be useful?
The current implementation does NOT use transposed loading. This section is purely educational to show what’s possible with the layout system.
Current implementation recap:
- Uses
row_major[1, TPB]()for both matrices - Performs standard A × B multiplication
- No data transposition during copy
Educational scenarios where you WOULD use transposed loading:
While this puzzle uses standard coalesced loading for both matrices, the layout system’s flexibility enables powerful optimizations in other scenarios:
# Example: Loading pre-transposed matrix B^T to compute A × B
# (This is NOT what the current implementation does)
comptime load_b_layout = row_major[TPB, 1]() # Load B^T with coalesced access
comptime store_b_layout = row_major[1, TPB]() # Store as B in shared memory
copy_dram_to_sram_async[src_thread_layout=load_b_layout, dst_thread_layout=store_b_layout](b_shared, b_tile)
Use cases for transposed loading (not used in this puzzle):
- Pre-transposed input matrices: When \(B\) is already stored transposed in global memory
- Different algorithms: Computing \(A^T \times B\), \(A \times B^T\), or \(A^T \times B^T\)
- Memory layout conversion: Converting between row-major and column-major layouts
- Avoiding transpose operations: Loading data directly in the required orientation
Key distinction:
- Current implementation: Both matrices use
row_major[1, TPB]()for standard \(A \times B\) multiplication - Transposed loading example: Would use different layouts to handle pre-transposed data or different matrix operations
This demonstrates Mojo’s philosophy: providing low-level control when needed while maintaining high-level abstractions for common cases.
Summary: Key takeaways
What the idiomatic tiled implementation actually does:
- Matrix Operation: Standard A × B multiplication
- Memory Loading: Both matrices use
row_major[1, TPB]()for coalesced access - Computation Pattern:
acc += a_shared[local_row, k] * b_shared[k, local_col] - Data Layout: No transposition during loading
Why this is optimal:
- Coalesced global memory access:
row_major[1, TPB]()ensures efficient loading - Bank conflict avoidance: Shared memory access pattern avoids conflicts
- Standard algorithm: Implements the most common matrix multiplication pattern
Puzzle 17: 1D Convolution Op
Bridging to Python with MAX Graph
We’re now entering Part IV of our GPU puzzle journey: Interfacing with Python via MAX Graph Custom Ops.
In previous puzzles, we’ve learned how to write efficient GPU kernels in Mojo. Now we’ll explore how to:
- Package these kernels as custom operations that can be called from Python
- Integrate with the MAX Graph system for accelerated machine learning
- Bridge the gap between high-level Python APIs and low-level GPU code
This integration allows us to leverage the performance of Mojo GPU kernels while working in familiar Python environments.
Overview
In Puzzle 13, we implemented a 1D convolution kernel that runs efficiently on the GPU. Now we’ll take this kernel and transform it into a custom operation that can be called directly from Python using MAX Graph.
The 1D convolution kernel we’ll be working with is already implemented:
comptime TPB = 15
comptime BLOCKS_PER_GRID = (2, 1)
def conv1d_kernel[
input_size: Int,
conv_size: Int,
OutLayout: TensorLayout,
InLayout: TensorLayout,
ConvLayout: TensorLayout,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
input: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
kernel: TileTensor[mut=False, dtype, ConvLayout, ImmutAnyOrigin],
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# first: need to account for padding
var shared_a = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB + conv_size - 1]())
var shared_b = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[conv_size]())
if global_i < input_size:
shared_a[local_i] = input[global_i]
# second: load elements needed for convolution at block boundary
if local_i < conv_size - 1:
# indices from next block
var next_idx = global_i + TPB
if next_idx < input_size:
shared_a[TPB + local_i] = input[next_idx]
else:
shared_a[TPB + local_i] = 0
if local_i < conv_size:
shared_b[local_i] = kernel[local_i]
barrier()
if global_i < input_size:
var local_sum: output.ElementType = 0
comptime for j in range(conv_size):
if local_i + j < TPB + conv_size - 1:
local_sum += shared_a[local_i + j] * shared_b[j]
output[global_i] = local_sum
The key aspects of this puzzle include:
- Custom op registration: Understanding how to expose Mojo functions to
Python via the
@compiler.registerdecorator - Packaging custom ops: Learning how to package Mojo code for use with MAX Graph
- Python integration: Calling custom operations from Python through MAX Graph
- Cross-language data flow: Managing data types and memory between Python and GPU
This custom operation will:
- Accept NumPy arrays as input from Python
- Transfer this data to the GPU
- Execute our optimized convolution kernel
- Return the results back to Python
When you complete this puzzle, you’ll have created a seamless bridge between Python’s rich ecosystem and Mojo’s powerful GPU performance.
Code to complete
To complete this puzzle, you only need to fill one line in conv1d.mojo to call
the conv1d_kernel:
import compiler
from std.runtime.asyncrt import DeviceContextPtr
from tensor import InputTensor, OutputTensor
from std.memory import UnsafePointer
from std.gpu.host import DeviceBuffer
@compiler.register("conv1d")
struct Conv1DCustomOp:
@staticmethod
def execute[
# The kind of device this will be run on: "cpu" or "gpu"
target: StaticString,
input_size: Int,
conv_size: Int,
dtype: DType = DType.float32,
](
output: OutputTensor[rank=1, static_spec=_],
input: InputTensor[rank=output.rank, static_spec=_],
kernel: InputTensor[rank=output.rank, static_spec=_],
# the context is needed for some GPU calls
ctx: DeviceContextPtr,
) raises:
var output_tensor = output.to_layout_tensor()
var input_tensor = input.to_layout_tensor()
var kernel_tensor = kernel.to_layout_tensor()
comptime if target == "gpu":
var gpu_ctx = ctx.get_device_context()
# making sure the output tensor is zeroed out before the kernel is called
gpu_ctx.enqueue_memset(
DeviceBuffer[output_tensor.dtype](
gpu_ctx,
output_tensor.ptr,
input_size,
owning=False,
),
0,
)
# FILL ME IN with 1 line calling our conv1d_kernel
elif target == "cpu":
# we can fallback to CPU
pass
else:
raise Error("Unsupported target: " + target)
View full file: problems/p17/op/conv1d.mojo
You can run the puzzle with:
pixi run p17
pixi run -e amd p17
pixi run -e apple p17
uv run poe p17
When successful, you should see output similar to:
Input array: [ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14.]
Convolution kernel: [0. 1. 2. 3.]
Expected result (NumPy calculation): [14. 20. 26. 32. 38. 44. 50. 56. 62. 68. 74. 80. 41. 14. 0.]
Compiling 1D convolution graph...
Executing 1D convolution...
1D Convolution result (custom Mojo kernel): [14. 20. 26. 32. 38. 44. 50. 56. 62. 68. 74. 80. 41. 14. 0.]
Verification passed: Custom kernel results match NumPy calculation
This indicates that your custom MAX Graph operation correctly implements the 1D convolution algorithm.
Solution
To solve this puzzle, we need to integrate our 1D convolution kernel with the
MAX Graph system. The key is to properly call our kernel from the execute
method in the Conv1DCustomOp struct.
The solution is:
comptime kernel = conv1d_kernel[
input_size, conv_size, OutLayout, OutLayout, ConvLayout
]
gpu_ctx.enqueue_function[kernel, kernel](
output_tensor,
input_tensor,
kernel_tensor,
grid_dim=BLOCKS_PER_GRID,
block_dim=(TPB, 1),
)
- Calls
enqueue_function
on the GPU context (
gpu_ctxis of type DeviceContext) to schedule our kernel execution - Passes the necessary layout and size information as compile-time parameters
- Provides the output, input, and kernel tensors as runtime arguments
- Configures the execution grid with the appropriate dimensions
Let’s break down how this works in the larger context:
Python-Mojo integration flow
-
Python side (problems/p17/p17.py):
- Creates NumPy arrays for input and kernel
- Calls
conv_1d()function which wraps our operation in MAX Graph - Converts NumPy arrays to
MAX driver Buffers with
Buffer.from_numpy(input).to(device) - Loads the custom operation package with
custom_extensions=[mojo_kernels]
-
Graph building:
- Defines input and output tensor types with TensorType
- Specifies parameters for our operation via
parameters={...} - Creates a computation graph with
Graph("conv_1d_graph", ...) - Calls our operation using
ops.custom(name="conv1d", ...)
-
Custom op registration:
- The
@compiler.register("conv1d")decorator exposes our operation to MAX Graph. See @compiler.register - The
executemethod parameters define the interface (inputs, outputs, context) - Input/output tensors are converted to TileTensors for use in our kernel
- Device context manages GPU memory allocation and kernel execution
- The
-
Kernel execution:
- When
model.execute(...)is called, ourconv1d_kernelreceives the data - GPU thread configuration is set with
grid_dimandblock_dim - Results are transferred back to CPU with
result.to(CPU()) - NumPy verification compares our results with the expected output
- When
Key components in detail
-
Custom Op Structure:
@compiler.register("conv1d") struct Conv1DCustomOp: @staticmethod def execute[target: StaticString, input_size: Int, conv_size: Int, dtype: DType = DType.float32]( output: OutputTensor[rank=1], input: InputTensor[dtype = output.dtype, rank = output.rank], kernel: InputTensor[dtype = output.dtype, rank = output.rank], ctx: DeviceContextPtr, ) raises: # Implementationtargetindicates the device type (“gpu” or “cpu”)input_sizeandconv_sizeare parameters passed from Python- Tensor types ensure correct shape and type checking
- Return type is
raisesfor proper error handling
-
Tensor Conversion:
output_tensor = output.to_layout_tensor() input_tensor = input.to_layout_tensor() kernel_tensor = kernel.to_layout_tensor()- MAX Graph tensors are converted to Mojo TileTensors
- This allows our kernel to work with them directly
- The layouts are extracted for compile-time optimization
-
Device Context Usage:
gpu_ctx = ctx.get_device_context() gpu_ctx.enqueue_memset(...) # Zero output buffer gpu_ctx.enqueue_function[..., ...](...) # Schedule kernel- Device context manages GPU resources
- Memory operations ensure correct buffer state
- Function enqueueing schedules our kernel for execution
This solution demonstrates the complete flow from Python data through MAX Graph to GPU execution and back, leveraging Mojo’s powerful type system and parametric functions to create efficient, type-safe, accelerated operations.
Understanding MAX Graph custom ops
Check out the follow tutorials for more details:
Custom op registration
The core of creating a custom operation is the @compiler.register decorator
and the associated structure:
@compiler.register("conv1d")
struct Conv1DCustomOp:
@staticmethod
def execute[...](
output: OutputTensor[rank=1],
input: InputTensor[dtype = output.dtype, rank = output.rank],
kernel: InputTensor[type = output.dtype, rank = output.rank],
ctx: DeviceContextPtr,
) raises:
# Implementation here
Key components of the registration:
- The name passed to the decorator (
"conv1d") is what Python code will use to call this operation - The struct must have an
executemethod with the correct signature - OutputTensor and InputTensor types define the interface for Python data
- DeviceContextPtr provides access to the execution environment
Packaging custom ops
Before the custom operation can be used from Python, it needs to be packaged:
mojo package op -o op.mojopkg
This command:
- Compiles the Mojo code into a deployable package
- Creates the necessary metadata for MAX Graph to understand the operation
- Produces a binary artifact (
op.mojopkg) that can be loaded by Python
The package must be placed in a location where MAX Graph can find it, typically in a directory accessible to the Python code.
Python integration
On the Python side, here’s how the custom operation is used:
# Path to the directory containing our Mojo operations
mojo_kernels = Path(__file__).parent / "op"
# Configure our graph with the custom conv1d operation
with Graph(
"conv_1d_graph",
input_types=[...],
custom_extensions=[mojo_kernels], # Load our custom op package
) as graph:
# Define inputs to the graph
input_value, kernel_value = graph.inputs
# Use our custom operation by name
output = ops.custom(
name="conv1d", # Must match the name in @compiler.register
values=[input_value, kernel_value],
out_types=[...],
parameters={
"input_size": input_tensor.shape[0],
"conv_size": kernel_tensor.shape[0],
"dtype": dtype,
},
)[0].tensor
The key elements are:
- Specifying the path to our custom operations with
custom_extensions - Calling
ops.customwith the registered operation name - Passing input values and parameters that match our operation’s signature
Puzzle 18: Softmax Op
Overview
In this puzzle, we’ll implement the softmax function as a custom MAX Graph operation. Softmax takes a vector of real numbers and normalizes it into a probability distribution.
The softmax function works by performing two main steps:
-
Exponentiation: It applies the exponential function to each element of the input vector. This ensures all values are positive and amplifies the differences between them. Larger input values result in significantly larger exponential outputs, while smaller or negative values result in outputs closer to zero.
-
Normalization: It then divides each exponentiated value by the sum of all the exponentiated values. This normalization step ensures that the resulting values are a valid probability distribution, meaning they are all between 0 and 1 and their sum is exactly 1.
Mathematically, the softmax function is defined as:
$$\Large \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_{j=1}^{n} e^{x_j}}$$
Where:
- \(x_i\) is the \(i\)-th element of the input vector
- \(n\) is the length of the input vector
However, this direct implementation can lead to numerical overflow issues when values are large. To address this, we use a more numerically stable version:
$$\Large \text{softmax}(x_i) = \frac{e^{x_i - \max(x)}}{\sum_{j=1}^{n} e^{x_j - \max(x)}}$$
Our GPU implementation uses parallel reduction for both finding the maximum value and computing the sum of exponentials, making it highly efficient for large vectors.
Key concepts
- Parallel reduction for efficient maximum and sum calculations
- Numerical stability through max-subtraction technique
- Shared memory usage for thread communication
- Custom MAX Graph operation integration with Python
- Thread synchronization with barriers
Configuration
- Vector size:
SIZE = 128 - Threads per block:
BLOCK_DIM_X = 1 << log2_ceil(SIZE). Tree-based reduction requiresBLOCK_DIM_Xto be the next power of two>= SIZEfor correctness. - Grid dimensions: \(1 \times 1\) block
- Shared memory: Two shared variables for max and sum
Layout configuration:
- Input tensor:
row_major[SIZE]() - Output tensor:
row_major[SIZE]() - Custom op parameters:
{"input_size": input_tensor.shape[0]}
Key aspects of this puzzle include:
- Numerical stability: Understanding how to handle potential numerical issues
- Parallel reductions: Using shared memory for efficient max and sum calculations
- Custom op integration: Completing the Python interface for our Mojo GPU kernel
- Testing and verification: Ensuring our implementation matches the expected results
Our softmax custom operation will:
- Accept NumPy arrays from Python
- Process them efficiently on the GPU
- Return normalized probability distributions
- Match the results of SciPy’s softmax implementation
Code to complete
To complete this puzzle, you need to implement both the GPU and CPU kernels in the Mojo file and complete the graph definition in the Python code.
1. Implement the GPU kernel in softmax.mojo
from std.gpu import thread_idx, block_idx, block_dim, barrier
from std.gpu.host import DeviceContext, HostBuffer, DeviceBuffer
from std.gpu.memory import AddressSpace
from layout import TileTensor
from layout.tile_layout import row_major
from layout.tile_tensor import stack_allocation
from std.math import exp
from std.bit import log2_ceil
from std.utils.numerics import max_finite, min_finite
comptime SIZE = 128 # This must be equal to INPUT_SIZE in p18.py
comptime layout = row_major[SIZE]()
comptime LayoutType = type_of(layout)
comptime GRID_DIM_X = 1
# Tree-based reduction require the number of threads to be the next power of two >= SIZE for correctness.
comptime BLOCK_DIM_X = 1 << log2_ceil(SIZE)
def softmax_gpu_kernel[
input_size: Int,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
comptime assert (
dtype.is_floating_point()
), "dtype must be a floating-point type"
# FILL IN (roughly 31 lines)
...
View full file: problems/p18/op/softmax.mojo
Tips
- Use shared memory for both the maximum value and sum to ensure all threads can access these values
- Remember to call
barrier()at appropriate points to synchronize threads - Implement parallel reduction by having each thread process a portion of the input array
- Use a tree-based reduction pattern to minimize thread divergence
- Handle out-of-bounds access carefully, especially for large inputs
- For numerical stability, calculate \(e^{x_i - max}\) instead of \(e^{x_i}\)
2. Implement the CPU kernel in softmax.mojo
def softmax_cpu_kernel[
input_size: Int,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
comptime assert (
dtype.is_floating_point()
), "dtype must be a floating-point type"
# FILL IN (roughly 10 lines)
...
View full file: problems/p18/op/softmax.mojo
Tips
- Create a sequential implementation that follows the same mathematical steps as the GPU version
- First find the maximum value across all inputs
- Then compute \(e^{x_i - max}\) for each element and accumulate the sum
- Finally, normalize by dividing each element by the sum
- Use scalar operations since we don’t have parallel threads in the CPU implementation
Test the CPU and GPU kernels
uv run poe p18-test-kernels
pixi run p18-test-kernels
when done correctly you’ll see
Total Discovered Tests: 1
Passed : 1 (100.00%)
Failed : 0 (0.00%)
Skipped: 0 (0.00%)
3. Complete the graph definition in p18.py
from pathlib import Path
import numpy as np
from max.driver import CPU, Accelerator, Buffer, Device
from max.dtype import DType
from max.engine import InferenceSession
from max.graph import DeviceRef, Graph, TensorType
from numpy.typing import NDArray
from scipy.special import softmax as scipy_softmax
def softmax(
input: NDArray[np.float32],
session: InferenceSession,
device: Device,
) -> Buffer:
dtype = DType.float32
input_tensor = Buffer.from_numpy(input).to(device)
mojo_kernels = Path(__file__).parent / "op"
with Graph(
"softmax_graph",
input_types=[
TensorType(
dtype,
shape=input_tensor.shape,
device=DeviceRef.from_device(device),
),
],
custom_extensions=[mojo_kernels],
) as graph:
# FILL IN (roughly 4 unformatted lines)
pass
View full file: problems/p18/p18.py
Tips
- Use
graph.inputs[0]to access the input tensor passed to the graph - Call
ops.custom()with the name matching your registered custom op (“softmax”) - Pass the input tensor as a value to the custom operation
- Specify the output type to match the input shape
- Include the “input_size” parameter which is required by the kernel
- Set
graph.outputsto a list containing your operation’s output tensor
You can run the puzzle with:
pixi run p18
pixi run -e amd p18
pixi run -e apple p18
uv run poe p18
When successful, you should see output similar to on CPU and GPU:
Input shape: (128,)
First few random input values: [ 1.1810775 0.60472375 0.5718309 0.6644599 -0.08899796]
Compiling softmax graph on Device(type=cpu,id=0)
Executing softmax on Device(type=cpu,id=0)
====================================================================================================
Compiling softmax graph on Device(type=gpu,id=0)
Executing softmax on Device(type=gpu,id=0)
====================================================================================================
First few softmax results on CPU (custom Mojo kernel): [0.01718348 0.00965615 0.0093437 0.01025055 0.0048253 ]
First few softmax results on GPU (custom Mojo kernel): [0.01718348 0.00965615 0.0093437 0.01025055 0.0048253 ]
First few expected results (SciPy calculation): [0.01718348 0.00965615 0.0093437 0.01025055 0.0048253 ]
Verification passed: Custom kernel results match SciPy calculation
Sum of all probabilities on CPU: 1.0
Sum of all probabilities on GPU: 1.0
This indicates that your custom MAX Graph operation correctly implements the softmax algorithm and produces a valid probability distribution.
Solution
To solve this puzzle, we need to implement both the Mojo kernels (GPU and CPU) and the Python graph definition for our softmax custom operation. Similar to what we did in Puzzle 17, we’re creating a bridge between Python’s ecosystem and Mojo’s GPU-accelerated computing capabilities.
The softmax operation we’re implementing is mathematically defined as:
$$\Large \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_{j=1}^{n} e^{x_j}}$$
However, to prevent numerical overflow, we use the more stable form:
$$\Large \text{softmax}(x_i) = \frac{e^{x_i - \max(x)}}{\sum_{j=1}^{n} e^{x_j - \max(x)}}$$
GPU kernel implementation
def softmax_gpu_kernel[
input_size: Int,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
):
comptime assert (
dtype.is_floating_point()
), "dtype must be a floating-point type"
var shared_max = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[BLOCK_DIM_X]())
var shared_sum = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[BLOCK_DIM_X]())
var global_i = thread_idx.x
# Initialize out-of-bounds (shared_max[local_i], global_i >= input_size) shared memory addresses to the minimum
# finite value for dtype, ensuring that if these elements are accessed in the parallel max reduction below they
# do not influence the result (max(min_finite, x) == x for any x).
var val: Scalar[dtype] = min_finite[dtype]()
if global_i < input_size:
val = rebind[Scalar[dtype]](input[global_i])
shared_max[global_i] = val
barrier()
# Parallel reduction to find max similar to reduction we saw before
var stride = BLOCK_DIM_X // 2
while stride > 0:
if global_i < stride:
shared_max[global_i] = max(
shared_max[global_i], shared_max[global_i + stride]
)
barrier()
stride = stride // 2
var block_max = shared_max[0]
# Initialize out-of-bounds (shared_max[global_i], global_i >= input_size) shared memory addresses to 0.0,
# ensuring that if these elements are accessed in the parallel sum reduction below they
# do not influence the result (adding 0.0 does not change the sum).
var exp_val: Scalar[dtype] = 0.0
if global_i < input_size:
exp_val = rebind[Scalar[dtype]](exp(val - block_max))
shared_sum[global_i] = exp_val
barrier()
# Parallel reduction for sum similar to reduction we saw before
stride = BLOCK_DIM_X // 2
while stride > 0:
if global_i < stride:
shared_sum[global_i] += shared_sum[global_i + stride]
barrier()
stride = stride // 2
var block_sum = shared_sum[0]
# Normalize by sum
if global_i < input_size:
output[global_i] = exp_val / block_sum
Kernel signature and memory management
def softmax_gpu_kernel[
layout: Layout,
input_size: Int,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, layout],
input: TileTensor[mut=False, dtype, layout],
)
The kernel is parameterized with:
- Common layout parameter for both input and output tensors
- Vector size as an Integer parameter
- Configurable data type with float32 as default
- Mutable output tensor for in-place computation
- Non-mutable input tensor (mut=False)
Shared memory allocation
shared_max = stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[BLOCK_DIM_X]())
shared_sum = stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[BLOCK_DIM_X]())
The kernel allocates two shared memory buffers:
shared_max: For parallel maximum finding reductionshared_sum: For parallel sum computation- Both use
BLOCK_DIM_X = 128as their size - Shared memory provides fast access for all threads within a block
Thread indexing
global_i = thread_idx.x
This implementation of softmax operates on a single 1d thread block. i.e. The global and local index are the same.
Maximum-finding phase
var val: Scalar[dtype] = min_finite[dtype]()
if global_i < input_size:
val = rebind[Scalar[dtype]](input[global_i])
shared_max[local_i] = val
barrier()
This initializes each thread with:
- The minimum finite value for elements outside the valid range
- The actual input value for threads that map to valid elements
- Storage in shared memory for the reduction process
- A barrier synchronization to ensure all threads complete memory writes
Parallel max reduction
stride = BLOCK_DIM_X // 2
while stride > 0:
if local_i < stride:
shared_max[local_i] = max(shared_max[local_i], shared_max[local_i + stride])
barrier()
stride = stride // 2
This implements a parallel tree-reduction pattern:
- Start with
stride = 64(half ofBLOCK_DIM_X) - Each active thread compares two values separated by the stride
- Store the maximum in the lower index
- Synchronize all threads with a barrier
- Halve the stride and repeat
- After \(\log_2(BLOCK\_DIM\_X)~\) steps,
shared_max[0]contains the global maximum
This logarithmic reduction is significantly faster than a linear scan on large inputs.
Exponentiation with numerical stability
block_max = shared_max[0]
var exp_val: Scalar[dtype] = 0.0
if global_i < input_size:
exp_val = rebind[Scalar[dtype]](exp(val - block_max))
Each thread:
- Reads the global maximum from shared memory
- Subtracts it from its input value before taking the exponential
- This subtraction is crucial for numerical stability - it prevents overflow
- The largest exponent becomes \(e^0 = 1\), and all others are \(e^{negative} < 1\)
Parallel sum reduction
shared_sum[local_i] = exp_val
barrier()
stride = BLOCK_DIM_X // 2
while stride > 0:
if local_i < stride:
shared_sum[local_i] += shared_sum[local_i + stride]
barrier()
stride = stride // 2
The second reduction phase:
- Stores all exponential values in shared memory
- Uses the same tree-based reduction pattern as for max
- But performs addition instead of maximum comparison
- After \(\log_2(BLOCK\_DIM\_X)~\) steps,
shared_sum[0]contains the total sum of all exponentials
Final normalization
block_sum = shared_sum[0]
if global_i < input_size:
output[global_i] = exp_val / block_sum
Each thread:
- Reads the total sum from shared memory
- Divides its exponential value by this sum
- Writes the normalized probability to the output buffer
- This produces a valid probability distribution that sums to 1
Performance characteristics
The implementation has excellent performance characteristics:
- Complexity: \(O(\log n)\) for both max and sum calculations vs \(O(n)\) in a sequential approach
- Memory efficiency: Uses only \(2 \times BLOCK\_DIM\_X~\) elements of shared memory
- Work efficiency: Each thread performs approximately \(2 \times \log_2(BLOCK\_DIM\_X)~\) operations
- Load balancing: Each thread handles the same amount of work
- Synchronization: Uses minimal barriers, only where necessary
- Memory access: Coalesced global memory access pattern for optimal bandwidth
The algorithm is also numerically robust, handling potential overflow/underflow cases by applying the max-subtraction technique that maintains precision across the wide range of values common in neural network activations.
CPU fallback implementation
def softmax_cpu_kernel[
input_size: Int,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
):
comptime assert (
dtype.is_floating_point()
), "dtype must be a floating-point type"
var max_val: Scalar[dtype] = min_finite[dtype]()
for i in range(input_size):
max_val = max(max_val, rebind[Scalar[dtype]](input[i]))
var sum_exp: Scalar[dtype] = 0.0
for i in range(input_size):
var exp_val = rebind[Scalar[dtype]](exp(input[i] - max_val))
output[i] = exp_val
sum_exp += exp_val
for i in range(input_size):
output[i] = output[i] / sum_exp
-
Maximum Finding:
var max_val: Scalar[dtype] = min_finite[dtype]() for i in range(input_size): max_val = max(max_val, rebind[Scalar[dtype]](input[i]))We initialize with the minimum finite value and perform a linear scan through the array, keeping track of the maximum value encountered. This has \(O(n)\) complexity but works efficiently on CPU where we don’t have many cores to parallelize across.
-
Exponential Computation and Summation:
var sum_exp: Scalar[dtype] = 0.0 for i in range(input_size): var exp_val = rebind[Scalar[dtype]](exp(input[i] - max_val)) output[i] = exp_val sum_exp += exp_valWe compute \(e^{x_i - max}\) for each element, store the result in the output buffer, and accumulate the sum \(\sum_{j=1}^{n} e^{x_j - max}\) in a single pass. This approach minimizes memory operations compared to using separate loops.
-
Normalization:
for i in range(input_size): output[i] = output[i] / sum_expFinally, we normalize each element by dividing by the sum, producing a proper probability distribution according to the softmax formula:
$$\Large \text{softmax}(x_i) = \frac{e^{x_i - \max(x)}}{\sum_{j=1}^{n} e^{x_j - \max(x)}}$$
The CPU implementation uses the same numerical stability technique (subtracting the maximum) but with sequential operations rather than parallel ones. It’s simpler than the GPU version since it doesn’t need to handle shared memory or thread synchronization, but it’s also less efficient for large inputs.
Both implementations are registered with MAX Graph’s custom operation system
through the @compiler.register("softmax") decorator, allowing seamless
execution on either device type based on availability.
Python integration
with Graph(
"softmax_graph",
input_types=[
TensorType(
dtype,
shape=input_tensor.shape,
device=DeviceRef.from_device(device),
),
],
custom_extensions=[mojo_kernels],
) as graph:
input_value = graph.inputs[0]
# The output shape is the same as the input for softmax
# Note: the name must match the name used in `@compiler.register("softmax")` in op/softmax.mojo
output = ops.custom(
name="softmax",
values=[input_value],
device=DeviceRef.from_device(device),
out_types=[
TensorType(
dtype=input_value.tensor.dtype,
shape=input_value.tensor.shape,
device=DeviceRef.from_device(device),
)
],
parameters={
"target": "gpu" if device == Accelerator() else "cpu",
"input_size": input_tensor.shape[0],
"dtype": dtype,
},
)[0].tensor
graph.output(output)
-
Graph Setup and Configuration:
with Graph( "softmax_graph", input_types=[ TensorType( dtype, shape=input_tensor.shape, device=DeviceRef.from_device(device), ), ], custom_extensions=[mojo_kernels], ) as graph:This creates a computation graph named “softmax_graph” that:
- Defines the input tensor type with proper dtype and shape
- Maps the tensor to the target device (CPU or GPU)
- Loads our custom Mojo operations from the specified directory
- The
custom_extensionsparameter is crucial for linking to our Mojo implementation
-
Custom Operation Configuration:
output = ops.custom( name="softmax", values=[input_value], out_types=[ TensorType( dtype=input_value.tensor.dtype, shape=input_value.tensor.shape, device=DeviceRef.from_device(device), ) ], parameters={ "target": "gpu" if device == Accelerator() else "cpu", "input_size": input_tensor.shape[0], "dtype": dtype, }, )[0].tensorThis sets up our custom operation with:
- Name matching the
@compiler.register("softmax")in our Mojo code - Input values passed as a list
- Output type definition matching the input shape and type
- Parameters required by our kernel, including the target device, vector size and data type
- We extract the tensor from the first returned element with
[0].tensor
- Name matching the
-
Graph Output Definition:
graph.output(output)This registers our operation’s result as the graph’s output.
The main script includes comprehensive testing that:
- Generates random input data:
np.random.randn(INPUT_SIZE).astype(np.float32) - Calculates expected results with SciPy:
scipy_softmax(input_array) - Verifies numerical accuracy:
np.testing.assert_allclose(..., rtol=1e-5) - Confirms the output is a valid probability distribution:
np.sum(result.to_numpy())
This implementation showcases the power of MAX Graph for integrating high-performance Mojo kernels with Python’s scientific computing ecosystem, providing both efficiency and ease of use.
Puzzle 19: Attention Op
Overview
In this puzzle, we’ll implement the attention mechanism as a custom MAX Graph operation. Attention is a fundamental building block of modern neural networks, popularized particularly by transformers, that allows models to focus on relevant parts of the input when making predictions.
Mathematically, the attention function is defined as:
$$\Large \text{Attention}(Q, K, V) = \text{softmax}(Q \cdot K^T) \cdot V$$
Where:
- \(Q\) is the query vector of shape \((d,)~\) - represents what we’re looking for
- \(K\) is the key matrix of shape \((\text{seq_len}, d)~\) - represents what’s available to match against
- \(V\) is the value matrix of shape \((\text{seq_len}, d)~\) - represents the information to retrieve
- The output is a weighted combination vector of shape \((d,)\)
The computation involves three main steps:
- Attention Scores: Compute \(Q \cdot K^T\) to measure how well the query matches each key vector
- Attention Weights: Apply softmax to convert scores into a probability distribution (weights sum to 1)
- Weighted Sum: Combine value vectors using attention weights to produce the final output
Understanding attention: a step-by-step breakdown
Think of attention as a smart lookup mechanism. Given a query (what you’re looking for), attention finds the most relevant information from a collection of key-value pairs:
-
Step 1 - Similarity Matching: Compare your query \(Q\) against all keys \(K\) to get similarity scores
- Compute \(Q \cdot K^T\) where each score measures how well \(Q\) matches each key vector
- Higher scores = better matches
-
Step 2 - Probability Distribution: Convert raw scores into normalized weights
- Apply softmax to ensure all weights sum to 1.0
- This creates a probability distribution over which values to focus on
-
Step 3 - Weighted Retrieval: Combine values using the attention weights
- Multiply each value vector by its corresponding weight
- Sum everything up to get the final output
Real-world analogy: Imagine searching a library. Your query is what you want to find, the book titles are keys, and the book contents are values. Attention computes how relevant each book is to your query, then gives you a summary weighted by relevance.
Visual computation flow
Input: Q(16,) K(16,16) V(16,16)
↓ ↓ ↓
Step 1: Q(1,16) @ K^T(16,16) → Scores(1,16)
↓
Step 2: softmax(Scores) → Weights(1,16) [sum = 1.0]
↓
Step 3: Weights(1,16) @ V(16,16) → Output(1,16) → reshape → Output(16,)
Key insight: We reshape the query vector \(Q\) from shape \((16,)\) to \((1,16)\) so we can use matrix multiplication instead of manual dot products. This allows us to leverage the highly optimized tiled matmul kernel from Puzzle 18!
Our GPU implementation reuses and combines optimized kernels from previous puzzles:
- Tiled matrix multiplication from Puzzle 16 for efficient \(Q \cdot K^T\) and \(\text{weights} \cdot V\) operations
- Shared memory transpose for computing \(K^T\) efficiently
- Parallel softmax from Puzzle 18 for numerically stable attention weight computation
🔄 Kernel Reuse Strategy: This puzzle demonstrates how to build complex operations by combining proven, optimized kernels from previous puzzles. Rather than writing everything from scratch, we leverage the
matmul_idiomatic_tiledfrom Puzzle 16 andsoftmax_kernelfrom Puzzle 18, showcasing the power of modular GPU kernel design.
Key concepts
- Vector attention mechanism for sequence processing
- Kernel reuse: Leveraging proven implementations from Puzzle 16 and Puzzle 18
- Efficient matrix multiplication using shared memory tiling
- Memory-optimized tensor reshaping to minimize buffer allocation
- Integration of multiple optimized kernels into a single operation
- Custom MAX Graph operation with multi-input support
- CPU fallback implementation for compatibility
Configuration
- Sequence length: \(\text{SEQ_LEN} = 16~\) - number of key/value vectors in our sequence
- Model dimension: \(\text{D} = 16~\) - dimensionality of each vector (query, keys, values)
- Threads per block: Individually optimized for each kernel
- Grid dimensions: Computed dynamically to handle different matrix sizes efficiently
- Shared memory: Utilized in transpose, matmul, and softmax kernels for performance
Layout configuration:
- Query tensor:
row_major[d]() - Key tensor:
row_major[seq_len, d]() - Value tensor:
row_major[seq_len, d]() - Output tensor:
row_major[d]() - Custom op parameters:
{"seq_len": seq_len, "d": d, "dtype": dtype}
Key aspects of this puzzle include:
- Multi-kernel orchestration: Combining transpose, matmul, and softmax operations
- Memory optimization: Using reshape operations and buffer reuse to minimize allocations
- Numerical stability: Leveraging the proven softmax implementation from Puzzle 18
- Performance optimization: Using tiled algorithms from Puzzle 16 for all matrix operations
- Multi-input operations: Handling three input tensors (Q, K, V) in a single custom op
Our attention custom operation will:
- Accept query, key, and value tensors from Python
- Process them efficiently on GPU using optimized kernels
- Return the attention-weighted output vector
- Match the results of NumPy reference implementation
Code to complete
To complete this puzzle, we’ll leverage the tiled matmul kernel from Puzzle 16 and the softmax kernel from Puzzle 18. You only need to implement the transpose kernel in the Mojo file using shared memory.
1. Implement the transpose kernel
def transpose_kernel[
rows: Int,
cols: Int,
OutLayout: TensorLayout,
InLayout: TensorLayout,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
inp: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
):
# FILL ME IN (roughly 18 lines)
...
View full file: problems/p19/op/attention.mojo
Tips
Transpose Kernel Implementation Guide:
-
Shared Memory Setup: Use
stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TRANSPOSE_BLOCK_DIM_XY, TRANSPOSE_BLOCK_DIM_XY]())to create a squareTRANSPOSE_BLOCK_DIM_XY×TRANSPOSE_BLOCK_DIM_XYshared memory tile for efficient data exchange between threads -
Thread Indexing: Map threads to matrix elements:
local_row = thread_idx.y,local_col = thread_idx.x(position within the block)global_row = block_idx.y * TRANSPOSE_BLOCK_DIM_XY + local_row(position in the full matrix)
-
Two-Phase Operation:
- Phase 1: Load data from global memory into shared memory with normal indexing
- Phase 2: Store data from shared memory to global memory with swapped indexing
-
Critical Synchronization: Call
barrier()between loading and storing to ensure all threads have finished loading before any thread starts storing -
Transpose Magic: The transpose happens through swapped indexing:
shared_tile[local_col, local_row]instead ofshared_tile[local_row, local_col] -
Boundary Handling: Check bounds when accessing global memory to avoid out-of-bounds reads/writes for matrices that don’t perfectly divide by
TRANSPOSE_BLOCK_DIM_XYxTRANSPOSE_BLOCK_DIM_XY -
Memory Coalescing: This pattern ensures both reads and writes are coalesced for optimal memory bandwidth utilization
2. Orchestrate the attention
var gpu_ctx = rebind[DeviceContext](ctx[])
# Define layouts for matrix multiplication
# Q reshaped to (1, d)
comptime layout_q_2d = row_major[1, d]()
comptime Q2DLayout = type_of(layout_q_2d)
# K^T is (d, seq_len)
comptime layout_k_t = row_major[d, seq_len]()
comptime KTLayout = type_of(layout_k_t)
# Scores as (1, seq_len)
comptime layout_scores_2d = row_major[1, seq_len]()
comptime Scores2DLayout = type_of(layout_scores_2d)
# Weights as (1, seq_len)
comptime layout_weights_2d = row_major[1, seq_len]()
comptime Weights2DLayout = type_of(layout_weights_2d)
# Result as (1, d)
comptime layout_result_2d = row_major[1, d]()
comptime Result2DLayout = type_of(layout_result_2d)
# Transpose implementation limited to square (TRANSPOSE_BLOCK_DIM_XY x TRANSPOSE_BLOCK_DIM_XY) thread blocks
comptime transpose_threads_per_block = (
TRANSPOSE_BLOCK_DIM_XY,
TRANSPOSE_BLOCK_DIM_XY,
)
# Tile over the K (seq_len, d) matrix
comptime transpose_blocks_per_grid = (
(d + TRANSPOSE_BLOCK_DIM_XY - 1) // TRANSPOSE_BLOCK_DIM_XY,
(seq_len + TRANSPOSE_BLOCK_DIM_XY - 1)
// TRANSPOSE_BLOCK_DIM_XY,
)
# Matmul implementation limited to square (MATMUL_BLOCK_DIM_XY x MATMUL_BLOCK_DIM_XY) thread blocks
comptime matmul_threads_per_block = (
MATMUL_BLOCK_DIM_XY,
MATMUL_BLOCK_DIM_XY,
)
# seq_len outputs ( Q @ K^T = (1, d) @ (d, seq_len) -> (1, seq_len) ) with one thread per output
comptime scores_blocks_per_grid = (
seq_len + MATMUL_BLOCK_DIM_XY - 1
) // MATMUL_BLOCK_DIM_XY
comptime softmax_threads = SOFTMAX_BLOCK_DIM_X
comptime softmax_blocks_per_grid = 1
# d outputs ( weights @ V = (1, seq_len) @ (seq_len, d) -> (1, d) ) with one thread per output
comptime result_blocks_per_grid = (
d + MATMUL_BLOCK_DIM_XY - 1
) // MATMUL_BLOCK_DIM_XY
# Allocate minimal temporary buffers - reuse same buffer for different shapes
var k_t_buf = gpu_ctx.enqueue_create_buffer[dtype](
seq_len * d
) # K^T as (d, seq_len)
var scores_weights_buf = gpu_ctx.enqueue_create_buffer[dtype](
seq_len
) # Reused for scores and weights
var k_t = TileTensor(k_t_buf, layout_k_t)
# Step 1: Reshape Q from (d,) to (1, d) - no buffer needed
# FILL ME IN 1 line
# Step 2: Transpose K from (seq_len, d) to K^T (d, seq_len)
# FILL ME IN 1 function call
# Step 3: Compute attention scores using matmul: Q @ K^T = (1, d) @ (d, seq_len) -> (1, seq_len)
# This computes Q · K^T[i] = Q · K[i] for each column i of K^T (which is row i of K)
# Reuse scores_weights_buf as (1, seq_len) for scores
# FILL ME IN 2 lines
# Step 4: Reshape scores from (1, seq_len) to (seq_len,) for softmax
# FILL ME IN 1 line
# Step 5: Apply softmax to get attention weights
# FILL ME IN 1 function call
# Step 6: Reshape weights from (seq_len,) to (1, seq_len) for final matmul
# FILL ME IN 1 line
# Step 7: Compute final result using matmul: weights @ V = (1, seq_len) @ (seq_len, d) -> (1, d)
# Reuse out_tensor reshaped as (1, d) for result
# FILL ME IN 2 lines
View full file: problems/p19/op/attention.mojo
Test the kernels
pixi run p19
pixi run -e amd p19
pixi run -e apple p19
uv run poe p19
When successful, you should see output similar to on CPU and GPU:
Input shapes: Q=(16,), K=(16, 16), V=(16, 16)
Sample Q values: [ 0.04967142 -0.01382643 0.06476886 0.15230298 -0.02341534]
Sample K[0] values: [-0.10128311 0.03142473 -0.09080241 -0.14123037 0.14656489]
Sample V[0] values: [ 0.11631638 0.00102331 -0.09815087 0.04621035 0.01990597]
================================================================================
STEP-BY-STEP VECTOR ATTENTION COMPUTATION DEBUG
================================================================================
1. INPUT SHAPES:
Q shape: (16,) (query vector)
K shape: (16, 16) (key matrix)
V shape: (16, 16) (value matrix)
Q[:5]: [ 0.04967142 -0.01382643 0.06476886 0.15230298 -0.02341534]
2. ATTENTION SCORES (K[i] · Q):
Scores shape: (16,)
Scores[:5]: [-0.03479404 -0.01563787 0.04834607 0.06764711 0.04001468]
Min: -0.061636, Max: 0.067647
Manual verification:
Q · K[0] = K[0] · Q = -0.034794 (computed: -0.034794)
Q · K[1] = K[1] · Q = -0.015638 (computed: -0.015638)
Q · K[2] = K[2] · Q = 0.048346 (computed: 0.048346)
3. SOFTMAX:
Max score: 0.067647
Attention weights shape: (16,)
Attention weights[:5]: [0.05981331 0.06097015 0.06499878 0.0662655 0.06445949]
Sum: 1.000000 (should be 1.0)
4. WEIGHTED SUM OF VALUES:
Output shape: (16,)
Output[:5]: [-0.00935538 -0.0243433 0.00306551 0.02346884 0.019306 ]
Output norm: 0.092764
Manual output[:5]: [-0.00935538 -0.0243433 0.00306551 0.02346884 0.019306 ]
Match: True
================================================================================
TESTING INDIVIDUAL OPERATIONS
================================================================================
Test 1: Vector Dot Product
a · b = 3.000000
Test 2: Matrix-Vector Multiplication
M @ v = [ 3. 7. 11.]
Test 3: Softmax
Input: [1. 2. 3. 4.]
Softmax: [0.0320586 0.08714432 0.2368828 0.6439143 ]
Sum: 1.000000
================================================================================
TESTING FULL ATTENTION
================================================================================
Compiling attention graph on Device(type=cpu,id=0)
Executing attention on Device(type=cpu,id=0)
====================================================================================================
CPU attention output[:5]: [-0.00935538 -0.02434331 0.00306551 0.02346884 0.019306 ]
CPU matches NumPy: True
Compiling attention graph on Device(type=gpu,id=0)
Executing attention on Device(type=gpu,id=0)
====================================================================================================
GPU attention output[:5]: [-0.00935538 -0.0243433 0.00306551 0.02346884 0.019306 ]
Expected output[:5]: [-0.00935538 -0.0243433 0.00306551 0.02346884 0.019306 ]
GPU matches NumPy: True
================================================================================
FINAL VERIFICATION
================================================================================
✓ CPU implementation PASSED
✓ GPU implementation PASSED
Output vector norms:
CPU: 0.092764
GPU: 0.092764
Expected: 0.092764
This indicates that your custom MAX Graph operation correctly implements the attention algorithm and produces results matching the NumPy reference implementation.
Solution
To solve this puzzle, we need to implement the transpose kernel in Mojo and complete the Python graph definition for our attention custom operation. This puzzle builds upon concepts from previous puzzles, combining tiled matrix multiplication from Puzzle 16 and softmax from Puzzle 18 into a complete attention mechanism.
Reused kernels
Our implementation directly incorporates these proven kernels:
matmul_idiomatic_tiledfrom Puzzle 16 - Powers both \(Q \times K^T\) and \(\text{weights} \times V\) operationssoftmax_kernelfrom Puzzle 18 - Provides numerically stable attention weight computation
This exemplifies modular GPU architecture: complex neural network operations built by orchestrating proven, optimized components rather than monolithic implementations.
The attention operation follows the canonical mathematical definition:
$$\Large \text{Attention}(Q, K, V) = \text{softmax}(Q \cdot K^T) \cdot V$$
Breaking down the math:
- \(Q \cdot K^T~\): Query-key similarity scores of shape: \((1, \text{seq_len})\)
- \(\text{softmax}(\cdot)~\): Normalize scores to probabilities of shape: \((1, \text{seq_len})\)
- \(\text{weights} \cdot V~\): Weighted combination of values of shape: \((1, d)\)
This involves several computational steps that we optimize using GPU kernels from previous puzzles.
1. Transpose kernel implementation
def transpose_kernel[
rows: Int,
cols: Int,
OutLayout: TensorLayout,
InLayout: TensorLayout,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
inp: TileTensor[mut=True, dtype, InLayout, MutAnyOrigin],
):
"""Transpose matrix using shared memory tiling for coalesced access."""
comptime shared_layout = row_major[
TRANSPOSE_BLOCK_DIM_XY, TRANSPOSE_BLOCK_DIM_XY
]()
var shared_tile = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](shared_layout)
var local_row = thread_idx.y
var local_col = thread_idx.x
var global_row = block_idx.y * TRANSPOSE_BLOCK_DIM_XY + local_row
var global_col = block_idx.x * TRANSPOSE_BLOCK_DIM_XY + local_col
var inp_lt = inp.to_layout_tensor()
var output_lt = output.to_layout_tensor()
var shared_tile_lt = shared_tile.to_layout_tensor()
if global_row < rows and global_col < cols:
shared_tile_lt[local_row, local_col] = inp_lt[global_row, global_col]
barrier()
var out_row = block_idx.x * TRANSPOSE_BLOCK_DIM_XY + local_row
var out_col = block_idx.y * TRANSPOSE_BLOCK_DIM_XY + local_col
# Store data from shared memory to global memory (coalesced write)
# Note: we transpose the shared memory access pattern
if out_row < cols and out_col < rows:
output_lt[out_row, out_col] = shared_tile_lt[local_col, local_row]
The transpose kernel uses shared memory tiling to achieve coalesced memory access patterns. Key implementation details:
Critical transpose pattern
# Load with normal indexing
shared_tile[local_row, local_col] = inp[global_row, global_col]
barrier()
# Store with swapped indexing for transpose
output[out_row, out_col] = shared_tile[local_col, local_row]
The transpose happens through swapped indexing in shared memory access
([local_col, local_row] instead of [local_row, local_col]) and
swapped block coordinates for output positioning. This ensures both reads
and writes remain coalesced while achieving the transpose operation.
2. GPU kernel orchestration
# Step 1: Reshape Q from (d,) to (1, d) - no buffer needed
var q_2d = q_tensor.reshape(layout_q_2d)
# Step 2: Transpose K from (seq_len, d) to K^T (d, seq_len)\
comptime kernel = transpose_kernel[
seq_len, d, KTLayout, KLayout, dtype
]
gpu_ctx.enqueue_function[kernel, kernel](
k_t,
k_tensor,
grid_dim=transpose_blocks_per_grid,
block_dim=transpose_threads_per_block,
)
# Step 3: Compute attention scores using matmul: Q @ K^T = (1, d) @ (d, seq_len) -> (1, seq_len)
# This computes Q · K^T[i] = Q · K[i] for each column i of K^T (which is row i of K)
# Reuse scores_weights_buf as (1, seq_len) for scores
var scores_2d = TileTensor(scores_weights_buf, layout_scores_2d)
comptime kernel2 = matmul_idiomatic_tiled[
1,
seq_len,
d,
Scores2DLayout,
Q2DLayout,
KTLayout,
dtype,
]
gpu_ctx.enqueue_function[kernel2, kernel2](
scores_2d,
q_2d,
k_t,
grid_dim=scores_blocks_per_grid,
block_dim=matmul_threads_per_block,
)
# Step 4: Reshape scores from (1, seq_len) to (seq_len,) for softmax
var weights = scores_2d.reshape(layout_scores)
# Step 5: Apply softmax to get attention weights (in-place)
comptime ScoresLayout = type_of(layout_scores)
comptime kernel3 = softmax_gpu_kernel[seq_len, ScoresLayout, dtype]
# Create two TileTensor views from the underlying buffer to avoid aliasing error
var weights_out = TileTensor[
mut=True, dtype, ScoresLayout, MutAnyOrigin
](scores_weights_buf, layout_scores)
var weights_in = TileTensor[
mut=True, dtype, ScoresLayout, MutAnyOrigin
](scores_weights_buf, layout_scores)
gpu_ctx.enqueue_function[kernel3, kernel3](
weights_out,
weights_in,
grid_dim=softmax_blocks_per_grid,
block_dim=softmax_threads,
)
# Step 6: Reshape weights from (seq_len,) to (1, seq_len) for final matmul
var weights_2d = weights.reshape(layout_weights_2d)
# Step 7: Compute final result using matmul: weights @ V = (1, seq_len) @ (seq_len, d) -> (1, d)
# Reuse out_tensor reshaped as (1, d) for result
var result_2d = output_tensor.reshape(layout_result_2d)
comptime kernel4 = matmul_idiomatic_tiled[
1,
d,
seq_len,
Result2DLayout,
Weights2DLayout,
VLayout,
dtype,
]
gpu_ctx.enqueue_function[kernel4, kernel4](
result_2d,
weights_2d,
v_tensor,
grid_dim=result_blocks_per_grid,
block_dim=matmul_threads_per_block,
)
The GPU orchestration demonstrates sophisticated kernel chaining and zero-copy memory optimization:
Advanced memory optimization strategies
# Zero-copy reshaping - no data movement, just reinterpret tensor shape
q_2d = q_tensor.reshape[layout_q_2d]()
# Aggressive buffer reuse - same memory, different interpretations
weights = scores_2d.reshape[layout_scores]()
The implementation achieves maximum memory efficiency through:
- Zero-copy reshaping: Reinterpreting tensor shapes without moving data in memory
- Intelligent buffer reuse: The same
scores_weights_bufserves dual purposes as both scores \((1,\text{seq_len})\) and weights \((\text{seq_len},)\) - Minimal allocations: Only 2 temporary buffers power the entire attention operation
- Memory coalescing: All operations maintain optimal memory access patterns
Strategic kernel reuse pattern
- Steps 3 & 7: Both leverage
matmul_idiomatic_tiledfrom Puzzle 16- Step 3: \(Q \times K^T\) → attention scores computation \((1,d) \times (d,\text{seq_len}) \rightarrow (1,\text{seq_len})\)
- Step 7: \(\text{weights} \times V\) → final weighted output \((1,\text{seq_len}) \times (\text{seq_len},d) \rightarrow (1,d)\)
- Both operations include bounds checking for robustness with variable matrix dimensions
- Step 5: Employs
softmax_kernelfrom Puzzle 18- Converts raw scores into normalized probability distribution
- Ensures numerical stability through max subtraction and parallel reduction
- Guarantees \(\sum_{i} \text{weights}[i] = 1.0\)
This exemplifies modular GPU architecture: complex neural network operations built by orchestrating proven, optimized kernels rather than monolithic implementations!
Key implementation insights
Memory optimization strategy
The implementation achieves minimal memory allocation through aggressive buffer reuse:
# Only 2 temporary buffers needed for the entire operation
k_t_buf = gpu_ctx.enqueue_create_buffer[dtype](seq_len * d)
scores_weights_buf = gpu_ctx.enqueue_create_buffer[dtype](seq_len)
Key optimization insights:
- The same
scores_weights_bufis reused for both attention scores and weights through reshape operations - Zero-copy tensor reshaping eliminates unnecessary data movement
Kernel reuse architecture
This puzzle showcases modular kernel design by combining three specialized kernels:
matmul_idiomatic_tiled(used twice) - Powers both \(Q \times K^T\) and \(\text{weights} \times V\) operationssoftmax_kernel- Provides numerically stable attention weight computation with parallel reductiontranspose_kernel- Enables efficient \(K^T\) computation with coalesced memory access
Architectural benefits:
- Composability: Complex operations built from proven components
- Maintainability: Each kernel has a single, well-defined responsibility
- Performance: Leverages highly optimized implementations from previous puzzles
- Scalability: Modular design enables easy extension to larger attention mechanisms
The implementation demonstrates that sophisticated neural network operations can be built by orchestrating simpler, well-tested GPU kernels rather than writing monolithic implementations.
Bonus Challenges
Challenge I: advanced softmax implementations
This challenge extends Puzzle 18: Softmax Op
Here are some advanced challenges to extend your softmax implementation:
1. Large-scale softmax: Handling TPB < SIZE
When the input size exceeds the number of threads per block (TPB < SIZE), our
current implementation fails because a single block cannot process the entire
array. Two approaches to solve this:
1.1 Buffer reduction
- Store block-level results (max and sum) in device memory
- Use a second kernel to perform reduction across these intermediate results
- Implement a final normalization pass that uses the global max and sum
1.2 Two-pass softmax
- First pass: Each block calculates its local max value
- Synchronize and compute global max
- Second pass: Calculate \(e^{x-max}\) and local sum
- Synchronize and compute global sum
- Final pass: Normalize using global sum
2. Batched softmax
Implement softmax for a batch of vectors (2D input tensor) with these variants:
- Row-wise softmax: Apply softmax independently to each row
- Column-wise softmax: Apply softmax independently to each column
- Compare performance differences between these implementations
Challenge II: advanced attention mechanisms
This challenge extends Puzzle 19: Attention Op
Building on the vector attention implementation, here are advanced challenges that push the boundaries of attention mechanisms:
1. Larger sequence lengths
Extend the attention mechanism to handle longer sequences using the existing kernels:
1.1 Sequence length scaling
- Modify the attention implementation to handle
SEQ_LEN = 32andSEQ_LEN = 64 - Update the
TPB(threads per block) parameter accordingly - Ensure the transpose kernel handles the larger matrix sizes correctly
1.2 Dynamic sequence lengths
- Implement attention that can handle variable sequence lengths at runtime
- Add bounds checking in the kernels to handle sequences shorter than
SEQ_LEN - Compare performance with fixed vs. dynamic sequence length handling
2. Batched vector attention
Extend to process multiple attention computations simultaneously:
2.1 Batch processing
- Modify the attention operation to handle multiple query vectors at once
- Input shapes: Q(batch_size, d), K(seq_len, d), V(seq_len, d)
- Output shape: (batch_size, d)
- Reuse the existing kernels with proper indexing
2.2 Memory optimization for batches
- Minimize memory allocations by reusing buffers across batch elements
- Compare performance with different batch sizes (2, 4, 8)
- Analyze memory usage patterns
Puzzle 20: 1D Convolution Op
From MAX Graph to PyTorch custom ops
We’re now entering Part V of our GPU puzzle journey: PyTorch Custom Operations.
In Puzzle 17, we learned how to integrate Mojo GPU kernels with Python using MAX Graph. Now we’ll explore how to:
- Use the same Mojo kernel with PyTorch’s CustomOpLibrary
- Integrate with PyTorch’s tensor system and autograd
- Compare MAX Graph vs PyTorch approaches for custom operations
- Understand the critical pattern of explicit output tensor allocation
This transition shows how the same optimized GPU kernel can work with different Python integration approaches.
Overview
In this puzzle, we’ll take the exact same 1D convolution kernel from Puzzle 17 and integrate it with PyTorch using the CustomOpLibrary instead of MAX Graph.
The key learning here is that the same Mojo kernel works unchanged - only the Python integration layer differs between MAX Graph and PyTorch approaches.
Code to complete
To complete this puzzle, you need to fill in one line to call the custom operation:
import torch
from max.experimental.torch import CustomOpLibrary
def conv1d_pytorch(
input_tensor: torch.Tensor, kernel_tensor: torch.Tensor
) -> torch.Tensor:
"""
1D convolution using our custom PyTorch operation.
This demonstrates the transition from MAX Graph (p15) to PyTorch CustomOpLibrary.
Uses the EXACT same Mojo kernel, but different Python integration!
"""
# Load our custom operations
mojo_kernels = Path(__file__).parent / "op"
ops = CustomOpLibrary(mojo_kernels)
# Create output tensor with same shape as input
output_tensor = torch.empty_like(input_tensor)
# Call our custom conv1d operation with explicit output tensor
# The Mojo signature expects: (out, input, kernel)
_conv1d = ops.conv1d[
{
"input_size": input_tensor.shape[0],
"conv_size": kernel_tensor.shape[0],
}
]
# FILL IN with 1 line of code
return output_tensor
View full file: problems/p20/p20.py
You can run the puzzle with:
pixi run p20
pixi run -e amd p20
uv run poe p20
When successful, you should see output similar to:
Puzzle 20: From MAX Graph to PyTorch Custom Ops
============================================================
Input array: [ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14.]
Convolution kernel: [0. 1. 2. 3.]
NumPy reference result: [14. 20. 26. 32. 38. 44. 50. 56. 62. 68. 74. 80. 41. 14. 0.]
Testing PyTorch Custom Op (device: cuda)
----------------------------------------
PyTorch custom op result: [14. 20. 26. 32. 38. 44. 50. 56. 62. 68. 74. 80. 41. 14. 0.]
✅ PyTorch custom op verification PASSED
Comparing with MAX Graph approach (like p15)
--------------------------------------------
MAX Graph result: [14. 20. 26. 32. 38. 44. 50. 56. 62. 68. 74. 80. 41. 14. 0.]
✅ MAX Graph verification PASSED
✅ PyTorch and MAX Graph results MATCH
Solution
The solution requires calling the compiled custom operation with the proper arguments:
# Call our custom conv1d operation with explicit output tensor
# The Mojo signature expects: (out, input, kernel)
conv1d = ops.conv1d[
{
"input_size": input_tensor.shape[0],
"conv_size": kernel_tensor.shape[0],
}
]
torch.compile(conv1d)(output_tensor, input_tensor, kernel_tensor)
This solution demonstrates several critical concepts:
1. torch.compile() integration
The solution shows torch.compile integration
torch.compile(conv1d)(output_tensor, input_tensor, kernel_tensor)
2. Explicit Output Tensor Allocation
output_tensor = torch.empty_like(input_tensor)
- Unlike MAX Graph which handles output allocation automatically
- PyTorch CustomOpLibrary requires pre-allocated output tensors
- The Mojo operation signature expects
(out, input, kernel)order
3. Parameter Dictionary
ops.conv1d[{"input_size": input_tensor.shape[0], "conv_size": kernel_tensor.shape[0]}]
- Parameters are passed as a dictionary to the operation
- These become compile-time parameters in the Mojo kernel
- Must match the parameter names in the Mojo
@staticmethod fn executesignature
4. Same Kernel, Different Integration
The underlying Mojo kernel (conv1d_kernel) is identical to Puzzle 17:
- Same GPU kernel code
- Same memory access patterns
- Same computational logic
- Only the Python wrapper layer changes
Key concepts
This puzzle illustrates several important patterns for PyTorch custom operations:
| Concept | MAX Graph (p15) | PyTorch CustomOpLibrary (p18) |
|---|---|---|
| Output Allocation | Automatic | Manual (torch.empty_like()) |
| Operation Call | ops.custom(...) | torch.compile(op)(...) |
| Parameter Passing | parameters={...} | op[{...}] |
| Device Management | Explicit device context | PyTorch tensor device |
| Memory Management | MAX Graph tensors | PyTorch tensors |
Critical pattern: Explicit output tensor allocation
The most important difference is that PyTorch CustomOpLibrary requires explicit output tensor allocation:
# ❌ This won't work - no output tensor
result = torch.compile(conv1d)(input_tensor, kernel_tensor)
# ✅ This works - pre-allocated output tensor
output_tensor = torch.empty_like(input_tensor)
torch.compile(conv1d)(output_tensor, input_tensor, kernel_tensor)
This pattern ensures:
- Memory is allocated on the correct device
- Output tensor has the right shape and dtype
- The Mojo kernel can write directly to the output buffer
torch.compile() integration
torch.compile() is essential because it:
- Handles memory layout conversion between PyTorch and Mojo
- Manages device synchronization (CPU ↔ GPU)
- Optimizes tensor format conversion
- Provides proper error handling for memory operations
Note: Without torch.compile(), you might encounter std::bad_alloc errors
because the raw operation can’t handle PyTorch’s tensor memory management.
Debugging custom operations
Common issues and solutions:
- Memory Allocation Errors: Always use
torch.compile() - Wrong Output Shape: Ensure output tensor matches expected dimensions
- Device Mismatch: All tensors must be on the same device
- Parameter Errors: Verify parameter names match Mojo operation signature
The debug approach: Compare your PyTorch results with the MAX Graph reference implementation that runs the same kernel.
Puzzle 21: Embedding Op
Memory access patterns and performance
We’re continuing Part IV with a focus on memory-bound operations and GPU memory access optimization.
Building on Puzzle 20, you’ll now explore how different kernel implementations of the same operation can have dramatically different performance characteristics. You’ll learn:
- How GPU memory coalescing affects performance
- Why grid configuration matters for memory-bound operations
- How to design kernels with optimal memory access patterns
- The performance implications of different threading strategies
This puzzle demonstrates that how you access memory can be more important than what computation you perform.
Overview
In this puzzle, you’ll implement two different GPU kernels for embedding operations - a fundamental component in neural networks. While both kernels produce identical results, they use different memory access patterns that lead to significant performance differences.
You’ll compare:
- 1D coalesced kernel: Optimized for memory bandwidth with consecutive memory accesses
- 2D non-coalesced kernel: Suboptimal memory access pattern for comparison
This comparison teaches the critical importance of memory coalescing in GPU kernel performance.
Background: Embedding operations
An embedding operation converts discrete token indices into dense vector representations:
# Input: token indices
indices = [[1, 5, 2], [7, 1, 9]] # Shape: [batch_size, seq_len]
# Embedding table (learned parameters)
embedding_table = [ # Shape: [vocab_size, embed_dim]
[0.1, 0.2, 0.3, 0.4], # Token 0
[0.5, 0.6, 0.7, 0.8], # Token 1
[0.9, 1.0, 1.1, 1.2], # Token 2
# ... more tokens
]
# Output: embedded vectors
output[0,0] = embedding_table[1] # [0.5, 0.6, 0.7, 0.8]
output[0,1] = embedding_table[5] # lookup token 5's embedding
output[0,2] = embedding_table[2] # [0.9, 1.0, 1.1, 1.2]
# ... and so on
This operation is memory-bound - performance depends on how efficiently you can read from the embedding table and write to the output tensor.
Learning path
This puzzle is structured in two parts to build your understanding systematically:
Simple embedding kernel
Start here to implement the actual puzzle code and understand the kernel implementations.
What you’ll do:
- Complete two different GPU embedding kernels (1D coalesced vs 2D non-coalesced)
- Learn fundamental memory access patterns for GPU programming
- See the same algorithm implemented with different threading strategies
- Understand custom operation registration in Mojo
Performance comparison
Deep dive into why the kernels perform differently and the theory behind memory coalescing.
What you’ll learn:
- Why memory coalescing matters for GPU performance
- How thread organization affects memory bandwidth utilization
- Real-world implications for neural network optimization
- Optimization strategies for memory-bound operations
Getting started
Ready to explore GPU memory optimization? Start with the Simple embedding kernel to implement the code, then move to Performance comparison to understand the performance implications.
💡 Success tip: Pay attention to how the different grid configurations (1D vs 2D) affect memory access patterns - this insight applies to many GPU programming scenarios beyond embeddings.
Embedding Kernels: Coalesced vs Non-Coalesced
In this puzzle, you’ll implement two different GPU kernels for embedding operations that produce identical results but use different memory access patterns, demonstrating the critical importance of memory coalescing in GPU performance.
1D coalesced kernel (optimized approach)
This kernel uses a simple 1D grid where each thread processes exactly one output element. The key insight is that consecutive threads will access consecutive memory locations, leading to optimal memory coalescing.
Thread organization:
- Grid configuration:
[total_elements // 256]blocks,256threads per block - Thread mapping: Each thread handles one
(batch, seq, embed)position - Memory pattern: Consecutive threads access consecutive embedding dimensions
What you need to implement:
- Calculate the global thread index from block and thread indices
- Convert the flat index to 3D coordinates
(batch_idx, seq_idx, embed_idx) - Look up the token index from the indices tensor
- Copy the appropriate embedding vector element to the output
Code to complete
You need to complete the missing parts in both embedding kernels:
comptime THREADS_PER_BLOCK = 256
def embedding_kernel_coalesced[
batch_size: Int,
seq_len: Int,
vocab_size: Int,
embed_dim: Int,
OutLayout: TensorLayout,
IndicesLayout: TensorLayout,
WeightsLayout: TensorLayout,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
indices: TileTensor[mut=False, DType.int32, IndicesLayout, MutAnyOrigin],
weights: TileTensor[mut=False, dtype, WeightsLayout, MutAnyOrigin],
):
"""
Memory-coalescing focused embedding kernel.
Key insight: The bottleneck is memory access patterns, not computation.
- Each thread handles one (batch, seq, embed) position
- Simple 1D grid for maximum simplicity and correctness
- Focus on getting memory access right first
"""
# Simple 1D indexing - each thread = one output element
var global_idx = block_idx.x * block_dim.x + thread_idx.x
var total_elements = batch_size * seq_len * embed_dim
if global_idx >= total_elements:
return
# Convert to (batch, seq, embed) coordinates
# FILL IN roughly 4 lines
# Get token index
# FILL IN 1 line
# Simple, correct assignment
# FILL IN 4 lines
View full file: problems/p21/op/embedding.mojo
Tips
- Start with
global_idx = block_idx.x * block_dim.x + thread_idx.x - Convert to 3D coordinates using division and modulo:
batch_idx = global_idx // (seq_len * embed_dim) - Use
remaining = global_idx % (seq_len * embed_dim)to simplify further calculations - Always check bounds:
if global_idx >= total_elements: return - Handle invalid token indices by setting output to 0
- The embedding lookup is:
output[batch_idx, seq_idx, embed_idx] = weights[token_idx, embed_idx]
2D non-coalesced kernel (comparison approach)
This kernel uses a 2D grid where the X dimension spans (batch × seq) positions
and the Y dimension spans embedding dimensions. This can lead to non-coalesced
memory access patterns.
Thread organization:
- Grid configuration:
[batch x seq // 16, embed_dim // 16]blocks,16 x 16threads per block - Thread mapping:
thread_idx.xmaps to batch/sequence,thread_idx.ymaps to embedding dimension - Memory pattern: Threads in a warp may access scattered memory locations
What you need to implement:
- Calculate both X and Y coordinates from the 2D grid
- Convert the X coordinate to separate batch and sequence indices
- Use the Y coordinate directly as the embedding dimension
- Perform the same embedding lookup with bounds checking
Code to complete
You need to complete the missing parts in both embedding kernels:
def embedding_kernel_2d[
batch_size: Int,
seq_len: Int,
vocab_size: Int,
embed_dim: Int,
OutLayout: TensorLayout,
IndicesLayout: TensorLayout,
WeightsLayout: TensorLayout,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
indices: TileTensor[mut=False, DType.int32, IndicesLayout, MutAnyOrigin],
weights: TileTensor[mut=False, dtype, WeightsLayout, MutAnyOrigin],
):
"""
2D grid non-coalesced embedding kernel.
Non-optimal approach for comparison:
- 2D grid: (batch*seq, embed_dim)
- More complex indexing
- Potentially worse memory access patterns
"""
# 2D grid indexing
var batch_seq_idx = block_idx.x * block_dim.x + thread_idx.x
var embed_idx = block_idx.y * block_dim.y + thread_idx.y
var total_positions = batch_size * seq_len
if batch_seq_idx >= total_positions or embed_idx >= embed_dim:
return
# Convert to (batch, seq) coordinates
# FILL IN 2 lines
# Get token index
# FILL IN 1 line
# Assignment with 2D grid pattern
# FILL IN 4 lines
View full file: problems/p21/op/embedding.mojo
Tips
- Use both X and Y thread coordinates:
batch_seq_idx = block_idx.x * block_dim.x + thread_idx.x - And:
embed_idx = block_idx.y * block_dim.y + thread_idx.y - Convert
batch_seq_idxto separate batch and sequence indices:batch_idx = batch_seq_idx // seq_len - Remember to check bounds for both dimensions:
if batch_seq_idx >= total_positions or embed_idx >= embed_dim - The token lookup is the same as 1D, but you’re only handling one embedding dimension per thread
- This kernel processes one embedding dimension per thread instead of entire vectors
Custom ops registration
The kernels are wrapped in PyTorch custom operations for easy integration. The registration pattern is the same as MAX custom ops explained in Understanding MAX Graph custom ops:
1D coalesced operation
This operation registers the optimized 1D embedding kernel as "embedding":
import compiler
from std.runtime.asyncrt import DeviceContextPtr
from tensor import InputTensor, OutputTensor
from std.memory import UnsafePointer
from std.gpu.host import DeviceBuffer
@compiler.register("embedding")
struct EmbeddingCustomOp:
@staticmethod
def execute[
target: StaticString,
batch_size: Int,
seq_len: Int,
vocab_size: Int,
embed_dim: Int,
](
output: OutputTensor[
dtype=DType.float32, rank=3, static_spec=_
], # [batch_size, seq_len, embed_dim]
indices: InputTensor[
dtype=DType.int32, rank=2, static_spec=_
], # [batch_size, seq_len]
weights: InputTensor[
dtype=output.dtype, rank=2, static_spec=_
], # [vocab_size, embed_dim]
ctx: DeviceContextPtr,
) raises:
comptime out_layout_val = row_major[batch_size, seq_len, embed_dim]()
comptime OutLayout = type_of(out_layout_val)
comptime indices_layout_val = row_major[batch_size, seq_len]()
comptime IndicesLayout = type_of(indices_layout_val)
comptime weights_layout_val = row_major[vocab_size, embed_dim]()
comptime WeightsLayout = type_of(weights_layout_val)
var output_tensor = TileTensor[
mut=True, output.dtype, OutLayout, MutAnyOrigin
](output.unsafe_ptr(), out_layout_val)
var indices_tensor = TileTensor[
mut=True, DType.int32, IndicesLayout, MutAnyOrigin
](indices.unsafe_ptr(), indices_layout_val)
var weights_tensor = TileTensor[
mut=True, output.dtype, WeightsLayout, MutAnyOrigin
](weights.unsafe_ptr(), weights_layout_val)
comptime if target == "gpu":
var gpu_ctx = ctx.get_device_context()
# Zero out output tensor
gpu_ctx.enqueue_memset(
DeviceBuffer[output.dtype](
gpu_ctx,
output.unsafe_ptr(),
batch_size * seq_len * embed_dim,
owning=False,
),
0,
)
# Calculate 1D grid dimensions (matching kernel's flat indexing)
var total_elements = batch_size * seq_len * embed_dim
var blocks = max(1, ceildiv(total_elements, THREADS_PER_BLOCK))
# Compile and launch optimized kernel
comptime kernel = embedding_kernel_coalesced[
batch_size,
seq_len,
vocab_size,
embed_dim,
OutLayout,
IndicesLayout,
WeightsLayout,
output.dtype,
]
var compiled_kernel = gpu_ctx.compile_function[kernel, kernel]()
gpu_ctx.enqueue_function(
compiled_kernel,
output_tensor,
indices_tensor,
weights_tensor,
grid_dim=(blocks,),
block_dim=(THREADS_PER_BLOCK,),
)
elif target == "cpu":
for batch in range(batch_size):
for seq in range(seq_len):
var token_idx_val = Int(indices_tensor[batch, seq])
if token_idx_val >= 0 and token_idx_val < vocab_size:
for emb in range(embed_dim):
output_tensor[batch, seq, emb] = weights_tensor[
token_idx_val, emb
]
else:
raise Error("Unsupported target: " + target)
Key aspects of this registration:
- Simple grid configuration: Uses a straightforward 1D grid with
ceildiv(total_elements, THREADS_PER_BLOCK)blocks - Memory optimization: Single
enqueue_memsetcall to zero the output buffer efficiently - Compile-time parameters: All tensor dimensions passed as compile-time parameters for optimal performance
- Device abstraction: Handles both GPU execution and CPU fallback seamlessly
2D non-coalesced operation
This operation registers the comparison 2D embedding kernel as "embedding_2d":
@compiler.register("embedding_2d")
struct Embedding2DCustomOp:
@staticmethod
def execute[
target: StaticString,
batch_size: Int,
seq_len: Int,
vocab_size: Int,
embed_dim: Int,
](
output: OutputTensor[
dtype=DType.float32, rank=3, static_spec=_
], # [batch_size, seq_len, embed_dim]
indices: InputTensor[
dtype=DType.int32, rank=2, static_spec=_
], # [batch_size, seq_len]
weights: InputTensor[
dtype=output.dtype, rank=2, static_spec=_
], # [vocab_size, embed_dim]
ctx: DeviceContextPtr,
) raises:
comptime out_layout_val = row_major[batch_size, seq_len, embed_dim]()
comptime OutLayout = type_of(out_layout_val)
comptime indices_layout_val = row_major[batch_size, seq_len]()
comptime IndicesLayout = type_of(indices_layout_val)
comptime weights_layout_val = row_major[vocab_size, embed_dim]()
comptime WeightsLayout = type_of(weights_layout_val)
var output_tensor = TileTensor[
mut=True, output.dtype, OutLayout, MutAnyOrigin
](output.unsafe_ptr(), out_layout_val)
var indices_tensor = TileTensor[
mut=True, DType.int32, IndicesLayout, MutAnyOrigin
](indices.unsafe_ptr(), indices_layout_val)
var weights_tensor = TileTensor[
mut=True, output.dtype, WeightsLayout, MutAnyOrigin
](weights.unsafe_ptr(), weights_layout_val)
comptime if target == "gpu":
var gpu_ctx = ctx.get_device_context()
# Zero out output tensor
gpu_ctx.enqueue_memset(
DeviceBuffer[output.dtype](
gpu_ctx,
output.unsafe_ptr(),
batch_size * seq_len * embed_dim,
owning=False,
),
0,
)
# Calculate 2D grid dimensions for non-coalesced access
var total_positions = batch_size * seq_len
comptime BLOCK_X = 16 # batch*seq dimension
comptime BLOCK_Y = 16 # embed dimension
var blocks_x = max(1, ceildiv(total_positions, BLOCK_X))
var blocks_y = max(1, ceildiv(embed_dim, BLOCK_Y))
# Compile and launch 2D kernel
comptime kernel = embedding_kernel_2d[
batch_size,
seq_len,
vocab_size,
embed_dim,
OutLayout,
IndicesLayout,
WeightsLayout,
output.dtype,
]
var compiled_kernel = gpu_ctx.compile_function[kernel, kernel]()
gpu_ctx.enqueue_function(
compiled_kernel,
output_tensor,
indices_tensor,
weights_tensor,
grid_dim=(blocks_x, blocks_y),
block_dim=(BLOCK_X, BLOCK_Y),
)
elif target == "cpu":
# Same CPU fallback as 1D version
for batch in range(batch_size):
for seq in range(seq_len):
var token_idx_val = Int(indices_tensor[batch, seq])
if token_idx_val >= 0 and token_idx_val < vocab_size:
for emb in range(embed_dim):
output_tensor[batch, seq, emb] = weights_tensor[
token_idx_val, emb
]
else:
raise Error("Unsupported target: " + target)
Key differences from the 1D operation:
- Complex grid configuration: Uses a 2D grid with separate calculations for
blocks_xandblocks_y - Fixed block dimensions: Hard-coded
BLOCK_X = 16andBLOCK_Y = 16for 2D thread organization - Same memory management: Identical memory initialization and CPU fallback logic
- Different kernel call: Passes 2D grid dimensions
(blocks_x, blocks_y)and block dimensions(BLOCK_X, BLOCK_Y)
Common wrapper functionality
Both custom operations provide essential infrastructure:
-
Memory management:
- Zero-initialization of output tensors with
enqueue_memset - Proper buffer creation and memory layout handling
- Automatic cleanup and resource management
- Zero-initialization of output tensors with
-
Device abstraction:
- GPU execution with optimized kernels
- CPU fallback for compatibility and debugging
- Consistent interface regardless of execution target
-
Parameter passing:
- Compile-time tensor dimensions for kernel optimization
- Runtime tensor data through layout tensor conversion
- Type-safe parameter validation
-
Grid configuration:
- Automatic calculation of optimal grid dimensions
- Different strategies optimized for each kernel’s access pattern
- Proper block dimension management
Integration with PyTorch
These registered operations can be called from Python using the CustomOpLibrary:
# Load the custom operations
ops = CustomOpLibrary(mojo_kernels)
# Call the 1D coalesced version
result_1d = ops.embedding[{"batch_size": B, "seq_len": L, "vocab_size": V, "embed_dim": E}](
indices, weights
)
# Call the 2D non-coalesced version
result_2d = ops.embedding_2d[{"batch_size": B, "seq_len": L, "vocab_size": V, "embed_dim": E}](
indices, weights
)
The power of this approach is that the same kernel implementations can be used across different Python frameworks while maintaining optimal performance characteristics.
Run the code
You can run the puzzle with:
pixi run p21
pixi run -e amd p21
uv run poe p21
When successful, you should see output similar to:
Puzzle 21: Mojo Embedding Kernel Comparison
======================================================================
Configuration: B=8, L=512, V=10000, E=512
------------------------------------------------------------
Testing Correctness...
1D Coalesced - Max difference: 1.19e-07
2D Non-coalesced - Max difference: 1.19e-07
✅ Both implementations CORRECT
Benchmarking Mojo Kernels...
Performance Results:
1D Coalesced: 2.145 ms
2D Non-coalesced: 3.867 ms
1D is 1.80x faster than 2D
Key Learning Points:
• Compare different GPU kernel implementations
• 1D vs 2D grid patterns have different memory access
• Coalesced memory access should be faster
• Grid configuration affects GPU utilization
Solution
The solution involves implementing the coordinate transformations and memory operations for both kernels:
1D Coalesced Kernel
def embedding_kernel_coalesced[
batch_size: Int,
seq_len: Int,
vocab_size: Int,
embed_dim: Int,
OutLayout: TensorLayout,
IndicesLayout: TensorLayout,
WeightsLayout: TensorLayout,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
indices: TileTensor[mut=True, DType.int32, IndicesLayout, MutAnyOrigin],
weights: TileTensor[mut=True, dtype, WeightsLayout, MutAnyOrigin],
):
"""
Memory-coalescing focused embedding kernel.
Key insight: The bottleneck is memory access patterns, not computation.
- Each thread handles one (batch, seq, embed) position
- Simple 1D grid for maximum simplicity and correctness
- Focus on getting memory access right first
"""
# Simple 1D indexing - each thread = one output element
var global_idx = block_idx.x * block_dim.x + thread_idx.x
var total_elements = batch_size * seq_len * embed_dim
if global_idx >= total_elements:
return
var output_lt = output.to_layout_tensor()
var indices_lt = indices.to_layout_tensor()
var weights_lt = weights.to_layout_tensor()
# Convert to (batch, seq, embed) coordinates
var batch_idx = global_idx // (seq_len * embed_dim)
var remaining = global_idx % (seq_len * embed_dim)
var seq_idx = remaining // embed_dim
var embed_idx = remaining % embed_dim
# Get token index
var token_idx_val = Int(indices_lt[batch_idx, seq_idx])
# Simple, correct assignment
if token_idx_val >= 0 and token_idx_val < vocab_size:
output_lt[batch_idx, seq_idx, embed_idx] = weights_lt[
token_idx_val, embed_idx
]
else:
output_lt[batch_idx, seq_idx, embed_idx] = 0
2D Non-Coalesced Kernel
def embedding_kernel_2d[
batch_size: Int,
seq_len: Int,
vocab_size: Int,
embed_dim: Int,
OutLayout: TensorLayout,
IndicesLayout: TensorLayout,
WeightsLayout: TensorLayout,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
indices: TileTensor[mut=True, DType.int32, IndicesLayout, MutAnyOrigin],
weights: TileTensor[mut=True, dtype, WeightsLayout, MutAnyOrigin],
):
"""
2D grid non-coalesced embedding kernel.
Non-optimal approach for comparison:
- 2D grid: (batch*seq, embed_dim)
- More complex indexing
- Potentially worse memory access patterns
"""
# 2D grid indexing
var batch_seq_idx = block_idx.x * block_dim.x + thread_idx.x
var embed_idx = block_idx.y * block_dim.y + thread_idx.y
var total_positions = batch_size * seq_len
# Bounds check
if batch_seq_idx >= total_positions or embed_idx >= embed_dim:
return
var output_lt = output.to_layout_tensor()
var indices_lt = indices.to_layout_tensor()
var weights_lt = weights.to_layout_tensor()
# Convert to (batch, seq) coordinates
var batch_idx = batch_seq_idx // seq_len
var seq_idx = batch_seq_idx % seq_len
# Get token index
var token_idx_val = Int(indices_lt[batch_idx, seq_idx])
# Assignment with 2D grid pattern
if token_idx_val >= 0 and token_idx_val < vocab_size:
output_lt[batch_idx, seq_idx, embed_idx] = weights_lt[
token_idx_val, embed_idx
]
else:
output_lt[batch_idx, seq_idx, embed_idx] = 0
Both solutions implement the same embedding lookup logic but with different thread organizations:
Key differences
-
Thread mapping:
- 1D kernel: One thread per output element, simple flat indexing
- 2D kernel: 2D grid mapping to (batch×seq, embed_dim) coordinates
-
Memory access patterns:
- 1D kernel: Consecutive threads access consecutive embedding dimensions → coalesced
- 2D kernel: Thread access pattern depends on block configuration → potentially non-coalesced
-
Indexing complexity:
- 1D kernel: Single division/modulo chain to get 3D coordinates
- 2D kernel: Separate X/Y coordinate calculations
Performance implications
The 1D kernel typically performs better because:
- Memory coalescing: Consecutive threads access consecutive memory addresses
- Simple indexing: Lower computational overhead for coordinate calculations
- Better cache utilization: Predictable memory access patterns
The 2D kernel may perform worse due to:
- Scattered memory accesses: Threads within a warp may access different embedding vectors
- Complex grid configuration: 16×16 blocks may not align optimally with memory layout
- Warp divergence: Different threads may follow different execution paths
Key concepts
| Concept | 1D Coalesced | 2D Non-coalesced |
|---|---|---|
| Thread organization | 1D flat indexing | 2D grid (batch×seq, embed) |
| Memory access | Consecutive addresses | Potentially scattered |
| Grid configuration | Simple: [total_elements // 256] | Complex: [batch×seq // 16, embed // 16] |
| Performance | Optimized for memory bandwidth | Suboptimal memory pattern |
| Use case | Production kernels | Educational comparison |
The core lesson: memory coalescing can lead to 2-3x performance differences for memory-bound operations like embeddings.
Performance: Coalesced vs non-coalesced memory access
Understanding memory access patterns is crucial for GPU performance optimization. This section explains why coalesced memory access patterns typically outperform non-coalesced patterns, particularly for memory-bound operations like embedding lookups.
Memory coalescing basics
Memory coalescing occurs when consecutive threads in a warp access consecutive memory addresses. GPUs can combine these individual memory requests into fewer, larger memory transactions, dramatically improving bandwidth utilization.
Coalesced vs non-coalesced access
Coalesced (efficient):
- Thread 0 → Address 0x1000
- Thread 1 → Address 0x1004
- Thread 2 → Address 0x1008
- Thread 3 → Address 0x100C
- ...
Result: 1 memory transaction for entire warp (32 threads)
Non-coalesced (inefficient):
- Thread 0 → Address 0x1000
- Thread 1 → Address 0x2000
- Thread 2 → Address 0x3000
- Thread 3 → Address 0x4000
- ...
Result: Up to 32 separate memory transactions
Why embedding operations are memory-bound
Embedding lookups are memory-bound because they involve:
- Minimal computation: Just copying data from input to output
- Large memory footprint: Embedding tables can be gigabytes in size
- High memory bandwidth requirements: Need to transfer large amounts of data
For such operations, memory access efficiency determines performance more than computational complexity.
Kernel comparison
1D coalesced kernel
- Thread organization:
[total_elements // 256]blocks, one thread per output element - Memory pattern: Consecutive threads access consecutive embedding dimensions
- Why it’s coalesced:
Thread 0: output[0,0,0],Thread 1: output[0,0,1]→ consecutive addresses
2D non-coalesced kernel
- Thread organization:
[batch*seq // 16, embed_dim // 16]blocks with 16×16 threads - Memory pattern: Threads may access different embedding vectors
- Why it’s non-coalesced: Thread access pattern can be scattered across memory
Performance results
Typical benchmark results:
Performance Results:
1D Coalesced: 2.145 ms
2D Non-coalesced: 3.867 ms
1D is 1.80x faster than 2D
Memory access visualization
Coalesced pattern (1D kernel)
Warp execution for output[0,0,0:32]:
| Element | Thread ID | Memory Access | Address Pattern |
|---|---|---|---|
output[0,0,0] | 0 | [0,0] | Base + 0 |
output[0,0,1] | 1 | [0,1] | Base + 4 |
output[0,0,2] | 2 | [0,2] | Base + 8 |
output[0,0,3] | 3 | [0,3] | Base + 12 |
| … | … | … | … |
output[0,0,31] | 31 | [0,31] | Base + 124 |
Result: Consecutive addresses → 1 memory transaction for entire warp
Non-coalesced pattern (2D kernel)
Warp execution with 16×16 blocks:
Block organization (16×16):
X-dim: batch*seq positions (0-15)
Y-dim: embed dimensions (0-15)
Warp threads might access:
Thread 0: batch=0, seq=0, embed=0 → Address A
Thread 1: batch=0, seq=1, embed=0 → Address B (different row)
Thread 2: batch=0, seq=2, embed=0 → Address C (different row)
...
Thread 31: batch=1, seq=15, embed=0 → Address Z (scattered)
Result: Potentially scattered addresses → Multiple memory transactions
Key optimization strategies
- Prefer 1D indexing for memory-bound operations when possible
- Align data structures to coalescing-friendly layouts
- Consider memory access patterns during kernel design
- Profile memory bandwidth to identify bottlenecks
- Use memory-bound benchmarks to validate optimizations
The core insight: memory access patterns often determine GPU performance more than computational complexity, especially for memory-bound operations like embeddings.
Puzzle 22: Kernel Fusion and Custom Backward Pass
Kernel fusion and autograd integration
We’re continuing Part IV with a focus on kernel fusion and autograd integration.
Building on Puzzle 21, you’ll now explore how to combine multiple operations into a single efficient kernel and integrate it with PyTorch’s autograd system. You’ll learn:
- How kernel fusion improves performance in both forward and backward passes
- Why custom backward passes are crucial for fused operations
- How to design fused kernels with proper gradient flow
- The performance implications of different fusion strategies
This puzzle demonstrates that how you combine operations can be as important as how you implement them.
Overview
In this puzzle, you’ll implement fused LayerNorm + Linear operations with both forward and backward passes. While both fused and unfused implementations produce identical results, they use different strategies that lead to significant performance differences.
You’ll compare:
- Unfused approach: Separate kernels for LayerNorm and Linear
- Fused kernel: Combined operation in a single kernel
- Custom backward pass: Gradient computation for fused operations
This comparison teaches the critical importance of kernel fusion and proper gradient computation in deep learning operations.
Background: LayerNorm + Linear operations
LayerNorm and Linear are fundamental operations in transformer architectures, particularly in attention mechanisms and feed-forward networks. Here’s how they’re typically used:
import torch
import torch.nn.functional as F
# Input: hidden states
x = torch.randn(batch_size, seq_len, hidden_dim)
# LayerNorm parameters
ln_weight = torch.ones(hidden_dim) # scale parameter (γ)
ln_bias = torch.zeros(hidden_dim) # shift parameter (β)
# Linear layer parameters
linear_weight = torch.randn(output_dim, hidden_dim)
linear_bias = torch.zeros(output_dim)
# Unfused operations (with autograd)
ln_output = F.layer_norm(x, [hidden_dim], weight=ln_weight, bias=ln_bias)
output = F.linear(ln_output, linear_weight, linear_bias)
# Fused operation (custom implementation)
# This is what you'll implement in this puzzle
output_fused = fused_layernorm_linear(x, ln_weight, ln_bias, linear_weight, linear_bias)
When fused, these operations are combined into a single efficient kernel that:
- Reduces memory bandwidth usage
- Minimizes kernel launch overhead
- Improves cache utilization
- Eliminates intermediate allocations
In practice, this fusion can provide up to 1.5-2x speedup in both forward and backward passes, which is crucial for transformer training efficiency.
Why custom backward passes matter
PyTorch’s autograd system automatically computes gradients for individual operations, but fused operations require custom backward passes to:
- Maintain numerical stability
- Ensure proper gradient flow
- Optimize memory access patterns
- Handle atomic operations for gradient accumulation
Learning path
This puzzle is structured in two parts to build your understanding systematically:
Forward pass implementation
Start here to implement the fused forward kernel and understand kernel fusion benefits.
What you’ll do:
- Implement both unfused and fused forward kernels
- Learn fundamental kernel fusion techniques
- See the same operations implemented with different strategies
- Understand performance implications of fusion
- Learn memory access patterns for optimal performance
Backward pass implementation
Deep dive into autograd integration and gradient computation.
What you’ll learn:
- How to implement custom backward passes
- Why proper gradient flow is crucial
- Real-world implications for training efficiency
- Optimization strategies for backward operations
- Mathematical foundations of gradient computation
- Atomic operations for gradient accumulation
- Numerical stability in backward passes
Getting started
Ready to explore kernel fusion and autograd integration? Start with the Forward pass implementation to implement the fused kernel, then move to Backward pass implementation to understand gradient computation.
The puzzle includes a comprehensive testing framework that verifies:
- Numerical correctness against PyTorch’s implementation for both forward and backward passes
- Performance comparison between our CPU and GPU implementations
- Gradient computation accuracy for all parameters (input, LayerNorm weights/bias, Linear weights/bias)
- Memory usage optimization through kernel fusion
💡 Success tip: Pay attention to how the different implementations (fused vs unfused) affect both forward and backward pass performance - this insight applies to many deep learning operations beyond LayerNorm + Linear. The backward pass implementation is particularly important as it directly impacts training efficiency and numerical stability.
⚛️ Fused vs Unfused Kernels
Overview
In this puzzle, we explore the performance benefits of kernel fusion by implementing and comparing two approaches to the LayerNorm and Linear operation:
- Unfused approach: Executes LayerNorm and Linear as separate operations
- Fused kernel: Combines LayerNorm and Linear operations into a single GPU kernel
This comparison demonstrates how kernel fusion can significantly improve performance by:
- Reducing memory bandwidth usage
- Minimizing kernel launch overhead
- Improving cache utilization
- Eliminating intermediate memory allocations
Key concepts
In this puzzle, you’ll learn:
- Kernel fusion techniques for combining multiple operations
- Memory bandwidth optimization through fused operations
- Performance benchmarking of different kernel implementations
- Numerical stability in fused operations
- PyTorch custom operation integration
The mathematical operations we’re fusing are:
-
LayerNorm: \[\Large \text{LayerNorm}(x) = \gamma \odot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta \]
-
Linear: \[\Large \text{Linear}(x) = Wx + b \]
When fused, we compute: \[\Large \text{Fused}(x) = W(\gamma \odot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta) + b \]
Understanding LayerNorm
LayerNorm is a normalization technique that helps stabilize and accelerate the training of deep neural networks. Let’s break down its components and parameters:
What LayerNorm does
-
Normalization: LayerNorm normalizes the activations across the features (hidden dimensions) for each sample independently. This means:
- For each sequence position, it computes statistics across the hidden dimension
- Each sample in the batch is normalized independently
- This is different from BatchNorm, which normalizes across the batch dimension
-
Parameters:
- \(\gamma\) (scale): A learnable parameter vector that allows the network to learn the optimal scale for each feature
- \(\beta\) (shift): A learnable parameter vector that allows the network to learn the optimal shift for each feature
- \(\epsilon\): A small constant (1e-5) added to the variance to prevent division by zero
What LayerNorm does in practice
LayerNorm performs several crucial functions in deep neural networks:
-
Feature standardization:
- Transforms each feature to have zero mean and unit variance
- Makes the network’s learning process more stable
- Helps prevent the “internal covariate shift” problem where the distribution of layer inputs changes during training
-
Gradient flow:
- Improves gradient flow through the network
- Prevents vanishing/exploding gradients
- Makes training more efficient by allowing higher learning rates
-
Regularization effect:
- Acts as a form of implicit regularization
- Helps prevent overfitting by normalizing the feature distributions
- Makes the network more robust to input variations
-
Sequence modeling:
- Particularly effective in transformer architectures
- Helps maintain consistent signal magnitude across different sequence lengths
- Enables better handling of variable-length sequences
-
Training dynamics:
- Accelerates training convergence
- Reduces the need for careful learning rate tuning
- Makes the network less sensitive to weight initialization
Mathematical components
-
Mean Calculation (\(\mu\)): \[\Large \mu = \frac{1}{H} \sum_{i=1}^{H} x_i \]
- Computes the mean across the hidden dimension (H)
- Each sequence position has its own mean
-
Variance Calculation (\(\sigma^2\)): \[\Large \sigma^2 = \frac{1}{H} \sum_{i=1}^{H} (x_i - \mu)^2 \]
- Computes the variance across the hidden dimension
- Used to scale the normalized values
-
Normalization and Scaling: \[\Large \text{LayerNorm}(x) = \gamma \odot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta \]
- First normalizes the input to have zero mean and unit variance
- Then applies learnable scale (\(\gamma\)) and shift (\(\beta\)) parameters
- The \(\odot\) symbol represents elementwise multiplication (Hadamard product)
- For example, if \(\gamma = [1.2, 0.8, 1.5]\) and normalized input is \([0.5, -0.3, 0.7]\), then \(\gamma \odot x = [0.6, -0.24, 1.05]\)
Why LayerNorm is important
-
Training Stability:
- Prevents activations from growing too large or small
- Helps maintain consistent signal magnitude throughout the network
-
Feature Learning:
- The scale (\(\gamma\)) and shift (\(\beta\)) parameters allow the network to learn which features are important
- Can effectively learn to ignore or emphasize certain features
-
Independence:
- Unlike BatchNorm, LayerNorm’s statistics are computed independently for each sample
- Makes it more suitable for variable-length sequences and small batch sizes
Configuration
- Batch size:
BATCH_SIZE = 4 - Sequence length:
SEQ_LEN = 4 - Hidden dimension:
HIDDEN_DIM = 8 - Output dimension:
OUTPUT_DIM = 16 - Epsilon:
EPS = 1e-5 - Data type:
DType.float32
Implementation approaches
1. Unfused implementation
The unfused approach executes operations separately using multiple kernels. Here are some of the kernels we wrote in the previous chapters:
Matrix multiplication kernel
From Puzzle 16, we reuse the tiled matrix multiplication kernel for the linear transformation. This kernel includes bounds checking to handle variable matrix dimensions safely:
# Idiomatic tiled matmul from p19.mojo
def matmul_idiomatic_tiled[
rows: Int,
cols: Int,
inner: Int,
OutLayout: TensorLayout,
ALayout: TensorLayout,
BLayout: TensorLayout,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, ALayout, MutAnyOrigin],
b: TileTensor[mut=False, dtype, BLayout, MutAnyOrigin],
):
"""Idiomatic tiled matrix multiplication from p19."""
var local_row = thread_idx.y
var local_col = thread_idx.x
var tiled_row = block_idx.y * MATMUL_BLOCK_DIM_XY + local_row
var tiled_col = block_idx.x * MATMUL_BLOCK_DIM_XY + local_col
# Get the tile of the output matrix that this thread block is responsible for
var out_tile = output.tile[MATMUL_BLOCK_DIM_XY, MATMUL_BLOCK_DIM_XY](
block_idx.y, block_idx.x
)
comptime shared_layout = row_major[
MATMUL_BLOCK_DIM_XY, MATMUL_BLOCK_DIM_XY
]()
var a_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](shared_layout)
var b_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](shared_layout)
var acc: output.ElementType = 0
comptime load_a_layout = row_major[
MATMUL_BLOCK_DIM_XY, MATMUL_BLOCK_DIM_XY
]() # Coalesced loading
comptime load_b_layout = row_major[
MATMUL_BLOCK_DIM_XY, MATMUL_BLOCK_DIM_XY
]() # Coalesced loading
comptime for idx in range(
(inner + MATMUL_BLOCK_DIM_XY - 1) // MATMUL_BLOCK_DIM_XY
):
# Get tiles from A and B matrices
var a_tile = a.tile[MATMUL_BLOCK_DIM_XY, MATMUL_BLOCK_DIM_XY](
block_idx.y, idx
)
var b_tile = b.tile[MATMUL_BLOCK_DIM_XY, MATMUL_BLOCK_DIM_XY](
idx, block_idx.x
)
# Asynchronously copy tiles to shared memory with consistent orientation
copy_dram_to_sram_async[
thread_layout=load_a_layout,
num_threads=MATMUL_NUM_THREADS,
block_dim_count=MATMUL_BLOCK_DIM_COUNT,
](a_shared, a_tile)
copy_dram_to_sram_async[
thread_layout=load_b_layout,
num_threads=MATMUL_NUM_THREADS,
block_dim_count=MATMUL_BLOCK_DIM_COUNT,
](b_shared, b_tile)
# Wait for all async copies to complete
async_copy_wait_all()
barrier()
# Compute partial matrix multiplication for this tile
comptime for k in range(MATMUL_BLOCK_DIM_XY):
if (
tiled_row < rows and tiled_col < cols
): # Only perform calculation for valid outputs
if k < a_tile.dim(
1
): # Only perform calculation on valid inputs
acc += a_shared[local_row, k] * b_shared[k, local_col]
barrier()
# Write final result with bounds checking (needed for variable matrix sizes)
if tiled_row < rows and tiled_col < cols:
out_tile[local_row, local_col] = acc
Transpose kernel
For efficient memory access patterns, we use a transpose kernel with shared memory tiling:
def transpose_kernel[
rows: Int,
cols: Int,
OutLayout: TensorLayout,
InLayout: TensorLayout,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
inp: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
):
"""Transpose matrix using shared memory tiling for coalesced access.
We will learn more about coalesced access in the next part.
"""
comptime shared_layout = row_major[
TRANSPOSE_BLOCK_DIM_XY, TRANSPOSE_BLOCK_DIM_XY
]()
var shared_tile = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](shared_layout)
var local_row = thread_idx.y
var local_col = thread_idx.x
var global_row = block_idx.y * TRANSPOSE_BLOCK_DIM_XY + local_row
var global_col = block_idx.x * TRANSPOSE_BLOCK_DIM_XY + local_col
if global_row < rows and global_col < cols:
shared_tile[local_row, local_col] = inp[global_row, global_col]
barrier()
var out_row = block_idx.x * TRANSPOSE_BLOCK_DIM_XY + local_row
var out_col = block_idx.y * TRANSPOSE_BLOCK_DIM_XY + local_col
# Store data from shared memory to global memory (coalesced write)
# Note: we transpose the shared memory access pattern
if out_row < cols and out_col < rows:
output[out_row, out_col] = shared_tile[local_col, local_row]
Bias addition kernel
A simple elementwise addition kernel for adding the bias term:
def add_bias_kernel[
batch_size: Int,
seq_len: Int,
output_dim: Int,
OutputLayout: TensorLayout,
InputLayout: TensorLayout,
BiasLayout: TensorLayout,
](
output: TileTensor[mut=True, dtype, OutputLayout, MutAnyOrigin],
input: TileTensor[mut=False, dtype, InputLayout, MutAnyOrigin],
bias: TileTensor[mut=False, dtype, BiasLayout, ImmutAnyOrigin],
):
"""Simple bias addition."""
var batch_idx = block_idx.x
var seq_idx = block_idx.y
var out_idx = thread_idx.x
if batch_idx >= batch_size or seq_idx >= seq_len or out_idx >= output_dim:
return
output[batch_idx, seq_idx, out_idx] = input[
batch_idx, seq_idx, out_idx
] + rebind[Scalar[dtype]](bias[out_idx])
LayerNorm kernel
Now complete this kernel to implement the LayerNorm operation. You’ll need to:
- Compute mean \(\mu\) and variance \(\sigma^2\) for each sequence position
- Normalize the input using these statistics
- Apply the scale \(\gamma\) and shift \(\beta\) parameters
def layernorm_kernel[
batch_size: Int,
seq_len: Int,
hidden_dim: Int,
OutputLayout: TensorLayout,
InputLayout: TensorLayout,
LnParamsLayout: TensorLayout,
](
output: TileTensor[mut=True, dtype, OutputLayout, MutAnyOrigin],
input: TileTensor[mut=False, dtype, InputLayout, ImmutAnyOrigin],
ln_weight: TileTensor[mut=False, dtype, LnParamsLayout, ImmutAnyOrigin],
ln_bias: TileTensor[mut=False, dtype, LnParamsLayout, ImmutAnyOrigin],
):
var batch_idx = block_idx.x
var seq_idx = block_idx.y
var hidden_idx = thread_idx.x
if (
batch_idx >= batch_size
or seq_idx >= seq_len
or hidden_idx >= hidden_dim
):
return
# Compute statistics for this sequence position (redundant but simple)
var sum_val: Scalar[dtype] = 0
var sq_sum: Scalar[dtype] = 0
# FILL ME IN (roughly 11 lines)
Implementation steps:
- First, compute mean and variance using parallel reduction
- Then normalize the input using these statistics
- Finally, apply the scale and shift parameters
Characteristics of unfused approach:
- Multiple kernel launches (LayerNorm → MatMul → Bias)
- Intermediate tensor allocations between operations
- More memory bandwidth usage due to separate passes
- Simpler implementation with clear separation of concerns
- Easier to debug as each operation is isolated
Tips
-
Thread organization:
- Use one thread block per sequence position (grid:
[batch_size, seq_len]) - Each thread handles one hidden dimension element
- Avoid redundant computation by computing statistics once per sequence
- Use one thread block per sequence position (grid:
-
Memory access:
- Access input tensor with
[batch_idx, seq_idx, hidden_idx] - Access output tensor with
[batch_idx, seq_idx, hidden_idx] - Access LayerNorm parameters with
[hidden_idx]
- Access input tensor with
-
Numerical stability:
- Add epsilon (1e-5) before taking square root
- Use
rebind[Scalar[dtype]]for proper type casting - Compute variance as (sq_sum / hidden_dim) - (mean * mean)
-
Performance:
- Compute mean and variance in a single pass
- Reuse computed statistics for all elements in sequence
- Avoid unnecessary memory barriers
Running the code
To test your unfused implementation, run:
pixi run p22 --unfused
pixi run -e amd p22 --unfused
uv run poe p22 --unfused
Your output will look like this:
Testing with dimensions: [4, 4, 8] -> [4, 4, 16]
✅ Loaded Mojo operations library
============================================================
Puzzle 22: UNFUSED Algorithm Test & Benchmark
============================================================
🧪 Correctness Testing for UNFUSED Algorithm
====================================================
Testing Reference PyTorch Implementation
-----------------------------------------------
✅ Reference PyTorch
Max difference: 0.00e+00
Result: ✅ CORRECT
Testing CPU Implementation
---------------------------------
✅ Using Mojo fused kernel (CPU)
Max difference: 1.86e-08
Result: ✅ CORRECT
Testing GPU Unfused Implementation
-----------------------------------------
✅ Using Mojo unfused kernel (GPU)
Max difference: 1.86e-08
Result: ✅ CORRECT
Correctness Summary:
- Reference: ✅ CORRECT
- CPU: ✅ CORRECT
- GPU unfused: ✅ CORRECT
Overall Correctness: ✅ ALL CORRECT
Benchmarking CPU vs GPU UNFUSED
------------------------------------------
Testing CPU performance...
CPU: 3173.70ms (50 iterations)
Testing GPU unfused performance...
GPU unfused: 3183.57ms (50 iterations)
GPU unfused vs CPU: 1.00x slower
CPU wins (GPU overhead > computation benefit)
UNFUSED Algorithm Test Completed!
Solution
def layernorm_kernel[
batch_size: Int,
seq_len: Int,
hidden_dim: Int,
OutputLayout: TensorLayout,
InputLayout: TensorLayout,
LnParamsLayout: TensorLayout,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, OutputLayout, MutAnyOrigin],
input: TileTensor[mut=True, dtype, InputLayout, MutAnyOrigin],
ln_weight: TileTensor[mut=True, dtype, LnParamsLayout, MutAnyOrigin],
ln_bias: TileTensor[mut=True, dtype, LnParamsLayout, MutAnyOrigin],
):
var batch_idx = block_idx.x
var seq_idx = block_idx.y
var hidden_idx = thread_idx.x
if (
batch_idx >= batch_size
or seq_idx >= seq_len
or hidden_idx >= hidden_dim
):
return
var output_lt = output.to_layout_tensor()
var input_lt = input.to_layout_tensor()
var ln_weight_lt = ln_weight.to_layout_tensor()
var ln_bias_lt = ln_bias.to_layout_tensor()
# Compute statistics for this sequence position (redundant but simple)
var sum_val: Scalar[dtype] = 0
var sq_sum: Scalar[dtype] = 0
comptime for h in range(hidden_dim):
var val = input_lt[batch_idx, seq_idx, h]
sum_val += rebind[Scalar[dtype]](val)
sq_sum += rebind[Scalar[dtype]](val * val)
var mean_val = sum_val / hidden_dim
var var_val = (sq_sum / hidden_dim) - (mean_val * mean_val)
var inv_std = 1.0 / sqrt(var_val + 1e-5)
# Apply LayerNorm to this element
var input_val = input_lt[batch_idx, seq_idx, hidden_idx]
var normalized = (input_val - mean_val) * inv_std * rebind[Scalar[dtype]](
ln_weight_lt[hidden_idx]
) + rebind[Scalar[dtype]](ln_bias_lt[hidden_idx])
output_lt[batch_idx, seq_idx, hidden_idx] = normalized
The unfused implementation follows a straightforward approach where each thread handles one element of the output tensor. Let’s break down the key components:
-
Thread and Block Organization:
batch_idx = block_idx.x seq_idx = block_idx.y hidden_idx = thread_idx.x-
Each thread block handles one sequence position in the batch
-
Grid dimensions:
[batch_size, seq_len] -
Each thread processes one element in the hidden dimension
-
Early return if indices are out of bounds:
if (batch_idx >= batch_size or seq_idx >= seq_len or hidden_idx >= hidden_dim): return
-
-
Statistics Computation:
var sum_val: Scalar[dtype] = 0 var sq_sum: Scalar[dtype] = 0 @parameter for h in range(hidden_dim): val = input[batch_idx, seq_idx, h] sum_val += rebind[Scalar[dtype]](val) sq_sum += rebind[Scalar[dtype]](val * val)-
Compute sum and squared sum in a single pass
-
Use
@parameterfor compile-time loop unrolling -
Proper type casting with
rebind[Scalar[dtype]] -
Calculate mean and variance:
mean_val = sum_val / hidden_dim var_val = (sq_sum / hidden_dim) - (mean_val * mean_val) inv_std = 1.0 / sqrt(var_val + 1e-5)
-
-
Normalization and Scaling:
input_val = input[batch_idx, seq_idx, hidden_idx] normalized = (input_val - mean_val) * inv_std * rebind[Scalar[dtype]]( ln_weight[hidden_idx] ) + rebind[Scalar[dtype]](ln_bias[hidden_idx]) output[batch_idx, seq_idx, hidden_idx] = normalized- Apply normalization: \[\Large \text{normalized} = \gamma \odot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta \]
- Scale with learnable parameter
γ(ln_weight) - Add learnable bias
β(ln_bias) - Store result in output tensor
-
Performance Characteristics:
- Each thread computes statistics independently
- No shared memory usage (simple but less efficient)
- Memory access pattern:
- Input:
[batch_idx, seq_idx, h] - Output:
[batch_idx, seq_idx, hidden_idx] - Parameters:
[hidden_idx]
- Input:
- Numerical stability ensured by:
- Adding epsilon (1e-5) before square root
- Using proper type casting
- Computing variance in a numerically stable way
-
Implementation Details:
-
Type Safety:
- Use
Scalar[dtype]for intermediate calculations rebind[Scalar[dtype]]for proper type casting- Ensures consistent floating-point precision
- Use
-
Memory Access:
- Coalesced reads from input tensor
- Coalesced writes to output tensor
- Sequential access to LayerNorm parameters
-
Computation Flow:
- Statistics computation: \[\Large O(H) \text{ operations per thread} \]
- Normalization: \[\Large O(1) \text{ operations per thread} \]
- Total complexity: \[\Large O(H) \text{ per output element} \]
-
Limitations:
- Redundant computation of statistics
- No shared memory for intermediate results
- High memory bandwidth usage
- Multiple kernel launches required
-
This implementation is correct but not optimal for performance, as shown in the benchmark results where it’s slightly slower than the CPU version. The fused implementation will address these performance limitations by:
- Computing statistics once per sequence
- Reusing normalized values
- Reducing memory traffic
- Eliminating intermediate tensor allocations
2. Fused kernel implementation
The fused kernel combines LayerNorm and Linear operations into a single GPU kernel:
def minimal_fused_kernel[
batch_size: Int,
seq_len: Int,
hidden_dim: Int,
output_dim: Int,
OutputLayout: TensorLayout,
InputLayout: TensorLayout,
LnParamsLayout: TensorLayout,
WeightLayout: TensorLayout,
BiasLayout: TensorLayout,
](
output: TileTensor[mut=True, dtype, OutputLayout, MutAnyOrigin],
input: TileTensor[mut=False, dtype, InputLayout, ImmutAnyOrigin],
ln_weight: TileTensor[mut=False, dtype, LnParamsLayout, ImmutAnyOrigin],
ln_bias: TileTensor[mut=False, dtype, LnParamsLayout, ImmutAnyOrigin],
linear_weight: TileTensor[mut=False, dtype, WeightLayout, ImmutAnyOrigin],
linear_bias: TileTensor[mut=False, dtype, BiasLayout, ImmutAnyOrigin],
):
"""Minimal fused kernel - one thread per sequence position to avoid redundancy.
"""
# Grid: (batch_size, seq_len) - one thread block per sequence position
# Block: (1,) - single thread per sequence position to avoid redundant computation
var batch_idx = block_idx.x
var seq_idx = block_idx.y
if batch_idx >= batch_size or seq_idx >= seq_len:
return
# Step 1: Compute LayerNorm statistics once per sequence position
# FILL IN roughly 10 lines
# Step 2: Compute all outputs for this sequence position
# FILL IN roughly 10 lines
Key optimizations:
- Single kernel launch instead of two
- Shared memory for intermediate results
- Coalesced memory access patterns
- Reduced memory bandwidth usage
- No intermediate tensor allocations
Tips
-
Thread organization:
- One thread block per sequence position (grid:
[batch_size, seq_len]) - Single thread per sequence position to avoid redundancy
- Compute all outputs for each sequence position in one thread
- One thread block per sequence position (grid:
-
Memory access:
- Access input tensor with
[batch_idx, seq_idx, h] - Access output tensor with
[batch_idx, seq_idx, out_idx] - Access weights with
[out_idx, h]for linear layer
- Access input tensor with
-
Computation flow:
- Compute LayerNorm statistics once per sequence
- Reuse normalized values for all output dimensions
- Combine normalization and linear transformation
-
Performance:
- Avoid redundant computation of statistics
- Minimize memory traffic by fusing operations
- Use proper type casting with
rebind[Scalar[dtype]]
Running the code
To test your fused implementation, run:
pixi run p22 --fused
pixi run -e amd p22 --fused
uv run poe p22 --fused
Your output will look like this:
Testing with dimensions: [4, 4, 8] -> [4, 4, 16]
✅ Loaded Mojo operations library
============================================================
Puzzle 22: FUSED Algorithm Test & Benchmark
============================================================
🧪 Correctness Testing for FUSED Algorithm
==================================================
Testing Reference PyTorch Implementation
-----------------------------------------------
✅ Reference PyTorch
Max difference: 0.00e+00
Result: ✅ CORRECT
Testing CPU Implementation
---------------------------------
✅ Using Mojo fused kernel (CPU)
Max difference: 1.86e-08
Result: ✅ CORRECT
Testing GPU Fused Implementation
---------------------------------------
✅ Using Mojo fused kernel (GPU)
Max difference: 1.86e-08
Result: ✅ CORRECT
Correctness Summary:
- Reference: ✅ CORRECT
- CPU: ✅ CORRECT
- GPU fused: ✅ CORRECT
Overall Correctness: ✅ ALL CORRECT
⚡ Benchmarking CPU vs GPU FUSED
----------------------------------------
Testing CPU performance...
CPU: 3144.75ms (50 iterations)
Testing GPU fused performance...
GPU fused: 3116.11ms (50 iterations)
GPU fused vs CPU: 1.01x faster
GPU fused wins!
FUSED Algorithm Test Completed!
Solution
def minimal_fused_kernel[
batch_size: Int,
seq_len: Int,
hidden_dim: Int,
output_dim: Int,
OutputLayout: TensorLayout,
InputLayout: TensorLayout,
LnParamsLayout: TensorLayout,
WeightLayout: TensorLayout,
BiasLayout: TensorLayout,
dtype: DType = DType.float32,
](
output: TileTensor[mut=True, dtype, OutputLayout, MutAnyOrigin],
input: TileTensor[mut=True, dtype, InputLayout, MutAnyOrigin],
ln_weight: TileTensor[mut=True, dtype, LnParamsLayout, MutAnyOrigin],
ln_bias: TileTensor[mut=True, dtype, LnParamsLayout, MutAnyOrigin],
linear_weight: TileTensor[mut=True, dtype, WeightLayout, MutAnyOrigin],
linear_bias: TileTensor[mut=True, dtype, BiasLayout, MutAnyOrigin],
):
"""Minimal fused kernel - one thread per sequence position to avoid redundancy.
"""
# Grid: (batch_size, seq_len) - one thread block per sequence position
# Block: (1,) - single thread per sequence position to avoid redundant computation
var batch_idx = block_idx.x
var seq_idx = block_idx.y
if batch_idx >= batch_size or seq_idx >= seq_len:
return
var output_lt = output.to_layout_tensor()
var input_lt = input.to_layout_tensor()
var ln_weight_lt = ln_weight.to_layout_tensor()
var ln_bias_lt = ln_bias.to_layout_tensor()
var linear_weight_lt = linear_weight.to_layout_tensor()
var linear_bias_lt = linear_bias.to_layout_tensor()
# Step 1: Compute LayerNorm statistics once per sequence position
var sum_val: Scalar[dtype] = 0
var sq_sum: Scalar[dtype] = 0
comptime for h in range(hidden_dim):
var val = input_lt[batch_idx, seq_idx, h]
sum_val += rebind[Scalar[dtype]](val)
sq_sum += rebind[Scalar[dtype]](val * val)
var mean_val = sum_val / hidden_dim
var var_val = (sq_sum / hidden_dim) - (mean_val * mean_val)
var inv_std = 1.0 / sqrt(var_val + 1e-5)
# Step 2: Compute all outputs for this sequence position
comptime for out_idx in range(output_dim):
var acc: Scalar[dtype] = 0
comptime for h in range(hidden_dim):
var input_val = input_lt[batch_idx, seq_idx, h]
var normalized = (input_val - mean_val) * inv_std * rebind[
Scalar[dtype]
](ln_weight_lt[h]) + rebind[Scalar[dtype]](ln_bias_lt[h])
acc += rebind[Scalar[dtype]](
normalized * linear_weight_lt[out_idx, h]
)
output_lt[batch_idx, seq_idx, out_idx] = acc + rebind[Scalar[dtype]](
linear_bias_lt[out_idx]
)
The fused implementation combines operations efficiently:
-
Thread organization:
- One thread block per sequence position (grid:
[batch_size, seq_len]) - Single thread per sequence position
- Thread indices:
batch_idx = block_idx.x,seq_idx = block_idx.y
- One thread block per sequence position (grid:
-
LayerNorm phase:
- Compute sum and squared sum for the sequence position
- Calculate mean: \[\Large \mu = \frac{1}{H} \sum_{i=1}^{H} x_i \]
- Calculate variance: \[\Large \sigma^2 = \frac{1}{H} \sum_{i=1}^{H} (x_i - \mu)^2 \]
- Compute inverse standard deviation: \[\Large \text{inv_std} = \frac{1}{\sqrt{\sigma^2 + \epsilon}} \]
-
Linear phase:
- For each output dimension:
- Compute normalized value: \[\Large \text{normalized} = \gamma \odot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta \]
- Multiply with linear weight and accumulate: \[\Large \text{acc} = \sum_{h=1}^{H} \text{normalized}h \cdot W{out,h} \]
- Add linear bias: \[\Large \text{output} = \text{acc} + b_{out} \]
- Store result in
output[batch_idx, seq_idx, out_idx]
- For each output dimension:
-
Performance optimizations:
- Single kernel launch for both operations
- Reuse computed statistics
- Minimize memory traffic
- No intermediate tensor allocations
- Efficient memory access patterns
This implementation achieves better performance than the unfused version by reducing memory bandwidth usage and kernel launch overhead.
Advantages of kernel fusion
In this puzzle, we’ve explored two approaches to implementing LayerNorm + Linear operations:
-
Unfused implementation:
- Separate kernels for LayerNorm and Linear
- Simpler implementation but less efficient
- Higher memory bandwidth usage
- Multiple kernel launches
- Benchmark results: 3183.57ms (GPU)
-
Fused implementation:
- Single kernel combining both operations
- More complex but significantly more efficient
- Reduced memory bandwidth usage
- Single kernel launch
- Benchmark results: 3116.11ms (GPU)
Memory bandwidth optimization
-
Eliminated memory traffic:
- No intermediate tensor allocations between operations
- Reduced global memory reads/writes
- Reuse of normalized values for linear transformation
- Memory bandwidth reduction: \[\Large \text{reduction} = \frac{\text{unfused_bandwidth} - \text{fused_bandwidth}}{\text{unfused_bandwidth}}\]
-
Cache efficiency:
- Better L1/L2 cache utilization
- Reduced cache misses
- Improved memory access patterns
- Higher arithmetic intensity
Reduced overhead
-
Kernel launch optimization:
- Single kernel launch instead of multiple
- Lower driver overhead
- Reduced synchronization points
- Fewer memory allocations
-
Resource management:
- Shared memory reuse between operations
- Better register utilization
- Improved thread occupancy
- Higher GPU utilization
Performance characteristics
-
Scalability:
- Better performance scaling with input size
- Reduced memory bandwidth bottleneck
- More efficient use of GPU resources
- Improved throughput for large models
-
Numerical efficiency:
- Maintained numerical stability
- Reduced rounding errors
- Better precision in intermediate results
- Optimized computation order
💡 Key insight: Kernel fusion is particularly beneficial for operations that are frequently used together in neural networks, like LayerNorm + Linear in transformer architectures. The performance benefits become more significant with larger input sizes and more complex models.
⛓️ Autograd Integration & Backward Pass
Overview
In this puzzle, we explore the backward pass implementation of the fused LayerNorm + Linear operation. The backward pass computes gradients with respect to:
- Input tensor
- LayerNorm scale (\(\gamma\)) and shift (\(\beta\)) parameters
- Linear layer weight matrix and bias
The mathematical operations we’re implementing are:
-
LayerNorm backward (details of derivation in Detailed derivation of LayerNorm backward pass): \[\Large \frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \odot \gamma \odot \frac{1}{\sqrt{\sigma^2 + \epsilon}} (1 - \frac{1}{H} - \frac{(x - \mu)^2}{H(\sigma^2 + \epsilon)}) \]
-
Linear backward: \[\Large \frac{\partial L}{\partial W} = \frac{\partial L}{\partial y}x^T \] \[\Large \frac{\partial L}{\partial b} = \frac{\partial L}{\partial y} \] \[\Large \frac{\partial L}{\partial x} = W^T\frac{\partial L}{\partial y} \]
-
Chain Rule for Fused Operation: \[\Large \frac{\partial L}{\partial x} = \frac{\partial L}{\partial y_{linear}} \frac{\partial y_{linear}}{\partial y_{norm}} \frac{\partial y_{norm}}{\partial x} \] where:
- \(y_{norm}\) is the LayerNorm output
- \(y_{linear}\) is the Linear layer output
- The chain rule ensures proper gradient flow through both operations
Key concepts
-
Thread organization:
- One thread block per sequence position (grid:
[batch_size, seq_len]) - Single thread per sequence position to avoid redundancy
- Compute all gradients for each sequence position in one thread
- Ensure proper thread synchronization for atomic operations
- One thread block per sequence position (grid:
-
Memory access:
- Access input tensor with
[batch_idx, seq_idx, h] - Access output tensor with
[batch_idx, seq_idx, out_idx] - Access weights with
[out_idx, h]for linear layer - Ensure memory alignment for atomic operations
- Use shared memory for frequently accessed data
- Access input tensor with
-
Computation flow:
- Compute LayerNorm statistics in same order as forward pass
- Reuse normalized values for all output dimensions
- Combine normalization and linear transformation
- Maintain numerical stability throughout
- Handle edge cases properly
-
Performance:
- Avoid redundant computation of statistics
- Minimize memory traffic by fusing operations
- Use proper type casting with
rebind[Scalar[dtype]] - Ensure proper memory alignment
- Optimize for autograd integration
Configuration
- Batch size:
BATCH_SIZE = 4 - Sequence length:
SEQ_LEN = 4 - Hidden dimension:
HIDDEN_DIM = 8 - Output dimension:
OUTPUT_DIM = 16 - Epsilon:
EPS = 1e-5 - Data type:
DType.float32
Implementation (challenging)
The fused backward kernel combines LayerNorm and Linear backward operations into a single GPU kernel. This is a challenging implementation that requires careful handling of:
- Atomic operations for gradient accumulation
- Numerical stability in gradient computations
- Memory access patterns for efficient GPU utilization
- Proper synchronization between operations
def minimal_fused_kernel_backward[
batch_size: Int,
seq_len: Int,
hidden_dim: Int,
output_dim: Int,
GradInputLayout: TensorLayout,
GradLnWeightLayout: TensorLayout,
GradLnBiasLayout: TensorLayout,
GradWeightLayout: TensorLayout,
GradBiasLayout: TensorLayout,
GradOutputLayout: TensorLayout,
InputLayout: TensorLayout,
LnParamsLayout: TensorLayout,
WeightLayout: TensorLayout,
](
grad_input: TileTensor[mut=True, dtype, GradInputLayout, MutAnyOrigin],
grad_ln_weight: TileTensor[
mut=True, dtype, GradLnWeightLayout, MutAnyOrigin
],
grad_ln_bias: TileTensor[mut=True, dtype, GradLnBiasLayout, MutAnyOrigin],
grad_weight: TileTensor[mut=True, dtype, GradWeightLayout, MutAnyOrigin],
grad_bias: TileTensor[mut=True, dtype, GradBiasLayout, MutAnyOrigin],
grad_output: TileTensor[mut=False, dtype, GradOutputLayout, ImmutAnyOrigin],
input: TileTensor[mut=False, dtype, InputLayout, ImmutAnyOrigin],
ln_weight: TileTensor[mut=False, dtype, LnParamsLayout, ImmutAnyOrigin],
ln_bias: TileTensor[mut=False, dtype, LnParamsLayout, ImmutAnyOrigin],
linear_weight: TileTensor[mut=False, dtype, WeightLayout, ImmutAnyOrigin],
):
"""Fused backward kernel using atomic operations for safe gradient accumulation.
"""
# Grid: (batch_size, seq_len) - one thread per sequence position
# Block: (1,) - single thread per sequence position
var batch_idx = block_idx.x
var seq_idx = block_idx.y
if batch_idx >= batch_size or seq_idx >= seq_len:
return
# Initialize gradient tensors to zero (block 0,0 only to avoid UB with atomic ops)
if batch_idx == 0 and seq_idx == 0:
# Initialize grad_ln_weight and grad_ln_bias
comptime for h in range(hidden_dim):
(grad_ln_weight.ptr + h).init_pointee_copy(0)
(grad_ln_bias.ptr + h).init_pointee_copy(0)
# Initialize grad_weight and grad_bias
comptime for out_idx in range(output_dim):
(grad_bias.ptr + out_idx).init_pointee_copy(0)
comptime for h in range(hidden_dim):
(grad_weight.ptr + out_idx * hidden_dim + h).init_pointee_copy(
0
)
# Note: We cannot use barrier() here as it only synchronizes within a block.
# The atomic operations will handle synchronization across blocks.
# Step 1: Recompute forward pass statistics (needed for gradients)
var sum_val: Scalar[dtype] = 0
var sq_sum: Scalar[dtype] = 0
# FILL IN roughly 8 lines
# Step 2: Atomically accumulate gradients w.r.t. linear bias
# FILL IN roughly 4 lines
# Step 3: Atomically accumulate gradients w.r.t. linear weight
# Make sure to use the correct atomic operation to avoid race conditions
# FILL IN roughly 10 lines
# Step 4: Atomically accumulate gradients w.r.t. LayerNorm parameters
# FILL IN roughly 10 lines
# Step 5: Compute gradients w.r.t. input (LayerNorm backward)
# Compute sum terms needed for LayerNorm backward
# Make sure to use the correct atomic operation to avoid race conditions
# FILL IN roughly 12 lines
# Compute actual input gradients (no race conditions here - each thread writes to different positions)
# FILL IN roughly 10 lines
Key optimizations:
- Single kernel launch for all gradient computations
- Atomic operations for safe gradient accumulation
- Coalesced memory access patterns
- Reduced memory bandwidth usage
- No intermediate tensor allocations
Tips
-
Thread organization:
- One thread block per sequence position
- Single thread per sequence position
- Compute all gradients in one thread
-
Memory access:
- Coalesced access for input/output tensors
- Strided access for weight matrix
- Proper alignment for atomic operations
-
Computation flow:
- Compute statistics in same order as forward pass
- Reuse normalized values
- Maintain numerical stability
-
Performance:
- Minimize memory traffic
- Use proper type casting
- Ensure proper alignment
Running the code
To test your fused backward implementation, run:
pixi run p22 --backward
pixi run -e amd p22 --backward
uv run poe p22 --backward
Your output will look like this:
Testing with dimensions: [4, 4, 8] -> [4, 4, 16]
✅ Loaded Mojo operations library
============================================================
Comprehensive Backward Pass Test
Testing Custom LayerNorm + Linear Gradients
============================================================
Testing with dimensions: [4, 4, 8] -> [4, 4, 16]
Testing CPU Backward Pass:
Testing CPU Backward Implementation - Backward Pass
---------------------------------------------------------
Computing PyTorch autograd reference...
Computing Mojo backward implementation (CPU)...
✅ CPU Backward Implementation backward completed
Forward max difference: 1.49e-08
grad_input: 2.98e-08 ✅
grad_ln_weight: 5.96e-08 ✅
grad_ln_bias: 2.38e-07 ✅
grad_linear_weight: 9.54e-07 ✅
grad_linear_bias: 0.00e+00 ✅
Forward pass: ✅ CORRECT
Gradients: ✅ CORRECT
Overall: ✅ CORRECT
Testing GPU Backward Pass:
Testing GPU Backward Implementation - Backward Pass
---------------------------------------------------------
Computing PyTorch autograd reference...
Computing Mojo backward implementation (GPU)...
✅ GPU Backward Implementation backward completed
Forward max difference: 1.86e-08
grad_input: 4.47e-08 ✅
grad_ln_weight: 5.96e-08 ✅
grad_ln_bias: 3.58e-07 ✅
grad_linear_weight: 9.54e-07 ✅
grad_linear_bias: 0.00e+00 ✅
Forward pass: ✅ CORRECT
Gradients: ✅ CORRECT
Overall: ✅ CORRECT
Backward Pass Test Summary:
- CPU Backward: ✅ CORRECT
- GPU Backward: ✅ CORRECT
Overall Result: ✅ ALL CORRECT
BACKWARD PASS Test Completed!
Solution
def minimal_fused_kernel_backward[
batch_size: Int,
seq_len: Int,
hidden_dim: Int,
output_dim: Int,
GradInputLayout: TensorLayout,
GradLnWeightLayout: TensorLayout,
GradLnBiasLayout: TensorLayout,
GradWeightLayout: TensorLayout,
GradBiasLayout: TensorLayout,
GradOutputLayout: TensorLayout,
InputLayout: TensorLayout,
LnParamsLayout: TensorLayout,
WeightLayout: TensorLayout,
dtype: DType = DType.float32,
](
grad_input: TileTensor[mut=True, dtype, GradInputLayout, MutAnyOrigin],
grad_ln_weight: TileTensor[
mut=True, dtype, GradLnWeightLayout, MutAnyOrigin
],
grad_ln_bias: TileTensor[mut=True, dtype, GradLnBiasLayout, MutAnyOrigin],
grad_weight: TileTensor[mut=True, dtype, GradWeightLayout, MutAnyOrigin],
grad_bias: TileTensor[mut=True, dtype, GradBiasLayout, MutAnyOrigin],
grad_output: TileTensor[mut=True, dtype, GradOutputLayout, MutAnyOrigin],
input: TileTensor[mut=True, dtype, InputLayout, MutAnyOrigin],
ln_weight: TileTensor[mut=True, dtype, LnParamsLayout, MutAnyOrigin],
ln_bias: TileTensor[mut=True, dtype, LnParamsLayout, MutAnyOrigin],
linear_weight: TileTensor[mut=True, dtype, WeightLayout, MutAnyOrigin],
):
"""Fused backward kernel using atomic operations for safe gradient accumulation.
"""
# Grid: (batch_size, seq_len) - one thread per sequence position
# Block: (1,) - single thread per sequence position
var batch_idx = block_idx.x
var seq_idx = block_idx.y
if batch_idx >= batch_size or seq_idx >= seq_len:
return
var grad_input_lt = grad_input.to_layout_tensor()
var grad_ln_weight_lt = grad_ln_weight.to_layout_tensor()
var grad_ln_bias_lt = grad_ln_bias.to_layout_tensor()
var grad_weight_lt = grad_weight.to_layout_tensor()
var grad_bias_lt = grad_bias.to_layout_tensor()
var grad_output_lt = grad_output.to_layout_tensor()
var input_lt = input.to_layout_tensor()
var ln_weight_lt = ln_weight.to_layout_tensor()
var ln_bias_lt = ln_bias.to_layout_tensor()
var linear_weight_lt = linear_weight.to_layout_tensor()
# Initialize gradient tensors to zero (block 0,0 only to avoid UB with atomic ops)
if batch_idx == 0 and seq_idx == 0:
# Initialize grad_ln_weight and grad_ln_bias
comptime for h in range(hidden_dim):
(grad_ln_weight.ptr + h).init_pointee_copy(0)
(grad_ln_bias.ptr + h).init_pointee_copy(0)
# Initialize grad_weight and grad_bias
comptime for out_idx in range(output_dim):
(grad_bias.ptr + out_idx).init_pointee_copy(0)
comptime for h in range(hidden_dim):
(grad_weight.ptr + out_idx * hidden_dim + h).init_pointee_copy(
0
)
# Note: We cannot use barrier() here as it only synchronizes within a block.
# The atomic operations will handle synchronization across blocks.
# Step 1: Recompute forward pass statistics (needed for gradients)
var sum_val: Scalar[dtype] = 0
var sq_sum: Scalar[dtype] = 0
comptime for h in range(hidden_dim):
var val = input_lt[batch_idx, seq_idx, h]
sum_val += rebind[Scalar[dtype]](val)
sq_sum += rebind[Scalar[dtype]](val * val)
var mean_val = sum_val / hidden_dim
var var_val = (sq_sum / hidden_dim) - (mean_val * mean_val)
var inv_std = 1.0 / sqrt(var_val + 1e-5)
# Step 2: Atomically accumulate gradients w.r.t. linear bias
comptime for out_idx in range(output_dim):
var grad_bias_ptr = grad_bias.ptr + out_idx
_ = Atomic[dtype].fetch_add(
grad_bias_ptr,
rebind[Scalar[dtype]](grad_output_lt[batch_idx, seq_idx, out_idx]),
)
# Step 3: Atomically accumulate gradients w.r.t. linear weight
comptime for out_idx in range(output_dim):
comptime for h in range(hidden_dim):
var input_val = input_lt[batch_idx, seq_idx, h]
var normalized = (input_val - mean_val) * inv_std
var ln_output_val = normalized * rebind[Scalar[dtype]](
ln_weight_lt[h]
) + rebind[Scalar[dtype]](ln_bias_lt[h])
# Atomic gradient accumulation for linear weight
var grad_w = (
grad_output_lt[batch_idx, seq_idx, out_idx] * ln_output_val
)
var grad_weight_ptr = grad_weight.ptr + out_idx * hidden_dim + h
_ = Atomic.fetch_add(grad_weight_ptr, rebind[Scalar[dtype]](grad_w))
# Step 4: Atomically accumulate gradients w.r.t. LayerNorm parameters
comptime for h in range(hidden_dim):
input_val = input_lt[batch_idx, seq_idx, h]
normalized = (input_val - mean_val) * inv_std
# Compute gradient w.r.t. LayerNorm output for this h
var grad_ln_out: Scalar[dtype] = 0
comptime for out_idx in range(output_dim):
grad_ln_out = grad_ln_out + rebind[Scalar[dtype]](
grad_output_lt[batch_idx, seq_idx, out_idx]
* linear_weight_lt[out_idx, h]
)
# Atomic accumulation of LayerNorm parameter gradients
var grad_ln_weight_ptr = grad_ln_weight.ptr + h
var grad_ln_bias_ptr = grad_ln_bias.ptr + h
_ = Atomic[dtype].fetch_add(
grad_ln_weight_ptr, rebind[Scalar[dtype]](grad_ln_out * normalized)
)
_ = Atomic[dtype].fetch_add(
grad_ln_bias_ptr, rebind[Scalar[dtype]](grad_ln_out)
)
# Step 5: Compute gradients w.r.t. input (LayerNorm backward)
# Compute sum terms needed for LayerNorm backward
var sum_grad_normalized: Scalar[dtype] = 0
var sum_grad_normalized_times_normalized: Scalar[dtype] = 0
comptime for h in range(hidden_dim):
h_input_val = input_lt[batch_idx, seq_idx, h]
h_normalized = (h_input_val - mean_val) * inv_std
var h_grad_ln_out: Scalar[dtype] = 0
comptime for out_idx in range(output_dim):
h_grad_ln_out = h_grad_ln_out + rebind[Scalar[dtype]](
grad_output_lt[batch_idx, seq_idx, out_idx]
* linear_weight_lt[out_idx, h]
)
h_grad_norm = h_grad_ln_out * rebind[Scalar[dtype]](ln_weight_lt[h])
sum_grad_normalized = sum_grad_normalized + rebind[Scalar[dtype]](
h_grad_norm
)
sum_grad_normalized_times_normalized = (
sum_grad_normalized_times_normalized
+ rebind[Scalar[dtype]](h_grad_norm * h_normalized)
)
# Compute actual input gradients (no race conditions here - each thread writes to different positions)
comptime for h in range(hidden_dim):
h_input_val = input_lt[batch_idx, seq_idx, h]
h_normalized = (h_input_val - mean_val) * inv_std
var h_grad_ln_out: Scalar[dtype] = 0
comptime for out_idx in range(output_dim):
h_grad_ln_out = h_grad_ln_out + rebind[Scalar[dtype]](
grad_output_lt[batch_idx, seq_idx, out_idx]
* linear_weight_lt[out_idx, h]
)
h_grad_norm = h_grad_ln_out * rebind[Scalar[dtype]](ln_weight_lt[h])
grad_input_lt[batch_idx, seq_idx, h] = inv_std * (
h_grad_norm
- (sum_grad_normalized / hidden_dim)
- (h_normalized * sum_grad_normalized_times_normalized / hidden_dim)
)
The fused backward implementation combines operations efficiently:
-
Thread organization and memory layout:
- Grid dimensions:
[batch_size, seq_len]for one thread block per sequence position - Thread indices:
batch_idx = block_idx.x,seq_idx = block_idx.y - Memory layout:
- Input tensor:
[batch_size, seq_len, hidden_dim] - Output tensor:
[batch_size, seq_len, output_dim] - Weight matrix:
[output_dim, hidden_dim] - Gradients:
[batch_size, seq_len, hidden_dim]for input gradients - Parameter gradients:
[hidden_dim]for LayerNorm,[output_dim, hidden_dim]for Linear
- Input tensor:
- Grid dimensions:
-
LayerNorm backward phase:
- Recompute forward pass statistics in same order as forward pass:
- Mean: \[\Large \mu = \frac{1}{H} \sum_{i=1}^{H} x_i \]
- Variance: \[\Large \sigma^2 = \frac{1}{H} \sum_{i=1}^{H} (x_i - \mu)^2 \]
- Inverse standard deviation: \[\Large \text{inv_std} = \frac{1}{\sqrt{\sigma^2 + \epsilon}} \]
- Compute normalized values: \[\Large \hat{x} = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} \]
- Calculate gradients:
- Input gradient: \[\Large \frac{\partial L}{\partial x} = \frac{\partial
L}{\partial y} \odot \gamma \odot \frac{1}{\sqrt{\sigma^2 + \epsilon}} (1
- \frac{1}{H} - \frac{(x - \mu)^2}{H(\sigma^2 + \epsilon)}) \]
- Scale gradient: \[\Large \frac{\partial L}{\partial \gamma} = \sum_{i=1}^{H} \frac{\partial L}{\partial y_i} \odot \hat{x}_i \]
- Shift gradient: \[\Large \frac{\partial L}{\partial \beta} = \sum_{i=1}^{H} \frac{\partial L}{\partial y_i} \]
- Input gradient: \[\Large \frac{\partial L}{\partial x} = \frac{\partial
L}{\partial y} \odot \gamma \odot \frac{1}{\sqrt{\sigma^2 + \epsilon}} (1
- Recompute forward pass statistics in same order as forward pass:
-
Linear backward phase:
- For each output dimension:
- Bias gradient: \[\Large \frac{\partial L}{\partial b} = \frac{\partial L}{\partial y} \]
- Weight gradient: \[\Large \frac{\partial L}{\partial W} = \frac{\partial L}{\partial y}x^T \]
- Input gradient: \[\Large \frac{\partial L}{\partial x} = W^T\frac{\partial L}{\partial y} \]
- Use atomic operations for gradient accumulation:
atomic_addfor bias gradients with proper alignmentatomic_addfor weight gradients with proper alignmentatomic_addfor LayerNorm parameter gradients with proper alignment
- For each output dimension:
-
Memory access patterns:
- Coalesced access for input/output tensors
- Strided access for weight matrix
- Atomic operations for gradient accumulation
- Shared memory for intermediate results
- Register usage for frequently accessed values
- Proper memory alignment for all operations
-
Numerical stability:
- Careful handling of epsilon in denominator
- Proper scaling of gradients
- Stable computation of statistics
- Type casting with
rebind[Scalar[dtype]] - Proper handling of edge cases
- Maintain same computation order as forward pass
-
Performance optimizations:
- Single kernel launch for all operations
- Reuse of computed statistics
- Minimized memory traffic
- No intermediate tensor allocations
- Efficient thread utilization
- Reduced synchronization points
- Optimized memory access patterns
- Proper memory alignment
-
Implementation details:
- Use of
@parameterfor compile-time constants - Proper handling of tensor dimensions
- Efficient type casting and conversions
- Careful management of shared memory
- Proper synchronization between operations
- Error handling and boundary checks
- Integration with PyTorch’s autograd system
- Use of
This implementation achieves better performance than the unfused version by:
- Reducing memory bandwidth usage through kernel fusion
- Minimizing kernel launch overhead
- Optimizing memory access patterns
- Efficient use of GPU resources
- Maintaining numerical stability
- Proper handling of gradient accumulation
- Ensuring proper memory alignment
- Efficient autograd integration
The fused backward pass is particularly important in transformer architectures where LayerNorm + Linear operations are frequently used together, making the performance benefits significant for real-world applications.
Performance considerations
The backward pass implementation uses torch.compile with optimizations to
minimize overhead:
# Compilation configuration
torch._dynamo.config.cache_size_limit = 64 # Increase cache
torch._dynamo.config.suppress_errors = True # Handle errors gracefully
torch._dynamo.config.automatic_dynamic_shapes = True # Dynamic shapes
These optimizations are particularly important for the backward pass because:
- Small tensor operations benefit from compilation caching
- Dynamic shapes are common in backward passes
- Error handling needs to be robust for gradient computation
- Cache size helps with repeated backward operations
- Proper error handling is crucial for gradient computation
- Compilation overhead can significantly impact training time
The backward pass is compiled with reduce-overhead mode to minimize the
compilation overhead while maintaining correctness. This is especially important
because:
- Backward passes are called frequently during training
- Gradient computation needs to be numerically stable
- Memory access patterns need to be optimized
- Atomic operations require proper synchronization
- Autograd integration needs to be efficient
Detailed derivation of LayerNorm backward pass
The backward pass gradient for LayerNorm is derived through careful application of the chain rule. Here’s the step-by-step derivation:
Forward pass operations
- Mean: \(\mu = \frac{1}{H} \sum_{i=1}^{H} x_i\)
- Variance: \(\sigma^2 = \frac{1}{H} \sum_{i=1}^{H} (x_i - \mu)^2\)
- Normalized value: \(\hat{x} = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}}\)
- Final output: \(y = \gamma \odot \hat{x} + \beta\)
Chain rule application
To compute \(\frac{\partial L}{\partial x}\), we apply the chain rule: \[\Large \frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \frac{\partial y}{\partial \hat{x}} \frac{\partial \hat{x}}{\partial x}\]
Gradient components
Output to normalized value
- \(\frac{\partial y}{\partial \hat{x}} = \gamma\) (element-wise multiplication)
Normalized value to input
The gradient \(\frac{\partial \hat{x}}{\partial x}\) has three components:
- Direct effect through numerator: \(\frac{1}{\sqrt{\sigma^2 + \epsilon}}\)
- Indirect effect through mean: \(-\frac{1}{H} \frac{1}{\sqrt{\sigma^2 + \epsilon}}\)
- Indirect effect through variance: \(-\frac{(x - \mu)}{H(\sigma^2 + \epsilon)^{3/2}} (x - \mu)\)
Combining terms
The gradient through the normalization term can be simplified to: \[\Large \frac{\partial \hat{x}}{\partial x} = \frac{1}{\sqrt{\sigma^2 + \epsilon}} (1 - \frac{1}{H} - \frac{(x - \mu)^2}{H(\sigma^2 + \epsilon)})\]
Final gradient expression
Combining all terms: \[\Large \frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \odot \gamma \odot \frac{1}{\sqrt{\sigma^2 + \epsilon}} (1 - \frac{1}{H} - \frac{(x - \mu)^2}{H(\sigma^2 + \epsilon)})\]
Key insights
- The chain rule accounts for all paths through which x affects the output
- The normalization term \(\sqrt{\sigma^2 + \epsilon}\) appears in both numerator and denominator
- The mean and variance terms create additional paths for gradient flow
- The final expression combines all effects into a single efficient computation
Implementation considerations
- The gradient properly accounts for the scaling effect of \(\gamma\)
- The normalization effect of mean and variance is preserved
- The numerical stability term \(\epsilon\) is maintained
- Gradients are properly scaled across the hidden dimension H
- The computation order matches the forward pass for numerical stability
This derivation ensures that the backward pass maintains the same numerical properties as the forward pass while efficiently computing all necessary gradients.
Puzzle 23: GPU Functional Programming Patterns
Overview
Part VI: Functional GPU Programming introduces Mojo’s high-level programming patterns for GPU computation. You’ll learn functional approaches that automatically handle vectorization, memory optimization, and performance tuning, replacing manual GPU kernel programming.
Key insight: Modern GPU programming doesn’t require sacrificing elegance for performance - Mojo’s functional patterns give you both.
What you’ll learn
GPU execution hierarchy
Understand the fundamental relationship between GPU threads and SIMD operations:
GPU Device
├── Grid (your entire problem)
│ ├── Block 1 (group of threads, shared memory)
│ │ ├── Warp 1 (32 threads, lockstep execution) --> We'll learn in Part VI
│ │ │ ├── Thread 1 → SIMD
│ │ │ ├── Thread 2 → SIMD
│ │ │ └── ... (32 threads total)
│ │ └── Warp 2 (32 threads)
│ └── Block 2 (independent group)
What Mojo abstracts for you:
- Grid/Block configuration automatically calculated
- Warp management handled transparently
- Thread scheduling optimized automatically
- Memory hierarchy optimization built-in
💡 Note: While this Part focuses on functional patterns, warp-level programming and advanced GPU memory management will be covered in detail in Part VII.
Four fundamental patterns
Learn the complete spectrum of GPU functional programming:
- Elementwise: Maximum parallelism with automatic SIMD vectorization
- Tiled: Memory-efficient processing with cache optimization
- Manual vectorization: Expert-level control over SIMD operations
- Mojo vectorize: Safe, automatic vectorization with bounds checking
Performance patterns you’ll recognize
Problem: Add two 1024-element vectors (SIZE=1024, SIMD_WIDTH=4)
Elementwise: 256 threads × 1 SIMD op = High parallelism
Tiled: 32 threads × 8 SIMD ops = Cache optimization
Manual: 8 threads × 32 SIMD ops = Maximum control
Mojo vectorize: 32 threads × 8 SIMD ops = Automatic safety
📊 Real performance insights
Learn to interpret empirical benchmark results:
Benchmark Results (SIZE=1,048,576):
elementwise: 11.34ms ← Maximum parallelism wins at scale
tiled: 12.04ms ← Good balance of locality and parallelism
manual_vectorized: 15.75ms ← Complex indexing hurts simple operations
vectorized: 13.38ms ← Automatic optimization overhead
Prerequisites
Before diving into functional patterns, ensure you’re comfortable with:
- Basic GPU concepts: Memory hierarchy, thread execution, SIMD operations
- Mojo fundamentals: Parameter functions, compile-time specialization, capturing semantics
- TileTensor operations: Loading, storing, and tensor manipulation
- GPU memory management: Buffer allocation, host-device synchronization
Learning path
1. Elementwise operations
→ Elementwise - Basic GPU Functional Operations
Start with the foundation: automatic thread management and SIMD vectorization.
What you’ll learn:
- Functional GPU programming with
elementwise - Automatic SIMD vectorization within GPU threads
- TileTensor operations for safe memory access
- Capturing semantics in nested functions
Key pattern:
elementwise[add_function, SIMD_WIDTH, target="gpu"](total_size, ctx)
2. Tiled processing
→ Tile - Memory-Efficient Tiled Processing
Build on elementwise with memory-optimized tiling patterns.
What you’ll learn:
- Tile-based memory organization for cache optimization
- Sequential SIMD processing within tiles
- Memory locality principles and cache-friendly access patterns
- Thread-to-tile mapping vs thread-to-element mapping
Key insight: Tiling trades parallel breadth for memory locality - fewer threads each doing more work with better cache utilization.
3. Advanced vectorization
→ Vectorization - Fine-Grained SIMD Control
Explore manual control and automatic vectorization strategies.
What you’ll learn:
- Manual SIMD operations with explicit index management
- Mojo’s vectorize function for safe, automatic vectorization
- Chunk-based memory organization for optimal SIMD alignment
- Performance trade-offs between manual control and safety
Two approaches:
- Manual: Direct control, maximum performance, complex indexing
- Mojo vectorize: Automatic optimization, built-in safety, clean code
🧠 4. Threading vs SIMD concepts
→ GPU Threading vs SIMD - Understanding the Execution Hierarchy
Understand the fundamental relationship between parallelism levels.
What you’ll learn:
- GPU threading hierarchy and hardware mapping
- SIMD operations within GPU threads
- Pattern comparison and thread-to-work mapping
- Choosing the right pattern for different workloads
Key insight: GPU threads provide the parallelism structure, while SIMD operations provide the vectorization within each thread.
📊 5. Performance benchmarking in Mojo
Learn to measure, analyze, and optimize GPU performance scientifically.
What you’ll learn:
- Mojo’s built-in benchmarking framework
- GPU-specific timing and synchronization challenges
- Parameterized benchmark functions with compile-time specialization
- Empirical performance analysis and pattern selection
Critical technique: Using keep() to prevent compiler optimization of
benchmarked code.
Getting started
Start with the elementwise pattern and work through each section systematically. Each puzzle builds on the previous concepts while introducing new levels of sophistication.
💡 Success tip: Focus on understanding the why behind each pattern, not just the how. The conceptual framework you develop here will serve you throughout your GPU programming career.
Learning objective: By the end of Part VI, you’ll think in terms of functional patterns rather than low-level GPU mechanics, enabling you to write more maintainable, performant, and portable GPU code.
Begin with: Elementwise Operations to discover functional GPU programming.
Elementwise - Basic GPU Functional Operations
This puzzle implements vector addition using Mojo’s functional elementwise
pattern. Each thread automatically processes multiple SIMD elements, showing how
modern GPU programming abstracts low-level details while preserving high
performance.
Key insight: The elementwise function automatically handles thread management, SIMD vectorization, and memory coalescing for you.
Key concepts
This puzzle covers:
- Functional GPU programming with
elementwise - Automatic SIMD vectorization within GPU threads
- TileTensor operations for safe memory access
- GPU thread hierarchy vs SIMD operations
- Capturing semantics in nested functions
The mathematical operation is simple element-wise addition: \[\Large \text{output}[i] = a[i] + b[i]\]
The implementation covers fundamental patterns applicable to all GPU functional programming in Mojo.
Configuration
- Vector size:
SIZE = 1024 - Data type:
DType.float32 - SIMD width: Target-dependent (determined by GPU architecture and data type)
- Layout:
row_major[SIZE]()(1D row-major)
Code to complete
comptime SIZE = 1024
comptime rank = 1
comptime layout = row_major[SIZE]()
comptime LayoutType = type_of(layout)
comptime dtype = DType.float32
comptime SIMD_WIDTH = simd_width_of[dtype, target=get_gpu_target()]()
def elementwise_add[
LayoutT: TensorLayout, dtype: DType, simd_width: Int, rank: Int, size: Int
](
output: TileTensor[mut=True, dtype, LayoutT, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
ctx: DeviceContext,
) raises:
@parameter
@always_inline
def add[
simd_width: Int, rank: Int, alignment: Int = align_of[dtype]()
](indices: IndexList[rank]) capturing -> None:
var idx = indices[0]
print("idx:", idx)
# FILL IN (2 to 4 lines)
elementwise[add, SIMD_WIDTH, target="gpu"](size, ctx)
View full file: problems/p23/p23.mojo
Tips
1. Understanding the function structure
The elementwise function expects a nested function with this exact signature:
@parameter
@always_inline
def your_function[simd_width: Int, rank: Int](indices: IndexList[rank]) capturing -> None:
# Your implementation here
Why each part matters:
@parameter: Enables compile-time specialization for optimal GPU code generation@always_inline: Forces inlining to eliminate function call overhead in GPU kernelscapturing: Allows access to variables from the outer scope (the input/output tensors)IndexList[rank]: Provides multi-dimensional indexing (rank=1 for vectors, rank=2 for matrices)
2. Index extraction and SIMD processing
idx = indices[0] # Extract linear index for 1D operations
This idx represents the starting position for a SIMD vector, not a single
element. If SIMD_WIDTH=4 (GPU-dependent), then:
- Thread 0 processes elements
[0, 1, 2, 3]starting atidx=0 - Thread 1 processes elements
[4, 5, 6, 7]starting atidx=4 - Thread 2 processes elements
[8, 9, 10, 11]starting atidx=8 - And so on…
3. SIMD loading pattern
a_simd = a.aligned_load[simd_width](Index(idx)) # Load 4 consecutive floats (GPU-dependent)
b_simd = b.aligned_load[simd_width](Index(idx)) # Load 4 consecutive floats (GPU-dependent)
The second parameter 0 is the dimension offset (always 0 for 1D vectors). This
loads a vectorized chunk of data in a single operation. The exact number of
elements loaded depends on your GPU’s SIMD capabilities.
4. Vector arithmetic
result = a_simd + b_simd # SIMD addition of 4 elements simultaneously (GPU-dependent)
This performs element-wise addition across the entire SIMD vector (if supported) in parallel - much faster than 4 separate scalar additions.
5. SIMD storing
output.store[simd_width](Index(idx), result) # Store 4 results at once (GPU-dependent)
Writes the entire SIMD vector back to memory in one operation.
6. Calling the elementwise function
elementwise[your_function, SIMD_WIDTH, target="gpu"](total_size, ctx)
total_sizeshould bea.size()to process all elements- The GPU automatically determines how many threads to launch:
total_size // SIMD_WIDTH
7. Key debugging insight
Notice the print("idx:", idx) in the template. When you run it, you’ll see:
idx: 0, idx: 4, idx: 8, idx: 12, ...
This shows that each thread handles a different SIMD chunk, automatically spaced
by SIMD_WIDTH (which is GPU-dependent).
Running the code
To test your solution, run the following command in your terminal:
pixi run p23 --elementwise
pixi run -e amd p23 --elementwise
pixi run -e apple p23 --elementwise
uv run poe p23 --elementwise
Your output will look like this if the puzzle isn’t solved yet:
SIZE: 1024
simd_width: 4
...
idx: 404
idx: 408
idx: 412
idx: 416
...
out: HostBuffer([0.0, 0.0, 0.0, ..., 0.0, 0.0, 0.0])
expected: HostBuffer([1.0, 5.0, 9.0, ..., 4085.0, 4089.0, 4093.0])
Solution
def elementwise_add[
LayoutT: TensorLayout, dtype: DType, simd_width: Int, rank: Int, size: Int
](
output: TileTensor[mut=True, dtype, LayoutT, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
ctx: DeviceContext,
) raises:
@parameter
@always_inline
def add[
simd_width: Int, rank: Int, alignment: Int = align_of[dtype]()
](indices: IndexList[rank]) capturing -> None:
var idx = indices[0]
# Convert inside GPU kernel to avoid host-captured LayoutTensor issues
var a_lt = a.to_layout_tensor()
var b_lt = b.to_layout_tensor()
var out_lt = output.to_layout_tensor()
# Note: This is thread-local SIMD - each thread processes its own vector of data
# we'll later better see this hierarchy in Mojo:
# SIMD within threads, warp across threads, block across warps
var a_simd = a_lt.aligned_load[width=simd_width](Index(idx))
var b_simd = b_lt.aligned_load[width=simd_width](Index(idx))
var ret = a_simd + b_simd
out_lt.store[simd_width](Index(idx), ret)
elementwise[add, SIMD_WIDTH, target="gpu"](size, ctx)
The elementwise functional pattern in Mojo introduces several fundamental concepts for modern GPU programming:
1. Functional abstraction philosophy
The elementwise function represents a paradigm shift from traditional GPU
programming:
Traditional CUDA/HIP approach:
# Manual thread management
idx = thread_idx.x + block_idx.x * block_dim.x
if idx < size:
output[idx] = a[idx] + b[idx]; // Scalar operation
Mojo functional approach:
# Automatic management + SIMD vectorization
elementwise[add_function, simd_width, target="gpu"](size, ctx)
What elementwise abstracts away:
- Thread grid configuration: No need to calculate block/grid dimensions
- Bounds checking: Automatic handling of array boundaries
- Memory coalescing: Optimal memory access patterns built-in
- SIMD orchestration: Vectorization handled transparently
- GPU target selection: Works across different GPU architectures
2. Deep dive: nested function architecture
@parameter
@always_inline
def add[simd_width: Int, rank: Int](indices: IndexList[rank]) capturing -> None:
Parameter Analysis:
@parameter: This decorator provides compile-time specialization. The function is generated separately for each uniquesimd_widthandrank, allowing aggressive optimization.@always_inline: Critical for GPU performance - eliminates function call overhead by embedding the code directly into the kernel.capturing: Enables lexical scoping - the inner function can access variables from the outer scope without explicit parameter passing.IndexList[rank]: Provides dimension-agnostic indexing - the same pattern works for 1D vectors, 2D matrices, 3D tensors, etc.
3. SIMD execution model deep dive
idx = indices[0] # Linear index: 0, 4, 8, 12... (GPU-dependent spacing)
a_simd = a.aligned_load[simd_width](Index(idx)) # Load: [a[0:4], a[4:8], a[8:12]...] (4 elements per load)
b_simd = b.aligned_load[simd_width](Index(idx)) # Load: [b[0:4], b[4:8], b[8:12]...] (4 elements per load)
ret = a_simd + b_simd # SIMD: 4 additions in parallel (GPU-dependent)
output.store[simd_width](Index(idx), ret) # Store: 4 results simultaneously (GPU-dependent)
Execution Hierarchy Visualization:
GPU Architecture:
├── Grid (entire problem)
│ ├── Block 1 (multiple warps)
│ │ ├── Warp 1 (32 threads) --> We'll learn about Warp in the next Part VI
│ │ │ ├── Thread 1 → SIMD[4 elements] ← Our focus (GPU-dependent width)
│ │ │ ├── Thread 2 → SIMD[4 elements]
│ │ │ └── ...
│ │ └── Warp 2 (32 threads)
│ └── Block 2 (multiple warps)
For a 1024-element vector with SIMD_WIDTH=4 (example GPU):
- Total SIMD operations needed: 1024 ÷ 4 = 256
- GPU launches: 256 threads (1024 ÷ 4)
- Each thread processes: Exactly 4 consecutive elements
- Memory bandwidth: SIMD_WIDTH× improvement over scalar operations
Note: SIMD width varies by GPU architecture (e.g., 4 for some GPUs, 8 for RTX 4090, 16 for A100).
4. Memory access pattern analysis
a.aligned_load[simd_width](Index(idx)) // Coalesced memory access
Memory Coalescing Benefits:
- Sequential access: Threads access consecutive memory locations
- Cache optimization: Maximizes L1/L2 cache hit rates
- Bandwidth utilization: Achieves near-theoretical memory bandwidth
- Hardware efficiency: GPU memory controllers optimized for this pattern
Example for SIMD_WIDTH=4 (GPU-dependent):
Thread 0: loads a[0:4] → Memory bank 0-3
Thread 1: loads a[4:8] → Memory bank 4-7
Thread 2: loads a[8:12] → Memory bank 8-11
...
Result: Optimal memory controller utilization
5. Performance characteristics & optimization
Computational Intensity Analysis (for SIMD_WIDTH=4):
- Arithmetic operations: 1 SIMD addition per 4 elements
- Memory operations: 2 SIMD loads + 1 SIMD store per 4 elements
- Arithmetic intensity: 1 add ÷ 3 memory ops = 0.33 (memory-bound)
Why This Is Memory-Bound:
Memory bandwidth >>> Compute capability for simple operations
Optimization Implications:
- Focus on memory access patterns rather than arithmetic optimization
- SIMD vectorization provides the primary performance benefit
- Memory coalescing is critical for performance
- Cache locality matters more than computational complexity
6. Scaling and adaptability
Automatic Hardware Adaptation:
comptime SIMD_WIDTH = simd_width_of[dtype, target = _get_gpu_target()]()
- GPU-specific optimization: SIMD width adapts to hardware (e.g., 4 for some cards, 8 for RTX 4090, 16 for A100)
- Data type awareness: Different SIMD widths for float32 vs float16
- Compile-time optimization: Zero runtime overhead for hardware detection
Scalability Properties:
- Thread count: Automatically scales with problem size
- Memory usage: Linear scaling with input size
- Performance: Near-linear speedup until memory bandwidth saturation
7. Advanced insights: why this pattern matters
Foundation for Complex Operations: This elementwise pattern is the building block for:
- Reduction operations: Sum, max, min across large arrays
- Broadcast operations: Scalar-to-vector operations
- Complex transformations: Activation functions, normalization
- Multi-dimensional operations: Matrix operations, convolutions
Compared to Traditional Approaches:
// Traditional: Error-prone, verbose, hardware-specific
__global__ void add_kernel(float* output, float* a, float* b, int size) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size) {
output[idx] = a[idx] + b[idx]; // No vectorization
}
}
// Mojo: Safe, concise, automatically vectorized
elementwise[add, SIMD_WIDTH, target="gpu"](size, ctx)
Benefits of Functional Approach:
- Safety: Automatic bounds checking prevents buffer overruns
- Portability: Same code works across GPU vendors/generations
- Performance: Compiler optimizations often exceed hand-tuned code
- Maintainability: Clean abstractions reduce debugging complexity
- Composability: Easy to combine with other functional operations
This pattern represents the future of GPU programming - high-level abstractions that don’t sacrifice performance, making GPU computing accessible while maintaining optimal efficiency.
Next steps
Once you’ve learned elementwise operations, you’re ready for:
- Tile Operations: Memory-efficient tiled processing patterns
- Vectorization: Fine-grained SIMD control
- 🧠 GPU Threading vs SIMD: Understanding the execution hierarchy
- 📊 Benchmarking: Performance analysis and optimization
💡 Key Takeaway: The elementwise pattern shows how Mojo combines
functional programming elegance with GPU performance, automatically handling
vectorization and thread management while maintaining full control over the
computation.
Tile - Memory-Efficient Tiled Processing
Overview
Building on the elementwise pattern, this puzzle introduces tiled processing - a fundamental technique for optimizing memory access patterns and cache utilization on GPUs. Instead of each thread processing individual SIMD vectors across the entire array, tiling organizes data into smaller, manageable chunks that fit better in cache memory.
You’ve already seen tiling in action with Puzzle 16’s tiled matrix multiplication, where we used tiles to process large matrices efficiently. Here, we apply the same tiling principles to vector operations, demonstrating how this technique scales from 2D matrices to 1D arrays.
Implement the same vector addition operation using Mojo’s tiled approach. Each GPU thread will process an entire tile of data sequentially, demonstrating how memory locality can improve performance for certain workloads.
Key insight: Tiling trades parallel breadth for memory locality - fewer threads each doing more work with better cache utilization.
Key concepts
In this puzzle, you’ll learn:
- Tile-based memory organization for cache optimization
- Sequential SIMD processing within tiles
- Memory locality principles and cache-friendly access patterns
- Thread-to-tile mapping vs thread-to-element mapping
- Performance trade-offs between parallelism and memory efficiency
The same mathematical operation as elementwise: \[\Large \text{output}[i] = a[i] + b[i]\]
But with a completely different execution strategy optimized for memory hierarchy.
Configuration
- Vector size:
SIZE = 1024 - Tile size:
TILE_SIZE = 32 - Data type:
DType.float32 - SIMD width: GPU-dependent (for operations within tiles)
- Layout:
row_major[SIZE]()(1D row-major)
Code to complete
comptime TILE_SIZE = 32
def tiled_elementwise_add[
LayoutT: TensorLayout,
dtype: DType,
simd_width: Int,
rank: Int,
size: Int,
tile_size: Int,
](
output: TileTensor[mut=True, dtype, LayoutT, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
ctx: DeviceContext,
) raises:
@parameter
@always_inline
def process_tiles[
simd_width: Int, rank: Int, alignment: Int = align_of[dtype]()
](indices: IndexList[rank]) capturing -> None:
var tile_id = indices[0]
print("tile_id:", tile_id)
var output_tile = output.tile[tile_size](tile_id)
var a_tile = a.tile[tile_size](tile_id)
var b_tile = b.tile[tile_size](tile_id)
# FILL IN (6 lines at most)
var num_tiles = (size + tile_size - 1) // tile_size
elementwise[process_tiles, 1, target="gpu"](num_tiles, ctx)
View full file: problems/p23/p23.mojo
Tips
1. Understanding tile organization
The tiled approach divides your data into fixed-size chunks:
num_tiles = (size + tile_size - 1) // tile_size # Ceiling division
For a 1024-element vector with TILE_SIZE=32: 1024 ÷ 32 = 32 tiles exactly.
2. Tile extraction pattern
Check out the
TileTensor .tile documentation.
tile_id = indices[0] # Each thread gets one tile to process
out_tile = output.tile[tile_size](tile_id)
a_tile = a.tile[tile_size](tile_id)
b_tile = b.tile[tile_size](tile_id)
The tile[size](id) method creates a view of size consecutive elements
starting at id × size.
3. Sequential processing within tiles
Unlike elementwise, you process the tile sequentially:
@parameter
for i in range(tile_size):
# Process element i within the current tile
This @parameter loop unrolls at compile-time for optimal performance.
4. SIMD operations within tile elements
a_vec = a_tile.load[simd_width](Index(i)) # Load from position i in tile
b_vec = b_tile.load[simd_width](Index(i)) # Load from position i in tile
result = a_vec + b_vec # SIMD addition (GPU-dependent width)
out_tile.store[simd_width](Index(i), result) # Store to position i in tile
5. Thread configuration difference
elementwise[process_tiles, 1, target="gpu"](num_tiles, ctx)
Note the 1 instead of SIMD_WIDTH - each thread processes one entire tile
sequentially.
6. Memory access pattern insight
Each thread accesses a contiguous block of memory (the tile), then moves to the next tile. This creates excellent spatial locality within each thread’s execution.
7. Key debugging insight
With tiling, you’ll see fewer thread launches but each does more work:
- Elementwise: ~256 threads (for SIMD_WIDTH=4), each processing 4 elements
- Tiled: ~32 threads, each processing 32 elements sequentially
Running the code
To test your solution, run the following command in your terminal:
pixi run p23 --tiled
pixi run -e amd p23 --tiled
pixi run -e apple p23 --tiled
uv run poe p23 --tiled
Your output will look like this when not yet solved:
SIZE: 1024
simd_width: 4
tile size: 32
tile_id: 0
tile_id: 1
tile_id: 2
tile_id: 3
...
tile_id: 29
tile_id: 30
tile_id: 31
out: HostBuffer([0.0, 0.0, 0.0, ..., 0.0, 0.0, 0.0])
expected: HostBuffer([1.0, 5.0, 9.0, ..., 4085.0, 4089.0, 4093.0])
Solution
comptime TILE_SIZE = 32
def tiled_elementwise_add[
LayoutT: TensorLayout,
dtype: DType,
simd_width: Int,
rank: Int,
size: Int,
tile_size: Int,
](
output: TileTensor[mut=True, dtype, LayoutT, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
ctx: DeviceContext,
) raises:
@parameter
@always_inline
def process_tiles[
simd_width: Int, rank: Int, alignment: Int = align_of[dtype]()
](indices: IndexList[rank]) capturing -> None:
var tile_id = indices[0]
var output_tile = output.tile[tile_size](tile_id).to_layout_tensor()
var a_tile = a.tile[tile_size](tile_id).to_layout_tensor()
var b_tile = b.tile[tile_size](tile_id).to_layout_tensor()
comptime for i in range(tile_size):
var a_vec = a_tile.aligned_load[width=simd_width](Index(i))
var b_vec = b_tile.aligned_load[width=simd_width](Index(i))
var ret = a_vec + b_vec
output_tile.store[simd_width](Index(i), ret)
var num_tiles = (size + tile_size - 1) // tile_size
elementwise[process_tiles, 1, target="gpu"](num_tiles, ctx)
The tiled processing pattern demonstrates advanced memory optimization techniques for GPU programming:
1. Tiling philosophy and memory hierarchy
Tiling represents a fundamental shift in how we think about parallel processing:
Elementwise approach:
- Wide parallelism: Many threads, each doing minimal work
- Global memory pressure: Threads scattered across entire array
- Cache misses: Poor spatial locality across thread boundaries
Tiled approach:
- Deep parallelism: Fewer threads, each doing substantial work
- Localized memory access: Each thread works on contiguous data
- Cache optimization: Excellent spatial and temporal locality
2. Tile organization and indexing
tile_id = indices[0]
out_tile = output.tile[tile_size](tile_id)
a_tile = a.tile[tile_size](tile_id)
b_tile = b.tile[tile_size](tile_id)
Tile mapping visualization (TILE_SIZE=32):
Original array: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ..., 1023]
Tile 0 (thread 0): [0, 1, 2, ..., 31] ← Elements 0-31
Tile 1 (thread 1): [32, 33, 34, ..., 63] ← Elements 32-63
Tile 2 (thread 2): [64, 65, 66, ..., 95] ← Elements 64-95
...
Tile 31 (thread 31): [992, 993, ..., 1023] ← Elements 992-1023
Key insights:
- Each
tile[size](id)creates a view into the original tensor - Views are zero-copy - no data movement, just pointer arithmetic
- Tile boundaries are always aligned to
tile_sizeboundaries
3. Sequential processing deep dive
@parameter
for i in range(tile_size):
a_vec = a_tile.load[simd_width](Index(i))
b_vec = b_tile.load[simd_width](Index(i))
ret = a_vec + b_vec
out_tile.store[simd_width](Index(i), ret)
Why sequential processing?
- Cache optimization: Consecutive memory accesses maximize cache hit rates
- Compiler optimization:
@parameterloops unroll completely at compile-time - Memory bandwidth: Sequential access aligns with memory controller design
- Reduced coordination: No need to synchronize between SIMD groups
Execution pattern within one tile (TILE_SIZE=32, SIMD_WIDTH=4):
Thread processes tile sequentially:
Step 0: Process elements [0:4] with SIMD
Step 1: Process elements [4:8] with SIMD
Step 2: Process elements [8:12] with SIMD
...
Step 7: Process elements [28:32] with SIMD
Total: 8 SIMD operations per thread (32 ÷ 4 = 8)
4. Memory access pattern analysis
Cache behavior comparison:
Elementwise pattern:
Thread 0: accesses global positions [0, 4, 8, 12, ...] ← Stride = SIMD_WIDTH
Thread 1: accesses global positions [4, 8, 12, 16, ...] ← Stride = SIMD_WIDTH
...
Result: Memory accesses spread across entire array
Tiled pattern:
Thread 0: accesses positions [0:32] sequentially ← Contiguous 32-element block
Thread 1: accesses positions [32:64] sequentially ← Next contiguous 32-element block
...
Result: Perfect spatial locality within each thread
Cache efficiency implications:
- L1 cache: Small tiles often fit better in L1 cache, reducing cache misses
- Memory bandwidth: Sequential access maximizes effective bandwidth
- TLB efficiency: Fewer translation lookbook buffer misses
- Prefetching: Hardware prefetchers work optimally with sequential patterns
5. Thread configuration strategy
elementwise[process_tiles, 1, target="gpu"](num_tiles, ctx)
Why 1 instead of SIMD_WIDTH?
- Thread count: Launch exactly
num_tilesthreads, notnum_tiles × SIMD_WIDTH - Work distribution: Each thread handles one complete tile
- Load balancing: More work per thread, fewer threads total
- Memory locality: Each thread’s work is spatially localized
Performance trade-offs:
- Fewer logical threads: May not fully utilize all GPU cores at low occupancy
- More work per thread: Better cache utilization and reduced coordination overhead
- Sequential access: Optimal memory bandwidth utilization within each thread
- Reduced overhead: Less thread launch and coordination overhead
Important note: “Fewer threads” refers to the logical programming model. The GPU scheduler can still achieve high hardware utilization by running multiple warps and efficiently switching between them during memory stalls.
6. Performance characteristics
When tiling helps:
- Memory-bound operations: When memory bandwidth is the bottleneck
- Cache-sensitive workloads: Operations that benefit from data reuse
- Complex operations: When compute per element is higher
- Limited parallelism: When you have fewer threads than GPU cores
When tiling hurts:
- Highly parallel workloads: When you need maximum thread utilization
- Simple operations: When memory access dominates over computation
- Irregular access patterns: When tiling doesn’t improve locality
For our simple addition example (TILE_SIZE=32):
- Thread count: 32 threads instead of 256 (8× fewer)
- Work per thread: 32 elements instead of 4 (8× more)
- Memory pattern: Sequential vs strided access
- Cache utilization: Much better spatial locality
7. Advanced tiling considerations
Tile size selection:
- Too small: Poor cache utilization, more overhead
- Too large: May not fit in cache, reduced parallelism
- Sweet spot: Usually 16-64 elements for L1 cache optimization
- Our choice: 32 elements balances cache usage with parallelism
Hardware considerations:
- Cache size: Tiles should fit in L1 cache when possible
- Memory bandwidth: Consider memory controller width
- Core count: Ensure enough tiles to utilize all cores
- SIMD width: Tile size should be multiple of SIMD width
Comparison summary:
Elementwise: High parallelism, scattered memory access
Tiled: Moderate parallelism, localized memory access
The choice between elementwise and tiled patterns depends on your specific workload characteristics, data access patterns, and target hardware capabilities.
Next steps
Now that you understand both elementwise and tiled patterns:
- Vectorization: Fine-grained control over SIMD operations
- 🧠 GPU Threading vs SIMD: Understanding the execution hierarchy
- 📊 Benchmarking: Performance analysis and optimization
💡 Key takeaway: Tiling demonstrates how memory access patterns often matter more than raw computational throughput. The best GPU code balances parallelism with memory hierarchy optimization.
Vectorization - Fine-Grained SIMD Control
Overview
This puzzle explores advanced vectorization techniques using manual vectorization and vectorize that give you precise control over SIMD operations within GPU kernels. You’ll implement two different approaches to vectorized computation:
- Manual vectorization: Direct SIMD control with explicit index calculations
- Mojo’s vectorize function: High-level vectorization with automatic bounds checking
Both approaches build on tiling concepts but with different trade-offs between control, safety, and performance optimization.
Key insight: Different vectorization strategies suit different performance requirements and complexity levels.
Key concepts
In this puzzle, you’ll learn:
- Manual SIMD operations with explicit index management
- Mojo’s vectorize function for safe, automatic vectorization
- Chunk-based memory organization for optimal SIMD alignment
- Bounds checking strategies for edge cases
- Performance trade-offs between manual control and safety
The same mathematical operation as before: \[\Large \text{output}[i] = a[i] + b[i]\]
But with sophisticated vectorization strategies for maximum performance.
Configuration
- Vector size:
SIZE = 1024 - Tile size:
TILE_SIZE = 32 - Data type:
DType.float32 - SIMD width: GPU-dependent
- Layout:
row_major[SIZE]()(1D row-major)
1. Manual vectorization approach
Code to complete
def manual_vectorized_tiled_elementwise_add[
LayoutT: TensorLayout,
dtype: DType,
simd_width: Int,
num_threads_per_tile: Int,
rank: Int,
size: Int,
tile_size: Int,
](
output: TileTensor[mut=True, dtype, LayoutT, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
ctx: DeviceContext,
) raises:
# Each tile contains tile_size groups of simd_width elements
comptime chunk_size = tile_size * simd_width
@parameter
@always_inline
def process_manual_vectorized_tiles[
num_threads_per_tile: Int, rank: Int, alignment: Int = align_of[dtype]()
](indices: IndexList[rank]) capturing -> None:
var tile_id = indices[0]
print("tile_id:", tile_id)
var output_tile = output.tile[chunk_size](tile_id)
var a_tile = a.tile[chunk_size](tile_id)
var b_tile = b.tile[chunk_size](tile_id)
# FILL IN (7 lines at most)
# Number of tiles needed: each tile processes chunk_size elements
var num_tiles = (size + chunk_size - 1) // chunk_size
elementwise[
process_manual_vectorized_tiles, num_threads_per_tile, target="gpu"
](num_tiles, ctx)
View full file: problems/p23/p23.mojo
Tips
1. Understanding chunk organization
comptime chunk_size = tile_size * simd_width # 32 * 4 = 128 elements per chunk
Each tile now contains multiple SIMD groups, not just sequential elements.
2. Global index calculation
global_start = tile_id * chunk_size + i * simd_width
This calculates the exact global position for each SIMD vector within the chunk.
3. Direct tensor access
a_vec = a.aligned_load[simd_width](Index(global_start)) # Load from global tensor
output.store[simd_width](Index(global_start), ret) # Store to global tensor
Note: Access the original tensors, not the tile views.
4. Key characteristics
- More control, more complexity, global tensor access
- Perfect SIMD alignment with hardware
- Manual bounds checking required
Running manual vectorization
pixi run p23 --manual-vectorized
pixi run -e amd p23 --manual-vectorized
pixi run -e apple p23 --manual-vectorized
uv run poe p23 --manual-vectorized
Your output will look like this when not yet solved:
SIZE: 1024
simd_width: 4
tile size: 32
tile_id: 0
tile_id: 1
tile_id: 2
tile_id: 3
tile_id: 4
tile_id: 5
tile_id: 6
tile_id: 7
out: HostBuffer([0.0, 0.0, 0.0, ..., 0.0, 0.0, 0.0])
expected: HostBuffer([1.0, 5.0, 9.0, ..., 4085.0, 4089.0, 4093.0])
Manual vectorization solution
def manual_vectorized_tiled_elementwise_add[
LayoutT: TensorLayout,
dtype: DType,
simd_width: Int,
num_threads_per_tile: Int,
rank: Int,
size: Int,
tile_size: Int,
](
output: TileTensor[mut=True, dtype, LayoutT, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
ctx: DeviceContext,
) raises:
# Each tile contains tile_size groups of simd_width elements
comptime chunk_size = tile_size * simd_width
@parameter
@always_inline
def process_manual_vectorized_tiles[
num_threads_per_tile: Int, rank: Int, alignment: Int = align_of[dtype]()
](indices: IndexList[rank]) capturing -> None:
var tile_id = indices[0]
# Convert inside GPU kernel to avoid host-captured LayoutTensor issues
var a_lt = a.to_layout_tensor()
var b_lt = b.to_layout_tensor()
var out_lt = output.to_layout_tensor()
comptime for i in range(tile_size):
var global_start = tile_id * chunk_size + i * simd_width
var a_vec = a_lt.aligned_load[width=simd_width](Index(global_start))
var b_vec = b_lt.aligned_load[width=simd_width](Index(global_start))
var ret = a_vec + b_vec
out_lt.store[simd_width](Index(global_start), ret)
# Number of tiles needed: each tile processes chunk_size elements
var num_tiles = (size + chunk_size - 1) // chunk_size
elementwise[
process_manual_vectorized_tiles, num_threads_per_tile, target="gpu"
](num_tiles, ctx)
Manual vectorization deep dive
Manual vectorization gives you direct control over SIMD operations with explicit index calculations:
- Chunk-based organization:
chunk_size = tile_size * simd_width - Global indexing: Direct calculation of memory positions
- Manual bounds management: You handle edge cases explicitly
Architecture and memory layout:
comptime chunk_size = tile_size * simd_width # 32 * 4 = 128
Chunk organization visualization (TILE_SIZE=32, SIMD_WIDTH=4):
Original array: [0, 1, 2, 3, ..., 1023]
Chunk 0 (thread 0): [0:128] ← 128 elements = 32 SIMD groups of 4
Chunk 1 (thread 1): [128:256] ← Next 128 elements
Chunk 2 (thread 2): [256:384] ← Next 128 elements
...
Chunk 7 (thread 7): [896:1024] ← Final 128 elements
Processing within one chunk:
@parameter
for i in range(tile_size): # i = 0, 1, 2, ..., 31
global_start = tile_id * chunk_size + i * simd_width
# For tile_id=0: global_start = 0, 4, 8, 12, ..., 124
# For tile_id=1: global_start = 128, 132, 136, 140, ..., 252
Performance characteristics:
- Thread count: 8 threads (1024 ÷ 128 = 8)
- Work per thread: 128 elements (32 SIMD operations of 4 elements each)
- Memory pattern: Large chunks with perfect SIMD alignment
- Overhead: Minimal - direct hardware mapping
- Safety: Manual bounds checking required
Key advantages:
- Predictable indexing: Exact control over memory access patterns
- Optimal alignment: SIMD operations perfectly aligned to hardware
- Maximum throughput: No overhead from safety checks
- Hardware optimization: Direct mapping to GPU SIMD units
Key challenges:
- Index complexity: Manual calculation of global positions
- Bounds responsibility: Must handle edge cases explicitly
- Debugging difficulty: More complex to verify correctness
2. Mojo vectorize approach
Code to complete
def vectorize_within_tiles_elementwise_add[
LayoutT: TensorLayout,
dtype: DType,
simd_width: Int,
num_threads_per_tile: Int,
rank: Int,
size: Int,
tile_size: Int,
](
output: TileTensor[mut=True, dtype, LayoutT, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
ctx: DeviceContext,
) raises:
# Each tile contains tile_size elements (not SIMD groups)
@parameter
@always_inline
def process_tile_with_vectorize[
num_threads_per_tile: Int, rank: Int, alignment: Int = align_of[dtype]()
](indices: IndexList[rank]) capturing -> None:
var tile_id = indices[0]
var tile_start = tile_id * tile_size
var tile_end = min(tile_start + tile_size, size)
var actual_tile_size = tile_end - tile_start
print(
"tile_id:",
tile_id,
"tile_start:",
tile_start,
"tile_end:",
tile_end,
"actual_tile_size:",
actual_tile_size,
)
# FILL IN (9 lines at most)
var num_tiles = (size + tile_size - 1) // tile_size
elementwise[
process_tile_with_vectorize, num_threads_per_tile, target="gpu"
](num_tiles, ctx)
View full file: problems/p23/p23.mojo
Tips
1. Tile boundary calculation
tile_start = tile_id * tile_size
tile_end = min(tile_start + tile_size, size)
actual_tile_size = tile_end - tile_start
Handle cases where the last tile might be smaller than tile_size.
2. Vectorized function pattern
def vectorized_add[
width: Int
](i: Int) unified {read tile_start, read a, read b, mut output}:
global_idx = tile_start + i
if global_idx + width <= size: # Bounds checking
# SIMD operations here
The width parameter is automatically determined by the vectorize function.
3. Calling vectorize
vectorize[simd_width](actual_tile_size, vectorized_add)
This automatically handles the vectorization loop with the provided SIMD width.
4. Key characteristics
- Automatic remainder handling, built-in safety, tile-based access
- Takes explicit SIMD width parameter
- Built-in bounds checking and automatic remainder element processing
Running Mojo vectorize
uv run poe p23 --vectorized
pixi run p23 --vectorized
Your output will look like this when not yet solved:
SIZE: 1024
simd_width: 4
tile size: 32
tile_id: 0 tile_start: 0 tile_end: 32 actual_tile_size: 32
tile_id: 1 tile_start: 32 tile_end: 64 actual_tile_size: 32
tile_id: 2 tile_start: 64 tile_end: 96 actual_tile_size: 32
tile_id: 3 tile_start: 96 tile_end: 128 actual_tile_size: 32
...
tile_id: 29 tile_start: 928 tile_end: 960 actual_tile_size: 32
tile_id: 30 tile_start: 960 tile_end: 992 actual_tile_size: 32
tile_id: 31 tile_start: 992 tile_end: 1024 actual_tile_size: 32
out: HostBuffer([0.0, 0.0, 0.0, ..., 0.0, 0.0, 0.0])
expected: HostBuffer([1.0, 5.0, 9.0, ..., 4085.0, 4089.0, 4093.0])
Mojo vectorize solution
def vectorize_within_tiles_elementwise_add[
LayoutT: TensorLayout,
dtype: DType,
simd_width: Int,
num_threads_per_tile: Int,
rank: Int,
size: Int,
tile_size: Int,
](
output: TileTensor[mut=True, dtype, LayoutT, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutT, MutAnyOrigin],
ctx: DeviceContext,
) raises:
# Each tile contains tile_size elements (not SIMD groups)
@parameter
@always_inline
def process_tile_with_vectorize[
num_threads_per_tile: Int, rank: Int, alignment: Int = align_of[dtype]()
](indices: IndexList[rank]) capturing -> None:
var tile_id = indices[0]
var tile_start = tile_id * tile_size
var tile_end = min(tile_start + tile_size, size)
var actual_tile_size = tile_end - tile_start
# Convert inside GPU kernel to avoid host-captured LayoutTensor issues
var a_lt = a.to_layout_tensor()
var b_lt = b.to_layout_tensor()
var out_lt = output.to_layout_tensor()
def vectorized_add[
width: Int
](i: Int) {read tile_start, read a_lt, read b_lt, mut out_lt}:
var global_idx = tile_start + i
if global_idx + width <= size:
var a_vec = a_lt.aligned_load[width](Index(global_idx))
var b_vec = b_lt.aligned_load[width](Index(global_idx))
var result = a_vec + b_vec
out_lt.store[width](Index(global_idx), result)
# Use vectorize within each tile
vectorize[simd_width](actual_tile_size, vectorized_add)
var num_tiles = (size + tile_size - 1) // tile_size
elementwise[
process_tile_with_vectorize, num_threads_per_tile, target="gpu"
](num_tiles, ctx)
Mojo vectorize deep dive
Mojo’s vectorize function provides automatic vectorization with built-in safety:
- Explicit SIMD width parameter: You provide the simd_width to use
- Built-in bounds checking: Prevents buffer overruns automatically
- Automatic remainder handling: Processes leftover elements automatically
- Nested function pattern: Clean separation of vectorization logic
Tile-based organization:
tile_start = tile_id * tile_size # 0, 32, 64, 96, ...
tile_end = min(tile_start + tile_size, size)
actual_tile_size = tile_end - tile_start
Automatic vectorization mechanism:
def vectorized_add[
width: Int
](i: Int) unified {read tile_start, read a, read b, mut output}:
global_idx = tile_start + i
if global_idx + width <= size:
# Automatic SIMD optimization
How vectorize works:
- Automatic chunking: Divides
actual_tile_sizeinto chunks of your providedsimd_width - Remainder handling: Automatically processes leftover elements with smaller widths
- Bounds safety: Automatically prevents buffer overruns
- Loop management: Handles the vectorization loop automatically
Execution visualization (TILE_SIZE=32, SIMD_WIDTH=4):
Tile 0 processing:
vectorize call 0: processes elements [0:4] with SIMD_WIDTH=4
vectorize call 1: processes elements [4:8] with SIMD_WIDTH=4
...
vectorize call 7: processes elements [28:32] with SIMD_WIDTH=4
Total: 8 automatic SIMD operations
Performance characteristics:
- Thread count: 32 threads (1024 ÷ 32 = 32)
- Work per thread: 32 elements (automatic SIMD chunking)
- Memory pattern: Smaller tiles with automatic vectorization
- Overhead: Slight - automatic optimization and bounds checking
- Safety: Built-in bounds checking and edge case handling
Performance comparison and best practices
When to use each approach
Choose manual vectorization when:
- Maximum performance is critical
- You have predictable, aligned data patterns
- Expert-level control over memory access is needed
- You can guarantee bounds safety manually
- Hardware-specific optimization is required
Choose Mojo vectorize when:
- Development speed and safety are priorities
- Working with irregular or dynamic data sizes
- You want automatic remainder handling instead of manual edge case management
- Bounds checking complexity would be error-prone
- You prefer cleaner vectorization patterns over manual loop management
Advanced optimization insights
Memory bandwidth utilization:
Manual: 8 threads × 32 SIMD ops = 256 total SIMD operations
Vectorize: 32 threads × 8 SIMD ops = 256 total SIMD operations
Both achieve similar total throughput but with different parallelism strategies.
Cache behavior:
- Manual: Large chunks may exceed L1 cache, but perfect sequential access
- Vectorize: Smaller tiles fit better in cache, with automatic remainder handling
Hardware mapping:
- Manual: Direct control over warp utilization and SIMD unit mapping
- Vectorize: Simplified vectorization with automatic loop and remainder management
Best practices summary
Manual vectorization best practices:
- Always validate index calculations carefully
- Use compile-time constants for
chunk_sizewhen possible - Profile memory access patterns for cache optimization
- Consider alignment requirements for optimal SIMD performance
Mojo vectorize best practices:
- Choose appropriate SIMD width for your data and hardware
- Focus on algorithm clarity over micro-optimizations
- Use nested parameter functions for clean vectorization logic
- Trust automatic bounds checking and remainder handling for edge cases
Both approaches represent valid strategies in the GPU performance optimization toolkit, with manual vectorization offering maximum control and Mojo’s vectorize providing safety and automatic remainder handling.
Next steps
Now that you understand all three fundamental patterns:
- 🧠 GPU Threading vs SIMD: Understanding the execution hierarchy
- 📊 Benchmarking: Performance analysis and optimization
💡 Key takeaway: Different vectorization strategies suit different performance requirements. Manual vectorization gives maximum control, while Mojo’s vectorize function provides safety and automatic remainder handling. Choose based on your specific performance needs and development constraints.
🧠 GPU Threading vs SIMD - Understanding the Execution Hierarchy
Overview
After exploring elementwise, tiled, and vectorization patterns, you’ve seen different ways to organize GPU computation. This section clarifies the fundamental relationship between GPU threads and SIMD operations - two distinct but complementary levels of parallelism that work together for optimal performance.
Key insight: GPU threads provide the parallelism structure, while SIMD operations provide the vectorization within each thread.
Core concepts
GPU threading hierarchy
GPU execution follows a well-defined hierarchy that abstracts hardware complexity:
GPU Device
├── Grid (your entire problem)
│ ├── Block 1 (group of threads, shared memory)
│ │ ├── Warp 1 (32 threads, lockstep execution)
│ │ │ ├── Thread 1 → SIMD operations
│ │ │ ├── Thread 2 → SIMD operations
│ │ │ └── ... (32 threads total)
│ │ └── Warp 2 (32 threads)
│ └── Block 2 (independent group)
💡 Note: While this Part focuses on functional patterns, warp-level programming and advanced GPU memory management will be covered in detail in Part VII.
What Mojo abstracts for you:
- Grid/Block configuration: Automatically calculated based on problem size
- Warp management: Hardware handles 32-thread groups transparently
- Thread scheduling: GPU scheduler manages execution automatically
- Memory hierarchy: Optimal access patterns built into functional operations
SIMD within GPU threads
Each GPU thread can process multiple data elements simultaneously using SIMD (Single Instruction, Multiple Data) operations:
# Within one GPU thread:
a_simd = a.load[simd_width](Index(idx)) # Load 4 floats simultaneously
b_simd = b.load[simd_width](Index(idx)) # Load 4 floats simultaneously
result = a_simd + b_simd # Add 4 pairs simultaneously
output.store[simd_width](Index(idx), result) # Store 4 results simultaneously
Pattern comparison and thread-to-work mapping
Critical insight: All patterns perform the same total work - 256 SIMD operations for 1024 elements with SIMD_WIDTH=4. The difference is in how this work is distributed across GPU threads.
Thread organization comparison (SIZE=1024, SIMD_WIDTH=4)
| Pattern | Threads | SIMD ops/thread | Memory pattern | Trade-off |
|---|---|---|---|---|
| Elementwise | 256 | 1 | Distributed access | Max parallelism, poor locality |
| Tiled | 32 | 8 | Small blocks | Balanced parallelism + locality |
| Manual vectorized | 8 | 32 | Large chunks | High bandwidth, fewer threads |
| Mojo vectorize | 32 | 8 | Smart blocks | Automatic optimization |
Detailed execution patterns
Elementwise pattern:
Thread 0: [0,1,2,3] → Thread 1: [4,5,6,7] → ... → Thread 255: [1020,1021,1022,1023]
256 threads × 1 SIMD op = 256 total SIMD operations
Tiled pattern:
Thread 0: [0:32] (8 SIMD) → Thread 1: [32:64] (8 SIMD) → ... → Thread 31: [992:1024] (8 SIMD)
32 threads × 8 SIMD ops = 256 total SIMD operations
Manual vectorized pattern:
Thread 0: [0:128] (32 SIMD) → Thread 1: [128:256] (32 SIMD) → ... → Thread 7: [896:1024] (32 SIMD)
8 threads × 32 SIMD ops = 256 total SIMD operations
Mojo vectorize pattern:
Thread 0: [0:32] auto-vectorized → Thread 1: [32:64] auto-vectorized → ... → Thread 31: [992:1024] auto-vectorized
32 threads × 8 SIMD ops = 256 total SIMD operations
Performance characteristics and trade-offs
Core trade-offs summary
| Aspect | High thread count (Elementwise) | Moderate threads (Tiled/Vectorize) | Low threads (Manual) |
|---|---|---|---|
| Parallelism | Maximum latency hiding | Balanced approach | Minimal parallelism |
| Cache locality | Poor between threads | Good within tiles | Excellent sequential |
| Memory bandwidth | Good coalescing | Good + cache reuse | Maximum theoretical |
| Complexity | Simplest | Moderate | Most complex |
When to choose each pattern
Use elementwise when:
- Simple operations with minimal arithmetic per element
- Maximum parallelism needed for latency hiding
- Scalability across different problem sizes is important
Use tiled/vectorize when:
- Cache-sensitive operations that benefit from data reuse
- Balanced performance and maintainability desired
- Automatic optimization (vectorize) is preferred
Use manual vectorization when:
- Expert-level control over memory patterns is needed
- Maximum memory bandwidth utilization is critical
- Development complexity is acceptable
Hardware considerations
Modern GPU architectures include several levels that Mojo abstracts:
Hardware reality:
- Warps: 32 threads execute in lockstep
- Streaming Multiprocessors (SMs): Multiple warps execute concurrently
- SIMD units: Vector processing units within each SM
- Memory hierarchy: L1/L2 caches, shared memory, global memory
Mojo’s abstraction benefits:
- Automatically handles warp alignment and scheduling
- Optimizes memory access patterns transparently
- Manages resource allocation across SMs
- Provides portable performance across GPU vendors
Performance mental model
Think of GPU programming as managing two complementary types of parallelism:
Thread-level parallelism:
- Provides the parallel structure (how many execution units)
- Enables latency hiding through concurrent execution
- Managed by GPU scheduler automatically
SIMD-level parallelism:
- Provides vectorization within each thread
- Maximizes arithmetic throughput per thread
- Utilizes vector processing units efficiently
Optimal performance formula:
Performance = (Sufficient threads for latency hiding) ×
(Efficient SIMD utilization) ×
(Optimal memory access patterns)
Scaling considerations
| Problem size | Optimal pattern | Reasoning |
|---|---|---|
| Small (< 1K) | Tiled/Vectorize | Lower launch overhead |
| Medium (1K-1M) | Any pattern | Similar performance |
| Large (> 1M) | Usually Elementwise | Parallelism dominates |
The optimal choice depends on your specific hardware, workload complexity, and development constraints.
Next steps
With a solid understanding of GPU threading vs SIMD concepts:
- 📊 Benchmarking: Measure and compare actual performance
💡 Key takeaway: GPU threads and SIMD operations work together as complementary levels of parallelism. Understanding their relationship allows you to choose the right pattern for your specific performance requirements and constraints.
📊 Benchmarking - Performance Analysis and Optimization
Overview
After learning elementwise, tiled, manual vectorization, and
Mojo vectorize patterns, it’s time to measure their actual performance.
Here’s how to use the built-in benchmarking system in p21.mojo to
scientifically compare these approaches and understand their performance
characteristics.
Key insight: Theoretical analysis is valuable, but empirical benchmarking reveals the true performance story on your specific hardware.
Running benchmarks
To execute the comprehensive benchmark suite:
pixi run p23 --benchmark
pixi run -e amd p23 --benchmark
pixi run -e apple p23 --benchmark
uv run poe p23 --benchmark
Your output will show performance measurements for each pattern:
SIZE: 1024
simd_width: 4
Running P21 GPU Benchmarks...
SIMD width: 4
--------------------------------------------------------------------------------
Testing SIZE=16, TILE=4
Running elementwise_16_4
Running tiled_16_4
Running manual_vectorized_16_4
Running vectorized_16_4
--------------------------------------------------------------------------------
Testing SIZE=128, TILE=16
Running elementwise_128_16
Running tiled_128_16
Running manual_vectorized_128_16
--------------------------------------------------------------------------------
Testing SIZE=128, TILE=16, Vectorize within tiles
Running vectorized_128_16
--------------------------------------------------------------------------------
Testing SIZE=1048576 (1M), TILE=1024
Running elementwise_1M_1024
Running tiled_1M_1024
Running manual_vectorized_1M_1024
Running vectorized_1M_1024
| name | met (ms) | iters |
| ------------------------- | --------------------- | ----- |
| elementwise_16_4 | 0.0033248 | 100 |
| tiled_16_4 | 0.00327392 | 100 |
| manual_vectorized_16_4 | 0.0036169600000000002 | 100 |
| vectorized_16_4 | 0.0037209599999999997 | 100 |
| elementwise_128_16 | 0.00351999 | 100 |
| tiled_128_16 | 0.00370431 | 100 |
| manual_vectorized_128_16 | 0.0043696 | 100 |
| vectorized_128_16 | 0.00378048 | 100 |
| elementwise_1M_1024 | 0.03130143 | 100 |
| tiled_1M_1024 | 0.6892189000000001 | 100 |
| manual_vectorized_1M_1024 | 0.5923888 | 100 |
| vectorized_1M_1024 | 0.1876688 | 100 |
Benchmarks completed!
Benchmark configuration
The benchmarking system uses Mojo’s built-in benchmark module:
from benchmark import Bench, BenchConfig, Bencher, BenchId, keep
bench_config = BenchConfig(max_iters=10, num_warmup_iters=1)
max_iters=10: Up to 10 iterations for statistical reliabilitynum_warmup_iters=1: GPU warmup before measurement- Check out the benchmark documentation
Benchmarking implementation essentials
Core workflow pattern
Each benchmark follows a streamlined pattern:
@parameter
def benchmark_pattern_parameterized[test_size: Int, tile_size: Int](mut b: Bencher) raises:
bench_ctx = DeviceContext()
# Setup: Create buffers and initialize data
@parameter
def pattern_workflow(ctx: DeviceContext) raises:
# Compute: Execute the algorithm being measured
b.iter_custom[pattern_workflow](bench_ctx)
# Prevent optimization: keep(out.unsafe_ptr())
# Synchronize: ctx.synchronize()
Key phases:
- Setup: Buffer allocation and data initialization
- Computation: The actual algorithm being benchmarked
- Prevent optimization: Critical for accurate measurement
- Synchronization: Ensure GPU work completes
Critical: The
keep()functionkeep(out.unsafe_ptr())prevents the compiler from optimizing away your computation as “unused code.” Without this, you might measure nothing instead of your algorithm! This is essential for accurate GPU benchmarking because kernels are launched asynchronously.
Why custom iteration works for GPU
Standard benchmarking assumes CPU-style synchronous execution. GPU kernels launch asynchronously, so we need:
- GPU context management: Proper DeviceContext lifecycle
- Memory management: Buffer cleanup between iterations
- Synchronization handling: Accurate timing of async operations
- Overhead isolation: Separate setup cost from computation cost
Test scenarios and thread analysis
The benchmark suite tests three scenarios to reveal performance characteristics:
Thread utilization summary
| Problem Size | Pattern | Threads | SIMD ops/thread | Total SIMD ops |
|---|---|---|---|---|
| SIZE=16 | Elementwise | 4 | 1 | 4 |
| Tiled | 4 | 1 | 4 | |
| Manual | 1 | 4 | 4 | |
| Vectorize | 4 | 1 | 4 | |
| SIZE=128 | Elementwise | 32 | 1 | 32 |
| Tiled | 8 | 4 | 32 | |
| Manual | 2 | 16 | 32 | |
| Vectorize | 8 | 4 | 32 | |
| SIZE=1M | Elementwise | 262,144 | 1 | 262,144 |
| Tiled | 1,024 | 256 | 262,144 | |
| Manual | 256 | 1,024 | 262,144 | |
| Vectorize | 1,024 | 256 | 262,144 |
Performance characteristics by problem size
Small problems (SIZE=16):
- Launch overhead dominates (~0.003ms baseline)
- Thread count differences don’t matter
- Tiled/vectorize show slightly lower overhead
Medium problems (SIZE=128):
- Still overhead-dominated (~0.003ms for all)
- Performance differences nearly disappear
- Transitional behaviour between overhead and computation
Large problems (SIZE=1M):
- Real algorithmic differences emerge
- Impact of uncoalesced loads becomes apparent
- Clear performance ranking appears
What the data shows
Based on empirical benchmark results across different hardware:
Performance rankings (large problems)
| Rank | Pattern | Typical time | Key insight |
|---|---|---|---|
| 🥇 | Elementwise | ~0.03ms | Coalesced memory access wins for memory-bound ops |
| 🥈 | Mojo vectorize | ~0.19ms | Uncoalesced memory access hurts performance |
| 🥉 | Manual vectorized | ~0.59ms | Uncoalesced memory access and manual optimization reduces performance |
| 4th | Tiled | ~0.69ms | Uncoalesced memory access, manual optimization without SIMD loads reduces performance further |
Key performance insights
For simple memory-bound operations: Maximum parallelism (elementwise) outperforms complex memory optimizations at scale.
Why elementwise wins:
- 262,144 threads provide excellent latency hiding
- Simple memory patterns achieve good coalescing
- Minimal overhead per thread
- Scales naturally with GPU core count
Why tiled and vectorize are competitive:
- Balanced approach between parallelism and memory locality
- Automatic optimization (vectorize) performs nearly as well as manual tiling
- Good thread utilization without excessive complexity
Why manual vectorization struggles:
- Only 256 threads limit parallelism
- Complex indexing adds computational overhead
- Cache pressure from large chunks per thread
- Diminishing returns for simple arithmetic
Framework intelligence:
- Automatic iteration count adjustment (91-100 iterations)
- Statistical reliability across different execution times
- Handles thermal throttling and system variation
Interpreting your results
Reading the output table
| name | met (ms) | iters |
| elementwise_1M_1024 | 0.03130143 | 100 |
met (ms): Execution time for a single iterationiters: Number of iterations performed- Compare within problem size: Same-size comparisons are most meaningful
Making optimization decisions
Choose patterns based on empirical evidence:
For production workloads:
- Large datasets (>100K elements): Elementwise typically optimal
- Small/startup datasets (<1K elements): Tiled or vectorize for lower overhead
- Development speed priority: Mojo vectorize for automatic optimization
- Avoid manual vectorization: Complexity rarely pays off for simple operations
Performance optimization workflow:
- Profile first: Measure before optimizing
- Test at scale: Small problems mislead about real performance
- Consider total cost: Include development and maintenance effort
- Validate improvements: Confirm with benchmarks on target hardware
Advanced benchmarking techniques
Custom test scenarios
Modify parameters to test different conditions:
# Different problem sizes
benchmark_elementwise_parameterized[1024, 32] # Large problem
benchmark_elementwise_parameterized[64, 8] # Small problem
# Different tile sizes
benchmark_tiled_parameterized[256, 8] # Small tiles
benchmark_tiled_parameterized[256, 64] # Large tiles
Hardware considerations
Your results will vary based on:
- GPU architecture: SIMD width, core count, memory bandwidth
- System configuration: PCIe bandwidth, CPU performance
- Thermal state: GPU boost clocks vs sustained performance
- Concurrent workloads: Other processes affecting GPU utilization
Best practices summary
Benchmarking workflow:
- Warm up GPU before critical measurements
- Run multiple iterations for statistical significance
- Test multiple problem sizes to understand scaling
- Use
keep()consistently to prevent optimization artifacts - Compare like with like (same problem size, same hardware)
Performance decision framework:
- Start simple: Begin with elementwise for memory-bound operations
- Measure don’t guess: Theoretical analysis guides, empirical data decides
- Scale matters: Small problem performance doesn’t predict large problem behaviour
- Total cost optimization: Balance development time vs runtime performance
Next steps
With benchmarking skills:
- Profile real applications: Apply these patterns to actual workloads
- Advanced GPU patterns: Explore reductions, convolutions, and matrix operations
- Multi-GPU scaling: Understand distributed GPU computing patterns
- Memory optimization: Dive deeper into shared memory and advanced caching
💡 Key takeaway: Benchmarking transforms theoretical understanding into practical performance optimization. Use empirical data to make informed decisions about which patterns work best for your specific hardware and workload characteristics.
Looking ahead: when you need more control
The functional patterns in Part V provide excellent performance for most workloads, but some algorithms require direct thread communication:
Algorithms that benefit from warp programming:
- Reductions: Sum, max, min operations across thread groups
- Prefix operations: Cumulative sums, running maximums
- Data shuffling: Reorganizing data between threads
- Cooperative algorithms: Where threads must coordinate closely
Performance preview:
In Part VI, we’ll revisit several algorithms from Part II and show how warp operations can:
- Simplify code: Replace complex shared memory patterns with single function calls
- Improve performance: Eliminate barriers and reduce memory traffic
- Enable new algorithms: Unlock patterns impossible with pure functional approaches
Coming up next: Part VII: Warp-Level Programming - starting with a dramatic reimplementation of Puzzle 14’s prefix sum.
Puzzle 24: Warp Fundamentals
Overview
Part VI: GPU Warp Programming introduces GPU warp-level primitives - hardware-accelerated operations that leverage synchronized thread execution within warps. You’ll learn to use built-in warp operations to replace complex shared memory patterns with simple, efficient function calls.
Goal: Replace complex shared memory + barrier + tree reduction patterns with efficient warp primitive calls that leverage hardware synchronization.
Key insight: GPU warps execute in lockstep - Mojo’s warp operations use this synchronization to provide powerful parallel primitives with zero explicit synchronization.
What you’ll learn
GPU warp execution model
Understand the fundamental hardware unit of GPU parallelism:
GPU Block (e.g., 256 threads)
├── Warp 0 (32 threads, SIMT lockstep execution)
│ ├── Lane 0 ─┐
│ ├── Lane 1 │ All execute same instruction
│ ├── Lane 2 │ at same time (SIMT)
│ │ ... │
│ └── Lane 31 ─┘
├── Warp 1 (32 threads, independent)
├── Warp 2 (32 threads, independent)
└── ...
Hardware reality:
- 32 threads per warp on NVIDIA GPUs (
WARP_SIZE=32) - 32 or 64 threads per warp on AMD GPUs (
WARP_SIZE=32 or 64) - Lockstep execution: All threads in a warp execute the same instruction simultaneously
- Zero synchronization cost: Warp operations happen instantly within each warp
Warp operations available in Mojo
Learn the core warp primitives from gpu.primitives.warp:
sum(value): Sum all values across warp lanesshuffle_idx(value, lane): Get value from specific laneshuffle_down(value, delta): Get value from lane+deltaprefix_sum(value): Compute prefix sum across laneslane_id(): Get current thread’s lane number (0-31 or 0-63)
Performance transformation example
# 1. Reduction through shared memory
# Complex pattern we have seen earlier (from p12.mojo):
shared = TileTensor[
dtype,
row_major[WARP_SIZE](),
MutAnyOrigin,
address_space = AddressSpace.SHARED,
].stack_allocation()
shared[local_i] = partial_product
barrier()
# Safe tree reduction through shared memory requires a barrier after each reduction phase:
stride = WARP_SIZE // 2
while stride > 0:
if local_i < stride:
shared[local_i] += shared[local_i + stride]
barrier()
stride //= 2
# 2. Reduction using warp primitives
# Safe tree reduction using warp primitives does not require shared memory or a barrier
# after each reduction phase.
# Mojo's warp-level sum operation uses warp primitives under the hood and hides all this
# complexity:
total = sum(partial_product) # Internally no barriers, no race conditions!
When warp operations excel
Learn the performance characteristics:
Problem Scale Traditional Warp Operations
Single warp (32) Fast Fastest (no barriers)
Few warps (128) Good Excellent (minimal overhead)
Many warps (1024+) Good Outstanding (scales linearly)
Massive (16K+) Bottlenecked Memory-bandwidth limited
Prerequisites
Before diving into warp programming, ensure you’re comfortable with:
- Part V functional patterns: Elementwise, tiled, and vectorized approaches
- GPU thread hierarchy: Understanding blocks, warps, and threads
- TileTensor operations: Loading, storing, and tensor manipulation
- Shared memory concepts: Why barriers and tree reduction are complex
Learning path
1. SIMT execution model
Understand the hardware foundation that makes warp operations possible.
What you’ll learn:
- Single Instruction, Multiple Thread (SIMT) execution model
- Warp divergence and convergence patterns
- Lane synchronization within warps
- Hardware vs software thread management
Key insight: Warps are the fundamental unit of GPU execution - understanding SIMT unlocks warp programming.
2. Warp sum fundamentals
Learn the most important warp operation through dot product implementation.
What you’ll learn:
- Replacing shared memory + barriers with
sum() - Cross-GPU architecture compatibility (
WARP_SIZE) - Kernel vs functional programming patterns with warps
- Performance comparison with traditional approaches
Key pattern:
partial_result = compute_per_lane_value()
total = sum(partial_result) # Magic happens here!
if lane_id() == 0:
output[0] = total
3. When to use warp programming
→ When to Use Warp Programming
Learn the decision framework for choosing warp operations over alternatives.
What you’ll learn:
- Problem characteristics that favor warp operations
- Performance scaling patterns with warp count
- Memory bandwidth vs computation trade-offs
- Warp operation selection guidelines
Decision framework: When reduction operations become the bottleneck, warp primitives often provide the breakthrough.
Key concepts to learn
Hardware-software alignment
Understanding how Mojo’s warp operations map to GPU hardware:
- SIMT execution: All lanes execute same instruction simultaneously
- Built-in synchronization: No explicit barriers needed within warps
- Cross-architecture support:
WARP_SIZEhandles NVIDIA vs AMD differences
Pattern transformation
Converting complex parallel patterns to warp primitives:
- Tree reduction →
sum() - Prefix computation →
prefix_sum() - Data shuffling →
shuffle_idx(),shuffle_down()
Performance characteristics
Recognizing when warp operations provide advantages:
- Small to medium problems: Eliminates barrier overhead
- Large problems: Reduces memory traffic and improves cache utilization
- Regular patterns: Warp operations excel with predictable access patterns
Getting started
Start with understanding the SIMT execution model, then dive into practical warp sum implementation, and finish with the strategic decision framework.
💡 Success tip: Think of warps as synchronized vector units rather than independent threads. This mental model will guide you toward effective warp programming patterns.
Learning objective: By the end of Part VI, you’ll recognize when warp operations can replace complex synchronization patterns, enabling you to write simpler, faster GPU code.
Ready to begin? Start with SIMT Execution Model and discover the power of warp-level programming!
🧠 Warp lanes & SIMT execution
Mental model for warp programming vs SIMD
What is a warp?
A warp is a group of 32 (or 64) GPU threads that execute the same instruction at the same time on different data. Think of it as a synchronized vector unit where each thread acts like a “lane” in a vector processor.
Simple example:
from gpu.primitives.warp import sum
# All 32 threads in the warp execute this simultaneously:
var my_value = input[my_thread_id] # Each gets different data
var warp_total = sum(my_value) # All contribute to one sum
What just happened? Instead of 32 separate threads doing complex coordination, the warp automatically synchronized them to produce a single result. This is SIMT (Single Instruction, Multiple Thread) execution.
SIMT vs SIMD comparison
If you’re familiar with CPU vector programming (SIMD), GPU warps are similar but with key differences:
| Aspect | CPU SIMD (e.g., AVX) | GPU Warp (SIMT) |
|---|---|---|
| Programming model | Explicit vector operations | Thread-based programming |
| Data width | Fixed (256/512 bits) | Flexible (32/64 threads) |
| Synchronization | Implicit within instruction | Implicit within warp |
| Communication | Via memory/registers | Via shuffle operations |
| Divergence handling | Not applicable | Hardware masking |
| Example | a + b | sum(thread_value) |
CPU SIMD approach (C++ intrinsics):
// Explicit vector operations - say 8 floats in parallel
__m256 result = _mm256_add_ps(a, b); // Add 8 pairs simultaneously
CPU SIMD approach (Mojo):
# SIMD in Mojo is first class citizen type so if a, b are of type SIMD then
# addition is performed in parallel
var result = a + b # Add 8 pairs simultaneously
GPU SIMT approach (Mojo):
# Thread-based code that becomes vector operations
from gpu.primitives.warp import sum
var my_data = input[thread_id] # Each thread gets its element
var partial = my_data * coefficient # All threads compute simultaneously
var total = sum(partial) # Hardware coordinates the sum
Core concepts that make warps powerful
1. Lane identity: Each thread has a “lane ID” (0 to 31) that’s essentially free to access
var my_lane = lane_id() # Just reading a hardware register
2. Implicit synchronization: No barriers needed within a warp
# This just works - all threads automatically synchronized
var sum = sum(my_contribution)
3. Efficient communication: Threads can share data without memory
# Get value from lane 0 to all other lanes
var broadcasted = shuffle_idx(my_value, 0)
Key insight: SIMT lets you write natural thread code that executes as efficient vector operations, combining the ease of thread programming with the performance of vector processing.
Where warps fit in GPU execution hierarchy
For complete context on how warps relate to the overall GPU execution model, see GPU Threading vs SIMD. Here’s where warps fit:
GPU Device
├── Grid (your entire problem)
│ ├── Block 1 (group of threads, shared memory)
│ │ ├── Warp 1 (32 threads, lockstep execution) ← This level
│ │ │ ├── Thread 1 → SIMD operations
│ │ │ ├── Thread 2 → SIMD operations
│ │ │ └── ... (32 threads total)
│ │ └── Warp 2 (32 threads)
│ └── Block 2 (independent group)
Warp programming operates at the “Warp level” - you work with operations
that coordinate all 32 threads within a single warp, enabling powerful
primitives like sum() that would otherwise require complex shared memory
coordination.
This mental model supports recognizing when problems map naturally to warp operations versus requiring traditional shared memory approaches.
The hardware foundation of warp programming
Understanding Single Instruction, Multiple Thread (SIMT) execution is crucial for effective warp programming. This isn’t just a software abstraction - it’s how GPU hardware actually works at the silicon level.
What is SIMT execution?
SIMT means that within a warp, all threads execute the same instruction at the same time on different data. This is fundamentally different from CPU threads, which can execute completely different instructions independently.
CPU vs GPU Execution Models
| Aspect | CPU (MIMD) | GPU Warp (SIMT) |
|---|---|---|
| Instruction Model | Multiple Instructions, Multiple Data | Single Instruction, Multiple Thread |
| Core 1 | add r1, r2 | add r1, r2 |
| Core 2 | load r3, [mem] | add r1, r2 (same instruction) |
| Core 3 | branch loop | add r1, r2 (same instruction) |
| … Core 32 | different instruction | add r1, r2 (same instruction) |
| Execution | Independent, asynchronous | Synchronized, lockstep |
| Scheduling | Complex, OS-managed | Simple, hardware-managed |
| Data | Independent data sets | Different data, same operation |
GPU Warp Execution Pattern:
- Instruction: Same for all 32 lanes:
add r1, r2 - Lane 0: Operates on
Data0→Result0 - Lane 1: Operates on
Data1→Result1 - Lane 2: Operates on
Data2→Result2 - … (all lanes execute simultaneously)
- Lane 31: Operates on
Data31→Result31
Key insight: All lanes execute the same instruction at the same time on different data.
Why SIMT works for GPUs
GPUs are optimized for throughput, not latency. SIMT enables:
- Hardware simplification: One instruction decoder serves 32 or 64 threads
- Execution efficiency: No complex scheduling between warp threads
- Memory bandwidth: Coalesced memory access patterns
- Power efficiency: Shared control logic across lanes
Warp execution mechanics
Lane numbering and identity
Each thread within a warp has a lane ID from 0 to WARP_SIZE-1:
from gpu import lane_id
from gpu.primitives.warp import WARP_SIZE
# Within a kernel function:
my_lane = lane_id() # Returns 0-31 (NVIDIA/RDNA) or 0-63 (CDNA)
Key insight: lane_id() is free - it’s just reading a hardware
register, not computing a value.
Synchronization within warps
The most powerful aspect of SIMT: implicit synchronization.
# Example with thread_idx.x < WARP_SIZE
# 1. Traditional shared memory approach:
shared[thread_idx.x] = partial_result
barrier() # Explicit synchronization required
var total = shared[0] + shared[1] + ... + shared[WARP_SIZE] # Sum reduction
# 2. Warp approach:
from gpu.primitives.warp import sum
var total = sum(partial_result) # Implicit synchronization!
Why no barriers needed? All lanes execute each instruction at exactly the
same time. When sum() starts, all lanes have already computed their
partial_result.
Warp divergence and convergence
What happens with conditional code?
if lane_id() % 2 == 0:
# Even lanes execute this path
result = compute_even()
else:
# Odd lanes execute this path
result = compute_odd()
# All lanes converge here
Hardware behaviour steps:
| Step | Phase | Active Lanes | Waiting Lanes | Efficiency | Performance Cost |
|---|---|---|---|---|---|
| 1 | Condition evaluation | All 32 lanes | None | 100% | Normal speed |
| 2 | Even lanes branch | Lanes 0,2,4…30 (16 lanes) | Lanes 1,3,5…31 (16 lanes) | 50% | 2× slower |
| 3 | Odd lanes branch | Lanes 1,3,5…31 (16 lanes) | Lanes 0,2,4…30 (16 lanes) | 50% | 2× slower |
| 4 | Convergence | All 32 lanes | None | 100% | Normal speed resumed |
Example breakdown:
- Step 2: Only even lanes execute
compute_even()while odd lanes wait - Step 3: Only odd lanes execute
compute_odd()while even lanes wait - Total time:
time(compute_even) + time(compute_odd)(sequential execution) - Without divergence:
max(time(compute_even), time(compute_odd))(parallel execution)
Performance impact:
- Divergence: Warp splits execution - some lanes active, others wait
- Serial execution: Different paths run sequentially, not in parallel
- Convergence: All lanes reunite and continue together
- Cost: Divergent warps take 2× time (or more) vs unified execution
Best practices for warp efficiency
Warp efficiency patterns
✅ EXCELLENT: Uniform execution (100% efficiency)
# All lanes do the same work - no divergence
var partial = a[global_i] * b[global_i]
var total = sum(partial)
Performance: All 32 lanes active simultaneously
⚠️ ACCEPTABLE: Predictable divergence (~95% efficiency)
# Divergence based on lane_id() - hardware optimized
if lane_id() == 0:
output[block_idx] = sum(partial)
Performance: Brief single-lane operation, predictable pattern
🔶 CAUTION: Structured divergence (~50-75% efficiency)
# Regular patterns can be optimized by compiler
if (global_i / 4) % 2 == 0:
result = method_a()
else:
result = method_b()
Performance: Predictable groups, some optimization possible
❌ AVOID: Data-dependent divergence (~25-50% efficiency)
# Different lanes may take different paths based on data
if input[global_i] > threshold: # Unpredictable branching
result = expensive_computation()
else:
result = simple_computation()
Performance: Random divergence kills warp efficiency
💀 TERRIBLE: Nested data-dependent divergence (~10-25% efficiency)
# Multiple levels of unpredictable branching
if input[global_i] > threshold1:
if input[global_i] > threshold2:
result = very_expensive()
else:
result = expensive()
else:
result = simple()
Performance: Warp efficiency destroyed
Cross-architecture compatibility
NVIDIA vs AMD warp sizes
from gpu.primitives.warp import WARP_SIZE
# NVIDIA GPUs: WARP_SIZE = 32
# AMD RDNA GPUs: WARP_SIZE = 32 (wavefront32 mode)
# AMD CDNA GPUs: WARP_SIZE = 64 (traditional wavefront64)
Why this matters:
- Memory patterns: Coalesced access depends on warp size
- Algorithm design: Reduction trees must account for warp size
- Performance scaling: Twice as many lanes per warp on AMD
Writing portable warp code
Architecture adaptation strategies
✅ PORTABLE: Always use WARP_SIZE
comptime THREADS_PER_BLOCK = (WARP_SIZE, 1) # Adapts automatically
comptime ELEMENTS_PER_WARP = WARP_SIZE # Scales with hardware
Result: Code works optimally on NVIDIA/AMD (32) and AMD (64)
❌ BROKEN: Never hardcode warp size
comptime THREADS_PER_BLOCK = (32, 1) # Breaks on AMD GPUs!
comptime REDUCTION_SIZE = 32 # Wrong on AMD!
Result: Suboptimal on AMD, potential correctness issues
Real hardware impact
| GPU Architecture | WARP_SIZE | Memory per Warp | Reduction Steps | Lane Pattern |
|---|---|---|---|---|
| NVIDIA/AMD RDNA | 32 | 128 bytes (4×32) | 5 steps: 32→16→8→4→2→1 | Lanes 0-31 |
| AMD CDNA | 64 | 256 bytes (4×64) | 6 steps: 64→32→16→8→4→2→1 | Lanes 0-63 |
Performance implications of 64 vs 32:
- CDNA advantage: 2× memory bandwidth per warp
- CDNA advantage: 2× computation per warp
- NVIDIA/RDNA advantage: More warps per block (better occupancy)
- Code portability: Same source, optimal performance on both
Memory access patterns with warps
Coalesced memory access patterns
✅ PERFECT: Coalesced access (100% bandwidth utilization)
# Adjacent lanes → adjacent memory addresses
var value = input[global_i] # Lane 0→input[0], Lane 1→input[1], etc.
Memory access patterns:
| Access Pattern | NVIDIA/RDNA (32 lanes) | CDNA (64 lanes) | Bandwidth Utilization | Performance |
|---|---|---|---|---|
| ✅ Coalesced | Lane N → Address 4×N | Lane N → Address 4×N | 100% | Optimal |
| 1 transaction: 128 bytes | 1 transaction: 256 bytes | Full bus width | Fast | |
| ❌ Scattered | Lane N → Random address | Lane N → Random address | ~6% | Terrible |
| 32 separate transactions | 64 separate transactions | Mostly idle bus | 32× slower |
Example addresses:
- Coalesced: Lane 0→0, Lane 1→4, Lane 2→8, Lane 3→12, …
- Scattered: Lane 0→1000, Lane 1→52, Lane 2→997, Lane 3→8, …
Shared memory bank conflicts
What is a bank conflict?
Assume that a GPU shared memory is divided into 32 independent banks that can be accessed simultaneously. A bank conflict occurs when multiple threads in a warp try to access different addresses within the same bank at the same time. When this happens, the hardware must serialize these accesses, turning what should be a single-cycle operation into multiple cycles.
Key concepts:
- No conflict: Each thread accesses a different bank → All accesses happen simultaneously (1 cycle)
- Bank conflict: Multiple threads access the same bank → Accesses happen sequentially (N cycles for N threads)
- Broadcast: All threads access the same address → Hardware optimizes this to 1 cycle
Shared memory bank organization:
| Bank | Addresses (byte offsets) | Example Data (float32) |
|---|---|---|
| Bank 0 | 0, 128, 256, 384, … | shared[0], shared[32], shared[64], … |
| Bank 1 | 4, 132, 260, 388, … | shared[1], shared[33], shared[65], … |
| Bank 2 | 8, 136, 264, 392, … | shared[2], shared[34], shared[66], … |
| … | … | … |
| Bank 31 | 124, 252, 380, 508, … | shared[31], shared[63], shared[95], … |
Bank conflict examples:
| Access Pattern | Bank Usage | Cycles | Performance | Explanation |
|---|---|---|---|---|
| ✅ Sequential | shared[thread_idx.x] | 1 cycle | 100% | Each lane hits different bank |
| Lane 0→Bank 0, Lane 1→Bank 1, … | Optimal | No conflicts | ||
| ✅ Same index | shared[0] | 1 cycle | 100% | All lanes broadcast from same address |
| All 32 lanes→Bank 0 (Same address) | Optimal | No conflicts | ||
| ❌ Stride 2 | shared[thread_idx.x * 2] | 2 cycles | 50% | 2 lanes per bank |
| Lane 0,16→Bank 0; Lane 1,17→Bank 1 | 2× slower | Serialized access | ||
| 💀 Stride 32 | shared[thread_idx.x * 32] | 32 cycles | 3% | All lanes hit same bank |
| All 32 lanes→Bank 0 (Different address) | 32× slower | Completely serialized |
Practical implications for warp programming
When warp operations are most effective
- Reduction operations:
sum(),max(), etc. - Broadcast operations:
shuffle_idx()to share values - Neighbor communication:
shuffle_down()for sliding windows - Prefix computations:
prefix_sum()for scan algorithms
Performance characteristics
| Operation Type | Traditional | Warp Operations |
|---|---|---|
| Reduction (32 elements) | ~20 instructions | 10 instructions |
| Memory traffic | High | Minimal |
| Synchronization cost | Expensive | Free |
| Code complexity | High | Low |
Next steps
Now that you understand the SIMT foundation, you’re ready to see how these
concepts enable powerful warp operations. The next section will show you how
sum() transforms complex reduction patterns into simple, efficient function
calls.
→ Continue to warp.sum() Essentials
warp.sum() Essentials - Warp-Level Dot Product
Implement the dot product we saw in puzzle 12 using
Mojo’s warp operations to replace complex shared memory patterns with simple
function calls. Each warp lane will process one element and use warp.sum() to
combine results automatically, demonstrating how warp programming transforms GPU
synchronization.
Key insight: The warp.sum() operation leverages SIMT execution to replace shared memory + barriers + tree reduction with a single hardware-accelerated instruction.
Key concepts
In this puzzle, you’ll learn:
- Warp-level reductions with
warp.sum() - SIMT execution model and lane synchronization
- Cross-architecture compatibility with
WARP_SIZE - Performance transformation from complex to simple patterns
- Lane ID management and conditional writes
The mathematical operation is a dot product (inner product): \[\Large \text{output}[0] = \sum_{i=0}^{N-1} a[i] \times b[i]\]
But the implementation teaches fundamental patterns for all warp-level GPU programming in Mojo.
Configuration
- Vector size:
SIZE = WARP_SIZE(32 or 64 depending on GPU architecture) - Data type:
DType.float32 - Block configuration:
(WARP_SIZE, 1)threads per block - Grid configuration:
(1, 1)blocks per grid - Layout:
row_major[SIZE]()(1D row-major)
The traditional complexity (from Puzzle 12)
Recall the complex approach from solutions/p12/p12.mojo that required shared memory, barriers, and tree reduction:
comptime SIZE = WARP_SIZE
comptime BLOCKS_PER_GRID = (1, 1)
comptime THREADS_PER_BLOCK = (WARP_SIZE, 1)
comptime dtype = DType.float32
comptime SIMD_WIDTH = simd_width_of[dtype]()
comptime in_layout = row_major[SIZE]()
comptime InLayoutType = type_of(in_layout)
comptime out_layout = row_major[1]()
comptime OutLayoutType = type_of(out_layout)
def traditional_dot_product_p12_style[
size: Int
](
output: TileTensor[mut=True, dtype, OutLayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, InLayoutType, ImmutAnyOrigin],
):
"""
This is the complex approach from p12_layout_tensor.mojo - kept for comparison.
"""
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[WARP_SIZE]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
if global_i < size:
shared[local_i] = (a[global_i] * b[global_i]).reduce_add()
else:
shared[local_i] = 0.0
barrier()
var stride = WARP_SIZE // 2
while stride > 0:
if local_i < stride:
shared[local_i] += shared[local_i + stride]
barrier()
stride //= 2
if local_i == 0:
output[global_i // WARP_SIZE] = shared[0]
What makes this complex:
- Shared memory allocation: Manual memory management within blocks
- Explicit barriers:
barrier()calls to synchronize threads - Tree reduction: Complex loop with stride-based indexing
- Conditional writes: Only thread 0 writes the final result
This works, but it’s verbose, error-prone, and requires deep understanding of GPU synchronization.
Test the traditional approach:
pixi run p24 --traditional
pixi run -e amd p24 --traditional
pixi run -e apple p24 --traditional
uv run poe p24 --traditional
Code to complete
1. Simple warp kernel approach
Transform the complex traditional approach into a simple warp kernel using
warp_sum():
def simple_warp_dot_product[
size: Int
](
output: TileTensor[mut=True, dtype, OutLayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, InLayoutType, ImmutAnyOrigin],
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
# FILL IN (6 lines at most)
View full file: problems/p24/p24.mojo
Tips
1. Understanding the simple warp kernel structure
You need to complete the simple_warp_dot_product function with
6 lines or fewer:
def simple_warp_dot_product[...](output, a, b):
global_i = block_dim.x * block_idx.x + thread_idx.x
# FILL IN (6 lines at most)
Pattern to follow:
- Compute partial product for this thread’s element
- Use
warp_sum()to combine across all warp lanes - Lane 0 writes the final result
2. Computing partial products
var partial_product: Scalar[dtype] = 0
if global_i < size:
partial_product = (a[global_i] * b[global_i]).reduce_add()
Why .reduce_add()? Values in Mojo are SIMD-based, so
a[global_i] * b[global_i] returns a SIMD vector. Use .reduce_add() to sum
the vector into a scalar.
Bounds checking: Essential because not all threads may have valid data to process.
3. Warp reduction magic
total = warp_sum(partial_product)
What warp_sum() does:
- Takes each lane’s
partial_productvalue - Sums them across all lanes in the warp (hardware-accelerated)
- Returns the same total to all lanes (not just lane 0)
- Requires zero explicit synchronization (SIMT handles it)
4. Writing the result
if lane_id() == 0:
output[global_i // WARP_SIZE] = total
Why only lane 0? All lanes have the same total value after warp_sum(),
but we only want to write once to avoid race conditions.
Why not write to output[0]? Flexibility, function can be used in cases
where there is more than one warp. i.e. The result from each warp is written to
the unique location global_i // WARP_SIZE.
lane_id(): Returns 0-31 (NVIDIA) or 0-63 (AMD) - identifies which lane
within the warp.
Test the simple warp kernel:
uv run poe p24 --kernel
pixi run p24 --kernel
Expected output when solved:
SIZE: 32
WARP_SIZE: 32
SIMD_WIDTH: 8
=== RESULT ===
out: 10416.0
expected: 10416.0
🚀 Notice how simple the warp version is compared to p12.mojo!
Same kernel structure, but warp_sum() replaces all the complexity!
Solution
def simple_warp_dot_product[
InLayoutT: TensorLayout, OutLayoutT: TensorLayout, size: Int
](
output: TileTensor[mut=True, dtype, OutLayoutT, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayoutT, MutAnyOrigin],
b: TileTensor[mut=False, dtype, InLayoutT, MutAnyOrigin],
):
var a_lt = a.to_layout_tensor()
var b_lt = b.to_layout_tensor()
var out_lt = output.to_layout_tensor()
var global_i = block_dim.x * block_idx.x + thread_idx.x
# Each thread computes one partial product using vectorized approach as values in Mojo are SIMD based
var partial_product: Scalar[dtype] = 0
if global_i < size:
partial_product = rebind[Scalar[dtype]](a_lt[global_i]) * rebind[
Scalar[dtype]
](b_lt[global_i])
# warp_sum() replaces all the shared memory + barriers + tree reduction
var total = warp_sum(partial_product)
# Only lane 0 writes the result (all lanes have the same total)
if lane_id() == 0:
out_lt.store[1](Index(global_i // WARP_SIZE), total)
The simple warp kernel demonstrates the fundamental transformation from complex synchronization to hardware-accelerated primitives:
What disappeared from the traditional approach:
- 15+ lines → 6 lines: Dramatic code reduction
- Shared memory allocation: Zero memory management required
- 3+ barrier() calls: Zero explicit synchronization
- Complex tree reduction: Single function call
- Stride-based indexing: Eliminated entirely
SIMT execution model:
Warp lanes (SIMT execution):
Lane 0: partial_product = a[0] * b[0] = 0.0
Lane 1: partial_product = a[1] * b[1] = 4.0
Lane 2: partial_product = a[2] * b[2] = 16.0
...
Lane 31: partial_product = a[31] * b[31] = 3844.0
warp_sum() hardware operation:
All lanes → 0.0 + 4.0 + 16.0 + ... + 3844.0 = 10416.0
All lanes receive → total = 10416.0 (broadcast result)
Why this works without barriers:
- SIMT execution: All lanes execute each instruction simultaneously
- Hardware synchronization: When
warp_sum()begins, all lanes have computed theirpartial_product - Built-in communication: GPU hardware handles the reduction operation
- Broadcast result: All lanes receive the same
totalvalue
2. Functional approach
Now implement the same warp dot product using Mojo’s functional programming patterns:
def functional_warp_dot_product[
dtype: DType,
simd_width: Int,
rank: Int,
size: Int,
](
output: TileTensor[mut=True, dtype, OutLayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayoutType, MutAnyOrigin],
b: TileTensor[mut=False, dtype, InLayoutType, MutAnyOrigin],
ctx: DeviceContext,
) raises:
@parameter
@always_inline
def compute_dot_product[
simd_width: Int, rank: Int, alignment: Int = align_of[dtype]()
](indices: IndexList[rank]) capturing -> None:
var idx = indices[0]
print("idx:", idx)
# FILL IN (10 lines at most)
# Launch exactly size == WARP_SIZE threads (one warp) to process all elements
elementwise[compute_dot_product, 1, target="gpu"](size, ctx)
Tips
1. Understanding the functional approach structure
You need to complete the compute_dot_product function with
10 lines or fewer:
@parameter
@always_inline
def compute_dot_product[simd_width: Int, rank: Int](indices: IndexList[rank]) capturing -> None:
idx = indices[0]
# FILL IN (10 lines at most)
Functional pattern differences:
- Uses
elementwiseto launch exactlyWARP_SIZEthreads - Each thread processes one element based on
idx - Same warp operations, different launch mechanism
2. Computing partial products
var partial_product: Scalar[dtype] = 0.0
if idx < size:
a_val = a.load[1](idx, 0)
b_val = b.load[1](idx, 0)
partial_product = (a_val * b_val).reduce_add()
else:
partial_product = 0.0
Loading pattern: a.load[1](idx, 0) loads exactly 1 element at position
idx (not SIMD vectorized).
Bounds handling: Set partial_product = 0.0 for out-of-bounds threads so
they don’t contribute to the sum.
3. Warp operations and storing
total = warp_sum(partial_product)
if lane_id() == 0:
output.store[1](Index(idx // WARP_SIZE), total)
Storage pattern: output.store[1](Index(idx // WARP_SIZE), 0, total) stores
1 element at position (idx // WARP_SIZE, 0) in the output tensor.
Same warp logic: warp_sum() and lane 0 writing work identically in
functional approach.
4. Available functions from imports
from gpu import lane_id
from gpu.primitives.warp import sum as warp_sum, WARP_SIZE
# Inside your function:
my_lane = lane_id() # 0 to WARP_SIZE-1
total = warp_sum(my_value) # Hardware-accelerated reduction
warp_size = WARP_SIZE # 32 (NVIDIA) or 64 (AMD)
Test the functional approach:
uv run poe p24 --functional
pixi run p24 --functional
Expected output when solved:
SIZE: 32
WARP_SIZE: 32
SIMD_WIDTH: 8
=== RESULT ===
out: 10416.0
expected: 10416.0
🔧 Functional approach shows modern Mojo style with warp operations!
Clean, composable, and still leverages warp hardware primitives!
Solution
def functional_warp_dot_product[
InLayoutT: TensorLayout,
OutLayoutT: TensorLayout,
dtype: DType,
simd_width: Int,
rank: Int,
size: Int,
](
output: TileTensor[mut=True, dtype, OutLayoutT, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayoutT, MutAnyOrigin],
b: TileTensor[mut=False, dtype, InLayoutT, MutAnyOrigin],
ctx: DeviceContext,
) raises:
@parameter
@always_inline
def compute_dot_product[
simd_width: Int, rank: Int, alignment: Int = align_of[dtype]()
](indices: IndexList[rank]) capturing -> None:
var idx = indices[0]
# Convert inside GPU kernel to avoid host-captured LayoutTensor issues
var a_lt = a.to_layout_tensor()
var b_lt = b.to_layout_tensor()
var out_lt = output.to_layout_tensor()
# Each thread computes one partial product
var partial_product: Scalar[dtype] = 0.0
if idx < size:
var a_val = a_lt.load[1](Index(idx))
var b_val = b_lt.load[1](Index(idx))
partial_product = rebind[Scalar[dtype]](a_val) * rebind[
Scalar[dtype]
](b_val)
else:
partial_product = 0.0
# Warp magic - combines all WARP_SIZE partial products!
var total = warp_sum(partial_product)
# Only lane 0 writes the result (all lanes have the same total)
if lane_id() == 0:
out_lt.store[1](Index(idx // WARP_SIZE), total)
# Launch exactly size == WARP_SIZE threads (one warp) to process all elements
elementwise[compute_dot_product, 1, target="gpu"](size, ctx)
The functional warp approach showcases modern Mojo programming patterns with warp operations:
Functional approach characteristics:
elementwise[compute_dot_product, 1, target="gpu"](size, ctx)
Benefits:
- Type safety: Compile-time tensor layout checking
- Composability: Easy integration with other functional operations
- Modern patterns: Leverages Mojo’s functional programming features
- Automatic optimization: Compiler can apply high-level optimizations
Key differences from kernel approach:
- Launch mechanism: Uses
elementwiseinstead ofenqueue_function - Memory access: Uses
.load[1]()and.store[1]()patterns - Integration: Seamlessly works with other functional operations
Same warp benefits:
- Zero synchronization:
warp_sum()works identically - Hardware acceleration: Same performance as kernel approach
- Cross-architecture:
WARP_SIZEadapts automatically
Performance comparison with benchmarks
Run comprehensive benchmarks to see how warp operations scale:
uv run poe p24 --benchmark
pixi run p24 --benchmark
Here’s example output from a complete benchmark run:
SIZE: 32
WARP_SIZE: 32
SIMD_WIDTH: 8
--------------------------------------------------------------------------------
Testing SIZE=1 x WARP_SIZE, BLOCKS=1
Running traditional_1x
Running simple_warp_1x
Running functional_warp_1x
--------------------------------------------------------------------------------
Testing SIZE=4 x WARP_SIZE, BLOCKS=4
Running traditional_4x
Running simple_warp_4x
Running functional_warp_4x
--------------------------------------------------------------------------------
Testing SIZE=32 x WARP_SIZE, BLOCKS=32
Running traditional_32x
Running simple_warp_32x
Running functional_warp_32x
--------------------------------------------------------------------------------
Testing SIZE=256 x WARP_SIZE, BLOCKS=256
Running traditional_256x
Running simple_warp_256x
Running functional_warp_256x
--------------------------------------------------------------------------------
Testing SIZE=2048 x WARP_SIZE, BLOCKS=2048
Running traditional_2048x
Running simple_warp_2048x
Running functional_warp_2048x
--------------------------------------------------------------------------------
Testing SIZE=16384 x WARP_SIZE, BLOCKS=16384 (Large Scale)
Running traditional_16384x
Running simple_warp_16384x
Running functional_warp_16384x
--------------------------------------------------------------------------------
Testing SIZE=65536 x WARP_SIZE, BLOCKS=65536 (Massive Scale)
Running traditional_65536x
Running simple_warp_65536x
Running functional_warp_65536x
| name | met (ms) | iters |
| ---------------------- | --------------------- | ----- |
| traditional_1x | 0.00460128 | 100 |
| simple_warp_1x | 0.00574047 | 100 |
| functional_warp_1x | 0.00484192 | 100 |
| traditional_4x | 0.00492671 | 100 |
| simple_warp_4x | 0.00485247 | 100 |
| functional_warp_4x | 0.00587679 | 100 |
| traditional_32x | 0.0062406399999999996 | 100 |
| simple_warp_32x | 0.0054918400000000004 | 100 |
| functional_warp_32x | 0.00552447 | 100 |
| traditional_256x | 0.0050614300000000004 | 100 |
| simple_warp_256x | 0.00488768 | 100 |
| functional_warp_256x | 0.00461472 | 100 |
| traditional_2048x | 0.01120031 | 100 |
| simple_warp_2048x | 0.00884383 | 100 |
| functional_warp_2048x | 0.007038720000000001 | 100 |
| traditional_16384x | 0.038533750000000005 | 100 |
| simple_warp_16384x | 0.0323264 | 100 |
| functional_warp_16384x | 0.01674271 | 100 |
| traditional_65536x | 0.19784991999999998 | 100 |
| simple_warp_65536x | 0.12870176 | 100 |
| functional_warp_65536x | 0.048680310000000004 | 100 |
Benchmarks completed!
WARP OPERATIONS PERFORMANCE ANALYSIS:
GPU Architecture: NVIDIA (WARP_SIZE=32) vs AMD (WARP_SIZE=64)
- 1,...,256 x WARP_SIZE: Grid size too small to benchmark
- 2048 x WARP_SIZE: Warp primative benefits emerge
- 16384 x WARP_SIZE: Large scale (512K-1M elements)
- 65536 x WARP_SIZE: Massive scale (2M-4M elements)
Expected Results at Large Scales:
• Traditional: Slower due to more barrier overhead
• Warp operations: Faster, scale better with problem size
• Memory bandwidth becomes the limiting factor
Performance insights from this example:
- Small scales (1x-4x): Warp operations show modest improvements (~10-15% faster)
- Medium scale (32x-256x): Functional approach often performs best
- Large scales (16K-65K): All approaches converge as memory bandwidth dominates
- Variability: Performance depends heavily on specific GPU architecture and memory subsystem
Note: Your results will vary significantly depending on your hardware (GPU
model, memory bandwidth, WARP_SIZE). The key insight is observing the relative
performance trends rather than absolute timings.
Next steps
Once you’ve learned warp sum operations, you’re ready for:
- When to Use Warp Programming: Strategic decision framework for warp vs traditional approaches
- Advanced warp operations:
shuffle_idx(),shuffle_down(),prefix_sum()for complex communication patterns - Multi-warp algorithms: Combining warp operations with block-level synchronization
- Part VII: Memory Coalescing: Optimizing memory access patterns for maximum bandwidth
💡 Key Takeaway: Warp operations transform GPU programming by replacing complex synchronization patterns with hardware-accelerated primitives, demonstrating how understanding the execution model enables dramatic simplification without sacrificing performance.
When to Use Warp Programming
Quick decision guide
✅ Use warp operations when:
- Reduction operations (
sum,max,min) with 32+ elements - Regular memory access patterns (adjacent lanes → adjacent addresses)
- Need cross-architecture portability (NVIDIA/RDNA 32 vs CDNA 64 threads)
- Want simpler, more maintainable code
❌ Use traditional approaches when:
- Complex cross-warp synchronization required
- Irregular/scattered memory access patterns
- Variable work per thread (causes warp divergence)
- Problem
size < WARP_SIZE
Performance characteristics
Problem size scaling
| Elements | Warp Advantage | Notes |
|---|---|---|
| < 32 | None | Traditional better |
| 32-1K | 1.2-1.5× | Sweet spot begins |
| 1K-32K | 1.5-2.5× | Warp operations excel |
| > 32K | Memory-bound | Both approaches limited by bandwidth |
Key warp advantages
- No synchronization overhead: Eliminates barrier costs
- Minimal memory usage: No shared memory allocation needed
- Better scaling: Performance improves with more warps
- Simpler code: Fewer lines, less error-prone
Algorithm-specific guidance
| Algorithm | Recommendation | Reason |
|---|---|---|
| Dot product | Warp ops (1K+ elements) | Single reduction, regular access |
| Matrix row/col sum | Warp ops | Natural reduction pattern |
| Prefix sum | Always warp prefix_sum() | Hardware-optimized primitive |
| Pooling (max/min) | Warp ops (regular windows) | Efficient window reductions |
| Histogram with large number of bins | Traditional | Irregular writes, atomic updates |
Code examples
✅ Perfect for warps
# Reduction operations
from gpu.primitives.warp import sum, max
var total = sum(partial_values)
var maximum = max(partial_values)
# Communication patterns
from gpu.primitives.warp import shuffle_idx, prefix_sum
var broadcast = shuffle_idx(my_value, 0)
var running_sum = prefix_sum(my_value)
❌ Better with traditional approaches
# Complex multi-stage synchronization
stage1_compute()
barrier() # Need ALL threads to finish
stage2_depends_on_stage1()
# Irregular memory access
var value = input[random_indices[global_i]] # Scattered reads
# Data-dependent work
if input[global_i] > threshold:
result = expensive_computation() # Causes warp divergence
Performance measurement
# Always benchmark both approaches
mojo p22.mojo --benchmark
# Look for scaling patterns:
# traditional_1x: X.XX ms
# warp_1x: Y.YY ms # Should be faster
# warp_32x: Z.ZZ ms # Advantage should increase
Summary
Start with warp operations for:
- Reductions with regular access patterns
- Problems ≥ 1 warp in size
- Cross-platform compatibility needs
Use traditional approaches for:
- Complex synchronization requirements
- Irregular memory patterns
- Small problems or heavy divergence
When in doubt: Implement both and benchmark. The performance difference will guide your decision.
Puzzle 25: Warp Communication
Overview
Puzzle 25: Warp Communication Primitives introduces advanced GPU warp-level communication operations - hardware-accelerated primitives that enable efficient data exchange and coordination patterns within warps. You’ll learn about using shuffle_down and broadcast to implement neighbor communication and collective coordination without complex shared memory patterns.
Part VII: GPU Warp Communication introduces warp-level data movement operations within thread groups. You’ll learn to replace complex shared memory + indexing + boundary checking patterns with efficient warp communication calls that leverage hardware-optimized data movement.
Key insight: GPU warps execute in lockstep - Mojo’s warp communication operations use this synchronization to provide efficient data exchange primitives with automatic boundary handling and zero explicit synchronization.
What you’ll learn
Warp communication model
Understand the fundamental communication patterns within GPU warps:
GPU Warp (32 threads, SIMT lockstep execution)
├── Lane 0 ──shuffle_down──> Lane 1 ──shuffle_down──> Lane 2
├── Lane 1 ──shuffle_down──> Lane 2 ──shuffle_down──> Lane 3
├── Lane 2 ──shuffle_down──> Lane 3 ──shuffle_down──> Lane 4
│ ...
└── Lane 31 ──shuffle_down──> undefined (boundary)
Broadcast pattern:
Lane 0 ──broadcast──> All lanes (0, 1, 2, ..., 31)
Hardware reality:
- Register-to-register communication: Data moves directly between thread registers
- Zero memory overhead: No shared memory allocation required
- Automatic boundary handling: Hardware manages warp edge cases
- Single-cycle operations: Communication happens in one instruction cycle
Warp communication operations in Mojo
Learn the core communication primitives from gpu.primitives.warp:
shuffle_down(value, offset): Get value from lane at higher index (neighbor access)broadcast(value): Share lane 0’s value with all other lanes (one-to-many)shuffle_idx(value, lane): Get value from specific lane (random access)shuffle_up(value, offset): Get value from lane at lower index (reverse neighbor)
Note: This puzzle focuses on
shuffle_down()andbroadcast()as the most commonly used communication patterns. For complete coverage of all warp operations, see the Mojo GPU Warp Documentation.
Performance transformation example
# Complex neighbor access pattern (traditional approach):
shared = TileTensor[
dtype,
row_major[WARP_SIZE](),
MutAnyOrigin,
address_space = AddressSpace.SHARED,
].stack_allocation()
shared[local_i] = input[global_i]
barrier()
if local_i < WARP_SIZE - 1:
next_value = shared[local_i + 1] # Neighbor access
result = next_value - shared[local_i]
else:
result = 0 # Boundary handling
barrier()
# Warp communication eliminates all this complexity:
current_val = input[global_i]
next_val = shuffle_down(current_val, 1) # Direct neighbor access
if lane < WARP_SIZE - 1:
result = next_val - current_val
else:
result = 0
When warp communication excels
Learn the performance characteristics:
| Communication Pattern | Traditional | Warp Operations |
|---|---|---|
| Neighbor access | Shared memory | Register-to-register |
| Stencil operations | Complex indexing | Simple shuffle patterns |
| Block coordination | Barriers + shared | Single broadcast |
| Boundary handling | Manual checks | Hardware automatic |
Prerequisites
Before diving into warp communication, ensure you’re comfortable with:
- Part VII warp fundamentals: Understanding SIMT execution and basic warp operations (see Puzzle 24)
- GPU thread hierarchy: Blocks, warps, and lane numbering
- TileTensor operations: Loading, storing, and tensor manipulation
- Boundary condition handling: Managing edge cases in parallel algorithms
Learning path
1. Neighbor communication with shuffle_down
Learn neighbor-based communication patterns for stencil operations and finite differences.
What you’ll learn:
- Using
shuffle_down()for accessing adjacent lane data - Implementing finite differences and moving averages
- Handling warp boundaries automatically
- Multi-offset shuffling for extended neighbor access
Key pattern:
current_val = input[global_i]
next_val = shuffle_down(current_val, 1)
if lane < WARP_SIZE - 1:
result = compute_with_neighbors(current_val, next_val)
2. Collective coordination with broadcast
Learn one-to-many communication patterns for block-level coordination and collective decision-making.
What you’ll learn:
- Using
broadcast()for sharing computed values across lanes - Implementing block-level statistics and collective decisions
- Combining broadcast with conditional logic
- Advanced broadcast-shuffle coordination patterns
Key pattern:
var shared_value = 0.0
if lane == 0:
shared_value = compute_block_statistic()
shared_value = broadcast(shared_value)
result = use_shared_value(shared_value, local_data)
Key concepts
Communication patterns
Understanding fundamental warp communication paradigms:
- Neighbor communication: Lane-to-adjacent-lane data exchange
- Collective coordination: One-lane-to-all-lanes information sharing
- Stencil operations: Accessing fixed patterns of neighboring data
- Boundary handling: Managing communication at warp edges
Hardware optimization
Recognizing how warp communication maps to GPU hardware:
- Register file communication: Direct inter-thread register access
- SIMT execution: All lanes execute communication simultaneously
- Zero latency: Communication happens within the execution unit
- Automatic synchronization: No explicit barriers needed
Algorithm transformation
Converting traditional parallel patterns to warp communication:
- Array neighbor access →
shuffle_down() - Shared memory coordination →
broadcast() - Complex boundary logic → Hardware-handled edge cases
- Multi-stage synchronization → Single communication operations
Getting started
Start with neighbor-based shuffle operations to understand the foundation, then progress to collective broadcast patterns for advanced coordination.
💡 Success tip: Think of warp communication as hardware-accelerated message passing between threads in the same warp. This mental model will guide you toward efficient communication patterns that leverage the GPU’s SIMT architecture.
Learning objective: By the end of Puzzle 25, you’ll recognize when warp communication can replace complex shared memory patterns, enabling you to write simpler, faster neighbor-based and coordination algorithms.
Begin with: Warp Shuffle Down Operations to learn neighbor communication, then advance to Warp Broadcast Operations for collective coordination patterns.
warp.shuffle_down() One-to-One Communication
For warp-level neighbor communication we can use shuffle_down() to access data
from adjacent lanes within a warp. This powerful primitive enables efficient
finite differences, moving averages, and neighbor-based computations without
shared memory or explicit synchronization.
Key insight: The shuffle_down() operation leverages SIMT execution to let each lane access data from its neighbors within the same warp, enabling efficient stencil patterns and sliding window operations.
What are stencil operations? Stencil operations are computations where each output element depends on a fixed pattern of neighboring input elements. Common examples include finite differences (derivatives), convolutions, and moving averages. The “stencil” refers to the pattern of neighbor access - like a 3-point stencil that reads
[i-1, i, i+1]or a 5-point stencil that reads[i-2, i-1, i, i+1, i+2].
Key concepts
In this puzzle, you’ll learn:
- Warp-level data shuffling with
shuffle_down() - Neighbor access patterns for stencil computations
- Boundary handling at warp edges
- Multi-offset shuffling for extended neighbor access
- Cross-warp coordination in multi-block scenarios
The shuffle_down operation enables each lane to access data from lanes at
higher indices: \[\Large \text{shuffle_down}(\text{value}, \text{offset}) =
\text{value_from_lane}(\text{lane_id} + \text{offset})\]
This transforms complex neighbor access patterns into simple warp-level operations, enabling efficient stencil computations without explicit memory indexing.
1. Basic neighbor difference
Configuration
- Vector size:
SIZE = WARP_SIZE(32 or 64 depending on GPU) - Grid configuration:
(1, 1)blocks per grid - Block configuration:
(WARP_SIZE, 1)threads per block - Data type:
DType.float32 - Layout:
row_major[SIZE]()(1D row-major)
The shuffle_down concept
Traditional neighbor access requires complex indexing and bounds checking:
# Traditional approach - complex and error-prone
if global_i < size - 1:
next_value = input[global_i + 1] # Potential out-of-bounds
result = next_value - current_value
Problems with traditional approach:
- Bounds checking: Must manually verify array bounds
- Memory access: Requires separate memory loads
- Synchronization: May need barriers for shared memory patterns
- Complex logic: Handling edge cases becomes verbose
With shuffle_down(), neighbor access becomes elegant:
# Warp shuffle approach - simple and safe
current_val = input[global_i]
next_val = shuffle_down(current_val, 1) # Get value from lane+1
if lane < WARP_SIZE - 1:
result = next_val - current_val
Benefits of shuffle_down:
- Zero memory overhead: No additional memory accesses
- Automatic bounds: Hardware handles warp boundaries
- No synchronization: SIMT execution guarantees correctness
- Composable: Easy to combine with other warp operations
Code to complete
Implement finite differences using shuffle_down() to access the next element.
Mathematical operation: Compute the discrete derivative (finite difference) for each element: \[\Large \text{output}[i] = \text{input}[i+1] - \text{input}[i]\]
This transforms input data [0, 1, 4, 9, 16, 25, ...] (squares: i * i) into
differences [1, 3, 5, 7, 9, ...] (odd numbers), effectively computing the
discrete derivative of the quadratic function.
comptime SIZE = WARP_SIZE
comptime BLOCKS_PER_GRID = (1, 1)
comptime THREADS_PER_BLOCK = (WARP_SIZE, 1)
comptime dtype = DType.float32
comptime layout = row_major[SIZE]()
comptime LayoutType = type_of(layout)
def neighbor_difference[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
"""
Compute finite differences: output[i] = input[i+1] - input[i]
Uses shuffle_down(val, 1) to get the next neighbor's value.
Works across multiple blocks, each processing one warp worth of data.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var lane = Int(lane_id())
# FILL IN (roughly 7 lines)
View full file: problems/p25/p25.mojo
Tips
1. Understanding shuffle_down
The shuffle_down(value, offset) operation allows each lane to receive data
from a lane at a higher index. Study how this can give you access to neighboring
elements without explicit memory loads.
What shuffle_down(val, 1) does:
- Lane 0 gets value from Lane 1
- Lane 1 gets value from Lane 2
- …
- Lane 30 gets value from Lane 31
- Lane 31 gets undefined value (handled by boundary check)
2. Warp boundary considerations
Consider what happens at the edges of a warp. Some lanes may not have valid neighbors to access via shuffle operations.
Challenge: Design your algorithm to handle cases where shuffle operations may return undefined data for lanes at warp boundaries.
For neighbor difference with WARP_SIZE = 32:
-
Valid difference (
lane < WARP_SIZE - 1): Lanes 0-30 (31 lanes)- When: \(\text{lane_id}() \in {0, 1, \cdots, 30}\)
- Why:
shuffle_down(current_val, 1)successfully gets next neighbor’s value - Result:
output[i] = input[i+1] - input[i](finite difference)
-
Boundary case (else): Lane 31 (1 lane)
- When: \(\text{lane_id}() = 31\)
- Why:
shuffle_down(current_val, 1)returns undefined data (no lane 32) - Result:
output[i] = 0(cannot compute difference)
3. Lane identification
lane = lane_id() # Returns 0 to WARP_SIZE-1
Lane numbering: Within each warp, lanes are numbered 0, 1, 2,…,
WARP_SIZE-1
Test the neighbor difference:
pixi run p25 --neighbor
pixi run -e amd p25 --neighbor
pixi run -e apple p25 --neighbor
uv run poe p25 --neighbor
Expected output when solved:
WARP_SIZE: 32
SIZE: 32
output: [1.0, 3.0, 5.0, 7.0, 9.0, 11.0, 13.0, 15.0, 17.0, 19.0, 21.0, 23.0, 25.0, 27.0, 29.0, 31.0, 33.0, 35.0, 37.0, 39.0, 41.0, 43.0, 45.0, 47.0, 49.0, 51.0, 53.0, 55.0, 57.0, 59.0, 61.0, 0.0]
expected: [1.0, 3.0, 5.0, 7.0, 9.0, 11.0, 13.0, 15.0, 17.0, 19.0, 21.0, 23.0, 25.0, 27.0, 29.0, 31.0, 33.0, 35.0, 37.0, 39.0, 41.0, 43.0, 45.0, 47.0, 49.0, 51.0, 53.0, 55.0, 57.0, 59.0, 61.0, 0.0]
✅ Basic neighbor difference test passed!
Solution
def neighbor_difference[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, MutAnyOrigin],
):
"""
Compute finite differences: output[i] = input[i+1] - input[i]
Uses shuffle_down(val, 1) to get the next neighbor's value.
Works across multiple blocks, each processing one warp worth of data.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var lane = Int(lane_id())
if global_i < size:
# Get current value
var current_val = input[global_i]
# Get next neighbor's value using shuffle_down
var next_val = shuffle_down(current_val, 1)
# Compute difference - valid within warp boundaries
# Last lane of each warp has no valid neighbor within the warp
# Note there's only one warp in this test, so we don't need to check global_i < size - 1
# We'll see how this works with multiple blocks in the next tests
if lane < WARP_SIZE - 1:
output[global_i] = next_val - current_val
else:
# Last thread in warp or last thread overall, set to 0
output[global_i] = 0
This solution demonstrates how shuffle_down() transforms traditional array
indexing into efficient warp-level communication.
Algorithm breakdown:
if global_i < size:
current_val = input[global_i] # Each lane reads its element
next_val = shuffle_down(current_val, 1) # Hardware shifts data right
if lane < WARP_SIZE - 1:
output[global_i] = next_val - current_val # Compute difference
else:
output[global_i] = 0 # Boundary handling
SIMT execution deep dive:
Cycle 1: All lanes load their values simultaneously
Lane 0: current_val = input[0] = 0
Lane 1: current_val = input[1] = 1
Lane 2: current_val = input[2] = 4
...
Lane 31: current_val = input[31] = 961
Cycle 2: shuffle_down(current_val, 1) executes on all lanes
Lane 0: receives current_val from Lane 1 → next_val = 1
Lane 1: receives current_val from Lane 2 → next_val = 4
Lane 2: receives current_val from Lane 3 → next_val = 9
...
Lane 30: receives current_val from Lane 31 → next_val = 961
Lane 31: receives undefined (no Lane 32) → next_val = ?
Cycle 3: Difference computation (lanes 0-30 only)
Lane 0: output[0] = 1 - 0 = 1
Lane 1: output[1] = 4 - 1 = 3
Lane 2: output[2] = 9 - 4 = 5
...
Lane 31: output[31] = 0 (boundary condition)
Mathematical insight: This implements the discrete derivative operator \(D\): \[\Large D\lbrack f\rbrack(i) = f(i+1) - f(i)\]
For our quadratic input \(f(i) = i^2\): \[\Large D[i^2] = (i+1)^2 - i^2 = i^2 + 2i + 1 - i^2 = 2i + 1\]
Why shuffle_down is superior:
- Memory efficiency: Traditional approach requires
input[global_i + 1]load, potentially causing cache misses - Bounds safety: No risk of out-of-bounds access; hardware handles warp boundaries
- SIMT optimization: Single instruction processes all lanes simultaneously
- Register communication: Data moves between registers, not through memory hierarchy
Performance characteristics:
- Latency: 1 cycle (vs 100+ cycles for memory access)
- Bandwidth: 0 bytes (vs 4 bytes per thread for traditional)
- Parallelism: All 32 lanes process simultaneously
2. Multi-offset moving average
Configuration
- Vector size:
SIZE_2 = 64(multi-block scenario) - Grid configuration:
BLOCKS_PER_GRID = (2, 1)blocks per grid - Block configuration:
THREADS_PER_BLOCK = (WARP_SIZE, 1)threads per block
Code to complete
Implement a 3-point moving average using multiple shuffle_down operations.
Mathematical operation: Compute a sliding window average using three consecutive elements: \[\Large \text{output}[i] = \frac{1}{3}\left(\text{input}[i] + \text{input}[i+1] + \text{input}[i+2]\right)\]
Boundary handling: The algorithm gracefully degrades at warp boundaries:
- Full 3-point window: \(\text{output}[i] = \frac{1}{3}\sum_{k=0}^{2} \text{input}[i+k]\) when all neighbors available
- 2-point window: \(\text{output}[i] = \frac{1}{2}\sum_{k=0}^{1} \text{input}[i+k]\) when only next neighbor available
- 1-point window: \(\text{output}[i] = \text{input}[i]\) when no neighbors available
This demonstrates how shuffle_down() enables efficient stencil operations with
automatic boundary handling within warp limits.
comptime SIZE_2 = 64
comptime BLOCKS_PER_GRID_2 = (2, 1)
comptime THREADS_PER_BLOCK_2 = (WARP_SIZE, 1)
comptime layout_2 = row_major[SIZE_2]()
comptime LayoutType_2 = type_of(layout_2)
def moving_average_3[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType_2, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType_2, ImmutAnyOrigin],
):
"""
Compute 3-point moving average: output[i] = (input[i] + input[i+1] + input[i+2]) / 3
Uses shuffle_down with offsets 1 and 2 to access neighbors.
Works within warp boundaries across multiple blocks.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var lane = Int(lane_id())
# FILL IN (roughly 10 lines)
Tips
1. Multi-offset shuffle patterns
This puzzle requires accessing multiple neighbors simultaneously. You’ll need to use shuffle operations with different offsets.
Key questions:
- How can you get both
input[i+1]andinput[i+2]using shuffle operations? - What’s the relationship between shuffle offset and neighbor distance?
- Can you perform multiple shuffles on the same source value?
Visualization concept:
Your lane needs: current_val, next_val, next_next_val
Shuffle offsets: 0 (direct), 1, 2
Think about: How many shuffle operations do you need, and what offsets should you use?
2. Tiered boundary handling
Unlike the simple neighbor difference, this puzzle has multiple boundary scenarios because you need access to 2 neighbors.
Boundary scenarios to consider:
- Full window: Lane can access both neighbors → use all 3 values
- Partial window: Lane can access 1 neighbor → use 2 values
- No window: Lane can’t access any neighbors → use 1 value
Critical thinking:
- Which lanes fall into each category?
- How should you weight the averages when you have fewer values?
- What boundary conditions should you check?
Pattern to consider:
if (can_access_both_neighbors):
# 3-point average
elif (can_access_one_neighbor):
# 2-point average
else:
# 1-point (no averaging)
3. Multi-block coordination
This puzzle uses multiple blocks, each processing a different section of the data.
Important considerations:
- Each block has its own warp with lanes 0 to WARP_SIZE-1
- Boundary conditions apply within each warp independently
- Lane numbering resets for each block
Questions to think about:
- Does your boundary logic work correctly for both Block 0 and Block 1?
- Are you checking both lane boundaries AND global array boundaries?
- How does
global_irelate tolane_id()in different blocks?
Debugging tip: Test your logic by tracing through what happens at the boundary lanes of each block.
Test the moving average:
pixi run p25 --average
pixi run -e amd p25 --average
uv run poe p25 --average
Expected output when solved:
WARP_SIZE: 32
SIZE_2: 64
output: HostBuffer([3.3333333, 6.3333335, 10.333333, 15.333333, 21.333334, 28.333334, 36.333332, 45.333332, 55.333332, 66.333336, 78.333336, 91.333336, 105.333336, 120.333336, 136.33333, 153.33333, 171.33333, 190.33333, 210.33333, 231.33333, 253.33333, 276.33334, 300.33334, 325.33334, 351.33334, 378.33334, 406.33334, 435.33334, 465.33334, 496.33334, 512.0, 528.0, 595.3333, 630.3333, 666.3333, 703.3333, 741.3333, 780.3333, 820.3333, 861.3333, 903.3333, 946.3333, 990.3333, 1035.3334, 1081.3334, 1128.3334, 1176.3334, 1225.3334, 1275.3334, 1326.3334, 1378.3334, 1431.3334, 1485.3334, 1540.3334, 1596.3334, 1653.3334, 1711.3334, 1770.3334, 1830.3334, 1891.3334, 1953.3334, 2016.3334, 2048.0, 2080.0])
expected: HostBuffer([3.3333333, 6.3333335, 10.333333, 15.333333, 21.333334, 28.333334, 36.333332, 45.333332, 55.333332, 66.333336, 78.333336, 91.333336, 105.333336, 120.333336, 136.33333, 153.33333, 171.33333, 190.33333, 210.33333, 231.33333, 253.33333, 276.33334, 300.33334, 325.33334, 351.33334, 378.33334, 406.33334, 435.33334, 465.33334, 496.33334, 512.0, 528.0, 595.3333, 630.3333, 666.3333, 703.3333, 741.3333, 780.3333, 820.3333, 861.3333, 903.3333, 946.3333, 990.3333, 1035.3334, 1081.3334, 1128.3334, 1176.3334, 1225.3334, 1275.3334, 1326.3334, 1378.3334, 1431.3334, 1485.3334, 1540.3334, 1596.3334, 1653.3334, 1711.3334, 1770.3334, 1830.3334, 1891.3334, 1953.3334, 2016.3334, 2048.0, 2080.0])
✅ Moving average test passed!
Solution
def moving_average_3[
size: Int
](
output: TileTensor[mut=True, dtype, Layout2Type, MutAnyOrigin],
input: TileTensor[mut=False, dtype, Layout2Type, MutAnyOrigin],
):
"""
Compute 3-point moving average: output[i] = (input[i] + input[i+1] + input[i+2]) / 3
Uses shuffle_down with offsets 1 and 2 to access neighbors.
Works within warp boundaries across multiple blocks.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var lane = Int(lane_id())
if global_i < size:
# Get current, next, and next+1 values
var current_val = input[global_i]
var next_val = shuffle_down(current_val, 1)
var next_next_val = shuffle_down(current_val, 2)
# Compute 3-point average - valid within warp boundaries
if lane < WARP_SIZE - 2 and global_i < size - 2:
output[global_i] = (current_val + next_val + next_next_val) / 3.0
elif lane < WARP_SIZE - 1 and global_i < size - 1:
# Second-to-last in warp: only current + next available
output[global_i] = (current_val + next_val) / 2.0
else:
# Last thread in warp or boundary cases: only current available
output[global_i] = current_val
This solution demonstrates advanced multi-offset shuffling for complex stencil operations.
Complete algorithm analysis:
if global_i < size:
# Step 1: Acquire all needed data via multiple shuffles
current_val = input[global_i] # Direct access
next_val = shuffle_down(current_val, 1) # Right neighbor
next_next_val = shuffle_down(current_val, 2) # Right+1 neighbor
# Step 2: Adaptive computation based on available data
if lane < WARP_SIZE - 2 and global_i < size - 2:
# Full 3-point stencil available
output[global_i] = (current_val + next_val + next_next_val) / 3.0
elif lane < WARP_SIZE - 1 and global_i < size - 1:
# Only 2-point stencil available (near warp boundary)
output[global_i] = (current_val + next_val) / 2.0
else:
# No stencil possible (at warp boundary)
output[global_i] = current_val
Multi-offset execution trace (WARP_SIZE = 32):
Initial state (Block 0, elements 0-31):
Lane 0: current_val = input[0] = 1
Lane 1: current_val = input[1] = 2
Lane 2: current_val = input[2] = 4
...
Lane 31: current_val = input[31] = X
First shuffle: shuffle_down(current_val, 1)
Lane 0: next_val = input[1] = 2
Lane 1: next_val = input[2] = 4
Lane 2: next_val = input[3] = 7
...
Lane 30: next_val = input[31] = X
Lane 31: next_val = undefined
Second shuffle: shuffle_down(current_val, 2)
Lane 0: next_next_val = input[2] = 4
Lane 1: next_next_val = input[3] = 7
Lane 2: next_next_val = input[4] = 11
...
Lane 29: next_next_val = input[31] = X
Lane 30: next_next_val = undefined
Lane 31: next_next_val = undefined
Computation phase:
Lanes 0-29: Full 3-point average → (current + next + next_next) / 3
Lane 30: 2-point average → (current + next) / 2
Lane 31: 1-point average → current (passthrough)
Mathematical foundation: This implements a variable-width discrete convolution: \[\Large h[i] = \sum_{k=0}^{K(i)-1} w_k^{(i)} \cdot f[i+k]\]
Where the kernel adapts based on position:
- Interior points: \(K(i) = 3\), \(\mathbf{w}^{(i)} = [\frac{1}{3}, \frac{1}{3}, \frac{1}{3}]\)
- Near boundary: \(K(i) = 2\), \(\mathbf{w}^{(i)} = [\frac{1}{2}, \frac{1}{2}]\)
- At boundary: \(K(i) = 1\), \(\mathbf{w}^{(i)} = [1]\)
Multi-block coordination: With SIZE_2 = 64 and 2 blocks:
Block 0 (global indices 0-31):
Lane boundaries apply to global indices 29, 30, 31
Block 1 (global indices 32-63):
Lane boundaries apply to global indices 61, 62, 63
Lane numbers reset: global_i=32 → lane=0, global_i=63 → lane=31
Performance optimizations:
- Parallel data acquisition: Both shuffle operations execute simultaneously
- Conditional branching: GPU handles divergent lanes efficiently via predication
- Memory coalescing: Sequential global memory access pattern optimal for GPU
- Register reuse: All intermediate values stay in registers
Signal processing perspective: This is a causal FIR filter with impulse response \(h[n] = \frac{1}{3}[\delta[n] + \delta[n-1] + \delta[n-2]]\), providing smoothing with a cutoff frequency at \(f_c \approx 0.25f_s\).
Summary
Here is what the core pattern of this section looks like
current_val = input[global_i]
neighbor_val = shuffle_down(current_val, offset)
if lane < WARP_SIZE - offset:
result = compute(current_val, neighbor_val)
Key benefits:
- Hardware efficiency: Register-to-register communication
- Boundary safety: Automatic warp limit handling
- SIMT optimization: Single instruction, all lanes parallel
Applications: Finite differences, stencil operations, moving averages, convolutions.
warp.broadcast() One-to-Many Communication
For warp-level coordination we can use broadcast() to share data from one lane
to all other lanes within a warp. This powerful primitive enables efficient
block-level computations, conditional logic coordination, and one-to-many
communication patterns without shared memory or explicit synchronization.
Key insight: The broadcast() operation leverages SIMT execution to let one lane (typically lane 0) share its computed value with all other lanes in the same warp, enabling efficient coordination patterns and collective decision-making.
What are broadcast operations? Broadcast operations are communication patterns where one thread computes a value and shares it with all other threads in a group. This is essential for coordination tasks like computing block-level statistics, making collective decisions, or sharing configuration parameters across all threads in a warp.
Key concepts
In this puzzle, you’ll learn:
- Warp-level broadcasting with
broadcast() - One-to-many communication patterns
- Collective computation strategies
- Conditional coordination across lanes
- Combined broadcast-shuffle operations
The broadcast operation enables one lane (by default lane 0) to share its
value with all other lanes: \[\Large \text{broadcast}(\text{value}) =
\text{value_from_lane_0_to_all_lanes}\]
This transforms complex coordination patterns into simple warp-level operations, enabling efficient collective computations without explicit synchronization.
The broadcast concept
Traditional coordination requires complex shared memory patterns:
# Traditional approach - complex and error-prone
shared_memory[lane] = local_computation()
sync_threads() # Expensive synchronization
if lane == 0:
result = compute_from_shared_memory()
sync_threads() # Another expensive synchronization
final_result = shared_memory[0] # All threads read
Problems with traditional approach:
- Memory overhead: Requires shared memory allocation
- Synchronization: Multiple expensive barrier operations
- Complex logic: Managing shared memory indices and access patterns
- Error-prone: Easy to introduce race conditions
With broadcast(), coordination becomes elegant:
# Warp broadcast approach - simple and safe
collective_value = 0
if lane == 0:
collective_value = compute_block_statistic()
collective_value = broadcast(collective_value) # Share with all lanes
result = use_collective_value(collective_value)
Benefits of broadcast:
- Zero memory overhead: No shared memory required
- Automatic synchronization: SIMT execution guarantees correctness
- Simple pattern: One lane computes, all lanes receive
- Composable: Easy to combine with other warp operations
1. Basic broadcast
Implement a basic broadcast pattern where lane 0 computes a block-level statistic and shares it with all lanes.
Requirements:
- Lane 0 should compute the sum of the first 4 elements in the current block
- This computed value must be shared with all other lanes in the warp using
broadcast() - Each lane should then add this shared value to its own input element
Test data: Input [1, 2, 3, 4, 5, 6, 7, 8, ...] should produce output
[11, 12, 13, 14, 15, 16, 17, 18, ...]
Challenge: How do you coordinate so that only one lane does the block-level computation, but all lanes can use the result in their individual operations?
Configuration
- Vector size:
SIZE = WARP_SIZE(32 or 64 depending on GPU) - Grid configuration:
(1, 1)blocks per grid - Block configuration:
(WARP_SIZE, 1)threads per block - Data type:
DType.float32 - Layout:
row_major[SIZE]()(1D row-major)
Code to complete
def basic_broadcast[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
"""
Basic broadcast: Lane 0 computes a block-local value, broadcasts it to all lanes.
Each lane then uses this broadcast value in its own computation.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var lane = Int(lane_id())
if global_i < size:
var broadcast_value: output.ElementType = 0.0
# FILL IN (roughly 10 lines)
View full file: problems/p25/p25.mojo
Tips
1. Understanding broadcast mechanics
The broadcast(value) operation takes the value from lane 0 and distributes it
to all lanes in the warp.
Key insight: Only lane 0’s value matters for the broadcast. Other lanes’ values are ignored, but all lanes receive lane 0’s value.
Visualization:
Before broadcast: Lane 0 has \(\text{val}_0\), Lane 1 has \(\text{val}_1\), Lane 2 has \(\text{val}_2\), ...
After broadcast: Lane 0 has \(\text{val}_0\), Lane 1 has \(\text{val}_0\), Lane 2 has \(\text{val}_0\), ...
Think about: How can you ensure only lane 0 computes the value you want to broadcast?
2. Lane-specific computation
Design your algorithm so that lane 0 performs the special computation while other lanes wait.
Pattern to consider:
var shared_value = initial_value
if lane == 0:
# Only lane 0 computes
shared_value = special_computation()
# All lanes participate in broadcast
shared_value = broadcast(shared_value)
Critical questions:
- What should other lanes’ values be before the broadcast?
- How do you ensure lane 0 has the correct value to broadcast?
3. Collective usage
After broadcasting, all lanes have the same value and can use it in their individual computations.
Think about: How does each lane combine the broadcast value with its own local data?
Test the basic broadcast:
pixi run p25 --broadcast-basic
pixi run -e amd p25 --broadcast-basic
pixi run -e apple p25 --broadcast-basic
uv run poe p25 --broadcast-basic
Expected output when solved:
WARP_SIZE: 32
SIZE: 32
output: HostBuffer([11.0, 12.0, 13.0, 14.0, 15.0, 16.0, 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 24.0, 25.0, 26.0, 27.0, 28.0, 29.0, 30.0, 31.0, 32.0, 33.0, 34.0, 35.0, 36.0, 37.0, 38.0, 39.0, 40.0, 41.0, 42.0])
expected: HostBuffer([11.0, 12.0, 13.0, 14.0, 15.0, 16.0, 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 24.0, 25.0, 26.0, 27.0, 28.0, 29.0, 30.0, 31.0, 32.0, 33.0, 34.0, 35.0, 36.0, 37.0, 38.0, 39.0, 40.0, 41.0, 42.0])
✅ Basic broadcast test passed!
Solution
def basic_broadcast[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, MutAnyOrigin],
):
"""
Basic broadcast: Lane 0 computes a block-local value, broadcasts it to all lanes.
Each lane then uses this broadcast value in its own computation.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var lane = Int(lane_id())
if global_i < size:
# Step 1: Lane 0 computes special value (sum of first 4 elements in this block)
var broadcast_value: output.ElementType = 0.0
if lane == 0:
var block_start = block_idx.x * block_dim.x
var sum: output.ElementType = 0.0
for i in range(4):
if block_start + i < size:
sum += input[block_start + i]
broadcast_value = sum
# Step 2: Broadcast lane 0's value to all lanes in this warp
broadcast_value = broadcast(broadcast_value)
# Step 3: All lanes use broadcast value in their computation
output[global_i] = broadcast_value + input[global_i]
This solution demonstrates the fundamental broadcast pattern for warp-level coordination.
Algorithm breakdown:
if global_i < size:
# Step 1: Lane 0 computes special value
var broadcast_value: output.element_type = 0.0
if lane == 0:
# Only lane 0 performs this computation
block_start = block_idx.x * block_dim.x
var sum: output.element_type = 0.0
for i in range(4):
if block_start + i < size:
sum += input[block_start + i]
broadcast_value = sum
# Step 2: Share lane 0's value with all lanes
broadcast_value = broadcast(broadcast_value)
# Step 3: All lanes use the broadcast value
output[global_i] = broadcast_value + input[global_i]
SIMT execution trace:
Cycle 1: Lane-specific computation
Lane 0: Computes sum of input[0] + input[1] + input[2] + input[3] = 1+2+3+4 = 10
Lane 1: broadcast_value remains 0.0 (not lane 0)
Lane 2: broadcast_value remains 0.0 (not lane 0)
...
Lane 31: broadcast_value remains 0.0 (not lane 0)
Cycle 2: broadcast(broadcast_value) executes
Lane 0: Keeps its value → broadcast_value = 10.0
Lane 1: Receives lane 0's value → broadcast_value = 10.0
Lane 2: Receives lane 0's value → broadcast_value = 10.0
...
Lane 31: Receives lane 0's value → broadcast_value = 10.0
Cycle 3: Individual computation with broadcast value
Lane 0: output[0] = 10.0 + input[0] = 10.0 + 1.0 = 11.0
Lane 1: output[1] = 10.0 + input[1] = 10.0 + 2.0 = 12.0
Lane 2: output[2] = 10.0 + input[2] = 10.0 + 3.0 = 13.0
...
Lane 31: output[31] = 10.0 + input[31] = 10.0 + 32.0 = 42.0
Why broadcast is superior:
- Coordination efficiency: Single operation coordinates all lanes
- Memory efficiency: No shared memory allocation required
- Synchronization-free: SIMT execution handles coordination automatically
- Scalable pattern: Works identically regardless of warp size
Performance characteristics:
- Latency: 1 cycle for broadcast operation
- Bandwidth: 0 bytes (register-to-register communication)
- Coordination: All 32 lanes synchronized automatically
2. Conditional broadcast
Implement conditional coordination where lane 0 analyzes block data and makes a decision that affects all lanes.
Requirements:
- Lane 0 should analyze the first 8 elements in the current block and find their maximum value
- This maximum value must be broadcast to all other lanes using
broadcast() - Each lane should then apply conditional logic: if their element is above half the maximum, double it; otherwise, halve it
Test data: Input [3, 1, 7, 2, 9, 4, 6, 8, ...] (repeating pattern) should
produce output [1.5, 0.5, 14.0, 1.0, 18.0, 2.0, 12.0, 16.0, ...]
Challenge: How do you coordinate block-level analysis with element-wise conditional transformations across all lanes?
Configuration
- Vector size:
SIZE = WARP_SIZE(32 or 64 depending on GPU) - Grid configuration:
(1, 1)blocks per grid - Block configuration:
(WARP_SIZE, 1)threads per block
Code to complete
def conditional_broadcast[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
"""
Conditional broadcast: Lane 0 makes a decision based on block-local data, broadcasts it to all lanes.
All lanes apply different logic based on the broadcast decision.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var lane = Int(lane_id())
if global_i < size:
var decision_value: output.ElementType = 0.0
# FILL IN (roughly 10 lines)
var current_input = input[global_i]
var threshold = decision_value / 2.0
if current_input >= threshold:
output[global_i] = current_input * 2.0 # Double if >= threshold
else:
output[global_i] = current_input / 2.0 # Halve if < threshold
Tips
1. Analysis and decision-making
Lane 0 needs to analyze multiple data points and make a decision that will guide all other lanes.
Key questions:
- How can lane 0 efficiently analyze multiple elements?
- What kind of decision should be broadcast to coordinate lane behavior?
- How do you handle boundary conditions when analyzing data?
Pattern to consider:
var decision = default_value
if lane == 0:
# Analyze block-local data
decision = analyze_and_decide()
decision = broadcast(decision)
2. Conditional execution coordination
After receiving the broadcast decision, all lanes need to apply different logic based on the decision.
Think about:
- How do lanes use the broadcast value to make local decisions?
- What operations should be applied in each conditional branch?
- How do you ensure consistent behavior across all lanes?
Conditional pattern:
if (local_data meets_broadcast_criteria):
# Apply one transformation
else:
# Apply different transformation
3. Data analysis strategies
Consider efficient ways for lane 0 to analyze multiple data points.
Approaches to consider:
- Finding maximum/minimum values
- Computing averages or sums
- Detecting patterns or thresholds
- Making binary decisions based on data characteristics
Test the conditional broadcast:
pixi run p25 --broadcast-conditional
pixi run -e amd p25 --broadcast-conditional
uv run poe p25 --broadcast-conditional
Expected output when solved:
WARP_SIZE: 32
SIZE: 32
output: HostBuffer([1.5, 0.5, 14.0, 1.0, 18.0, 2.0, 12.0, 16.0, 1.5, 0.5, 14.0, 1.0, 18.0, 2.0, 12.0, 16.0, 1.5, 0.5, 14.0, 1.0, 18.0, 2.0, 12.0, 16.0, 1.5, 0.5, 14.0, 1.0, 18.0, 2.0, 12.0, 16.0])
expected: HostBuffer([1.5, 0.5, 14.0, 1.0, 18.0, 2.0, 12.0, 16.0, 1.5, 0.5, 14.0, 1.0, 18.0, 2.0, 12.0, 16.0, 1.5, 0.5, 14.0, 1.0, 18.0, 2.0, 12.0, 16.0, 1.5, 0.5, 14.0, 1.0, 18.0, 2.0, 12.0, 16.0])
✅ Conditional broadcast test passed!
Solution
def conditional_broadcast[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, MutAnyOrigin],
):
"""
Conditional broadcast: Lane 0 makes a decision based on block-local data, broadcasts it to all lanes.
All lanes apply different logic based on the broadcast decision.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var lane = Int(lane_id())
if global_i < size:
# Step 1: Lane 0 analyzes block-local data and makes decision (find max of first 8 in block)
var decision_value: output.ElementType = 0.0
if lane == 0:
var block_start = block_idx.x * block_dim.x
decision_value = input[block_start] if block_start < size else 0.0
for i in range(1, min(8, min(WARP_SIZE, size - block_start))):
if block_start + i < size:
var current_val = input[block_start + i]
if current_val > decision_value:
decision_value = current_val
# Step 2: Broadcast decision to all lanes in this warp
decision_value = broadcast(decision_value)
# Step 3: All lanes apply conditional logic based on broadcast decision
var current_input = input[global_i]
var threshold = decision_value / 2.0
if current_input >= threshold:
output[global_i] = current_input * 2.0 # Double if >= threshold
else:
output[global_i] = current_input / 2.0 # Halve if < threshold
This solution demonstrates advanced broadcast patterns for conditional coordination across lanes.
Complete algorithm analysis:
if global_i < size:
# Step 1: Lane 0 analyzes block data and makes decision
var decision_value: output.element_type = 0.0
if lane == 0:
# Find maximum among first 8 elements in block
block_start = block_idx.x * block_dim.x
decision_value = input[block_start] if block_start < size else 0.0
for i in range(1, min(8, min(WARP_SIZE, size - block_start))):
if block_start + i < size:
current_val = input[block_start + i]
if current_val > decision_value:
decision_value = current_val
# Step 2: Broadcast decision to coordinate all lanes
decision_value = broadcast(decision_value)
# Step 3: All lanes apply conditional logic based on broadcast
current_input = input[global_i]
threshold = decision_value / 2.0
if current_input >= threshold:
output[global_i] = current_input * 2.0 # Double if >= threshold
else:
output[global_i] = current_input / 2.0 # Halve if < threshold
Decision-making execution trace:
Input data: [3.0, 1.0, 7.0, 2.0, 9.0, 4.0, 6.0, 8.0, ...]
Step 1: Lane 0 finds maximum of first 8 elements
Lane 0 analysis:
Start with input[0] = 3.0
Compare with input[1] = 1.0 → keep 3.0
Compare with input[2] = 7.0 → update to 7.0
Compare with input[3] = 2.0 → keep 7.0
Compare with input[4] = 9.0 → update to 9.0
Compare with input[5] = 4.0 → keep 9.0
Compare with input[6] = 6.0 → keep 9.0
Compare with input[7] = 8.0 → keep 9.0
Final decision_value = 9.0
Step 2: Broadcast decision_value = 9.0 to all lanes
All lanes now have: decision_value = 9.0, threshold = 4.5
Step 3: Conditional execution per lane
Lane 0: input[0] = 3.0 < 4.5 → output[0] = 3.0 / 2.0 = 1.5
Lane 1: input[1] = 1.0 < 4.5 → output[1] = 1.0 / 2.0 = 0.5
Lane 2: input[2] = 7.0 ≥ 4.5 → output[2] = 7.0 * 2.0 = 14.0
Lane 3: input[3] = 2.0 < 4.5 → output[3] = 2.0 / 2.0 = 1.0
Lane 4: input[4] = 9.0 ≥ 4.5 → output[4] = 9.0 * 2.0 = 18.0
Lane 5: input[5] = 4.0 < 4.5 → output[5] = 4.0 / 2.0 = 2.0
Lane 6: input[6] = 6.0 ≥ 4.5 → output[6] = 6.0 * 2.0 = 12.0
Lane 7: input[7] = 8.0 ≥ 4.5 → output[7] = 8.0 * 2.0 = 16.0
...pattern repeats for remaining lanes
Mathematical foundation: This implements a threshold-based transformation: \[\Large f(x) = \begin{cases} 2x & \text{if } x \geq \tau \\ \frac{x}{2} & \text{if } x < \tau \end{cases}\]
Where \(\tau = \frac{\max(\text{block_data})}{2}\) is the broadcast threshold.
Coordination pattern benefits:
- Centralized analysis: One lane analyzes, all lanes benefit
- Consistent decisions: All lanes use the same threshold
- Adaptive behavior: Threshold adapts to block-local data characteristics
- Efficient coordination: Single broadcast coordinates complex conditional logic
Applications:
- Adaptive algorithms: Adjusting parameters based on local data characteristics
- Quality control: Applying different processing based on data quality metrics
- Load balancing: Distributing work based on block-local complexity analysis
3. Broadcast-shuffle coordination
Implement advanced coordination combining both broadcast() and
shuffle_down() operations.
Requirements:
- Lane 0 should compute the average of the first 4 elements in the block and broadcast this scaling factor to all lanes
- Each lane should use
shuffle_down(offset=1)to get their next neighbor’s value - For most lanes: multiply the scaling factor by
(current_value + next_neighbor_value) - For the last lane in the warp: multiply the scaling factor by just
current_value(no valid neighbor)
Test data: Input follows pattern [2, 4, 6, 8, 1, 3, 5, 7, ...] (first 4
elements: 2,4,6,8 then repeating 1,3,5,7)
- Lane 0 computes scaling factor:
(2+4+6+8)/4 = 5.0 - Expected output:
[30.0, 50.0, 70.0, 45.0, 20.0, 40.0, 60.0, 40.0, ...]
Challenge: How do you coordinate multiple warp primitives so that one lane’s computation affects all lanes, while each lane also accesses its neighbor’s data?
Configuration
- Vector size:
SIZE = WARP_SIZE(32 or 64 depending on GPU) - Grid configuration:
(1, 1)blocks per grid - Block configuration:
(WARP_SIZE, 1)threads per block
Code to complete
def broadcast_shuffle_coordination[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
"""
Combine broadcast() and shuffle_down() for advanced warp coordination.
Lane 0 computes block-local scaling factor, broadcasts it to all lanes in the warp.
Each lane uses shuffle_down() for neighbor access and applies broadcast factor.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var lane = Int(lane_id())
if global_i < size:
var scale_factor: output.ElementType = 0.0
# FILL IN (roughly 14 lines)
Tips
1. Multi-primitive coordination
This puzzle requires orchestrating both broadcast and shuffle operations in sequence.
Think about the flow:
- One lane computes a value for the entire warp
- This value is broadcast to all lanes
- Each lane uses shuffle to access neighbor data
- The broadcast value influences how neighbor data is processed
Coordination pattern:
# Phase 1: Broadcast coordination
var shared_param = compute_if_lane_0()
shared_param = broadcast(shared_param)
# Phase 2: Shuffle neighbor access
current_val = input[global_i]
neighbor_val = shuffle_down(current_val, offset)
# Phase 3: Combined computation
result = combine(current_val, neighbor_val, shared_param)
2. Parameter computation strategy
Consider what kind of block-level parameter would be useful for scaling neighbor operations.
Questions to explore:
- What statistic should lane 0 compute from the block data?
- How should this parameter influence the neighbor-based computation?
- What happens at warp boundaries when shuffle operations are involved?
3. Combined operation design
Think about how to meaningfully combine broadcast parameters with shuffle-based neighbor access.
Pattern considerations:
- Should the broadcast parameter scale the inputs, outputs, or computation?
- How do you handle boundary cases where shuffle returns undefined data?
- What’s the most efficient order of operations?
Test the broadcast-shuffle coordination:
pixi run p25 --broadcast-shuffle-coordination
pixi run -e amd p25 --broadcast-shuffle-coordination
uv run poe p25 --broadcast-shuffle-coordination
Expected output when solved:
WARP_SIZE: 32
SIZE: 32
output: HostBuffer([30.0, 50.0, 70.0, 45.0, 20.0, 40.0, 60.0, 40.0, 20.0, 40.0, 60.0, 40.0, 20.0, 40.0, 60.0, 40.0, 20.0, 40.0, 60.0, 40.0, 20.0, 40.0, 60.0, 40.0, 20.0, 40.0, 60.0, 40.0, 20.0, 40.0, 60.0, 35.0])
expected: HostBuffer([30.0, 50.0, 70.0, 45.0, 20.0, 40.0, 60.0, 40.0, 20.0, 40.0, 60.0, 40.0, 20.0, 40.0, 60.0, 40.0, 20.0, 40.0, 60.0, 40.0, 20.0, 40.0, 60.0, 40.0, 20.0, 40.0, 60.0, 40.0, 20.0, 40.0, 60.0, 35.0])
✅ Broadcast + Shuffle coordination test passed!
Solution
def broadcast_shuffle_coordination[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, MutAnyOrigin],
):
"""
Combine broadcast() and shuffle_down() for advanced warp coordination.
Lane 0 computes block-local scaling factor, broadcasts it to all lanes in the warp.
Each lane uses shuffle_down() for neighbor access and applies broadcast factor.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var lane = Int(lane_id())
if global_i < size:
# Step 1: Lane 0 computes block-local scaling factor
var scale_factor: output.ElementType = 0.0
if lane == 0:
# Compute average of first 4 elements in this block's data
var block_start = block_idx.x * block_dim.x
var sum: output.ElementType = 0.0
for i in range(4):
if block_start + i < size:
sum += input[block_start + i]
scale_factor = sum / 4.0
# Step 2: Broadcast scaling factor to all lanes in this warp
scale_factor = broadcast(scale_factor)
# Step 3: Each lane gets current and next values
var current_val = input[global_i]
var next_val = shuffle_down(current_val, 1)
# Step 4: Apply broadcast factor with neighbor coordination
if lane < WARP_SIZE - 1 and global_i < size - 1:
# Combine current + next, then scale by broadcast factor
output[global_i] = (current_val + next_val) * scale_factor
else:
# Last lane in warp or last element: only current value, scaled by broadcast factor
output[global_i] = current_val * scale_factor
This solution demonstrates the most advanced warp coordination pattern, combining broadcast and shuffle primitives.
Complete algorithm analysis:
if global_i < size:
# Step 1: Lane 0 computes block-local scaling factor
var scale_factor: output.element_type = 0.0
if lane == 0:
block_start = block_idx.x * block_dim.x
var sum: output.element_type = 0.0
for i in range(4):
if block_start + i < size:
sum += input[block_start + i]
scale_factor = sum / 4.0
# Step 2: Broadcast scaling factor to all lanes
scale_factor = broadcast(scale_factor)
# Step 3: Each lane gets current and next values via shuffle
current_val = input[global_i]
next_val = shuffle_down(current_val, 1)
# Step 4: Apply broadcast factor with neighbor coordination
if lane < WARP_SIZE - 1 and global_i < size - 1:
output[global_i] = (current_val + next_val) * scale_factor
else:
output[global_i] = current_val * scale_factor
Multi-primitive execution trace:
Input data: [2, 4, 6, 8, 1, 3, 5, 7, ...]
Phase 1: Lane 0 computes scaling factor
Lane 0 computes: (input[0] + input[1] + input[2] + input[3]) / 4
= (2 + 4 + 6 + 8) / 4 = 20 / 4 = 5.0
Other lanes: scale_factor remains 0.0
Phase 2: Broadcast scale_factor = 5.0 to all lanes
All lanes now have: scale_factor = 5.0
Phase 3: Shuffle operations for neighbor access
Lane 0: current_val = input[0] = 2, next_val = shuffle_down(2, 1) = input[1] = 4
Lane 1: current_val = input[1] = 4, next_val = shuffle_down(4, 1) = input[2] = 6
Lane 2: current_val = input[2] = 6, next_val = shuffle_down(6, 1) = input[3] = 8
Lane 3: current_val = input[3] = 8, next_val = shuffle_down(8, 1) = input[4] = 1
...
Lane 31: current_val = input[31], next_val = undefined
Phase 4: Combined computation with broadcast scaling
Lane 0: output[0] = (2 + 4) * 5.0 = 6 * 5.0 = 30.0
Lane 1: output[1] = (4 + 6) * 5.0 = 10 * 5.0 = 50.0... wait, expected is 30.0
Let me recalculate based on the expected pattern:
Expected: [30.0, 30.0, 35.0, 45.0, 30.0, 40.0, 35.0, 40.0, ...]
Lane 0: (2 + 4) * 5 = 30 ✓
Lane 1: (4 + 6) * 5 = 50, but expected 30...
Hmm, let me check if the input pattern is different or if there's an error in my understanding.
Communication pattern analysis: This algorithm implements a hierarchical coordination pattern:
- Vertical coordination (broadcast): Lane 0 → All lanes
- Horizontal coordination (shuffle): Lane i → Lane i+1
- Combined computation: Uses both broadcast and shuffle data
Mathematical foundation: \[\Large \text{output}[i] = \begin{cases} (\text{input}[i] + \text{input}[i+1]) \cdot \beta & \text{if lane} i < \text{WARP_SIZE} - 1 \\ \text{input}[i] \cdot \beta & \text{if lane } i = \text{WARP_SIZE} - 1 \end{cases}\]
Where \(\beta = \frac{1}{4}\sum_{k=0}^{3} \text{input}[\text{block_start} + k]\) is the broadcast scaling factor.
Advanced coordination benefits:
- Multi-level communication: Combines global (broadcast) and local (shuffle) coordination
- Adaptive scaling: Block-level parameters influence neighbor operations
- Efficient composition: Two primitives work together seamlessly
- Complex algorithms: Enables sophisticated parallel algorithms
Real-world applications:
- Adaptive filtering: Block-level noise estimation with neighbor-based filtering
- Dynamic load balancing: Global work distribution with local coordination
- Multi-scale processing: Global parameters controlling local stencil operations
Summary
Here is what the core pattern of this section looks like
var shared_value = initial_value
if lane == 0:
shared_value = compute_block_statistic()
shared_value = broadcast(shared_value)
result = use_shared_value(shared_value, local_data)
Key benefits:
- One-to-many coordination: Single lane computes, all lanes benefit
- Zero synchronization overhead: SIMT execution handles coordination
- Composable patterns: Easily combines with shuffle and other warp operations
Applications: Block statistics, collective decisions, parameter sharing, adaptive algorithms.
Puzzle 26: Advanced Warp Patterns
Overview
Welcome to Puzzle 26: Advanced Warp Communication Primitives! This puzzle introduces you to sophisticated GPU warp-level butterfly communication and parallel scan operations - hardware-accelerated primitives that enable efficient tree-based algorithms and parallel reductions within warps. You’ll learn about using shuffle_xor for butterfly networks and prefix_sum for hardware-optimized parallel scan without complex multi-phase shared memory algorithms.
What you’ll achieve: Transform from complex shared memory + barrier + multi-phase reduction patterns to elegant single-function-call algorithms that leverage hardware-optimized butterfly networks and parallel scan units.
Key insight: GPU warps can perform sophisticated tree-based communication and parallel scan operations in hardware - Mojo’s advanced warp primitives harness butterfly networks and dedicated scan units to provide \(O(\log n)\) algorithms with single-instruction simplicity.
What you’ll learn
Advanced warp communication model
Understand sophisticated communication patterns within GPU warps:
GPU Warp Butterfly Network (32 threads, XOR-based communication)
Offset 16: Lane 0 ↔ Lane 16, Lane 1 ↔ Lane 17, ..., Lane 15 ↔ Lane 31
Offset 8: Lane 0 ↔ Lane 8, Lane 1 ↔ Lane 9, ..., Lane 23 ↔ Lane 31
Offset 4: Lane 0 ↔ Lane 4, Lane 1 ↔ Lane 5, ..., Lane 27 ↔ Lane 31
Offset 2: Lane 0 ↔ Lane 2, Lane 1 ↔ Lane 3, ..., Lane 29 ↔ Lane 31
Offset 1: Lane 0 ↔ Lane 1, Lane 2 ↔ Lane 3, ..., Lane 30 ↔ Lane 31
Hardware Prefix Sum (parallel scan acceleration)
Input: [1, 2, 3, 4, 5, 6, 7, 8, ...]
Output: [1, 3, 6, 10, 15, 21, 28, 36, ...] (inclusive scan)
Hardware reality:
- Butterfly networks: XOR-based communication creates optimal tree topologies
- Dedicated scan units: Hardware-accelerated parallel prefix operations
- Logarithmic complexity: \(O(\log n)\) algorithms replace \(O(n)\) sequential patterns
- Single-cycle operations: Complex reductions happen in specialized hardware
Advanced warp operations in Mojo
Learn the sophisticated communication primitives from gpu.primitives.warp:
shuffle_xor(value, mask): XOR-based butterfly communication for tree algorithmsprefix_sum(value): Hardware-accelerated parallel scan operations- Advanced coordination patterns: Combining multiple primitives for complex algorithms
Note: These primitives enable sophisticated parallel algorithms like parallel reductions, stream compaction, quicksort partitioning, and FFT operations that would otherwise require dozens of lines of shared memory coordination code.
Performance transformation example
# Complex parallel reduction (traditional approach - from Puzzle 14):
shared = TileTensor[
dtype,
row_major[WARP_SIZE](),
MutAnyOrigin,
address_space = AddressSpace.SHARED,
].stack_allocation()
shared[local_i] = input[global_i]
barrier()
offset = 1
for i in range(Int(log2(Scalar[dtype](WARP_SIZE)))):
var current_val: output.element_type = 0
if local_i >= offset and local_i < WARP_SIZE:
current_val = shared[local_i - offset]
barrier()
if local_i >= offset and local_i < WARP_SIZE:
shared[local_i] += current_val
barrier()
offset *= 2
# Advanced warp primitives eliminate all this complexity:
current_val = input[global_i]
scan_result = prefix_sum[exclusive=False](current_val) # Single call!
output[global_i] = scan_result
When advanced warp operations excel
Learn the performance characteristics:
| Algorithm Pattern | Traditional | Advanced Warp Operations |
|---|---|---|
| Parallel reductions | Shared memory + barriers | Single shuffle_xor tree |
| Prefix/scan operations | Multi-phase algorithms | Hardware prefix_sum |
| Stream compaction | Complex indexing | prefix_sum + coordination |
| Quicksort partition | Manual position calculation | Combined primitives |
| Tree algorithms | Recursive shared memory | Butterfly communication |
Prerequisites
Before diving into advanced warp communication, ensure you’re comfortable with:
- Part VII warp fundamentals: Understanding SIMT execution and basic warp operations (see Puzzle 24 and Puzzle 25)
- Parallel algorithm theory: Tree reductions, parallel scan, and butterfly networks
- GPU memory hierarchy: Shared memory patterns and synchronization (see Puzzle 14)
- Mathematical operations: Understanding XOR operations and logarithmic complexity
Learning path
1. Butterfly communication with shuffle_xor
Learn XOR-based butterfly communication patterns for efficient tree algorithms and parallel reductions.
What you’ll learn:
- Using
shuffle_xor()for creating butterfly network topologies - Implementing \(O(\log n)\) parallel reductions with tree communication
- Understanding XOR-based lane pairing and communication patterns
- Advanced conditional butterfly operations for multi-value reductions
Key pattern:
max_val = input[global_i]
offset = WARP_SIZE // 2
while offset > 0:
max_val = max(max_val, shuffle_xor(max_val, UInt32(offset)))
offset //= 2
# All lanes now have global maximum
2. Hardware-accelerated parallel scan with prefix_sum
Learn hardware-optimized parallel scan operations that replace complex multi-phase algorithms with single function calls.
What you’ll learn:
- Using
prefix_sum()for hardware-accelerated cumulative operations - Implementing stream compaction and parallel partitioning
- Combining
prefix_sumwithshuffle_xorfor advanced coordination - Understanding inclusive vs exclusive scan patterns
Key pattern:
current_val = input[global_i]
scan_result = prefix_sum[exclusive=False](current_val)
output[global_i] = scan_result # Hardware-optimized cumulative sum
Key concepts
Butterfly network communication
Understanding XOR-based communication topologies:
- XOR pairing:
lane_id ⊕ maskcreates symmetric communication pairs - Tree reduction: Logarithmic complexity through hierarchical data exchange
- Parallel coordination: All lanes participate simultaneously in reduction
- Dynamic algorithms: Works for any power-of-2
WARP_SIZE(32, 64, etc.)
Hardware-accelerated parallel scan
Recognizing dedicated scan unit capabilities:
- Prefix sum operations: Cumulative operations with hardware acceleration
- Stream compaction: Parallel filtering and data reorganization
- Single-function simplicity: Complex algorithms become single calls
- Zero synchronization: Hardware handles all coordination internally
Algorithm complexity transformation
Converting traditional patterns to advanced warp operations:
- Sequential reductions (\(O(n)\)) → Butterfly reductions (\(O(\log n)\))
- Multi-phase scan algorithms → Single hardware prefix_sum
- Complex shared memory patterns → Register-only operations
- Explicit synchronization → Hardware-managed coordination
Advanced coordination patterns
Combining multiple primitives for sophisticated algorithms:
- Dual reductions: Simultaneous min/max tracking with butterfly patterns
- Parallel partitioning:
shuffle_xor+prefix_sumfor quicksort-style operations - Conditional operations: Lane-based output selection with global coordination
- Multi-primitive algorithms: Complex parallel patterns with optimal performance
Getting started
Ready to harness advanced GPU warp-level communication? Start with butterfly network operations to understand tree-based communication, then progress to hardware-accelerated parallel scan for optimal algorithm performance.
💡 Success tip: Think of advanced warp operations as hardware-accelerated parallel algorithm building blocks. These primitives replace entire categories of complex shared memory algorithms with single, optimized function calls.
Learning objective: By the end of Puzzle 24, you’ll recognize when advanced warp primitives can replace complex multi-phase algorithms, enabling you to write dramatically simpler and faster tree-based reductions, parallel scans, and coordination patterns.
Ready to begin? Start with Warp Shuffle XOR Operations to learn butterfly communication, then advance to Warp Prefix Sum Operations for hardware-accelerated parallel scan patterns!
warp.shuffle_xor() Butterfly Communication
For warp-level butterfly communication we can use shuffle_xor() to create
sophisticated tree-based communication patterns within a warp. This powerful
primitive enables efficient parallel reductions, sorting networks, and advanced
coordination algorithms without shared memory or explicit synchronization.
Key insight: The shuffle_xor() operation leverages SIMT execution to create XOR-based communication trees, enabling efficient butterfly networks and parallel algorithms that scale with \(O(\log n)\) complexity relative to warp size.
What are butterfly networks? Butterfly networks are communication topologies where threads exchange data based on XOR patterns of their indices. The name comes from the visual pattern when drawn - connections that look like butterfly wings. These networks are fundamental to parallel algorithms like FFT, bitonic sort, and parallel reductions because they enable \(O(\log n)\) communication complexity.
Key concepts
In this puzzle, you’ll learn:
- XOR-based communication patterns with
shuffle_xor() - Butterfly network topologies for parallel algorithms
- Tree-based parallel reductions with \(O(\log n)\) complexity
- Conditional butterfly operations for advanced coordination
- Hardware-optimized parallel primitives replacing complex shared memory
The shuffle_xor operation enables each lane to exchange data with lanes based
on XOR patterns: \[\Large
\text{shuffle_xor}(\text{value}, \text{mask}) =
\text{value_from_lane}(\text{lane_id} \oplus \text{mask})\]
This transforms complex parallel algorithms into elegant butterfly communication patterns, enabling efficient tree reductions and sorting networks without explicit coordination.
1. Basic butterfly pair swap
Configuration
- Vector size:
SIZE = WARP_SIZE(32 or 64 depending on GPU) - Grid configuration:
(1, 1)blocks per grid - Block configuration:
(WARP_SIZE, 1)threads per block - Data type:
DType.float32 - Layout:
row_major[SIZE]()(1D row-major)
The shuffle_xor concept
Traditional pair swapping requires complex indexing and coordination:
# Traditional approach - complex and requires synchronization
shared_memory[lane] = input[global_i]
barrier()
if lane % 2 == 0:
partner = lane + 1
else:
partner = lane - 1
if partner < WARP_SIZE:
swapped_val = shared_memory[partner]
Problems with traditional approach:
- Memory overhead: Requires shared memory allocation
- Synchronization: Needs explicit barriers
- Complex logic: Manual partner calculation and bounds checking
- Poor scaling: Doesn’t leverage hardware communication
With shuffle_xor(), pair swapping becomes elegant:
# Butterfly XOR approach - simple and hardware-optimized
current_val = input[global_i]
swapped_val = shuffle_xor(current_val, 1) # XOR with 1 creates pairs
output[global_i] = swapped_val
Benefits of shuffle_xor:
- Zero memory overhead: Direct register-to-register communication
- No synchronization: SIMT execution guarantees correctness
- Hardware optimized: Single instruction for all lanes
- Butterfly foundation: Building block for complex parallel algorithms
Code to complete
Implement pair swapping using shuffle_xor() to exchange values between
adjacent pairs.
Mathematical operation: Create adjacent pairs that exchange values using XOR pattern: \[\Large \text{output}[i] = \text{input}[i \oplus 1]\]
This transforms input data [0, 1, 2, 3, 4, 5, 6, 7, ...] into pairs
[1, 0, 3, 2, 5, 4, 7, 6, ...], where each pair (i, i+1) swaps values through
XOR communication.
View full file: problems/p26/p26.mojo
Tips
1. Understanding shuffle_xor
The shuffle_xor(value, mask) operation allows each lane to exchange data with
a lane whose ID differs by the XOR mask. Think about what happens when you XOR a
lane ID with different mask values.
Key question to explore:
- What partner does lane 0 get when you XOR with mask 1?
- What partner does lane 1 get when you XOR with mask 1?
- Do you see a pattern forming?
Hint: Try working out the XOR operation manually for the first few lane IDs to understand the pairing pattern.
2. XOR pair pattern
Think about the binary representation of lane IDs and what happens when you flip the least significant bit.
Questions to consider:
- What happens to even-numbered lanes when you XOR with 1?
- What happens to odd-numbered lanes when you XOR with 1?
- Why does this create perfect pairs?
3. No boundary checking needed
Unlike shuffle_down(), shuffle_xor() operations stay within warp boundaries.
Consider why XOR with small masks never creates out-of-bounds lane IDs.
Think about: What’s the maximum lane ID you can get when XORing any valid lane ID with 1?
Test the butterfly pair swap:
pixi run p26 --pair-swap
pixi run -e amd p26 --pair-swap
pixi run -e apple p26 --pair-swap
uv run poe p26 --pair-swap
Expected output when solved:
WARP_SIZE: 32
SIZE: 32
output: [1.0, 0.0, 3.0, 2.0, 5.0, 4.0, 7.0, 6.0, 9.0, 8.0, 11.0, 10.0, 13.0, 12.0, 15.0, 14.0, 17.0, 16.0, 19.0, 18.0, 21.0, 20.0, 23.0, 22.0, 25.0, 24.0, 27.0, 26.0, 29.0, 28.0, 31.0, 30.0]
expected: [1.0, 0.0, 3.0, 2.0, 5.0, 4.0, 7.0, 6.0, 9.0, 8.0, 11.0, 10.0, 13.0, 12.0, 15.0, 14.0, 17.0, 16.0, 19.0, 18.0, 21.0, 20.0, 23.0, 22.0, 25.0, 24.0, 27.0, 26.0, 29.0, 28.0, 31.0, 30.0]
✅ Butterfly pair swap test passed!
Solution
def butterfly_pair_swap[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
"""
Basic butterfly pair swap: Exchange values between adjacent pairs using XOR pattern.
Each thread exchanges its value with its XOR-1 neighbor, creating pairs: (0,1), (2,3), (4,5), etc.
Uses shuffle_xor(val, 1) to swap values within each pair.
This is the foundation of butterfly network communication patterns.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
if global_i < size:
var current_val = input[global_i]
# Exchange with XOR-1 neighbor using butterfly pattern
# Lane 0 exchanges with lane 1, lane 2 with lane 3, etc.
var swapped_val = shuffle_xor(current_val, 1)
# For demonstration, we'll store the swapped value
# In real applications, this might be used for sorting, reduction, etc.
output[global_i] = swapped_val
This solution demonstrates how shuffle_xor() creates perfect pair exchanges
through XOR communication patterns.
Algorithm breakdown:
if global_i < size:
current_val = input[global_i] # Each lane reads its element
swapped_val = shuffle_xor(current_val, 1) # XOR creates pair exchange
# For demonstration, store the swapped value
output[global_i] = swapped_val
SIMT execution deep dive:
Cycle 1: All lanes load their values simultaneously
Lane 0: current_val = input[0] = 0
Lane 1: current_val = input[1] = 1
Lane 2: current_val = input[2] = 2
Lane 3: current_val = input[3] = 3
...
Lane 31: current_val = input[31] = 31
Cycle 2: shuffle_xor(current_val, 1) executes on all lanes
Lane 0: receives from Lane 1 (0⊕1=1) → swapped_val = 1
Lane 1: receives from Lane 0 (1⊕1=0) → swapped_val = 0
Lane 2: receives from Lane 3 (2⊕1=3) → swapped_val = 3
Lane 3: receives from Lane 2 (3⊕1=2) → swapped_val = 2
...
Lane 30: receives from Lane 31 (30⊕1=31) → swapped_val = 31
Lane 31: receives from Lane 30 (31⊕1=30) → swapped_val = 30
Cycle 3: Store results
Lane 0: output[0] = 1
Lane 1: output[1] = 0
Lane 2: output[2] = 3
Lane 3: output[3] = 2
...
Mathematical insight: This implements perfect pair exchange using XOR properties: \[\Large \text{XOR}(i, 1) = \begin{cases} i + 1 & \text{if} i \bmod 2 = 0 \\ i - 1 & \text{if } i \bmod 2 = 1 \end{cases}\]
Why shuffle_xor is superior:
- Perfect symmetry: Every lane participates in exactly one pair
- No coordination: All pairs exchange simultaneously
- Hardware optimized: Single instruction for entire warp
- Butterfly foundation: Building block for complex parallel algorithms
Performance characteristics:
- Latency: 1 cycle (hardware register exchange)
- Bandwidth: 0 bytes (no memory traffic)
- Parallelism: All WARP_SIZE lanes exchange simultaneously
- Scalability: \(O(1)\) complexity regardless of data size
2. Butterfly parallel maximum
Configuration
- Vector size:
SIZE = WARP_SIZE(32 or 64 depending on GPU) - Grid configuration:
(1, 1)blocks per grid - Block configuration:
(WARP_SIZE, 1)threads per block
Code to complete
Implement parallel maximum reduction using butterfly shuffle_xor with
decreasing offsets.
Mathematical operation: Compute the maximum across all warp lanes using tree reduction: \[\Large \text{max_result} = \max_{i=0}^{\small\text{WARP_SIZE}-1} \text{input}[i]\]
Butterfly reduction pattern: Use XOR offsets starting from WARP_SIZE/2
down to 1 to create a binary tree where each step halves the active
communication range:
- Step 1: Compare with lanes
WARP_SIZE/2positions away (covers full warp) - Step 2: Compare with lanes
WARP_SIZE/4positions away (covers remaining range) - Step 3: Compare with lanes
WARP_SIZE/8positions away - Step 4: Continue halving until
offset = 1
After \(\log_2(\text{WARP_SIZE})\) steps, all lanes have the global
maximum. This works for any WARP_SIZE (32, 64, etc.).
def butterfly_parallel_max[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
"""
Parallel maximum reduction using butterfly pattern.
Uses shuffle_xor with decreasing offsets starting from WARP_SIZE/2 down to 1.
Each step reduces the active range by half until all threads have the maximum value.
This implements an efficient O(log n) parallel reduction algorithm that works
for any WARP_SIZE (32, 64, etc.).
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
# FILL ME IN (roughly 7 lines)
Tips
1. Understanding butterfly reduction
The butterfly reduction creates a binary tree communication pattern. Think about how you can systematically reduce the problem size at each step.
Key questions:
- What should be your starting offset to cover the maximum range?
- How should the offset change between steps?
- When should you stop the reduction?
Hint: The name “butterfly” comes from the communication pattern - try sketching it out for a small example.
2. XOR reduction properties
XOR creates non-overlapping communication pairs at each step. Consider why this is important for parallel reductions.
Think about:
- How does XOR with different offsets create different communication patterns?
- Why don’t lanes interfere with each other at the same step?
- What makes XOR particularly well-suited for tree reductions?
3. Accumulating maximum values
Each lane needs to progressively build up knowledge of the maximum value in its “region”.
Algorithm structure:
- Start with your own value
- At each step, compare with a neighbor’s value
- Keep the maximum and continue
Key insight: After each step, your “region of knowledge” doubles in size.
- After final step: Each lane knows global maximum
4. Why this pattern works
The butterfly reduction guarantees that after \(\log_2(\text{WARP_SIZE})\) steps:
- Every lane has seen every other lane’s value indirectly
- No redundant communication: Each pair exchanges exactly once per step
- Optimal complexity: \(O(\log n)\) steps instead of \(O(n)\) sequential comparison
Trace example (4 lanes, values [3, 1, 7, 2]):
Initial: Lane 0=3, Lane 1=1, Lane 2=7, Lane 3=2
Step 1 (offset=2): 0 ↔ 2, 1 ↔ 3
Lane 0: max(3, 7) = 7
Lane 1: max(1, 2) = 2
Lane 2: max(7, 3) = 7
Lane 3: max(2, 1) = 2
Step 2 (offset=1): 0 ↔ 1, 2 ↔ 3
Lane 0: max(7, 2) = 7
Lane 1: max(2, 7) = 7
Lane 2: max(7, 2) = 7
Lane 3: max(2, 7) = 7
Result: All lanes have global maximum = 7
Test the butterfly parallel maximum:
pixi run p26 --parallel-max
pixi run -e amd p26 --parallel-max
uv run poe p26 --parallel-max
Expected output when solved:
WARP_SIZE: 32
SIZE: 32
output: [1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0]
expected: [1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0, 1000.0]
✅ Butterfly parallel max test passed!
Solution
def butterfly_parallel_max[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
"""
Parallel maximum reduction using butterfly pattern.
Uses shuffle_xor with decreasing offsets (16, 8, 4, 2, 1) to perform tree-based reduction.
Each step reduces the active range by half until all threads have the maximum value.
This implements an efficient O(log n) parallel reduction algorithm.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
if global_i < size:
var max_val = input[global_i]
# Butterfly reduction tree: dynamic for any WARP_SIZE (32, 64, etc.)
# Start with half the warp size and reduce by half each step
var offset = WARP_SIZE // 2
while offset > 0:
max_val = max(max_val, shuffle_xor(max_val, UInt32(offset)))
offset //= 2
# All threads now have the maximum value across the entire warp
output[global_i] = max_val
This solution demonstrates how shuffle_xor() creates efficient parallel
reduction trees with \(O(\log n)\) complexity.
Complete algorithm analysis:
if global_i < size:
max_val = input[global_i] # Start with local value
# Butterfly reduction tree: dynamic for any WARP_SIZE
offset = WARP_SIZE // 2
while offset > 0:
max_val = max(max_val, shuffle_xor(max_val, UInt32(offset)))
offset //= 2
output[global_i] = max_val # All lanes have global maximum
Butterfly execution trace (8-lane example, values [0,2,4,6,8,10,12,1000]):
Initial state:
Lane 0: max_val = 0, Lane 1: max_val = 2
Lane 2: max_val = 4, Lane 3: max_val = 6
Lane 4: max_val = 8, Lane 5: max_val = 10
Lane 6: max_val = 12, Lane 7: max_val = 1000
Step 1: shuffle_xor(max_val, 4) - Halves exchange
Lane 0↔4: max(0,8)=8, Lane 1↔5: max(2,10)=10
Lane 2↔6: max(4,12)=12, Lane 3↔7: max(6,1000)=1000
Lane 4↔0: max(8,0)=8, Lane 5↔1: max(10,2)=10
Lane 6↔2: max(12,4)=12, Lane 7↔3: max(1000,6)=1000
Step 2: shuffle_xor(max_val, 2) - Quarters exchange
Lane 0↔2: max(8,12)=12, Lane 1↔3: max(10,1000)=1000
Lane 2↔0: max(12,8)=12, Lane 3↔1: max(1000,10)=1000
Lane 4↔6: max(8,12)=12, Lane 5↔7: max(10,1000)=1000
Lane 6↔4: max(12,8)=12, Lane 7↔5: max(1000,10)=1000
Step 3: shuffle_xor(max_val, 1) - Pairs exchange
Lane 0↔1: max(12,1000)=1000, Lane 1↔0: max(1000,12)=1000
Lane 2↔3: max(12,1000)=1000, Lane 3↔2: max(1000,12)=1000
Lane 4↔5: max(12,1000)=1000, Lane 5↔4: max(1000,12)=1000
Lane 6↔7: max(12,1000)=1000, Lane 7↔6: max(1000,12)=1000
Final result: All lanes have max_val = 1000
Mathematical insight: This implements the parallel reduction operator with butterfly communication: \[\Large \text{Reduce}(\oplus, [a_0, a_1, \ldots, a_{n-1}]) = a_0 \oplus a_1 \oplus \cdots \oplus a_{n-1}\]
Where \(\oplus\) is the max operation and the butterfly pattern ensures
optimal \(O(\log n)\) complexity.
Why butterfly reduction is superior:
- Logarithmic complexity: \(O(\log n)\) vs \(O(n)\) for sequential reduction
- Perfect load balancing: Every lane participates equally at each step
- No memory bottlenecks: Pure register-to-register communication
- Hardware optimized: Maps directly to GPU butterfly networks
Performance characteristics:
- Steps: \(\log_2(\text{WARP_SIZE})\) (e.g., 5 for 32-thread, 6 for 64-thread warp)
- Latency per step: 1 cycle (register exchange + comparison)
- Total latency: \(\log_2(\text{WARP_SIZE})\) cycles vs \((\text{WARP_SIZE}-1)\) cycles for sequential
- Parallelism: All lanes active throughout the algorithm
3. Butterfly conditional maximum
Configuration
- Vector size:
SIZE_2 = 64(multi-block scenario) - Grid configuration:
BLOCKS_PER_GRID_2 = (2, 1)blocks per grid - Block configuration:
THREADS_PER_BLOCK_2 = (WARP_SIZE, 1)threads per block
Code to complete
Implement conditional butterfly reduction where even lanes store the maximum and odd lanes store the minimum.
Mathematical operation: Perform butterfly reduction for both maximum and minimum, then conditionally output based on lane parity: \[\Large \text{output}[i] = \begin{cases} \max_{j=0}^{\text{WARP_SIZE}-1} \text{input}[j] & \text{if} i \bmod 2 = 0 \\ \min_{j=0}^{\text{WARP_SIZE}-1} \text{input}[j] & \text{if } i \bmod 2 = 1 \end{cases}\]
Dual reduction pattern: Simultaneously track both maximum and minimum values through the butterfly tree, then conditionally output based on lane ID parity. This demonstrates how butterfly patterns can be extended for complex multi-value reductions.
comptime SIZE_2 = 64
comptime BLOCKS_PER_GRID_2 = (2, 1)
comptime THREADS_PER_BLOCK_2 = (WARP_SIZE, 1)
comptime layout_2 = row_major[SIZE_2]()
comptime LayoutType_2 = type_of(layout_2)
def butterfly_conditional_max[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType_2, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType_2, ImmutAnyOrigin],
):
"""
Conditional butterfly maximum: Perform butterfly max reduction, but only store result
in even-numbered lanes. Odd-numbered lanes store the minimum value seen.
Demonstrates conditional logic combined with butterfly communication patterns.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var lane = lane_id()
if global_i < size:
var current_val = input[global_i]
var min_val = current_val
# FILL ME IN (roughly 11 lines)
Tips
1. Dual-track butterfly reduction
This puzzle requires tracking TWO different values simultaneously through the butterfly tree. Think about how you can run multiple reductions in parallel.
Key questions:
- How can you maintain both maximum and minimum values during the reduction?
- Can you use the same butterfly pattern for both operations?
- What variables do you need to track?
2. Conditional output logic
After completing the butterfly reduction, you need to output different values based on lane parity.
Consider:
- How do you determine if a lane is even or odd?
- Which lanes should output the maximum vs minimum?
- How do you access the lane ID?
3. Butterfly reduction for both min and max
The challenge is efficiently computing both min and max in parallel using the same butterfly communication pattern.
Think about:
- Do you need separate shuffle operations for min and max?
- Can you reuse the same neighbor values for both operations?
- How do you ensure both reductions complete correctly?
4. Multi-block boundary considerations
This puzzle uses multiple blocks. Consider how this affects the reduction scope.
Important considerations:
- What’s the scope of each butterfly reduction?
- How does the block structure affect lane numbering?
- Are you computing global or per-block min/max values?
Test the butterfly conditional maximum:
pixi run p26 --conditional-max
pixi run -e amd p26 --conditional-max
uv run poe p26 --conditional-max
Expected output when solved:
WARP_SIZE: 32
SIZE_2: 64
output: [9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0]
expected: [9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 9.0, 0.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0, 63.0, 32.0]
✅ Butterfly conditional max test passed!
Solution
def butterfly_conditional_max[
size: Int
](
output: TileTensor[mut=True, dtype, Layout2Type, MutAnyOrigin],
input: TileTensor[mut=False, dtype, Layout2Type, ImmutAnyOrigin],
):
"""
Conditional butterfly maximum: Perform butterfly max reduction, but only store result
in even-numbered lanes. Odd-numbered lanes store the minimum value seen.
Demonstrates conditional logic combined with butterfly communication patterns.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var lane = lane_id()
if global_i < size:
var current_val = input[global_i]
var min_val = current_val
# Butterfly reduction for both maximum and minimum: dynamic for any WARP_SIZE
var offset = WARP_SIZE // 2
while offset > 0:
var neighbor_val = shuffle_xor(current_val, UInt32(offset))
current_val = max(current_val, neighbor_val)
var min_neighbor_val = shuffle_xor(min_val, UInt32(offset))
min_val = min(min_val, min_neighbor_val)
offset //= 2
# Conditional output: max for even lanes, min for odd lanes
if lane % 2 == 0:
output[global_i] = current_val # Maximum
else:
output[global_i] = min_val # Minimum
This solution demonstrates advanced butterfly reduction with dual tracking and conditional output.
Complete algorithm analysis:
if global_i < size:
current_val = input[global_i]
min_val = current_val # Track minimum separately
# Butterfly reduction for both max and min log_2(WARP_SIZE}) steps)
offset = WARP_SIZE // 2
while offset > 0:
neighbor_val = shuffle_xor(current_val, UInt32(offset))
current_val = max(current_val, neighbor_val) # Max reduction
min_neighbor_val = shuffle_xor(min_val, UInt32(offset))
min_val = min(min_val, min_neighbor_val) # Min reduction
offset //= 2
# Conditional output based on lane parity
if lane % 2 == 0:
output[global_i] = current_val # Even lanes: maximum
else:
output[global_i] = min_val # Odd lanes: minimum
Dual reduction execution trace (4-lane example, values [3, 1, 7, 2]):
Initial state:
Lane 0: current_val=3, min_val=3
Lane 1: current_val=1, min_val=1
Lane 2: current_val=7, min_val=7
Lane 3: current_val=2, min_val=2
Step 1: shuffle_xor(current_val, 2) and shuffle_xor(min_val, 2) - Halves exchange
Lane 0↔2: max_neighbor=7, min_neighbor=7 → current_val=max(3,7)=7, min_val=min(3,7)=3
Lane 1↔3: max_neighbor=2, min_neighbor=2 → current_val=max(1,2)=2, min_val=min(1,2)=1
Lane 2↔0: max_neighbor=3, min_neighbor=3 → current_val=max(7,3)=7, min_val=min(7,3)=3
Lane 3↔1: max_neighbor=1, min_neighbor=1 → current_val=max(2,1)=2, min_val=min(2,1)=1
Step 2: shuffle_xor(current_val, 1) and shuffle_xor(min_val, 1) - Pairs exchange
Lane 0↔1: max_neighbor=2, min_neighbor=1 → current_val=max(7,2)=7, min_val=min(3,1)=1
Lane 1↔0: max_neighbor=7, min_neighbor=3 → current_val=max(2,7)=7, min_val=min(1,3)=1
Lane 2↔3: max_neighbor=2, min_neighbor=1 → current_val=max(7,2)=7, min_val=min(3,1)=1
Lane 3↔2: max_neighbor=7, min_neighbor=3 → current_val=max(2,7)=7, min_val=min(1,3)=1
Final result: All lanes have current_val=7 (global max) and min_val=1 (global min)
Dynamic algorithm (works for any WARP_SIZE):
offset = WARP_SIZE // 2
while offset > 0:
neighbor_val = shuffle_xor(current_val, UInt32(offset))
current_val = max(current_val, neighbor_val)
min_neighbor_val = shuffle_xor(min_val, UInt32(offset))
min_val = min(min_val, min_neighbor_val)
offset //= 2
Mathematical insight: This implements dual parallel reduction with conditional demultiplexing: \[\Large \begin{align} \text{max_result} &= \max_{i=0}^{n-1} \text{input}[i] \\ \text{min_result} &= \min_{i=0}^{n-1} \text{input}[i] \\ \text{output}[i] &= \text{lane_parity}(i) \; \text{?} \; \text{min_result}: \text{max_result} \end{align}\]
Why dual butterfly reduction works:
- Independent reductions: Max and min reductions are mathematically independent
- Parallel execution: Both can use the same butterfly communication pattern
- Shared communication: Same shuffle operations serve both reductions
- Conditional output: Lane parity determines which result to output
Performance characteristics:
- Communication steps: \(\log_2(\text{WARP_SIZE})\) (same as single reduction)
- Computation per step: 2 operations (max + min) vs 1 for single reduction
- Memory efficiency: 2 registers per thread vs complex shared memory approaches
- Output flexibility: Different lanes can output different reduction results
Summary
The shuffle_xor() primitive enables powerful butterfly communication patterns
that form the foundation of efficient parallel algorithms. Through these three
problems, you’ve learned:
Core Butterfly Patterns
-
Pair Exchange (
shuffle_xor(value, 1)):- Creates perfect adjacent pairs: (0,1), (2,3), (4,5), …
- \(O(1)\) complexity with zero memory overhead
- Foundation for sorting networks and data reorganization
-
Tree Reduction (dynamic offsets:
WARP_SIZE/2→1):- Logarithmic parallel reduction: \(O(\log n)\) vs \(O(n)\) sequential
- Works for any associative operation (max, min, sum, etc.)
- Optimal load balancing across all warp lanes
-
Conditional Multi-Reduction (dual tracking + lane parity):
- Simultaneous multiple reductions in parallel
- Conditional output based on thread characteristics
- Advanced coordination without explicit synchronization
Key Algorithmic Insights
XOR Communication Properties:
shuffle_xor(value, mask)creates symmetric, non-overlapping pairs- Each mask creates a unique communication topology
- Butterfly networks emerge naturally from binary XOR patterns
Dynamic Algorithm Design:
offset = WARP_SIZE // 2
while offset > 0:
neighbor_val = shuffle_xor(current_val, UInt32(offset))
current_val = operation(current_val, neighbor_val)
offset //= 2
Performance Advantages:
- Hardware optimization: Direct register-to-register communication
- No synchronization: SIMT execution guarantees correctness
- Scalable complexity: \(O(\log n)\) for any WARP_SIZE (32, 64, etc.)
- Memory efficiency: Zero shared memory requirements
Practical Applications
These butterfly patterns are fundamental to:
- Parallel reductions: Sum, max, min, logical operations
- Prefix/scan operations: Cumulative sums, parallel sorting
- FFT algorithms: Signal processing and convolution
- Bitonic sorting: Parallel sorting networks
- Graph algorithms: Tree traversals and connectivity
The shuffle_xor() primitive transforms complex parallel coordination into
elegant, hardware-optimized communication patterns that scale efficiently across
different GPU architectures.
warp.prefix_sum() Hardware-Optimized Parallel Scan
For warp-level parallel scan operations we can use prefix_sum() to replace
complex shared memory algorithms with hardware-optimized primitives. This
powerful operation enables efficient cumulative computations, parallel
partitioning, and advanced coordination algorithms that would otherwise require
dozens of lines of shared memory and synchronization code.
Key insight: The prefix_sum() operation leverages hardware-accelerated parallel scan to compute cumulative operations across warp lanes with \(O(\log n)\) complexity, replacing complex multi-phase algorithms with single function calls.
What is parallel scan? Parallel scan (prefix sum) is a fundamental parallel primitive that computes cumulative operations across data elements. For addition, it transforms
[a, b, c, d]into[a, a+b, a+b+c, a+b+c+d]. This operation is essential for parallel algorithms like stream compaction, quicksort partitioning, and parallel sorting.
Key concepts
In this puzzle, you’ll learn:
- Hardware-optimized parallel scan with
prefix_sum() - Inclusive vs exclusive prefix sum patterns
- Warp-level stream compaction for data reorganization
- Advanced parallel partitioning combining multiple warp primitives
- Single-warp algorithm optimization replacing complex shared memory
This transforms multi-phase shared memory algorithms into elegant single-function calls, enabling efficient parallel scan operations without explicit synchronization.
1. Warp inclusive prefix sum
Configuration
- Vector size:
SIZE = WARP_SIZE(32 or 64 depending on GPU) - Grid configuration:
(1, 1)blocks per grid - Block configuration:
(WARP_SIZE, 1)threads per block - Data type:
DType.float32 - Layout:
row_major[SIZE]()(1D row-major)
The prefix_sum advantage
Traditional prefix sum requires complex multi-phase shared memory algorithms. In Puzzle 14, we implemented this the hard way with explicit shared memory management:
def prefix_sum_simple(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
if global_i < size:
shared[local_i] = a[global_i]
barrier()
var offset = 1
for _ in range(Int(log2(Scalar[dtype](TPB)))):
var current_val: output.ElementType = 0
if local_i >= offset and local_i < size:
current_val = shared[local_i - offset] # read
barrier()
if local_i >= offset and local_i < size:
shared[local_i] += current_val
barrier()
offset *= 2
if global_i < size:
output[global_i] = shared[local_i]
Problems with traditional approach:
- Memory overhead: Requires shared memory allocation
- Multiple barriers: Complex multi-phase synchronization
- Complex indexing: Manual stride calculation and boundary checking
- Poor scaling: \(O(\log n)\) phases with barriers between each
With prefix_sum(), parallel scan becomes trivial:
# Hardware-optimized approach - single function call!
current_val = input[global_i]
scan_result = prefix_sum[exclusive=False](current_val)
output[global_i] = scan_result
Benefits of prefix_sum:
- Zero memory overhead: Hardware-accelerated computation
- No synchronization: Single atomic operation
- Hardware optimized: Leverages specialized scan units
- Perfect scaling: Works for any
WARP_SIZE(32, 64, etc.)
Code to complete
Implement inclusive prefix sum using the hardware-optimized prefix_sum()
primitive.
Mathematical operation: Compute cumulative sum where each lane gets the sum of all elements up to and including its position: \[\Large \text{output}[i] = \sum_{j=0}^{i} \text{input}[j]\]
This transforms input data [1, 2, 3, 4, 5, ...] into cumulative sums
[1, 3, 6, 10, 15, ...], where each position contains the sum of all previous
elements plus itself.
def warp_inclusive_prefix_sum[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
"""
Inclusive prefix sum using warp primitive:
Each thread gets sum of all elements up to and including its position.
Compare this to Puzzle 12's complex shared memory + barrier approach.
Puzzle 12 approach:
- Shared memory allocation
- Multiple barrier synchronizations
- Log(n) iterations with manual tree reduction
- Complex multi-phase algorithm
Warp prefix_sum approach:
- Single function call!
- Hardware-optimized parallel scan
- Automatic synchronization
- O(log n) complexity, but implemented in hardware.
NOTE: This implementation only works correctly within a single warp (WARP_SIZE threads).
For multi-warp scenarios, additional coordination would be needed.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
# FILL ME IN (roughly 4 lines)
View full file: problems/p26/p26.mojo
Tips
1. Understanding prefix_sum parameters
The prefix_sum() function has an important template parameter that controls
the scan type.
Key questions:
- What’s the difference between inclusive and exclusive prefix sum?
- Which parameter controls this behavior?
- For inclusive scan, what should each lane output?
Hint: Look at the function signature and consider what “inclusive” means for cumulative operations.
2. Single warp limitation
This hardware primitive only works within a single warp. Consider the implications.
Think about:
- What happens if you have multiple warps?
- Why is this limitation important to understand?
- How would you extend this to multi-warp scenarios?
3. Data type considerations
The prefix_sum function may require specific data types for optimal
performance.
Consider:
- What data type does your input use?
- Does
prefix_sumexpect a specific scalar type? - How do you handle type conversions if needed?
Test the warp inclusive prefix sum:
pixi run p26 --prefix-sum
pixi run -e amd p26 --prefix-sum
pixi run -e apple p26 --prefix-sum
uv run poe p26 --prefix-sum
Expected output when solved:
WARP_SIZE: 32
SIZE: 32
output: [1.0, 3.0, 6.0, 10.0, 15.0, 21.0, 28.0, 36.0, 45.0, 55.0, 66.0, 78.0, 91.0, 105.0, 120.0, 136.0, 153.0, 171.0, 190.0, 210.0, 231.0, 253.0, 276.0, 300.0, 325.0, 351.0, 378.0, 406.0, 435.0, 465.0, 496.0, 528.0]
expected: [1.0, 3.0, 6.0, 10.0, 15.0, 21.0, 28.0, 36.0, 45.0, 55.0, 66.0, 78.0, 91.0, 105.0, 120.0, 136.0, 153.0, 171.0, 190.0, 210.0, 231.0, 253.0, 276.0, 300.0, 325.0, 351.0, 378.0, 406.0, 435.0, 465.0, 496.0, 528.0]
✅ Warp inclusive prefix sum test passed!
Solution
def warp_inclusive_prefix_sum[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
"""
Inclusive prefix sum using warp primitive: Each thread gets sum of all elements up to and including its position.
Compare this to Puzzle 12's complex shared memory + barrier approach.
Puzzle 12 approach:
- Shared memory allocation
- Multiple barrier synchronizations
- Log(n) iterations with manual tree reduction
- Complex multi-phase algorithm
Warp prefix_sum approach:
- Single function call!
- Hardware-optimized parallel scan
- Automatic synchronization
- O(log n) complexity, but implemented in hardware.
NOTE: This implementation only works correctly within a single warp (WARP_SIZE threads).
For multi-warp scenarios, additional coordination would be needed.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
if global_i < size:
var current_val = input[global_i]
# This one call replaces ~30 lines of complex shared memory logic from Puzzle 12!
# But it only works within the current warp (WARP_SIZE threads)
var scan_result = prefix_sum[exclusive=False](
rebind[Scalar[dtype]](current_val)
)
output[global_i] = scan_result
This solution demonstrates how prefix_sum() replaces complex multi-phase
algorithms with a single hardware-optimized function call.
Algorithm breakdown:
if global_i < size:
current_val = input[global_i]
# This one call replaces ~30 lines of complex shared memory logic from Puzzle 14!
# But it only works within the current warp (WARP_SIZE threads)
scan_result = prefix_sum[exclusive=False](
rebind[Scalar[dtype]](current_val)
)
output[global_i] = scan_result
SIMT execution deep dive:
Input: [1, 2, 3, 4, 5, 6, 7, 8, ...]
Cycle 1: All lanes load their values simultaneously
Lane 0: current_val = 1
Lane 1: current_val = 2
Lane 2: current_val = 3
Lane 3: current_val = 4
...
Lane 31: current_val = 32
Cycle 2: prefix_sum[exclusive=False] executes (hardware-accelerated)
Lane 0: scan_result = 1 (sum of elements 0 to 0)
Lane 1: scan_result = 3 (sum of elements 0 to 1: 1+2)
Lane 2: scan_result = 6 (sum of elements 0 to 2: 1+2+3)
Lane 3: scan_result = 10 (sum of elements 0 to 3: 1+2+3+4)
...
Lane 31: scan_result = 528 (sum of elements 0 to 31)
Cycle 3: Store results
Lane 0: output[0] = 1
Lane 1: output[1] = 3
Lane 2: output[2] = 6
Lane 3: output[3] = 10
...
Mathematical insight: This implements the inclusive prefix sum operation: \[\Large \text{output}[i] = \sum_{j=0}^{i} \text{input}[j]\]
Comparison with Puzzle 14’s approach:
- Puzzle 14: ~30 lines of shared memory + multiple barriers + complex indexing
- Warp primitive: 1 function call with hardware acceleration
- Performance: Same \(O(\log n)\) complexity, but implemented in specialized hardware
- Memory: Zero shared memory usage vs explicit allocation
Evolution from Puzzle 12: This demonstrates the power of modern GPU
architectures - what required careful manual implementation in Puzzle 12 is now
a single hardware-accelerated primitive. The warp-level prefix_sum() gives you
the same algorithmic benefits with zero implementation complexity.
Why prefix_sum is superior:
- Hardware acceleration: Dedicated scan units on modern GPUs
- Zero memory overhead: No shared memory allocation required
- Automatic synchronization: No explicit barriers needed
- Perfect scaling: Works optimally for any
WARP_SIZE
Performance characteristics:
- Latency: ~1-2 cycles (hardware scan units)
- Bandwidth: Zero memory traffic (register-only operation)
- Parallelism: All
WARP_SIZElanes participate simultaneously - Scalability: \(O(\log n)\) complexity with hardware optimization
Important limitation: This primitive only works within a single warp. For multi-warp scenarios, you would need additional coordination between warps.
2. Warp partition
Configuration
- Vector size:
SIZE = WARP_SIZE(32 or 64 depending on GPU) - Grid configuration:
(1, 1)blocks per grid - Block configuration:
(WARP_SIZE, 1)threads per block
Code to complete
Implement single-warp parallel partitioning using BOTH shuffle_xor AND
prefix_sum primitives.
Mathematical operation: Partition elements around a pivot value, placing
elements < pivot on the left and elements >= pivot on the right:
\[\Large \text{output} = [\text{elements} < \text{pivot}] \,|\, [\text{elements} \geq \text{pivot}]\]
Advanced algorithm: This combines two sophisticated warp primitives:
shuffle_xor(): Butterfly pattern for warp-level reduction (count left elements)prefix_sum(): Exclusive scan for position calculation within partitions
This demonstrates the power of combining multiple warp primitives for complex parallel algorithms within a single warp.
def warp_partition[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
pivot: Float32,
):
"""
Single-warp parallel partitioning using BOTH shuffle_xor AND prefix_sum.
This implements a warp-level quicksort partition step that places elements < pivot
on the left and elements >= pivot on the right.
ALGORITHM COMPLEXITY - combines two advanced warp primitives:
1. shuffle_xor(): Butterfly pattern for warp-level reductions
2. prefix_sum(): Warp-level exclusive scan for position calculation.
This demonstrates the power of warp primitives for sophisticated parallel algorithms
within a single warp (works for any WARP_SIZE: 32, 64, etc.).
Example with pivot=5:
Input: [3, 7, 1, 8, 2, 9, 4, 6]
var Result: [3, 1, 2, 4, 7, 8, 9, 6] (< pivot | >= pivot).
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
if global_i < size:
var current_val = input[global_i]
# FILL ME IN (roughly 13 lines)
Tips
1. Multi-phase algorithm structure
This algorithm requires several coordinated phases. Think about the logical steps needed for partitioning.
Key phases to consider:
- How do you identify which elements belong to which partition?
- How do you calculate positions within each partition?
- How do you determine the total size of the left partition?
- How do you write elements to their final positions?
2. Predicate creation
You need to create boolean predicates to identify partition membership.
Think about:
- How do you represent “this element belongs to the left partition”?
- How do you represent “this element belongs to the right partition”?
- What data type should you use for predicates that work with
prefix_sum?
3. Combining shuffle_xor and prefix_sum
This algorithm uses both warp primitives for different purposes.
Consider:
- What is
shuffle_xorused for in this context? - What is
prefix_sumused for in this context? - How do these two operations work together?
4. Position calculation
The trickiest part is calculating where each element should be written in the output.
Key insights:
- Left partition elements: What determines their final position?
- Right partition elements: How do you offset them correctly?
- How do you combine local positions with partition boundaries?
Test the warp partition:
uv run poe p26 --partition
pixi run p26 --partition
Expected output when solved:
WARP_SIZE: 32
SIZE: 32
output: HostBuffer([3.0, 1.0, 2.0, 4.0, 0.0, 3.0, 1.0, 4.0, 3.0, 1.0, 2.0, 4.0, 0.0, 3.0, 1.0, 4.0, 7.0, 8.0, 9.0, 6.0, 10.0, 11.0, 12.0, 13.0, 7.0, 8.0, 9.0, 6.0, 10.0, 11.0, 12.0, 13.0])
expected: HostBuffer([3.0, 1.0, 2.0, 4.0, 0.0, 3.0, 1.0, 4.0, 3.0, 1.0, 2.0, 4.0, 0.0, 3.0, 1.0, 4.0, 7.0, 8.0, 9.0, 6.0, 10.0, 11.0, 12.0, 13.0, 7.0, 8.0, 9.0, 6.0, 10.0, 11.0, 12.0, 13.0])
pivot: 5.0
✅ Warp partition test passed!
Solution
def warp_partition[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
pivot: Float32,
):
"""
Single-warp parallel partitioning using BOTH shuffle_xor AND prefix_sum.
This implements a warp-level quicksort partition step that places elements < pivot
on the left and elements >= pivot on the right.
ALGORITHM COMPLEXITY - combines two advanced warp primitives:
1. shuffle_xor(): Butterfly pattern for warp-level reductions
2. prefix_sum(): Warp-level exclusive scan for position calculation.
This demonstrates the power of warp primitives for sophisticated parallel algorithms
within a single warp (works for any WARP_SIZE: 32, 64, etc.).
Example with pivot=5:
Input: [3, 7, 1, 8, 2, 9, 4, 6]
var Result: [3, 1, 2, 4, 7, 8, 9, 6] (< pivot | >= pivot).
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
if global_i < size:
var current_val = input[global_i]
# Phase 1: Create warp-level predicates
var predicate_left = Scalar[dtype](
1.0
) if current_val < pivot else Scalar[dtype](0.0)
var predicate_right = Scalar[dtype](
1.0
) if current_val >= pivot else Scalar[dtype](0.0)
# Phase 2: Warp-level prefix sum to get positions within warp
var warp_left_pos = prefix_sum[exclusive=True](predicate_left)
var warp_right_pos = prefix_sum[exclusive=True](predicate_right)
# Phase 3: Get total left count using shuffle_xor reduction
var warp_left_total = predicate_left
# Butterfly reduction to get total across the warp: dynamic for any WARP_SIZE
var offset = WARP_SIZE // 2
while offset > 0:
warp_left_total += shuffle_xor(warp_left_total, UInt32(offset))
offset //= 2
# Phase 4: Write to output positions
if current_val < pivot:
# Left partition: use warp-level position
output[Int(warp_left_pos)] = current_val
else:
# Right partition: offset by total left count + right position
output[Int(warp_left_total + warp_right_pos)] = current_val
This solution demonstrates advanced coordination between multiple warp primitives to implement sophisticated parallel algorithms.
Complete algorithm analysis:
if global_i < size:
current_val = input[global_i]
# Phase 1: Create warp-level predicates
predicate_left = Float32(1.0) if current_val < pivot else Float32(0.0)
predicate_right = Float32(1.0) if current_val >= pivot else Float32(0.0)
# Phase 2: Warp-level prefix sum to get positions within warp
warp_left_pos = prefix_sum[exclusive=True](predicate_left)
warp_right_pos = prefix_sum[exclusive=True](predicate_right)
# Phase 3: Get total left count using shuffle_xor reduction
warp_left_total = predicate_left
# Butterfly reduction to get total across the warp: dynamic for any WARP_SIZE
offset = WARP_SIZE // 2
while offset > 0:
warp_left_total += shuffle_xor(warp_left_total, UInt32(offset))
offset //= 2
# Phase 4: Write to output positions
if current_val < pivot:
# Left partition: use warp-level position
output[Int(warp_left_pos)] = current_val
else:
# Right partition: offset by total left count + right position
output[Int(warp_left_total + warp_right_pos)] = current_val
Multi-phase execution trace (8-lane example, pivot=5, values [3,7,1,8,2,9,4,6]):
Initial state:
Lane 0: current_val=3 (< 5) Lane 1: current_val=7 (>= 5)
Lane 2: current_val=1 (< 5) Lane 3: current_val=8 (>= 5)
Lane 4: current_val=2 (< 5) Lane 5: current_val=9 (>= 5)
Lane 6: current_val=4 (< 5) Lane 7: current_val=6 (>= 5)
Phase 1: Create predicates
Lane 0: predicate_left=1.0, predicate_right=0.0
Lane 1: predicate_left=0.0, predicate_right=1.0
Lane 2: predicate_left=1.0, predicate_right=0.0
Lane 3: predicate_left=0.0, predicate_right=1.0
Lane 4: predicate_left=1.0, predicate_right=0.0
Lane 5: predicate_left=0.0, predicate_right=1.0
Lane 6: predicate_left=1.0, predicate_right=0.0
Lane 7: predicate_left=0.0, predicate_right=1.0
Phase 2: Exclusive prefix sum for positions
warp_left_pos: [0, 0, 1, 1, 2, 2, 3, 3]
warp_right_pos: [0, 0, 0, 1, 1, 2, 2, 3]
Phase 3: Butterfly reduction for left total
Initial: [1, 0, 1, 0, 1, 0, 1, 0]
After reduction: all lanes have warp_left_total = 4
Phase 4: Write to output positions
Lane 0: current_val=3 < pivot → output[0] = 3
Lane 1: current_val=7 >= pivot → output[4+0] = output[4] = 7
Lane 2: current_val=1 < pivot → output[1] = 1
Lane 3: current_val=8 >= pivot → output[4+1] = output[5] = 8
Lane 4: current_val=2 < pivot → output[2] = 2
Lane 5: current_val=9 >= pivot → output[4+2] = output[6] = 9
Lane 6: current_val=4 < pivot → output[3] = 4
Lane 7: current_val=6 >= pivot → output[4+3] = output[7] = 6
Final result: [3, 1, 2, 4, 7, 8, 9, 6] (< pivot | >= pivot)
Mathematical insight: This implements parallel partitioning with dual warp primitives: \[\Large \begin{align} \text{left_pos}[i] &= \text{prefix_sum}_{\text{exclusive}}(\text{predicate_left}[i]) \\ \text{right_pos}[i] &= \text{prefix_sum}_{\text{exclusive}}(\text{predicate_right}[i]) \\ \text{left_total} &= \text{butterfly_reduce}(\text{predicate_left}) \\ \text{final_pos}[i] &= \begin{cases} \text{left_pos}[i] & \text{if } \text{input}[i] < \text{pivot} \\ \text{left_total} + \text{right_pos}[i] & \text{if} \text{input}[i] \geq \text{pivot} \end{cases} \end{align}\]
Why this multi-primitive approach works:
- Predicate creation: Identifies partition membership for each element
- Exclusive prefix sum: Calculates relative positions within each partition
- Butterfly reduction: Computes partition boundary (total left count)
- Coordinated write: Combines local positions with global partition structure
Algorithm complexity:
- Phase 1: \(O(1)\) - Predicate creation
- Phase 2: \(O(\log n)\) - Hardware-accelerated prefix sum
- Phase 3: \(O(\log n)\) - Butterfly reduction with
shuffle_xor - Phase 4: \(O(1)\) - Coordinated write
- Total: \(O(\log n)\) with excellent constants
Performance characteristics:
- Communication steps: \(2 \times \log_2(\text{WARP_SIZE})\) (prefix sum + butterfly reduction)
- Memory efficiency: Zero shared memory, all register-based
- Parallelism: All lanes active throughout algorithm
- Scalability: Works for any
WARP_SIZE(32, 64, etc.)
Practical applications: This pattern is fundamental to:
- Quicksort partitioning: Core step in parallel sorting algorithms
- Stream compaction: Removing null/invalid elements from data streams
- Parallel filtering: Separating data based on complex predicates
- Load balancing: Redistributing work based on computational requirements
Summary
The prefix_sum() primitive enables hardware-accelerated parallel scan
operations that replace complex multi-phase algorithms with single function
calls. Through these two problems, you’ve learned:
Core Prefix Sum Patterns
-
Inclusive Prefix Sum (
prefix_sum[exclusive=False]):- Hardware-accelerated cumulative operations
- Replaces ~30 lines of shared memory code with single function call
- \(O(\log n)\) complexity with specialized hardware optimization
-
Advanced Multi-Primitive Coordination (combining
prefix_sum+shuffle_xor):- Sophisticated parallel algorithms within single warp
- Exclusive scan for position calculation + butterfly reduction for totals
- Complex partitioning operations with optimal parallel efficiency
Key Algorithmic Insights
Hardware Acceleration Benefits:
prefix_sum()leverages dedicated scan units on modern GPUs- Zero shared memory overhead compared to traditional approaches
- Automatic synchronization without explicit barriers
Multi-Primitive Coordination:
# Phase 1: Create predicates for partition membership
predicate = 1.0 if condition else 0.0
# Phase 2: Use prefix_sum for local positions
local_pos = prefix_sum[exclusive=True](predicate)
# Phase 3: Use shuffle_xor for global totals
global_total = butterfly_reduce(predicate)
# Phase 4: Combine for final positioning
final_pos = local_pos + partition_offset
Performance Advantages:
- Hardware optimization: Specialized scan units vs software implementation
- Memory efficiency: Register-only operations vs shared memory allocation
- Scalable complexity: \(O(\log n)\) with hardware acceleration
- Single-warp optimization: Perfect for algorithms within
WARP_SIZElimits
Practical Applications
These prefix sum patterns are fundamental to:
- Parallel scan operations: Cumulative sums, products, min/max scans
- Stream compaction: Parallel filtering and data reorganization
- Quicksort partitioning: Core parallel sorting algorithm building block
- Parallel algorithms: Load balancing, work distribution, data restructuring
The combination of prefix_sum() and shuffle_xor() demonstrates how modern
GPU warp primitives can implement sophisticated parallel algorithms with minimal
code complexity and optimal performance characteristics.
Puzzle 27: Block-Level Programming
Overview
Welcome to Puzzle 27: Block-Level Programming! This puzzle introduces you to the fundamental building blocks of GPU parallel programming - block-level communication primitives that enable sophisticated parallel algorithms across entire thread blocks. You’ll explore three essential communication patterns that replace complex manual synchronization with elegant, hardware-optimized operations.
What you’ll achieve: Transform from complex shared memory + barriers + tree reduction patterns (Puzzle 12) to elegant single-function-call algorithms that leverage hardware-optimized block-wide communication primitives across multiple warps.
Key insight: GPU thread blocks execute with sophisticated hardware coordination - Mojo’s block operations harness cross-warp communication and dedicated hardware units to provide complete parallel programming building blocks: reduction (all→one), scan (all→each), and broadcast (one→all).
What you’ll learn
Block-level communication model
Understand the three fundamental communication patterns within GPU thread blocks:
GPU Thread Block (128 threads across 4 or 2 warps, hardware coordination)
All-to-One (Reduction): All threads → Single result at thread 0
All-to-Each (Scan): All threads → Each gets cumulative position
One-to-All (Broadcast): Thread 0 → All threads get same value
Cross-warp coordination:
├── Warp 0 (threads 0-31) ──block.sum()──┐
├── Warp 1 (threads 32-63) ──block.sum()──┼→ Thread 0 result
├── Warp 2 (threads 64-95) ──block.sum()──┤
└── Warp 3 (threads 96-127) ──block.sum()──┘
Hardware reality:
- Cross-warp synchronization: Automatic coordination across multiple warps within a block
- Dedicated hardware units: Specialized scan units and butterfly reduction networks
- Zero explicit barriers: Hardware manages all synchronization internally
- Logarithmic complexity: \(O(\log n)\) algorithms with single-instruction simplicity
Block operations in Mojo
Learn the complete parallel programming toolkit from gpu.primitives.block:
block.sum(value): All-to-one reduction for totals, averages, maximum/minimum valuesblock.prefix_sum(value): All-to-each scan for parallel filtering and extractionblock.broadcast(value): One-to-all distribution for parameter sharing and coordination
Note: These primitives enable sophisticated parallel algorithms like statistical computations, histogram binning, and normalization workflows that would otherwise require dozens of lines of complex shared memory coordination code.
Performance transformation example
# Complex block-wide reduction (traditional approach - from Puzzle 12):
shared_memory[local_i] = my_value
barrier()
stride = 64
while stride > 0:
if local_i < stride:
shared_memory[local_i] += shared_memory[local_i + stride]
barrier()
stride //= 2
if local_i == 0:
output[block_idx.x] = shared_memory[0]
# Block operations eliminate all this complexity:
my_partial = compute_local_contribution()
total = block.sum[block_size=128, broadcast=False](my_partial) # Single call!
if local_i == 0:
output[block_idx.x] = total[0]
When block operations excel
Learn the performance characteristics:
| Algorithm Pattern | Traditional | Block Operations |
|---|---|---|
| Block-wide reductions | Shared memory + barriers | Single block.sum call |
| Parallel filtering | Complex indexing | block.prefix_sum coordination |
| Parameter sharing | Manual synchronization | Single block.broadcast call |
| Cross-warp algorithms | Explicit barrier management | Hardware-managed coordination |
The evolution of GPU programming patterns
Where we started: Manual coordination (Puzzle 12)
Complex but educational - explicit shared memory, barriers, and tree reduction:
# Manual approach: 15+ lines of complex synchronization
shared_memory[local_i] = my_value
barrier()
# Tree reduction with stride-based indexing...
stride = 64
while stride > 0:
if local_i < stride:
shared_memory[local_i] += shared_memory[local_i + stride]
barrier()
stride //= 2
The intermediate step: Warp programming (Puzzle 24)
Hardware-accelerated but limited scope - warp.sum() within 32-thread warps:
# Warp approach: 1 line but single warp only
total = warp.sum[warp_size=WARP_SIZE](val=partial_product)
The destination: Block programming (This puzzle)
Complete toolkit - hardware-optimized primitives across entire blocks:
# Block approach: 1 line across multiple warps (128+ threads)
total = block.sum[block_size=128, broadcast=False](val=partial_product)
The three fundamental communication patterns
Block-level programming provides three essential primitives that cover all parallel communication needs:
1. All-to-One: Reduction (block.sum())
- Pattern: All threads contribute → One thread receives result
- Use case: Computing totals, averages, finding maximum/minimum values
- Example: Dot product, statistical aggregation
- Hardware: Cross-warp butterfly reduction with automatic barriers
2. All-to-Each: Scan (block.prefix_sum())
- Pattern: All threads contribute → Each thread receives cumulative position
- Use case: Parallel filtering, stream compaction, histogram binning
- Example: Computing write positions for parallel data extraction
- Hardware: Parallel scan with cross-warp coordination
3. One-to-All: Broadcast (block.broadcast())
- Pattern: One thread provides → All threads receive same value
- Use case: Parameter sharing, configuration distribution
- Example: Sharing computed mean for normalization algorithms
- Hardware: Optimized distribution across multiple warps
Learning progression
Complete this puzzle in three parts, building from simple to sophisticated:
Part 1: Block.sum() Essentials
Transform complex reduction to simple function call
Learn the foundational block reduction pattern by implementing dot product with
block.sum(). This part shows how block operations replace 15+ lines of manual
barriers with a single optimized call.
Key concepts:
- Block-wide synchronization across multiple warps
- Hardware-optimized reduction patterns
- Thread 0 result management
- Performance comparison with traditional approaches
Expected outcome: Understand how block.sum() provides warp.sum()
simplicity at block scale.
Part 2: Block.prefix_sum() Parallel Histogram
Advanced parallel filtering and extraction
Build sophisticated parallel algorithms using block.prefix_sum() for histogram
binning. This part demonstrates how prefix sum enables complex data
reorganization that would be difficult with simple reductions.
Key concepts:
- Parallel filtering with binary predicates
- Coordinated write position computation
- Advanced partitioning algorithms
- Cross-thread data extraction patterns
Expected outcome: Understand how block.prefix_sum() enables sophisticated
parallel algorithms beyond simple aggregation.
Part 3: Block.broadcast() Vector Normalization
Complete workflow combining all patterns
Implement vector mean normalization using the complete block operations toolkit. This part shows how all three primitives work together to solve real computational problems with mathematical correctness.
Key concepts:
- One-to-all communication patterns
- Coordinated multi-phase algorithms
- Complete block operations workflow
- Real-world algorithm implementation
Expected outcome: Understand how to compose block operations for sophisticated parallel algorithms.
Why block operations matter
Code simplicity transformation:
Traditional approach: 20+ lines of barriers, shared memory, complex indexing
Block operations: 3-5 lines of composable, hardware-optimized primitives
Performance advantages:
- Hardware optimization: Leverages GPU architecture-specific optimizations
- Automatic synchronization: Eliminates manual barrier placement errors
- Composability: Operations work together seamlessly
- Portability: Same code works across different GPU architectures
Educational value:
- Conceptual clarity: Each operation has a clear communication purpose
- Progressive complexity: Build from simple reductions to complex algorithms
- Real applications: Patterns used extensively in scientific computing, graphics, AI
Prerequisites
Before starting this puzzle, you should have completed:
- Puzzle 12: Understanding of manual GPU synchronization
- Puzzle 24: Experience with warp-level programming
Expected learning outcomes
After completing all three parts, you’ll understand:
- When to use each block operation for different parallel communication needs
- How to compose operations to build sophisticated algorithms
- Performance trade-offs between manual and automated approaches
- Real-world applications of block-level programming patterns
- Architecture-independent programming using hardware-optimized primitives
Getting started
Recommended approach: Complete the three parts in sequence, as each builds on concepts from the previous parts. The progression from simple reduction → advanced partitioning → complete workflow provides the optimal learning path for understanding block-level GPU programming.
💡 Key insight: Block operations represent the sweet spot between programmer productivity and hardware performance - they provide the simplicity of high-level operations with the efficiency of carefully optimized low-level implementations. This puzzle teaches you to think at the right abstraction level for modern GPU programming.
block.sum() Essentials - Block-Level Dot Product
Implement the dot product we saw in puzzle 12 using
block-level sum
operations to replace complex shared memory patterns with simple function calls.
Each thread in the block will process one element and use block.sum() to
combine results automatically, demonstrating how block programming transforms
GPU synchronization across entire thread blocks.
Key insight: The block.sum() operation leverages block-wide execution to replace shared memory + barriers + tree reduction with expertly optimized implementations that work across all threads using warp patterns in a block. See technical investigation for LLVM analysis.
Key concepts
In this puzzle, you’ll learn:
- Block-level reductions with
block.sum() - Block-wide synchronization and thread coordination
- Cross-warp communication within a single block
- Performance transformation from complex to simple patterns
- Thread 0 result management and conditional writes
The mathematical operation is a dot product (inner product): \[\Large \text{output}[0] = \sum_{i=0}^{N-1} a[i] \times b[i]\]
But the implementation teaches fundamental patterns for all block-level GPU programming in Mojo.
Configuration
- Vector size:
SIZE = 128elements - Data type:
DType.float32 - Block configuration:
(128, 1)threads per block (TPB = 128) - Grid configuration:
(1, 1)blocks per grid - Layout:
row_major[SIZE]()(1D row-major) - Warps per block:
128 / WARP_SIZE(4 warps on NVIDIA, 2 or 4 warps on AMD)
The traditional complexity (from Puzzle 12)
Recall the complex approach from Puzzle 12 that required shared memory, barriers, and tree reduction:
def traditional_dot_product[
tpb: Int
](
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
size: Int,
):
"""Traditional dot product using shared memory + barriers + tree reduction.
Educational but complex - shows the manual coordination needed."""
var shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[tpb]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Each thread computes partial product
if global_i < size:
var a_val = rebind[Scalar[dtype]](a[global_i])
var b_val = rebind[Scalar[dtype]](b[global_i])
shared[local_i] = a_val * b_val
barrier()
# Tree reduction in shared memory - complex but educational
var stride = tpb // 2
while stride > 0:
if local_i < stride:
shared[local_i] += shared[local_i + stride]
barrier()
stride //= 2
# Only thread 0 writes final result
if local_i == 0:
output[0] = shared[0]
What makes this complex:
- Shared memory allocation: Manual memory management within blocks
- Explicit barriers:
barrier()calls to synchronize all threads in block - Tree reduction: Complex loop with stride-based indexing (64→32→16→8→4→2→1)
- Cross-warp coordination: Must synchronize across multiple warps
- Conditional writes: Only thread 0 writes the final result
This works across the entire block (128 threads across 2 or 4 warps depending on GPU), but it’s verbose, error-prone, and requires deep understanding of block-level GPU synchronization.
The warp-level improvement (from Puzzle 24)
Before jumping to block-level operations, recall how
Puzzle 24 simplified reduction within a single warp
using warp.sum():
def simple_warp_dot_product[
InLayoutT: TensorLayout, OutLayoutT: TensorLayout, size: Int
](
output: TileTensor[mut=True, dtype, OutLayoutT, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayoutT, MutAnyOrigin],
b: TileTensor[mut=False, dtype, InLayoutT, MutAnyOrigin],
):
var a_lt = a.to_layout_tensor()
var b_lt = b.to_layout_tensor()
var out_lt = output.to_layout_tensor()
var global_i = block_dim.x * block_idx.x + thread_idx.x
# Each thread computes one partial product using vectorized approach as values in Mojo are SIMD based
var partial_product: Scalar[dtype] = 0
if global_i < size:
partial_product = rebind[Scalar[dtype]](a_lt[global_i]) * rebind[
Scalar[dtype]
](b_lt[global_i])
# warp_sum() replaces all the shared memory + barriers + tree reduction
var total = warp_sum(partial_product)
# Only lane 0 writes the result (all lanes have the same total)
if lane_id() == 0:
out_lt.store[1](Index(global_i // WARP_SIZE), total)
What warp.sum() achieved:
- Single warp scope: Works within 32 threads (NVIDIA) or 32/64 threads (AMD)
- Hardware shuffle: Uses
shfl.sync.bfly.b32instructions for efficiency - Zero shared memory: No explicit memory management needed
- One line reduction:
total = warp_sum[warp_size=WARP_SIZE](val=partial_product)
But the limitation: warp.sum() only works within a single warp. For
problems requiring multiple warps (like our 128-thread block), you’d still need
the complex shared memory + barriers approach to coordinate between warps.
Test the traditional approach:
pixi run p27 --traditional-dot-product
pixi run -e amd p27 --traditional-dot-product
pixi run -e apple p27 --traditional-dot-product
uv run poe p27 --traditional-dot-product
Code to complete
block.sum() approach
Transform the complex traditional approach into a simple block kernel using
block.sum():
comptime SIZE = 128
comptime TPB = 128
comptime NUM_BINS = 8
comptime in_layout = row_major[SIZE]()
comptime InLayoutType = type_of(in_layout)
comptime out_layout = row_major[1]()
comptime OutLayoutType = type_of(out_layout)
comptime dtype = DType.float32
def block_sum_dot_product[
tpb: Int
](
output: TileTensor[mut=True, dtype, OutLayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, InLayoutType, ImmutAnyOrigin],
size: Int,
):
"""Dot product using block.sum() - convenience function like warp.sum()!
Replaces manual shared memory + barriers + tree reduction with one line."""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# FILL IN (roughly 6 lines)
View full file: problems/p27/p27.mojo
pixi run p27 --block-sum-dot-product
pixi run -e amd p27 --block-sum-dot-product
uv run poe p27 --block-sum-dot-product
Expected output when solved:
SIZE: 128
TPB: 128
Expected result: 1381760.0
Block.sum result: 1381760.0
Block.sum() gives identical results!
Compare the code: 15+ lines of barriers → 1 line of block.sum()!
Just like warp.sum() but for the entire block
Tips
1. Think about the three-step pattern
Every block reduction follows the same conceptual pattern:
- Each thread computes its local contribution
- All threads participate in a block-wide reduction
- One designated thread handles the final result
2. Remember the dot product math
Each thread should handle one element pair from vectors a and b. What
operation combines these into a “partial result” that can be summed across
threads?
3. TileTensor indexing patterns
When accessing TileTensor elements, remember that indexing returns SIMD
values. You’ll need to extract the scalar value for arithmetic operations.
4. block.sum() API concepts
Study the function signature - it needs:
- A template parameter specifying the block size
- A template parameter for result distribution (
broadcast) - A runtime parameter containing the value to reduce
5. Thread coordination principles
- Which threads have valid data to process? (Hint: bounds checking)
- Which thread should write the final result? (Hint: consistent choice)
- How do you identify that specific thread? (Hint: thread indexing)
Solution
def block_sum_dot_product[
tpb: Int
](
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
size: Int,
):
"""Dot product using block.sum() - convenience function like warp.sum()!
Replaces manual shared memory + barriers + tree reduction with one line."""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Each thread computes partial product
var partial_product: Scalar[dtype] = 0.0
if global_i < size:
# TileTensor indexing `[0]` returns the underlying SIMD value
partial_product = a[global_i][0] * b[global_i][0]
# The magic: block.sum() replaces 15+ lines of manual reduction!
# Just like warp.sum() but for the entire block
var total = block.sum[block_size=tpb, broadcast=False](
val=SIMD[DType.float32, 1](partial_product)
)
# Only thread 0 writes the result
if local_i == 0:
output[0] = total[0]
The block.sum() kernel demonstrates the fundamental transformation from
complex block synchronization to expertly optimized implementations:
What disappeared from the traditional approach:
- 15+ lines → 8 lines: Dramatic code reduction
- Shared memory allocation: Zero memory management required
- 7+ barrier() calls: Zero explicit synchronization needed
- Complex tree reduction: Single function call
- Stride-based indexing: Eliminated entirely
- Cross-warp coordination: Handled automatically by optimized implementation
Block-wide execution model:
Block threads (128 threads across 4 warps):
Warp 0 (threads 0-31):
Thread 0: partial_product = a[0] * b[0] = 0.0
Thread 1: partial_product = a[1] * b[1] = 2.0
...
Thread 31: partial_product = a[31] * b[31] = 1922.0
Warp 1 (threads 32-63):
Thread 32: partial_product = a[32] * b[32] = 2048.0
...
Warp 2 (threads 64-95):
Thread 64: partial_product = a[64] * b[64] = 8192.0
...
Warp 3 (threads 96-127):
Thread 96: partial_product = a[96] * b[96] = 18432.0
Thread 127: partial_product = a[127] * b[127] = 32258.0
block.sum() hardware operation:
All threads → 0.0 + 2.0 + 1922.0 + 2048.0 + ... + 32258.0 = 1381760.0
Thread 0 receives → total = 1381760.0 (when broadcast=False)
Why this works without barriers:
- Block-wide execution: All threads execute each instruction in lockstep within warps
- Built-in synchronization:
block.sum()implementation handles synchronization internally - Cross-warp communication: Optimized communication between warps in the block
- Coordinated result delivery: Only thread 0 receives the final result
Comparison to warp.sum() (Puzzle 24):
- Warp scope:
warp.sum()works within 32/64 threads (single warp) - Block scope:
block.sum()works across entire block (multiple warps) - Same simplicity: Both replace complex manual reductions with one-line calls
- Automatic coordination:
block.sum()handles the cross-warp barriers thatwarp.sum()cannot
Technical investigation: What does block.sum() actually compile to?
To understand what block.sum() actually generates, we compiled the puzzle with
debug information:
pixi run mojo build --emit llvm --debug-level=line-tables solutions/p27/p27.mojo -o solutions/p27/p27.ll
This generated LLVM file solutions/p27/p27.ll. For example, on a
compatible NVIDIA GPU, the p27.ll file has embedded PTX assembly showing
the actual GPU instructions:
Finding 1: Not a single instruction
block.sum() compiles to approximately 20+ PTX instructions, organized in a
two-phase reduction:
Phase 1: Warp-level reduction (butterfly shuffles)
shfl.sync.bfly.b32 %r23, %r46, 16, 31, -1; // shuffle with offset 16
add.f32 %r24, %r46, %r23; // add shuffled values
shfl.sync.bfly.b32 %r25, %r24, 8, 31, -1; // shuffle with offset 8
add.f32 %r26, %r24, %r25; // add shuffled values
// ... continues for offsets 4, 2, 1
Phase 2: Cross-warp coordination
shr.u32 %r32, %r1, 5; // compute warp ID
mov.b32 %r34, _global_alloc_$__gpu_shared_mem; // shared memory
bar.sync 0; // barrier synchronization
// ... another butterfly shuffle sequence for cross-warp reduction
Finding 2: Hardware-optimized implementation
- Butterfly shuffles: More efficient than tree reduction
- Automatic barrier placement: Handles cross-warp synchronization
- Optimized memory access: Uses shared memory strategically
- Architecture-aware: Same API works on NVIDIA (32-thread warps) and AMD (32 or 64-thread warps)
Finding 3: Algorithm complexity analysis
Our approach to investigation:
- Located PTX assembly in binary ELF sections (
.nv_debug_ptx_txt) - Identified algorithmic differences rather than counting individual instructions
Key algorithmic differences observed:
- Traditional: Tree reduction with shared memory + multiple
bar.synccalls - block.sum(): Butterfly shuffle pattern + optimized cross-warp coordination
The performance advantage comes from expertly optimized algorithm choice (butterfly > tree), not from instruction count or magical hardware. Take a look at block.mojo in Mojo gpu module for more details about the implementation.
Performance insights
block.sum() vs Traditional:
- Code simplicity: 15+ lines → 1 line for the reduction
- Memory usage: No shared memory allocation required
- Synchronization: No explicit barriers needed
- Scalability: Works with any block size (up to hardware limits)
block.sum() vs warp.sum():
- Scope: Block-wide (128 threads) vs warp-wide (32 threads)
- Use case: When you need reduction across entire block
- Convenience: Same programming model, different scale
When to use block.sum():
- Single block problems: When all data fits in one block
- Block-level algorithms: Shared memory computations needing reduction
- Convenience over scalability: Simpler than multi-block approaches
Relationship to previous puzzles
From Puzzle 12 (Traditional):
Complex: shared memory + barriers + tree reduction
↓
Simple: block.sum() hardware primitive
From Puzzle 24 (warp.sum()):
Warp-level: warp.sum() across 32 threads (single warp)
↓
Block-level: block.sum() across 128 threads (multiple warps)
Three-stage progression:
- Manual reduction (Puzzle 12): Complex shared memory + barriers + tree reduction
- Warp primitives (Puzzle 24):
warp.sum()- simple but limited to single warp - Block primitives (Puzzle 27):
block.sum()- extends warp simplicity across multiple warps
The key insight: block.sum() gives you the simplicity of warp.sum() but
scales across an entire block by automatically handling the complex cross-warp
coordination that you’d otherwise need to implement manually.
Next steps
Once you’ve learned about block.sum() operations, you’re ready for:
- Block Prefix Sum Operations: Cumulative operations across block threads
- Block Broadcast Operations: Sharing values across all threads in a block
💡 Key Takeaway: Block operations extend warp programming concepts to entire
thread blocks, providing optimized primitives that replace complex
synchronization patterns while working across multiple warps simultaneously.
Just like warp.sum() simplified warp-level reductions, block.sum()
simplifies block-level reductions without sacrificing performance.
block.prefix_sum() Parallel Histogram Binning
This puzzle implements parallel histogram binning using block-level
block.prefix_sum
operations for advanced parallel filtering and extraction. Each thread
determines its element’s target bin, then applies block.prefix_sum() to
compute write positions for extracting elements from a specific bin, showing how
prefix sum enables sophisticated parallel partitioning beyond simple reductions.
Key insight: The block.prefix_sum() operation provides parallel filtering and extraction by computing cumulative write positions for matching elements across all threads in a block.
Key concepts
This puzzle covers:
- Block-level prefix sum with
block.prefix_sum() - Parallel filtering and extraction using cumulative computations
- Advanced parallel partitioning algorithms
- Histogram binning with block-wide coordination
- Exclusive vs inclusive prefix sum patterns
The algorithm constructs histograms by extracting elements belonging to specific value ranges (bins): \[\Large \text{Bin}_k = \{x_i: k/N \leq x_i < (k+1)/N\}\]
Each thread determines its element’s bin assignment, with block.prefix_sum()
coordinating parallel extraction.
Configuration
- Vector size:
SIZE = 128elements - Data type:
DType.float32 - Block configuration:
(128, 1)threads per block (TPB = 128) - Grid configuration:
(1, 1)blocks per grid - Number of bins:
NUM_BINS = 8(ranges [0.0, 0.125), [0.125, 0.25), etc.) - Layout:
row_major[SIZE]()(1D row-major) - Warps per block:
128 / WARP_SIZE(2 or 4 warps depending on GPU)
The challenge: Parallel bin extraction
Traditional sequential histogram construction processes elements one by one:
# Sequential approach - doesn't parallelize well
histogram = [[] for _ in range(NUM_BINS)]
for element in data:
bin_id = int(element * NUM_BINS) # Determine bin
histogram[bin_id].append(element) # Sequential append
Problems with naive GPU parallelization:
- Race conditions: Multiple threads writing to same bin simultaneously
- Uncoalesced memory: Threads access different memory locations
- Load imbalance: Some bins may have many more elements than others
- Complex synchronization: Need barriers and atomic operations
The advanced approach: block.prefix_sum() coordination
Transform the complex parallel partitioning into coordinated extraction:
Code to complete
block.prefix_sum() approach
Implement parallel histogram binning using block.prefix_sum() for extraction:
comptime bin_layout = row_major[SIZE]() # Max SIZE elements per bin
comptime BinLayoutType = type_of(bin_layout)
def block_histogram_bin_extract[
tpb: Int
](
input_data: TileTensor[mut=False, dtype, InLayoutType, ImmutAnyOrigin],
bin_output: TileTensor[mut=True, dtype, BinLayoutType, MutAnyOrigin],
count_output: TileTensor[
mut=True, DType.int32, OutLayoutType, MutAnyOrigin
],
size: Int,
target_bin: Int,
num_bins: Int,
):
"""Parallel histogram using block.prefix_sum() for bin extraction.
This demonstrates advanced parallel filtering and extraction:
1. Each thread determines which bin its element belongs to
2. Use block.prefix_sum() to compute write positions for target_bin elements
3. Extract and pack only elements belonging to target_bin
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Step 1: Each thread determines its bin and element value
# FILL IN (roughly 9 lines)
# Step 2: Create predicate for target bin extraction
# FILL IN (roughly 3 line)
# Step 3: Use block.prefix_sum() for parallel bin extraction!
# This computes where each thread should write within the target bin
# FILL IN (1 line)
# Step 4: Extract and pack elements belonging to target_bin
# FILL IN (roughly 2 line)
# Step 5: Final thread computes total count for this bin
# FILL IN (roughly 3 line)
View full file: problems/p27/p27.mojo
Tips
1. Core algorithm structure (adapt from previous puzzles)
Just like block_sum_dot_product, you need these key variables:
global_i = block_dim.x * block_idx.x + thread_idx.x
local_i = thread_idx.x
Your function will have 5 main steps (about 15-20 lines total):
- Load element and determine its bin
- Create binary predicate for target bin
- Run
block.prefix_sum()on the predicate - Conditionally write using computed offset
- Final thread computes total count
2. Bin calculation (use math.floor)
To classify a Float32 value into bins:
my_value = input_data[global_i][0] # Extract SIMD like in dot product
bin_number = Int(floor(my_value * Float32(num_bins)))
Edge case handling: Values exactly 1.0 would go to bin NUM_BINS, but you
only have bins 0 to NUM_BINS-1. Use an if statement to clamp the maximum
bin.
3. Binary predicate creation
Create an integer variable (0 or 1) indicating if this thread’s element belongs to target_bin:
var belongs_to_target: Int = 0
if (thread_has_valid_element) and (my_bin == target_bin):
belongs_to_target = 1
This is the key insight: prefix sum works on these binary flags to compute positions!
4. block.prefix_sum() call pattern
Following the documentation, the call looks like:
offset = block.prefix_sum[
dtype=DType.int32, # Working with integer predicates
block_size=tpb, # Same as block.sum()
exclusive=True # Key: gives position BEFORE each thread
](val=SIMD[DType.int32, 1](my_predicate_value))
Why exclusive? Thread with predicate=1 at position 5 should write to output[4] if 4 elements came before it.
5. Conditional writing pattern
Only threads with belongs_to_target == 1 should write:
if belongs_to_target == 1:
bin_output[Int(offset[0])] = my_value # Convert SIMD to Int for indexing
This is just like the bounds checking pattern from Puzzle 12, but now the condition is “belongs to target bin.”
6. Final count computation
The last thread (not thread 0!) computes the total count:
if local_i == tpb - 1: # Last thread in block
total_count = offset[0] + Int32(belongs_to_target) # Inclusive = exclusive + own contribution
count_output[0] = total_count
Why last thread? It has the highest offset value, so
offset + contribution gives the total.
7. Data types and conversions
Remember the patterns from previous puzzles:
TileTensorindexing returns SIMD:input_data[i][0]block.prefix_sum()returns SIMD:offset[0]to extract- Array indexing needs
Int:Int(offset[0])forbin_output[...]
Test the block.prefix_sum() approach:
pixi run p27 --histogram
pixi run -e amd p27 --histogram
pixi run -e apple p27 --histogram
uv run poe p27 --histogram
Expected output when solved:
SIZE: 128
TPB: 128
NUM_BINS: 8
Input sample: 0.0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 0.11 0.12 0.13 0.14 0.15 ...
=== Processing Bin 0 (range [ 0.0 , 0.125 )) ===
Bin 0 count: 26
Bin 0 extracted elements: 0.0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 ...
=== Processing Bin 1 (range [ 0.125 , 0.25 )) ===
Bin 1 count: 24
Bin 1 extracted elements: 0.13 0.14 0.15 0.16 0.17 0.18 0.19 0.2 ...
=== Processing Bin 2 (range [ 0.25 , 0.375 )) ===
Bin 2 count: 26
Bin 2 extracted elements: 0.25 0.26 0.27 0.28 0.29 0.3 0.31 0.32 ...
=== Processing Bin 3 (range [ 0.375 , 0.5 )) ===
Bin 3 count: 22
Bin 3 extracted elements: 0.38 0.39 0.4 0.41 0.42 0.43 0.44 0.45 ...
=== Processing Bin 4 (range [ 0.5 , 0.625 )) ===
Bin 4 count: 13
Bin 4 extracted elements: 0.5 0.51 0.52 0.53 0.54 0.55 0.56 0.57 ...
=== Processing Bin 5 (range [ 0.625 , 0.75 )) ===
Bin 5 count: 12
Bin 5 extracted elements: 0.63 0.64 0.65 0.66 0.67 0.68 0.69 0.7 ...
=== Processing Bin 6 (range [ 0.75 , 0.875 )) ===
Bin 6 count: 5
Bin 6 extracted elements: 0.75 0.76 0.77 0.78 0.79
=== Processing Bin 7 (range [ 0.875 , 1.0 )) ===
Bin 7 count: 0
Bin 7 extracted elements:
Solution
def block_histogram_bin_extract[
tpb: Int
](
input_data: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
bin_output: TileTensor[mut=True, dtype, BinLayout, MutAnyOrigin],
count_output: TileTensor[mut=True, DType.int32, OutLayout, MutAnyOrigin],
size: Int,
target_bin: Int,
num_bins: Int,
):
"""Parallel histogram using block.prefix_sum() for bin extraction.
This demonstrates advanced parallel filtering and extraction:
1. Each thread determines which bin its element belongs to
2. Use block.prefix_sum() to compute write positions for target_bin elements
3. Extract and pack only elements belonging to target_bin
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Step 1: Each thread determines its bin and element value
var my_value: Scalar[dtype] = 0.0
var my_bin: Int = -1
if global_i < size:
# `[0]` returns the underlying SIMD value
my_value = input_data[global_i][0]
# Bin values [0.0, 1.0) into num_bins buckets
my_bin = Int(floor(my_value * Scalar[dtype](num_bins)))
# Clamp to valid range
if my_bin >= num_bins:
my_bin = num_bins - 1
if my_bin < 0:
my_bin = 0
# Step 2: Create predicate for target bin extraction
var belongs_to_target: Int = 0
if global_i < size and my_bin == target_bin:
belongs_to_target = 1
# Step 3: Use block.prefix_sum() for parallel bin extraction!
# This computes where each thread should write within the target bin
var write_offset = block.prefix_sum[
dtype=DType.int32, block_size=tpb, exclusive=True
](val=SIMD[DType.int32, 1](belongs_to_target))
# Step 4: Extract and pack elements belonging to target_bin
if belongs_to_target == 1:
bin_output[Int(write_offset[0])] = my_value
# Step 5: Final thread computes total count for this bin
if local_i == tpb - 1:
# Inclusive sum = exclusive sum + my contribution
var total_count = write_offset[0] + Int32(belongs_to_target)
count_output[0] = total_count
The block.prefix_sum() kernel demonstrates advanced parallel coordination
patterns by building on concepts from previous puzzles:
Step-by-step algorithm walkthrough:
Phase 1: Element processing (like Puzzle 12 dot product)
Thread indexing (familiar pattern):
global_i = block_dim.x * block_idx.x + thread_idx.x // Global element index
local_i = thread_idx.x // Local thread index
Element loading (like TileTensor pattern):
Thread 0: my_value = input_data[0][0] = 0.00
Thread 1: my_value = input_data[1][0] = 0.01
Thread 13: my_value = input_data[13][0] = 0.13
Thread 25: my_value = input_data[25][0] = 0.25
...
Phase 2: Bin classification (new concept)
Bin calculation using floor operation:
Thread 0: my_bin = Int(floor(0.00 * 8)) = 0 // Values [0.000, 0.125) → bin 0
Thread 1: my_bin = Int(floor(0.01 * 8)) = 0 // Values [0.000, 0.125) → bin 0
Thread 13: my_bin = Int(floor(0.13 * 8)) = 1 // Values [0.125, 0.250) → bin 1
Thread 25: my_bin = Int(floor(0.25 * 8)) = 2 // Values [0.250, 0.375) → bin 2
...
Phase 3: Binary predicate creation (filtering pattern)
For target_bin=0, create extraction mask:
Thread 0: belongs_to_target = 1 (bin 0 == target 0)
Thread 1: belongs_to_target = 1 (bin 0 == target 0)
Thread 13: belongs_to_target = 0 (bin 1 != target 0)
Thread 25: belongs_to_target = 0 (bin 2 != target 0)
...
This creates binary array: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, ...]
Phase 4: Parallel prefix sum (the magic!)
block.prefix_sum[exclusive=True] on predicates:
Input: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, ...]
Exclusive: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12, -, -, -, ...]
^
doesn't matter
Key insight: Each thread gets its WRITE POSITION in the output array!
Phase 5: Coordinated extraction (conditional write)
Only threads with belongs_to_target=1 write:
Thread 0: bin_output[0] = 0.00 // Uses write_offset[0] = 0
Thread 1: bin_output[1] = 0.01 // Uses write_offset[1] = 1
Thread 12: bin_output[12] = 0.12 // Uses write_offset[12] = 12
Thread 13: (no write) // belongs_to_target = 0
Thread 25: (no write) // belongs_to_target = 0
...
Result: [0.00, 0.01, 0.02, ..., 0.12, ???, ???, ...] // Perfectly packed!
Phase 6: Count computation (like block.sum() pattern)
Last thread computes total (not thread 0!):
if local_i == tpb - 1: // Thread 127 in our case
total = write_offset[0] + Int32(belongs_to_target) // Inclusive sum formula
count_output[0] = total
Why this advanced algorithm works:
Connection to Puzzle 12 (Traditional dot product):
- Same thread indexing:
global_iandlocal_ipatterns - Same bounds checking:
if global_i < sizevalidation - Same data loading: TileTensor SIMD extraction with
[0]
Connection to block.sum() (earlier in this puzzle):
- Same block-wide operation: All threads participate in block primitive
- Same result handling: Special thread (last instead of first) handles final result
- Same SIMD conversion:
Int(result[0])pattern for array indexing
Advanced concepts unique to block.prefix_sum():
- Every thread gets result: Unlike
block.sum()where only thread 0 matters - Coordinated write positions: Prefix sum eliminates race conditions automatically
- Parallel filtering: Binary predicates enable sophisticated data reorganization
Performance advantages over naive approaches:
vs. Atomic operations:
- No race conditions: Prefix sum gives unique write positions
- Coalesced memory: Sequential writes improve cache performance
- No serialization: All writes happen in parallel
vs. Multi-pass algorithms:
- Single kernel: Complete histogram extraction in one GPU launch
- Full utilization: All threads work regardless of data distribution
- Optimal memory bandwidth: Pattern optimized for GPU memory hierarchy
This demonstrates how block.prefix_sum() enables sophisticated parallel
algorithms that would be complex or impossible with simpler primitives like
block.sum().
Performance insights
block.prefix_sum() vs Traditional:
- Algorithm sophistication: Advanced parallel partitioning vs sequential processing
- Memory efficiency: Coalesced writes vs scattered random access
- Synchronization: Built-in coordination vs manual barriers and atomics
- Scalability: Works with any block size and bin count
block.prefix_sum() vs block.sum():
- Scope: Every thread gets result vs only thread 0
- Use case: Complex partitioning vs simple aggregation
- Algorithm type: Parallel scan primitive vs reduction primitive
- Output pattern: Per-thread positions vs single total
When to use block.prefix_sum():
- Parallel filtering: Extract elements matching criteria
- Stream compaction: Remove unwanted elements
- Parallel partitioning: Separate data into categories
- Advanced algorithms: Load balancing, sorting, graph algorithms
Next steps
Once you’ve learned about block.prefix_sum() operations, you’re ready for:
- Block Broadcast Operations: Sharing values across all threads in a block
- Multi-block algorithms: Coordinating multiple blocks for larger problems
- Advanced parallel algorithms: Sorting, graph traversal, dynamic load balancing
- Complex memory patterns: Combining block operations with sophisticated memory access
💡 Key Takeaway: Block prefix sum operations transform GPU programming from
simple parallel computations to sophisticated parallel algorithms. While
block.sum() simplified reductions, block.prefix_sum() enables advanced data
reorganization patterns essential for high-performance parallel algorithms.
block.broadcast() Vector Normalization
Implement vector mean normalization by combining block.sum and block.broadcast operations to demonstrate the complete block-level communication workflow. Each thread will contribute to computing the mean, then receive the broadcast mean to normalize its element, showcasing how block operations work together to solve real parallel algorithms.
Key insight: The block.broadcast() operation enables one-to-all communication, completing the fundamental block communication patterns: reduction (all→one), scan (all→each), and broadcast (one→all).
Key concepts
In this puzzle, you’ll learn:
- Block-level broadcast with
block.broadcast() - One-to-all communication patterns
- Source thread specification and parameter control
- Complete block operations workflow combining multiple operations
- Real-world algorithm implementation using coordinated block primitives
The algorithm demonstrates vector mean normalization: \[\Large \text{output}[i] = \frac{\text{input}[i]}{\frac{1}{N}\sum_{j=0}^{N-1} \text{input}[j]}\]
Each thread contributes to the mean calculation, then receives the broadcast mean to normalize its element.
Configuration
- Vector size:
SIZE = 128elements - Data type:
DType.float32 - Block configuration:
(128, 1)threads per block (TPB = 128) - Grid configuration:
(1, 1)blocks per grid - Layout:
row_major[SIZE]()(1D row-major for input and output) - Test data: Values cycling 1-8, so mean = 4.5
- Expected output: Normalized vector with mean = 1.0
The challenge: Coordinating block-wide computation and distribution
Traditional approaches to mean normalization require complex coordination:
# Sequential approach - doesn't utilize parallelism
total = sum(input_array)
mean = total / len(input_array)
output_array = [x / mean for x in input_array]
Problems with naive GPU parallelization:
- Multiple kernel launches: One pass to compute mean, another to normalize
- Global memory round-trip: Store mean to global memory, read back later
- Synchronization complexity: Need barriers between computation phases
- Thread divergence: Different threads doing different tasks
Traditional GPU solution complexity:
# Phase 1: Reduce to find sum (complex shared memory + barriers)
shared_sum[local_i] = my_value
barrier()
# Manual tree reduction with multiple barrier() calls...
# Phase 2: Thread 0 computes mean
if local_i == 0:
mean = shared_sum[0] / size
shared_mean[0] = mean
barrier()
# Phase 3: All threads read mean and normalize
mean = shared_mean[0] # Everyone reads the same value
output[global_i] = my_value / mean
The advanced approach: block.sum() + block.broadcast() coordination
Transform the multi-phase coordination into elegant block operations workflow:
Code to complete
Complete block operations workflow
Implement sophisticated vector mean normalization using the full block operations toolkit:
comptime vector_layout = row_major[SIZE]()
comptime VectorLayoutType = type_of(vector_layout)
def block_normalize_vector[
tpb: Int
](
input_data: TileTensor[mut=False, dtype, InLayoutType, ImmutAnyOrigin],
output_data: TileTensor[mut=True, dtype, VectorLayoutType, MutAnyOrigin],
size: Int,
):
"""Vector mean normalization using block.sum() + block.broadcast() combination.
This demonstrates the complete block operations workflow:
1. Use block.sum() to compute sum of all elements (all → one)
2. Thread 0 computes mean = sum / size
3. Use block.broadcast() to share mean to all threads (one → all)
4. Each thread normalizes: output[i] = input[i] / mean
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Step 1: Each thread loads its element
# FILL IN (roughly 3 lines)
# Step 2: Use block.sum() to compute total sum (familiar from earlier!)
# FILL IN (1 line)
# Step 3: Thread 0 computes mean value
# FILL IN (roughly 4 lines)
# Step 4: block.broadcast() shares mean to ALL threads!
# This completes the block operations trilogy demonstration
# FILL IN (1 line)
# Step 5: Each thread normalizes by the mean
# FILL IN (roughly 3 lines)
View full file: problems/p27/p27.mojo
Tips
1. Complete workflow structure (builds on all previous operations)
The algorithm follows the perfect block operations pattern:
- Each thread loads its element (familiar from all previous puzzles)
- Use
block.sum()to compute total (from earlier in this puzzle) - Thread 0 computes mean from the sum
- Use
block.broadcast()to share mean to all threads (NEW!) - Each thread normalizes using the broadcast mean
2. Data loading and sum computation (familiar patterns)
Load your element using the established TileTensor pattern:
var my_value: Scalar[dtype] = 0.0
if global_i < size:
my_value = input_data[global_i][0] # SIMD extraction
Then use block.sum() exactly like the dot product earlier:
total_sum = block.sum[block_size=tpb, broadcast=False](...)
3. Mean computation (thread 0 only)
Only thread 0 should compute the mean:
var mean_value: Scalar[dtype] = 1.0 # Safe default
if local_i == 0:
# Compute mean from total_sum and size
Why thread 0? Consistent with block.sum() pattern where thread 0 receives
the result.
4. block.broadcast() API concepts
Study the function signature - it needs:
- Template parameters:
dtype,width,block_size - Runtime parameters:
val(SIMD value to broadcast),src_thread(default=0)
The call pattern follows the established template style:
result = block.broadcast[
dtype = DType.float32,
width = 1,
block_size = tpb
](val=SIMD[DType.float32, 1](value_to_broadcast), src_thread=UInt(0))
5. Understanding the broadcast pattern
Key insight: block.broadcast() takes a value from ONE thread and gives it
to ALL threads:
- Thread 0 has the computed mean value
- All threads need that same mean value
block.broadcast()copies thread 0’s value to everyone
This is the opposite of block.sum() (all→one) and different from
block.prefix_sum() (all→each position).
6. Final normalization step
Once every thread has the broadcast mean, normalize your element:
if global_i < size:
normalized_value = my_value / broadcasted_mean[0] # Extract SIMD
output_data[global_i] = normalized_value
SIMD extraction: Remember that block.broadcast() returns SIMD, so use
[0] to extract the scalar.
7. Pattern recognition from previous puzzles
- Thread indexing: Same
global_i,local_ipattern as always - Bounds checking: Same
if global_i < sizevalidation - SIMD handling: Same
[0]extraction patterns - Block operations: Same template parameter style as
block.sum()
The beauty is that each block operation follows consistent patterns!
Test the block.broadcast() approach:
pixi run p27 --normalize
pixi run -e amd p27 --normalize
pixi run -e apple p27 --normalize
uv run poe p27 --normalize
Expected output when solved:
SIZE: 128
TPB: 128
Input sample: 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 ...
Sum value: 576.0
Mean value: 4.5
Mean Normalization Results:
Normalized sample: 0.22222222 0.44444445 0.6666667 0.8888889 1.1111112 1.3333334 1.5555556 1.7777778 ...
Output sum: 128.0
Output mean: 1.0
✅ Success: Output mean is 1.0 (should be close to 1.0)
Solution
def block_normalize_vector[
tpb: Int
](
input_data: TileTensor[mut=False, dtype, InLayout, ImmutAnyOrigin],
output_data: TileTensor[mut=True, dtype, VectorLayout, MutAnyOrigin],
size: Int,
):
"""Vector mean normalization using block.sum() + block.broadcast() combination.
This demonstrates the complete block operations workflow:
1. Use block.sum() to compute sum of all elements (all -> one)
2. Thread 0 computes mean = sum / size
3. Use block.broadcast() to share mean to all threads (one -> all)
4. Each thread normalizes: output[i] = input[i] / mean
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Step 1: Each thread loads its element
var my_value: Scalar[dtype] = 0.0
if global_i < size:
my_value = input_data[global_i][0] # Extract SIMD value
# Step 2: Use block.sum() to compute total sum (familiar from earlier!)
var total_sum = block.sum[block_size=tpb, broadcast=False](
val=SIMD[DType.float32, 1](my_value)
)
# Step 3: Thread 0 computes mean value
var mean_value: Scalar[dtype] = 1.0 # Default to avoid division by zero
if local_i == 0:
if total_sum[0] > 0.0:
mean_value = total_sum[0] / Scalar[dtype](size)
# Step 4: block.broadcast() shares mean to ALL threads!
# This completes the block operations trilogy demonstration
var broadcasted_mean = block.broadcast[
dtype=DType.float32, width=1, block_size=tpb
](val=SIMD[DType.float32, 1](mean_value), src_thread=UInt(0))
# Step 5: Each thread normalizes by the mean
if global_i < size:
var normalized_value = my_value / broadcasted_mean[0]
output_data[global_i] = normalized_value
The block.broadcast() kernel demonstrates the complete block operations
workflow by combining all three fundamental communication patterns in a real
algorithm that produces mathematically verifiable results:
Complete algorithm walkthrough with concrete execution:
Phase 1: Parallel data loading (established patterns from all previous puzzles)
Thread indexing (consistent across all puzzles):
global_i = block_dim.x * block_idx.x + thread_idx.x // Maps to input array position
local_i = thread_idx.x // Position within block (0-127)
Parallel element loading using TileTensor pattern:
Thread 0: my_value = input_data[0][0] = 1.0 // First cycle value
Thread 1: my_value = input_data[1][0] = 2.0 // Second cycle value
Thread 7: my_value = input_data[7][0] = 8.0 // Last cycle value
Thread 8: my_value = input_data[8][0] = 1.0 // Cycle repeats: 1,2,3,4,5,6,7,8,1,2...
Thread 15: my_value = input_data[15][0] = 8.0 // 15 % 8 = 7, so 8th value
Thread 127: my_value = input_data[127][0] = 8.0 // 127 % 8 = 7, so 8th value
All 128 threads load simultaneously - perfect parallel efficiency!
Phase 2: Block-wide sum reduction (leveraging earlier block.sum() knowledge)
block.sum() coordination across all 128 threads:
Contribution analysis:
- Values 1,2,3,4,5,6,7,8 repeat 16 times each (128/8 = 16)
- Thread contributions: 16×1 + 16×2 + 16×3 + 16×4 + 16×5 + 16×6 + 16×7 + 16×8
- Mathematical sum: 16 × (1+2+3+4+5+6+7+8) = 16 × 36 = 576.0
block.sum() hardware execution:
All threads → [reduction tree] → Thread 0
total_sum = SIMD[DType.float32, 1](576.0) // Only thread 0 receives this
Threads 1-127: Have no access to total_sum (broadcast=False in block.sum)
Phase 3: Exclusive mean computation (single-thread processing)
Thread 0 performs critical computation:
Input: total_sum[0] = 576.0, size = 128
Computation: mean_value = 576.0 / 128.0 = 4.5
Verification: Expected mean = (1+2+3+4+5+6+7+8)/8 = 36/8 = 4.5 ✓
All other threads (1-127):
mean_value = 1.0 (default safety value)
These values are irrelevant - will be overwritten by broadcast
Critical insight: Only thread 0 has the correct mean value at this point!
Phase 4: Block-wide broadcast distribution (one → all communication)
block.broadcast() API execution:
Source: src_thread = UInt(0) → Thread 0's mean_value = 4.5
Target: All 128 threads in block
Before broadcast:
Thread 0: mean_value = 4.5 ← Source of truth
Thread 1: mean_value = 1.0 ← Will be overwritten
Thread 2: mean_value = 1.0 ← Will be overwritten
...
Thread 127: mean_value = 1.0 ← Will be overwritten
After block.broadcast() execution:
Thread 0: broadcasted_mean[0] = 4.5 ← Receives own value back
Thread 1: broadcasted_mean[0] = 4.5 ← Now has correct value!
Thread 2: broadcasted_mean[0] = 4.5 ← Now has correct value!
...
Thread 127: broadcasted_mean[0] = 4.5 ← Now has correct value!
Result: Perfect synchronization - all threads have identical mean value!
Phase 5: Parallel mean normalization (coordinated processing)
Each thread independently normalizes using broadcast mean:
Thread 0: normalized = 1.0 / 4.5 = 0.22222222...
Thread 1: normalized = 2.0 / 4.5 = 0.44444444...
Thread 2: normalized = 3.0 / 4.5 = 0.66666666...
Thread 7: normalized = 8.0 / 4.5 = 1.77777777...
Thread 8: normalized = 1.0 / 4.5 = 0.22222222... (pattern repeats)
...
Mathematical verification:
Output sum = (0.222... + 0.444... + ... + 1.777...) × 16 = 4.5 × 16 × 2 = 128.0
Output mean = 128.0 / 128 = 1.0 Perfect normalization!
Each value divided by original mean gives output with mean = 1.0
Phase 6: Verification of correctness
Input analysis:
- Sum: 576.0, Mean: 4.5
- Max: 8.0, Min: 1.0
- Range: [1.0, 8.0]
Output analysis:
- Sum: 128.0, Mean: 1.0 ✓
- Max: 1.777..., Min: 0.222...
- Range: [0.222, 1.777] (all values scaled by factor 1/4.5)
Proportional relationships preserved:
- Original 8:1 ratio becomes 1.777:0.222 = 8:1 ✓
- All relative magnitudes maintained perfectly
Why this complete workflow is mathematically and computationally superior:
Technical accuracy and verification:
Mathematical proof of correctness:
Input: x₁, x₂, ..., xₙ where n = 128
Mean: μ = (∑xᵢ)/n = 576/128 = 4.5
Normalization: yᵢ = xᵢ/μ
Output mean: (∑yᵢ)/n = (∑xᵢ/μ)/n = (1/μ)(∑xᵢ)/n = (1/μ)μ = 1 ✓
Algorithm produces provably correct mathematical result.
Connection to Puzzle 12 (foundational patterns):
- Thread coordination evolution: Same
global_i,local_ipatterns but with block primitives - Memory access patterns: Same TileTensor SIMD extraction
[0]but optimized workflow - Complexity elimination: Replaces 20+ lines of manual barriers with 2 block operations
- Educational progression: Manual → automated, complex → simple, error-prone → reliable
Connection to block.sum() (perfect integration):
- API consistency: Identical template structure
[block_size=tpb, broadcast=False] - Result flow design: Thread 0 receives sum, naturally computes derived parameter
- Seamless composition: Output of
block.sum()becomes input for computation + broadcast - Performance optimization: Single-kernel workflow vs multi-pass approaches
Connection to block.prefix_sum() (complementary communication):
- Distribution patterns:
prefix_sumgives unique positions,broadcastgives shared values - Usage scenarios:
prefix_sumfor parallel partitioning,broadcastfor parameter sharing - Template consistency: Same
dtype,block_sizeparameter patterns across all operations - SIMD handling uniformity: All block operations return SIMD requiring
[0]extraction
Advanced algorithmic insights:
Communication pattern comparison:
Traditional approach:
1. Manual reduction: O(log n) with explicit barriers
2. Shared memory write: O(1) with synchronization
3. Shared memory read: O(1) with potential bank conflicts
Total: Multiple synchronization points, error-prone
Block operations approach:
1. block.sum(): O(log n) hardware-optimized, automatic barriers
2. Computation: O(1) single thread
3. block.broadcast(): O(log n) hardware-optimized, automatic distribution
Total: Two primitives, automatic synchronization, provably correct
Real-world algorithm patterns demonstrated:
Common parallel algorithm structure:
Phase 1: Parallel data processing → All threads contribute
Phase 2: Global parameter computation → One thread computes
Phase 3: Parameter distribution → All threads receive
Phase 4: Coordinated parallel output → All threads process
This exact pattern appears in:
- Batch normalization (deep learning)
- Histogram equalization (image processing)
- Iterative numerical methods (scientific computing)
- Lighting calculations (computer graphics)
Mean normalization is the perfect educational example of this fundamental pattern.
Block operations trilogy completed:
1. block.sum() - All to One (Reduction)
- Input: All threads provide values
- Output: Thread 0 receives aggregated result
- Use case: Computing totals, finding maximums, etc.
2. block.prefix_sum() - All to Each (Scan)
- Input: All threads provide values
- Output: Each thread receives cumulative position
- Use case: Computing write positions, parallel partitioning
3. block.broadcast() - One to All (Broadcast)
- Input: One thread provides value (typically thread 0)
- Output: All threads receive the same value
- Use case: Sharing computed parameters, configuration values
Complete block operations progression:
- Manual coordination (Puzzle 12): Understand parallel fundamentals
- Warp primitives (Puzzle 24): Learn hardware-accelerated patterns
- Block reduction (
block.sum()): Learn all→one communication - Block scan (
block.prefix_sum()): Learn all→each communication - Block broadcast (
block.broadcast()): Learn one→all communication
The complete picture: Block operations provide the fundamental communication building blocks for sophisticated parallel algorithms, replacing complex manual coordination with clean, composable primitives.
Performance insights and technical analysis
Quantitative performance comparison:
block.broadcast() vs Traditional shared memory approach (for
demonstration):
Traditional Manual Approach:
Phase 1: Manual reduction
• Shared memory allocation: ~5 cycles
• Barrier synchronization: ~10 cycles
• Tree reduction loop: ~15 cycles
• Error-prone manual indexing
Phase 2: Mean computation: ~2 cycles
Phase 3: Shared memory broadcast
• Manual write to shared: ~2 cycles
• Barrier synchronization: ~10 cycles
• All threads read: ~3 cycles
Total: ~47 cycles
+ synchronization overhead
+ potential race conditions
+ manual error debugging
Block Operations Approach:
Phase 1: block.sum()
• Hardware-optimized: ~3 cycles
• Automatic barriers: 0 explicit cost
• Optimized reduction: ~8 cycles
• Verified correct implementation
Phase 2: Mean computation: ~2 cycles
Phase 3: block.broadcast()
• Hardware-optimized: ~4 cycles
• Automatic distribution: 0 explicit cost
• Verified correct implementation
Total: ~17 cycles
+ automatic optimization
+ guaranteed correctness
+ composable design
Memory hierarchy advantages:
Cache efficiency:
- block.sum(): Optimized memory access patterns reduce cache misses
- block.broadcast(): Efficient distribution minimizes memory bandwidth usage
- Combined workflow: Single kernel reduces global memory round-trips by 100%
Memory bandwidth utilization:
Traditional multi-kernel approach:
Kernel 1: Input → Reduction → Global memory write
Kernel 2: Global memory read → Broadcast → Output
Total global memory transfers: 3× array size
Block operations single-kernel:
Input → block.sum() → block.broadcast() → Output
Total global memory transfers: 2× array size (33% improvement)
When to use each block operation:
block.sum() optimal scenarios:
- Data aggregation: Computing totals, averages, maximum/minimum values
- Reduction patterns: Any all-to-one communication requirement
- Statistical computation: Mean, variance, correlation calculations
block.prefix_sum() optimal scenarios:
- Parallel partitioning: Stream compaction, histogram binning
- Write position calculation: Parallel output generation
- Parallel algorithms: Sorting, searching, data reorganization
block.broadcast() optimal scenarios:
- Parameter distribution: Sharing computed values to all threads
- Configuration propagation: Mode flags, scaling factors, thresholds
- Coordinated processing: When all threads need the same computed parameter
Composition benefits:
Individual operations: Good performance, limited scope
Combined operations: Excellent performance, comprehensive algorithms
Example combinations seen in real applications:
• block.sum() + block.broadcast(): Normalization algorithms
• block.prefix_sum() + block.sum(): Advanced partitioning
• All three together: Complex parallel algorithms
• With traditional patterns: Hybrid optimization strategies
Next steps
Once you’ve learned about the complete block operations trilogy, you’re ready for:
- Multi-block algorithms: Coordinating operations across multiple thread blocks
- Advanced parallel patterns: Combining block operations for complex algorithms
- Memory hierarchy optimization: Efficient data movement patterns
- Algorithm design: Structuring parallel algorithms using block operation building blocks
- Performance optimization: Choosing optimal block sizes and operation combinations
💡 Key Takeaway: The block operations trilogy (sum, prefix_sum,
broadcast) provides complete communication primitives for block-level parallel
programming. By composing these operations, you can implement sophisticated
parallel algorithms with clean, maintainable code that leverages GPU hardware
optimizations. Mean normalization demonstrates how these operations work
together to solve real computational problems efficiently.
Puzzle 28: Async Memory Operations & Copy Overlap
The GPU Memory Bottleneck: Most real-world GPU algorithms hit a frustrating wall - they’re not limited by compute power, but by memory bandwidth. Your expensive GPU cores sit idle, waiting for data to arrive from slow DRAM.
Consider this common scenario in GPU programming:
# The performance killer - sequential memory operations
load_input_tile() # ← 500 cycles waiting for DRAM
load_kernel_data() # ← Another 100 cycles waiting
barrier() # ← All threads wait idle
compute() # ← Finally, 50 cycles of actual work
# Total: 650 cycles, only 7.7% compute utilization!
What if you could do this instead?
# The performance win - overlapped operations
launch_async_load() # ← Start 500-cycle transfer in background
load_small_data() # ← 100 cycles of useful work while waiting
wait_and_compute() # ← Only wait for remaining ~400 cycles, then compute
# Total: ~550 cycles, 45% better utilization!
This is the power of async memory operations - the difference between a sluggish algorithm and one that maximizes your GPU’s potential.
Why this matters
In this puzzle, you’ll transform a memory-bound 1D convolution from Puzzle 13 into a high-performance implementation that hides memory latency behind computation. This isn’t just an academic exercise - these patterns are fundamental to:
- Deep learning: Efficiently loading weights and activations
- Scientific computing: Overlapping data transfers in stencil operations
- Image processing: Streaming large datasets through memory hierarchies
- Any memory-bound algorithm: Converting waiting time into productive work
Prerequisites
Before diving in, ensure you have solid foundation in:
Essential GPU programming concepts:
- Shared memory programming (Puzzle 8, Puzzle 16) - You’ll extend matmul patterns
- Memory coalescing (Puzzle 21) - Critical for optimal async transfers
- Tiled processing (Puzzle 23) - The foundation for this optimization
Hardware understanding:
- GPU memory hierarchy (DRAM → Shared Memory → Registers)
- Thread block organization and synchronization
- Basic understanding of memory latency vs. bandwidth
API familiarity: Mojo GPU Memory Operations
⚠️ Hardware compatibility note: This puzzle uses async copy operations (
copy_dram_to_sram_async,async_copy_wait_all) that may require modern GPU architectures. If you encounter compilation errors related to.asyncmodifiers or unsupported operations, your GPU may not support these features. The concepts remain valuable for understanding memory optimization patterns.Check your GPU compute capability:
nvidia-smi --query-gpu=name,compute_cap --format=csv,noheader,nounits
- SM_70 and above (e.g., V100, T4, A10G, RTX 20+ series): Basic async copy supported
- SM_80 and above (e.g., A100, RTX 30+ series): Full async copy features
- SM_90 and above (e.g., H100, RTX 40+ series): Advanced TMA operations supported
What you’ll focus
By the end of this puzzle, you’ll have hands-on experience with:
Core techniques
- Async copy primitives: Launch background DRAM→SRAM transfers
- Latency hiding: Overlap expensive memory operations with useful computation
- Thread layout optimization: Match memory access patterns to hardware
- Pipeline programming: Structure algorithms for maximum memory utilization
Key APIs you’ll focus
Building on the async copy operations introduced in Puzzle 16’s idiomatic matmul, you’ll now focus specifically on their memory optimization potential:
copy_dram_to_sram_async(): Launch background DRAM→SRAM transfers using dedicated copy enginesasync_copy_wait_all(): Synchronize transfer completion before accessing shared memory
What’s different from Puzzle 16? While Puzzle 16 used async copy for clean tile loading in matmul, this puzzle focuses specifically on latency hiding - structuring algorithms to overlap expensive memory operations with useful computation work.
Performance impact
These techniques can provide significant speedups for memory-bound algorithms by:
- Hiding DRAM latency: Convert idle waiting into productive computation time
- Maximizing bandwidth: Optimal memory access patterns prevent cache misses
- Pipeline efficiency: Keep compute units busy while memory transfers happen in parallel
What are async copy operations? Asynchronous copy operations allow GPU blocks to initiate memory transfers that execute in the background while the block continues with other work. This enables overlapping computation with memory movement, a fundamental optimization technique for memory-bound algorithms.
💡 Success tip: Think of this as pipeline programming for GPU memory - overlap stages, hide latencies, and maximize throughput. The goal is to keep your expensive compute units busy while data moves in the background.
Understanding halo regions
Before diving into async copy operations, it’s essential to understand halo regions (also called ghost cells or guard cells), which are fundamental to tile-based processing with stencil operations like convolution.
What is a halo region?
A halo region consists of extra elements that extend beyond the boundaries of a processing tile to provide necessary neighboring data for stencil computations. When processing elements near tile edges, the stencil operation requires access to data from adjacent tiles.
Why halo regions are necessary
Consider a 1D convolution with a 5-point kernel on a tile:
Original data: [... | a b c d e f g h i j k l m n o | ...]
Processing tile: [c d e f g h i j k l m n o]
^ ^
Need neighbors Need neighbors
from left tile from right tile
With halo: [a b | c d e f g h i j k l m n o | p q]
^^^ ^^^
Left halo Right halo
Key characteristics:
- Halo size: Typically
KERNEL_SIZE // 2elements on each side - Purpose: Enable correct stencil computation at tile boundaries
- Content: Copies of data from neighboring tiles or boundary conditions
- Memory overhead: Small additional storage for significant computational benefit
Halo region in convolution
For a 5-point convolution kernel \([k_0, k_1, k_2, k_3, k_4]\):
- Center element: \(k_2\) aligns with the current processing element
- Left neighbors: \(k_0, k_1\) require 2 elements to the left
- Right neighbors: \(k_3, k_4\) require 2 elements to the right
- Halo size:
HALO_SIZE = 5 // 2 = 2elements on each side
Without halo regions:
- Tile boundary elements cannot perform full convolution
- Results in incorrect output or complex boundary handling logic
- Performance suffers from scattered memory access patterns
With halo regions:
- All tile elements can perform full convolution using local data
- Simplified, efficient computation with predictable memory access
- Better cache utilization and memory coalescing
This concept becomes particularly important when implementing async copy operations, as halo regions must be properly loaded and synchronized to ensure correct parallel computation across multiple tiles.
Async copy overlap with 1D convolution
Building on Puzzle 13: This puzzle revisits the 1D convolution from Puzzle 13, but now optimizes it using async copy operations to hide memory latency behind computation. Instead of simple synchronous memory access, we’ll use hardware acceleration to overlap expensive DRAM transfers with useful work.
Configuration
- Vector size:
VECTOR_SIZE = 16384(16K elements across multiple blocks) - Tile size:
CONV_TILE_SIZE = 256(processing tile size) - Block configuration:
(256, 1)threads per block - Grid configuration:
(VECTOR_SIZE // CONV_TILE_SIZE, 1)blocks per grid (64 blocks) - Kernel size:
KERNEL_SIZE = 5(simple 1D convolution, same as Puzzle 13) - Data type:
DType.float32 - Layout:
row_major[VECTOR_SIZE]()(1D row-major)
The async copy opportunity
Building on Puzzle 16: You’ve already seen copy_dram_to_sram_async used
for clean tile loading in matmul. Now we’ll focus on its
latency hiding capabilities - the key to high-performance memory-bound
algorithms.
Traditional synchronous memory loading forces compute units to wait idle during transfers. Async copy operations enable overlapping transfers with useful work:
# Synchronous approach - INEFFICIENT:
for i in range(CONV_TILE_SIZE):
input_shared[i] = input[base_idx + i] # Each load waits for DRAM
for i in range(KERNEL_SIZE):
kernel_shared[i] = kernel[i] # More waiting for DRAM
barrier() # All threads wait before computation begins
# ↑ Total time = input_transfer_time + kernel_transfer_time
# Async copy approach - EFFICIENT:
copy_dram_to_sram_async[thread_layout](input_shared, input_tile) # Launch background transfer
# While input transfers in background, load kernel synchronously
for i in range(KERNEL_SIZE):
kernel_shared[i] = kernel[i] # Overlaps with async input transfer
async_copy_wait_all() # Wait only when both operations complete
# ↑ Total time = MAX(input_transfer_time, kernel_transfer_time)
Why async copy works so well:
- Dedicated copy engines: Modern GPUs have specialized hardware that bypasses registers and enables true compute-memory overlap (as explained in Puzzle 16)
- Latency hiding: Memory transfers happen while GPU threads execute other operations
- Optimal coalescing: Thread layouts ensure efficient DRAM access patterns
- Resource utilization: Compute units stay busy instead of waiting idle
Code to complete
Implement 1D convolution that uses async copy operations to overlap memory transfers with computation, following patterns from Puzzle 16’s matmul implementation.
Mathematical operation: Compute 1D convolution across large vector using async copy for efficiency: \[\text{output}[i] = \sum_{k=0}^{\text{KERNEL_SIZE}-1} \text{input}[i+k-\text{HALO_SIZE}] \times \text{kernel}[k]\]
Async copy algorithm:
- Async tile loading: Launch background DRAM→SRAM transfer for input data
- Overlapped operations: Load small kernel data while input transfers
- Synchronization: Wait for transfers, then compute using shared memory
comptime VECTOR_SIZE = 16384
comptime CONV_TILE_SIZE = 256
comptime KERNEL_SIZE = 5
comptime HALO_SIZE = KERNEL_SIZE // 2 # Halo elements needed for boundary
comptime BUFFER_SIZE = CONV_TILE_SIZE + 2 * HALO_SIZE # Include halo for boundary conditions
comptime BLOCKS_PER_GRID_ASYNC = (
VECTOR_SIZE + CONV_TILE_SIZE - 1
) // CONV_TILE_SIZE
comptime THREADS_PER_BLOCK_ASYNC = 256
comptime dtype = DType.float32
comptime layout_async = row_major[VECTOR_SIZE]()
comptime LayoutAsyncType = type_of(layout_async)
comptime kernel_layout = row_major[KERNEL_SIZE]()
comptime KernelLayoutType = type_of(kernel_layout)
def async_copy_overlap_convolution[
dtype: DType
](
output: TileTensor[mut=True, dtype, LayoutAsyncType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutAsyncType, ImmutAnyOrigin],
kernel: TileTensor[mut=False, dtype, KernelLayoutType, ImmutAnyOrigin],
):
"""Demonstrates async copy operations building on p14 patterns.
This shows how to use copy_dram_to_sram_async and async_copy_wait_all
for efficient memory transfers, extending the patterns from p14 matmul.
"""
# Shared memory buffers (like p14, but without .fill(0) to avoid race)
var input_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[CONV_TILE_SIZE]())
var kernel_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[KERNEL_SIZE]())
# FILL IN HERE (roughly 19 lines)
View full file: problems/p28/p28.mojo
Tips
1. Understanding async copy mechanics
Async copy operations initiate background transfers while your block continues executing other code.
Key questions to explore:
- What data needs to be transferred from DRAM to shared memory?
- Which operations can execute while the transfer happens in the background?
- How does the hardware coordinate multiple concurrent operations?
Thread layout considerations:
- Your block has
THREADS_PER_BLOCK_ASYNC = 256threads - The tile has
CONV_TILE_SIZE = 256elements - What layout pattern ensures optimal memory coalescing?
2. Identifying overlap opportunities
The goal is to hide memory latency behind useful computation.
Analysis approach:
- What operations must happen sequentially vs. in parallel?
- Which data transfers are large (expensive) vs. small (cheap)?
- How can you structure the algorithm to maximize parallel execution?
Memory hierarchy considerations:
- Large input tile: 256 elements × 4 bytes = 1KB transfer
- Small kernel: 5 elements × 4 bytes = 20 bytes
- Which transfer benefits most from async optimization?
3. Synchronization strategy
Proper synchronization ensures correctness without sacrificing performance.
Timing analysis:
- When does each operation actually need its data to be ready?
- What’s the minimum synchronization required for correctness?
- How do you avoid unnecessary stalls while maintaining data dependencies?
Race condition prevention:
- What happens if computation starts before transfers complete?
- How do memory fences and barriers coordinate different memory operations?
Test the async copy overlap:
pixi run p28
pixi run -e amd p28
pixi run -e apple p28
uv run poe p28
Solution
Complete Solution with Detailed Explanation
The async copy overlap solution demonstrates how to hide memory latency by overlapping expensive DRAM transfers with useful computation:
def async_copy_overlap_convolution[
dtype: DType
](
output: TileTensor[mut=True, dtype, AsyncLayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, AsyncLayoutType, MutAnyOrigin],
kernel: LayoutTensor[dtype, kernel_layout, ImmutAnyOrigin],
):
"""Demonstrates async copy operations building on p14 patterns.
This shows how to use copy_dram_to_sram_async and async_copy_wait_all
for efficient memory transfers, extending the patterns from p14 matmul.
"""
# Shared memory buffers (like p14, but without .fill(0) to avoid race)
var input_shared = LayoutTensor[
dtype,
Layout.row_major(CONV_TILE_SIZE),
MutAnyOrigin,
address_space=AddressSpace.SHARED,
].stack_allocation()
var kernel_shared = LayoutTensor[
dtype,
Layout.row_major(KERNEL_SIZE),
MutAnyOrigin,
address_space=AddressSpace.SHARED,
].stack_allocation()
var local_i = thread_idx.x
# Phase 1: Launch async copy for input tile
# Note: tile() does NOT perform bounds checking - ensure valid tile bounds
var input_tile = input.tile[CONV_TILE_SIZE](block_idx.x).to_layout_tensor()
# Use async copy with thread layout matching p14 pattern
comptime load_layout = Layout.row_major(THREADS_PER_BLOCK_ASYNC)
copy_dram_to_sram_async[thread_layout=load_layout](input_shared, input_tile)
# Phase 2: Load kernel synchronously (small data)
if local_i < KERNEL_SIZE:
kernel_shared[local_i] = kernel[local_i]
# Phase 3: Wait for async copy to complete
async_copy_wait_all() # Always wait since we always do async copy
barrier() # Sync all threads
# Phase 4: Compute convolution
var global_i = block_idx.x * CONV_TILE_SIZE + local_i
if local_i < CONV_TILE_SIZE and global_i < Int(output.dim[0]()):
var result: output.ElementType = 0
# Simple convolution avoiding boundary issues
if local_i >= HALO_SIZE and local_i < CONV_TILE_SIZE - HALO_SIZE:
# Full convolution for center elements
for k in range(KERNEL_SIZE):
var input_idx = local_i + k - HALO_SIZE
if input_idx >= 0 and input_idx < CONV_TILE_SIZE:
result += rebind[Scalar[dtype]](
input_shared[input_idx]
) * rebind[Scalar[dtype]](kernel_shared[k])
else:
# For boundary elements, just copy input (no convolution)
result = rebind[Scalar[dtype]](input_shared[local_i])
output[global_i] = result
Phase-by-phase breakdown
Phase 1: Async Copy Launch
# Phase 1: Launch async copy for input tile
input_tile = input.tile[CONV_TILE_SIZE](block_idx.x)
comptime load_layout = row_major[THREADS_PER_BLOCK_ASYNC]()
copy_dram_to_sram_async[thread_layout=load_layout](input_shared, input_tile)
-
Tile Creation:
input.tile[CONV_TILE_SIZE](block_idx.x)creates a 256-element view of the input array starting atblock_idx.x * 256. The Mojotilemethod does NOT perform bounds checking or zero-padding. Accessing out-of-bounds indices results in undefined behavior. The implementation must ensure the tile size and offset remain within valid array bounds. -
Thread Layout:
row_major[THREADS_PER_BLOCK_ASYNC, 1]()creates a256 x 1layout that matches our block organization. This is critical - the layout must match the physical thread arrangement for optimal coalesced memory access. When layouts mismatch, threads may access non-contiguous memory addresses, breaking coalescing and severely degrading performance. -
Async Copy Launch:
copy_dram_to_sram_asyncinitiates a background transfer from DRAM to shared memory. The hardware copies 256 floats (1KB) while the block continues executing.
Phase 2: Overlapped Operation
# Phase 2: Load kernel synchronously (small data)
if local_i < KERNEL_SIZE:
kernel_shared[local_i] = kernel[local_i]
-
Simultaneous Execution: While the 1KB input tile transfers in the background, threads load the small 20-byte kernel synchronously. This overlap is the key optimization.
-
Size-Based Strategy: Large transfers (input tile) use async copy; small transfers (kernel) use synchronous loading. This balances complexity with performance benefit.
Phase 3: Synchronization
# Phase 3: Wait for async copy to complete
async_copy_wait_all() # Always wait since we always do async copy
barrier() # Sync all threads
-
Transfer Completion:
async_copy_wait_all()blocks until all async transfers complete. This is essential before accessinginput_shared. -
Thread Synchronization:
barrier()ensures all threads see the completed transfer before proceeding to computation.
Phase 4: Computation
# Phase 4: Compute convolution
global_i = block_idx.x * CONV_TILE_SIZE + local_i
if local_i < CONV_TILE_SIZE and global_i < output.shape[0]():
var result: output.element_type = 0
if local_i >= HALO_SIZE and local_i < CONV_TILE_SIZE - HALO_SIZE:
# Full convolution for center elements
for k in range(KERNEL_SIZE):
input_idx = local_i + k - HALO_SIZE
if input_idx >= 0 and input_idx < CONV_TILE_SIZE:
result += input_shared[input_idx] * kernel_shared[k]
else:
# For boundary elements, just copy input (no convolution)
result = input_shared[local_i]
output[global_i] = result
-
Fast Shared Memory Access: All computation uses pre-loaded shared memory data, avoiding slow DRAM access during the compute-intensive convolution loop.
-
Simplified Boundary Handling: The implementation uses a pragmatic approach to handle elements near tile boundaries:
- Center elements (
local_i >= HALO_SIZEandlocal_i < CONV_TILE_SIZE - HALO_SIZE): Apply full 5-point convolution using shared memory data - Boundary elements (first 2 and last 2 elements in each tile): Copy input directly without convolution to avoid complex boundary logic
- Center elements (
Educational rationale: This approach prioritizes demonstrating async copy
patterns over complex boundary handling. For a 256-element tile with
HALO_SIZE = 2, elements 0-1 and 254-255 use input copying, while elements
2-253 use full convolution. This keeps the focus on memory optimization while
providing a working implementation.
Performance analysis
Without Async Copy (Synchronous):
Total Time = Input_Transfer_Time + Kernel_Transfer_Time + Compute_Time
= Large_DRAM_transfer + Small_DRAM_transfer + convolution
= Major_latency + Minor_latency + computation_work
With Async Copy (Overlapped):
Total Time = MAX(Input_Transfer_Time, Kernel_Transfer_Time) + Compute_Time
= MAX(Major_latency, Minor_latency) + computation_work
= Major_latency + computation_work
Speedup: Performance improvement from hiding the smaller kernel transfer latency behind the larger input transfer. The actual speedup depends on the relative sizes of transfers and available memory bandwidth. In memory-bound scenarios with larger overlaps, speedups can be much more significant.
Key technical insights
-
Thread Layout Matching: The
row_major[256, 1]()layout precisely matches the block’s(256, 1)thread organization, enabling optimal memory coalescing. -
Race Condition Avoidance: Proper sequencing (async copy → kernel load → wait → barrier → compute) eliminates all race conditions that could corrupt shared memory.
-
Hardware Optimization: Modern GPUs have dedicated hardware for async copy operations, allowing true parallelism between memory and compute units.
-
Memory Hierarchy Exploitation: The pattern moves data through the hierarchy efficiently: DRAM → Shared Memory → Registers → Computation.
-
Test-Implementation Consistency: The test verification logic matches the boundary handling strategy by checking
local_i_in_tile = i % CONV_TILE_SIZEto determine whether each element should expect convolution results (center elements) or input copying (boundary elements). This ensures accurate validation of the simplified boundary approach.
This solution transforms a naive memory-bound convolution into an optimized implementation that hides memory latency behind useful work, demonstrating fundamental principles of high-performance GPU programming.
Puzzle 29: GPU Synchronization Primitives
Beyond Simple Parallelism
This chapter introduces synchronization patterns that enable complex GPU algorithms requiring precise coordination between threads. Unlike previous puzzles that focused on simple parallel operations, these challenges explore architectural approaches used in production GPU software.
What you’ll learn:
- Thread specialization: Different thread groups executing distinct algorithms within a single block
- Producer-consumer pipelines: Multi-stage processing with explicit data dependencies
- Advanced barrier APIs: Fine-grained synchronization control beyond basic
barrier()calls- Memory barrier coordination: Explicit control over memory visibility and ordering
- Iterative algorithm patterns: Double-buffering and pipeline coordination for complex computations
Why this matters: Most GPU tutorials teach simple data-parallel patterns, but real-world applications require sophisticated coordination between different processing phases, memory access patterns, and algorithmic stages. These puzzles bridge the gap between academic examples and production GPU computing.
Overview
GPU synchronization is the foundation that enables complex parallel algorithms to work correctly and efficiently. This chapter explores three fundamental synchronization patterns that appear throughout high-performance GPU computing: pipeline coordination, memory barrier management, and streaming computation.
Core learning objectives:
- Understand when and why different synchronization primitives are needed
- Design multi-stage algorithms with proper thread specialization
- Implement iterative patterns that require precise memory coordination
- Optimize synchronization overhead while maintaining correctness guarantees
Architectural progression: These puzzles follow a carefully designed progression from basic pipeline coordination to advanced memory barrier management, culminating in streaming computation patterns used in high-throughput applications.
Key concepts
Thread coordination paradigms:
- Simple parallelism: All threads execute identical operations (previous puzzles)
- Specialized parallelism: Different thread groups execute distinct algorithms (this chapter)
- Pipeline parallelism: Sequential stages with producer-consumer relationships
- Iterative parallelism: Multiple passes with careful buffer management
Synchronization primitive hierarchy:
- Basic
barrier(): Simple thread synchronization within blocks - Advanced mbarrier APIs: Fine-grained memory barrier control with state tracking
- Streaming coordination: Asynchronous copy and bulk transfer synchronization
Memory consistency models:
- Shared memory coordination: Fast on-chip memory for inter-thread communication
- Global memory ordering: Ensuring visibility of writes across different memory spaces
- Buffer management: Double-buffering and ping-pong patterns for iterative algorithms
Configuration
System architecture:
- Block size:
TPB = 256threads per block for optimal occupancy - Grid configuration: Multiple blocks processing different data tiles
- Memory hierarchy: Strategic use of shared memory, registers, and global memory
- Data types:
DType.float32for numerical computations
Synchronization patterns covered:
- Multi-stage pipelines: Thread specialization with barrier coordination
- Double-buffered iterations: Memory barrier management for iterative algorithms
- Streaming computation: Asynchronous copy coordination for high-throughput processing
Performance considerations:
- Synchronization overhead: Understanding the cost of different barrier types
- Memory bandwidth: Optimizing access patterns for maximum throughput
- Thread utilization: Balancing specialized roles with overall efficiency
Puzzle structure
This chapter contains three interconnected puzzles that build upon each other:
Multi-Stage Pipeline Coordination
Focus: Thread specialization and pipeline architecture
Learn how to design GPU kernels where different thread groups execute completely different algorithms within the same block. This puzzle introduces producer-consumer relationships and strategic barrier placement for coordinating between different algorithmic stages.
Key concepts:
- Thread role specialization (Stage 1: load, Stage 2: process, Stage 3: output)
- Producer-consumer data flow between processing stages
- Strategic barrier placement between different algorithms
Real-world applications: Image processing pipelines, multi-stage scientific computations, neural network layer coordination
Double-Buffered Stencil Computation
Focus: Advanced memory barrier APIs and iterative processing
Explore fine-grained synchronization control using mbarrier APIs for iterative algorithms that require precise memory coordination. This puzzle demonstrates double-buffering patterns essential for iterative solvers and simulation algorithms.
Key concepts:
- Advanced mbarrier APIs vs
basic
barrier() - Double-buffering with alternating read/write buffer roles
- Iterative algorithm coordination with explicit memory barriers
Real-world applications: Iterative solvers (Jacobi, Gauss-Seidel), cellular automata, simulation time-stepping
Getting started
Recommended approach:
- Start with Pipeline Coordination: Understand thread specialization basics
- Progress to Memory Barriers: Learn fine-grained synchronization control
- Apply to streaming patterns: Combine concepts for high-throughput applications
Prerequisites:
- Comfort with basic GPU programming concepts (threads, blocks, shared memory)
- Understanding of memory hierarchies and access patterns
- Familiarity with barrier synchronization from previous puzzles
Learning outcomes: By completing this chapter, you’ll have the foundation to design and implement sophisticated GPU algorithms that require precise coordination, preparing you for the architectural complexity found in production GPU computing applications.
Ready to dive in? Start with Multi-Stage Pipeline Coordination to learn thread specialization fundamentals, then advance to Double-Buffered Stencil Computation to explore advanced memory barrier techniques.
Multi-Stage Pipeline Coordination
Overview
Implement a kernel that processes an image through a coordinated 3-stage pipeline where different thread groups handle specialized processing stages, synchronized with explicit barriers.
Note: You have specialized thread roles: Stage 1 (threads 0-127) loads and preprocesses data, Stage 2 (threads 128-255) applies blur operations, and Stage 3 (all threads) performs final smoothing.
Algorithm architecture: This puzzle implements a producer-consumer pipeline where different thread groups execute completely different algorithms within a single GPU block. Unlike traditional GPU programming where all threads execute the same algorithm on different data, this approach divides threads by functional specialization.
Pipeline concept: The algorithm processes data through three distinct stages, where each stage has specialized thread groups that execute different algorithms. Each stage produces data that the next stage consumes, creating explicit producer-consumer relationships that must be carefully synchronized with barriers.
Data dependencies and synchronization: Each stage produces data that the next stage consumes:
- Stage 1 → Stage 2: First stage produces preprocessed data for blur processing
- Stage 2 → Stage 3: Second stage produces blur results for final smoothing
- Barriers prevent race conditions by ensuring complete stage completion before dependent stages begin
Concretely, the multi-stage pipeline implements a coordinated image processing algorithm with three mathematical operations:
Stage 1 - Preprocessing Enhancement:
\[P[i] = I[i] \times 1.1\]
where \(P[i]\) is the preprocessed data and \(I[i]\) is the input data.
Stage 2 - Horizontal Blur Filter:
\[B[i] = \frac{1}{N_i} \sum_{k=-2}^{2} P[i+k] \quad \text{where} i+k \in [0, 255]\]
where \(B[i]\) is the blur result, and \(N_i\) is the count of valid neighbors within the tile boundary.
Stage 3 - Cascading Neighbor Smoothing:
\[F[i] = \begin{cases} (B[i] + B[i+1]) \times 0.6 & \text{if } i = 0 \\ ((B[i] + B[i-1]) \times 0.6 + B[i+1]) \times 0.6 & \text{if } 0 < i < 255 \\ (B[i] + B[i-1]) \times 0.6 & \text{if } i = 255 \end{cases}\]
where \(F[i]\) is the final output with cascading smoothing applied.
Thread Specialization:
- Threads 0-127: Compute \(P[i]\) for \(i \in \{0, 1, 2, \ldots, 255\}\) (2 elements per thread)
- Threads 128-255: Compute \(B[i]\) for \(i \in \{0, 1, 2, \ldots, 255\}\) (2 elements per thread)
- All 256 threads: Compute \(F[i]\) for \(i \in \{0, 1, 2, \ldots, 255\}\) (1 element per thread)
Synchronization Points:
\[\text{barrier}_1 \Rightarrow P[i] \text{ complete} \Rightarrow \text{barrier}_2 \Rightarrow B[i] \text{ complete} \Rightarrow \text{barrier}_3 \Rightarrow F[i] \text{ complete}\]
Key concepts
In this puzzle, you’ll learn about:
- Implementing thread role specialization within a single GPU block
- Coordinating producer-consumer relationships between processing stages
- Using barriers to synchronize between different algorithms (not just within the same algorithm)
The key insight is understanding how to design multi-stage pipelines where different thread groups execute completely different algorithms, coordinated through strategic barrier placement.
Why this matters: Most GPU tutorials teach barrier usage within a single algorithm - synchronizing threads during reductions or shared memory operations. But real-world GPU algorithms often require architectural complexity with multiple distinct processing stages that must be carefully orchestrated. This puzzle demonstrates how to transform monolithic algorithms into specialized, coordinated processing pipelines.
Previous vs. current barrier usage:
- Previous puzzles (P8, P12, P15): All threads execute the same algorithm, barriers sync within algorithm steps
- This puzzle: Different thread groups execute different algorithms, barriers coordinate between different algorithms
Thread specialization architecture: Unlike data parallelism where threads differ only in their data indices, this puzzle implements algorithmic parallelism where threads execute fundamentally different code paths based on their role in the pipeline.
Configuration
System parameters:
- Image size:
SIZE = 1024elements (1D for simplicity) - Threads per block:
TPB = 256threads organized as(256, 1)block dimension - Grid configuration:
(4, 1)blocks to process entire image in tiles (4 blocks total) - Data type:
DType.float32for all computations
Thread specialization architecture:
-
Stage 1 threads:
STAGE1_THREADS = 128(threads 0-127, first half of block)- Responsibility: Load input data from global memory and apply preprocessing
- Work distribution: Each thread processes 2 elements for efficient load balancing
- Output: Populates
input_shared[256]with preprocessed data
-
Stage 2 threads:
STAGE2_THREADS = 128(threads 128-255, second half of block)- Responsibility: Apply horizontal blur filter on preprocessed data
- Work distribution: Each thread processes 2 blur operations
- Output: Populates
blur_shared[256]with blur results
-
Stage 3 threads: All 256 threads collaborate
- Responsibility: Final smoothing and output to global memory
- Work distribution: One-to-one mapping (thread
iprocesses elementi) - Output: Writes final results to global
outputarray
Code to complete
comptime TPB = 256 # Threads per block for pipeline stages
comptime SIZE = 1024 # Image size (1D for simplicity)
comptime BLOCKS_PER_GRID = (4, 1)
comptime THREADS_PER_BLOCK = (TPB, 1)
comptime dtype = DType.float32
comptime layout = row_major[SIZE]()
comptime LayoutType = type_of(layout)
# Multi-stage processing configuration
comptime STAGE1_THREADS = TPB // 2
comptime STAGE2_THREADS = TPB // 2
comptime BLUR_RADIUS = 2
def multi_stage_image_blur_pipeline(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
"""Multi-stage image blur pipeline with barrier coordination.
Stage 1 (threads 0-127): Load input data and apply 1.1x preprocessing
Stage 2 (threads 128-255): Apply 5-point blur with BLUR_RADIUS=2
Stage 3 (all threads): Final neighbor smoothing and output
"""
# Shared memory buffers for pipeline stages
var input_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var blur_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Stage 1: Load and preprocess (threads 0-127)
# FILL ME IN (roughly 10 lines)
barrier() # Wait for Stage 1 completion
# Stage 2: Apply blur (threads 128-255)
# FILL ME IN (roughly 25 lines)
barrier() # Wait for Stage 2 completion
# Stage 3: Final smoothing (all threads)
# FILL ME IN (roughly 7 lines)
barrier() # Ensure all writes complete
View full file: problems/p29/p29.mojo
Tips
Thread role identification
- Use thread index comparisons to determine which stage each thread should execute
- Stage 1: First half of threads (threads 0-127)
- Stage 2: Second half of threads (threads 128-255)
- Stage 3: All threads participate
Stage 1 approach
- Identify Stage 1 threads using appropriate index comparison
- Each thread should handle multiple elements for load balancing
- Apply the preprocessing enhancement factor
- Implement proper boundary handling with zero-padding
Stage 2 approach
- Identify Stage 2 threads and map their indices to processing range
- Implement the blur kernel by averaging neighboring elements
- Handle boundary conditions by only including valid neighbors
- Process multiple elements per thread for efficiency
Stage 3 approach
- All threads participate in final processing
- Apply neighbor smoothing using the specified scaling factor
- Handle edge cases where neighbors may not exist
- Write results to global output with bounds checking
Synchronization strategy
- Place barriers between stages to prevent race conditions
- Ensure each stage completes before dependent stages begin
- Use final barrier to guarantee completion before block exit
Running the code
To test your solution, run the following command in your terminal:
pixi run p29 --multi-stage
pixi run -e amd p29 --multi-stage
uv run poe p29 --multi-stage
After completing the puzzle successfully, you should see output similar to:
Puzzle 29: GPU Synchronization Primitives
==================================================
TPB: 256
SIZE: 1024
STAGE1_THREADS: 128
STAGE2_THREADS: 128
BLUR_RADIUS: 2
Testing Puzzle 29A: Multi-Stage Pipeline Coordination
============================================================
Multi-stage pipeline blur completed
Input sample: 0.0 1.01 2.02
Output sample: 1.6665002 2.3331003 3.3996604
✅ Multi-stage pipeline coordination test PASSED!
Solution
def multi_stage_image_blur_pipeline(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, MutAnyOrigin],
size: Int,
):
"""Multi-stage image blur pipeline with barrier coordination.
Stage 1 (threads 0-127): Load input data and apply 1.1x preprocessing
Stage 2 (threads 128-255): Apply 5-point blur with BLUR_RADIUS=2
Stage 3 (all threads): Final neighbor smoothing and output
"""
# Shared memory buffers for pipeline stages
var input_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var blur_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Stage 1: Load and preprocess (threads 0-127)
if local_i < STAGE1_THREADS:
if global_i < size:
input_shared[local_i] = input[global_i] * 1.1
# Each thread loads 2 elements
if local_i + STAGE1_THREADS < size:
input_shared[local_i + STAGE1_THREADS] = (
input[global_i + STAGE1_THREADS] * 1.1
)
else:
# Zero-padding for out-of-bounds
input_shared[local_i] = 0.0
if local_i + STAGE1_THREADS < TPB:
input_shared[local_i + STAGE1_THREADS] = 0.0
barrier() # Wait for Stage 1 completion
# Stage 2: Apply blur (threads 128-255)
if local_i >= STAGE1_THREADS:
var blur_idx = local_i - STAGE1_THREADS
var blur_sum: Scalar[dtype] = 0.0
blur_count = 0
# 5-point blur kernel
for offset in range(-BLUR_RADIUS, BLUR_RADIUS + 1):
sample_idx = blur_idx + offset
if sample_idx >= 0 and sample_idx < TPB:
blur_sum += rebind[Scalar[dtype]](input_shared[sample_idx])
blur_count += 1
if blur_count > 0:
blur_shared[blur_idx] = blur_sum / Scalar[dtype](blur_count)
else:
blur_shared[blur_idx] = 0.0
# Process second element
var second_idx = blur_idx + STAGE1_THREADS
if second_idx < TPB:
blur_sum = 0.0
blur_count = 0
for offset in range(-BLUR_RADIUS, BLUR_RADIUS + 1):
sample_idx = second_idx + offset
if sample_idx >= 0 and sample_idx < TPB:
blur_sum += rebind[Scalar[dtype]](input_shared[sample_idx])
blur_count += 1
if blur_count > 0:
blur_shared[second_idx] = blur_sum / Scalar[dtype](blur_count)
else:
blur_shared[second_idx] = 0.0
barrier() # Wait for Stage 2 completion
# Stage 3: Final smoothing (all threads)
if global_i < size:
final_value = blur_shared[local_i]
# Neighbor smoothing with 0.6 scaling
if local_i > 0:
final_value = (final_value + blur_shared[local_i - 1]) * 0.6
if local_i < TPB - 1:
final_value = (final_value + blur_shared[local_i + 1]) * 0.6
output[global_i] = final_value
barrier() # Ensure all writes complete
The key insight is recognizing this as a pipeline architecture problem with thread role specialization:
- Design stage-specific thread groups: Divide threads by function, not just by data
- Implement producer-consumer chains: Stage 1 produces for Stage 2, Stage 2 produces for Stage 3
- Use strategic barrier placement: Synchronize between different algorithms, not within the same algorithm
- Optimize memory access patterns: Ensure coalesced reads and efficient shared memory usage
Complete Solution with Detailed Explanation
The multi-stage pipeline solution demonstrates sophisticated thread specialization and barrier coordination. This approach transforms a traditional monolithic GPU algorithm into a specialized, coordinated processing pipeline.
Pipeline architecture design
The fundamental breakthrough in this puzzle is thread specialization by role rather than by data:
Traditional approach: All threads execute the same algorithm on different data
- Everyone performs identical operations (like reductions or matrix operations)
- Barriers synchronize threads within the same algorithm steps
- Thread roles differ only by data indices they process
This puzzle’s innovation: Different thread groups execute completely different algorithms
- Threads 0-127 execute loading and preprocessing algorithms
- Threads 128-255 execute blur processing algorithms
- All threads collaborate in final smoothing algorithm
- Barriers coordinate between different algorithms, not within the same algorithm
Producer-consumer coordination
Unlike previous puzzles where threads were peers in the same algorithm, this establishes explicit producer-consumer relationships:
- Stage 1: Producer (creates preprocessed data for Stage 2)
- Stage 2: Consumer (uses Stage 1 data) + Producer (creates blur data for Stage 3)
- Stage 3: Consumer (uses Stage 2 data)
Strategic barrier placement
Understanding when barriers are necessary vs. wasteful:
- Necessary: Between dependent stages to prevent race conditions
- Wasteful: Within independent operations of the same stage
- Performance insight: Each barrier has a cost - use them strategically
Critical synchronization points:
- After Stage 1: Prevent Stage 2 from reading incomplete preprocessed data
- After Stage 2: Prevent Stage 3 from reading incomplete blur results
- After Stage 3: Ensure all output writes complete before block termination
Thread utilization patterns
- Stage 1: 50% utilization (128/256 threads active, 128 idle)
- Stage 2: 50% utilization (128 active, 128 idle)
- Stage 3: 100% utilization (all 256 threads active)
This demonstrates sophisticated algorithmic parallelism where different thread groups specialize in different computational tasks within a coordinated pipeline, moving beyond simple data parallelism to architectural thinking required for real-world GPU algorithms.
Memory hierarchy optimization
Shared memory architecture:
- Two specialized buffers handle data flow between stages
- Global memory access minimized to boundary operations only
- All intermediate processing uses fast shared memory
Access pattern benefits:
- Stage 1: Coalesced global memory reads for input loading
- Stage 2: Fast shared memory reads for blur processing
- Stage 3: Coalesced global memory writes for output
Real-world applications
This pipeline architecture pattern is fundamental to:
Image processing pipelines:
- Multi-stage filters (blur, sharpen, edge detection in sequence)
- Color space conversions (RGB → HSV → processing → RGB)
- Noise reduction with multiple algorithm passes
Scientific computing:
- Stencil computations with multi-stage finite difference methods
- Signal processing with filtering, transformation, and analysis pipelines
- Computational fluid dynamics with multi-stage solver iterations
Machine learning:
- Neural network layers with specialized thread groups for different operations
- Data preprocessing pipelines (load, normalize, augment in coordinated stages)
- Batch processing where different thread groups handle different operations
Key technical insights
Algorithmic vs. data parallelism:
- Data parallelism: Threads execute identical code on different data elements
- Algorithmic parallelism: Threads execute fundamentally different algorithms based on their specialized roles
Barrier usage philosophy:
- Strategic placement: Barriers only where necessary to prevent race conditions between dependent stages
- Performance consideration: Each barrier incurs synchronization overhead - use sparingly but correctly
- Correctness guarantee: Proper barrier placement ensures deterministic results regardless of thread execution timing
Thread specialization benefits:
- Algorithmic optimization: Each stage can be optimized for its specific computational pattern
- Memory access optimization: Different stages can use different memory access strategies
- Resource utilization: Complex algorithms can be decomposed into specialized, efficient components
This solution demonstrates how to design sophisticated GPU algorithms that leverage thread specialization and strategic synchronization for complex multi-stage computations, moving beyond simple parallel loops to architectural approaches used in production GPU software.
Double-Buffered Stencil Computation
🔬 Fine-Grained Synchronization: mbarrier vs barrier()
This puzzle introduces explicit memory barrier APIs that provide significantly more control than the basic
barrier()function used in previous puzzles.Basic
barrier()limitations:
- Fire-and-forget: Single synchronization point with no state tracking
- Block-wide only: All threads in the block must participate simultaneously
- No reusability: Each barrier() call creates a new synchronization event
- Coarse-grained: Limited control over memory ordering and timing
- Static coordination: Cannot adapt to different thread participation patterns
Advanced
mbarrier APIscapabilities:
- Precise control:
mbarrier_init()sets up reusable barrier objects with specific thread counts- State tracking:
mbarrier_arrive()signals individual thread completion and maintains arrival count- Flexible waiting:
mbarrier_test_wait()allows threads to wait for specific completion states- Reusable objects: Same barrier can be reinitialized and reused across multiple iterations
- Multiple barriers: Different barrier objects for different synchronization points (initialization, iteration, finalization)
- Hardware optimization: Maps directly to GPU hardware synchronization primitives for better performance
- Memory semantics: Explicit control over memory visibility and ordering guarantees
Why this matters for iterative algorithms: In double-buffering patterns, you need precise coordination between buffer swap phases. Basic
barrier()cannot provide the fine-grained control required for:
- Buffer role alternation: Ensuring all writes to buffer_A complete before reading from buffer_A begins
- Iteration boundaries: Coordinating multiple synchronization points within a single kernel
- State management: Tracking which threads have completed which phase of processing
- Performance optimization: Minimizing synchronization overhead through reusable barrier objects
This puzzle demonstrates synchronization patterns used in real-world GPU computing applications like iterative solvers, simulation frameworks, and high-performance image processing pipelines.
Overview
Implement a kernel that performs iterative stencil operations using double-buffered shared memory, coordinated with explicit memory barriers to ensure safe buffer swapping between iterations. A stencil operation is a computational pattern where the value of each element in an array is calculated based on a fixed pattern of its neighbors.
Note: You have alternating buffer roles: buffer_A and buffer_B swap
between read and write operations each iteration, with mbarrier synchronization
ensuring all threads complete writes before buffer swaps.
Algorithm architecture: This puzzle implements a double-buffering pattern where two shared memory buffers alternate roles as read and write targets across multiple iterations. Unlike simple stencil operations that process data once, this approach performs iterative refinement with careful memory barrier coordination to prevent race conditions during buffer transitions.
Pipeline concept: The algorithm processes data through iterative stencil refinement, where each iteration reads from one buffer and writes to another. The buffers alternate roles each iteration, creating a ping-pong pattern that enables continuous processing without data corruption.
Data dependencies and synchronization: Each iteration depends on the complete results of the previous iteration:
- Iteration N → Iteration N+1: Current iteration produces refined data that next iteration consumes
- Buffer coordination: Read and write buffers swap roles each iteration
- Memory barriers prevent race conditions by ensuring all writes complete before any thread begins reading from the newly written buffer
Concretely, the double-buffered stencil implements an iterative smoothing algorithm with three mathematical operations:
Iteration Pattern - Buffer Alternation:
\[\text{Iteration} i: \begin{cases} \text{Read from buffer_A, Write to buffer_B} & \text{if} i \bmod 2 = 0 \\ \text{Read from buffer_B, Write to buffer_A} & \text{if } i \bmod 2 = 1 \end{cases}\]
Stencil Operation - 3-Point Average:
\[S^{(i+1)}[j] = \frac{1}{N_j} \sum_{k=-1}^{1} S^{(i)}[j+k] \quad \text{where} j+k \in [0, 255]\]
where \(S^{(i)}[j]\) is the stencil value at position \(j\) after iteration \(i\), and \(N_j\) is the count of valid neighbors.
Memory Barrier Coordination:
\[\text{mbarrier_arrive}() \Rightarrow \text{mbarrier_test_wait}() \Rightarrow \text{buffer swap} \Rightarrow \text{next iteration}\]
Final Output Selection:
\[\text{Output}[j] = \begin{cases} \text{buffer_A}[j] & \text{if STENCIL_ITERATIONS } \bmod 2 = 0 \\ \text{buffer_B}[j] & \text{if STENCIL_ITERATIONS } \bmod 2 = 1 \end{cases}\]
Key concepts
In this puzzle, you’ll learn about:
- Implementing double-buffering patterns for iterative algorithms
- Coordinating explicit memory barriers using mbarrier APIs
- Managing alternating read/write buffer roles across iterations
The key insight is understanding how to safely coordinate buffer swapping in iterative algorithms where race conditions between read and write operations can corrupt data if not properly synchronized.
Why this matters: Most GPU tutorials show simple one-pass algorithms, but real-world applications often require iterative refinement with multiple passes over data. Double-buffering is essential for algorithms like iterative solvers, image processing filters, and simulation updates where each iteration depends on the complete results of the previous iteration.
Previous vs. current synchronization:
- Previous puzzles (P8,
P12, P15): Simple
barrier()calls for single-pass algorithms - This puzzle: Explicit mbarrier APIs for precise control over buffer swap timing
Memory barrier specialization: Unlike basic thread synchronization, this puzzle uses explicit memory barriers that provide fine-grained control over when memory operations complete, essential for complex memory access patterns.
Configuration
System parameters:
- Image size:
SIZE = 1024elements (1D for simplicity) - Threads per block:
TPB = 256threads organized as(256, 1)block dimension - Grid configuration:
(4, 1)blocks to process entire image in tiles (4 blocks total) - Data type:
DType.float32for all computations
Iteration parameters:
- Stencil iterations:
STENCIL_ITERATIONS = 3refinement passes - Buffer count:
BUFFER_COUNT = 2(double-buffering) - Stencil kernel: 3-point averaging with radius 1
Buffer architecture:
- buffer_A: Primary shared memory buffer (
[256]elements) - buffer_B: Secondary shared memory buffer (
[256]elements) - Role alternation: Buffers swap between read source and write target each iteration
Processing requirements:
Initialization phase:
- Buffer setup: Initialize buffer_A with input data, buffer_B with zeros
- Barrier initialization: Set up mbarrier objects for synchronization points
- Thread coordination: All threads participate in initialization
Iterative processing:
- Even iterations (0, 2, 4…): Read from buffer_A, write to buffer_B
- Odd iterations (1, 3, 5…): Read from buffer_B, write to buffer_A
- Stencil operation: 3-point average \((\text{left} + \text{center} + \text{right}) / 3\)
- Boundary handling: Use adaptive averaging for elements at buffer edges
Memory barrier coordination:
- mbarrier_arrive(): Each thread signals completion of write phase
- mbarrier_test_wait(): All threads wait until everyone completes writes
- Buffer swap safety: Prevents reading from buffer while others still writing
- Barrier reinitialization: Reset barrier state between iterations
Output phase:
- Final buffer selection: Choose active buffer based on iteration parity
- Global memory write: Copy final results to output array
- Completion barrier: Ensure all writes finish before block termination
Code to complete
# Double-buffered stencil configuration
comptime STENCIL_ITERATIONS = 3
comptime BUFFER_COUNT = 2
def double_buffered_stencil_computation(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
"""Double-buffered stencil computation with memory barrier coordination.
Iteratively applies 3-point stencil using alternating buffers.
Uses mbarrier APIs for precise buffer swap coordination.
"""
# Double-buffering: Two shared memory buffers
var buffer_A = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var buffer_B = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
# Memory barriers for coordinating buffer swaps
var init_barrier = stack_allocation[
dtype=DType.uint64, address_space=AddressSpace.SHARED
](row_major[1]())
var iter_barrier = stack_allocation[
dtype=DType.uint64, address_space=AddressSpace.SHARED
](row_major[1]())
var final_barrier = stack_allocation[
dtype=DType.uint64, address_space=AddressSpace.SHARED
](row_major[1]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Initialize barriers (only thread 0)
if local_i == 0:
mbarrier_init(init_barrier.ptr, TPB)
mbarrier_init(iter_barrier.ptr, TPB)
mbarrier_init(final_barrier.ptr, TPB)
# Initialize buffer_A with input data
# FILL ME IN (roughly 4 lines)
# Wait for buffer_A initialization
_ = mbarrier_arrive(init_barrier.ptr)
_ = mbarrier_test_wait(init_barrier.ptr, TPB)
# Iterative stencil processing with double-buffering
comptime for iteration in range(STENCIL_ITERATIONS):
comptime if iteration % 2 == 0:
# Even iteration: Read from A, Write to B
# FILL ME IN (roughly 12 lines)
...
else:
# Odd iteration: Read from B, Write to A
# FILL ME IN (roughly 12 lines)
...
# Memory barrier: wait for all writes before buffer swap
_ = mbarrier_arrive(iter_barrier.ptr)
_ = mbarrier_test_wait(iter_barrier.ptr, TPB)
# Reinitialize barrier for next iteration
if local_i == 0:
mbarrier_init(iter_barrier.ptr, TPB)
# Write final results from active buffer
if local_i < TPB and global_i < size:
comptime if STENCIL_ITERATIONS % 2 == 0:
# Even iterations end in buffer_A
output[global_i] = buffer_A[local_i]
else:
# Odd iterations end in buffer_B
output[global_i] = buffer_B[local_i]
# Final barrier
_ = mbarrier_arrive(final_barrier.ptr)
_ = mbarrier_test_wait(final_barrier.ptr, TPB)
View full file: problems/p29/p29.mojo
Tips
Buffer initialization
- Initialize
buffer_Awith input data,buffer_Bcan start empty - Use proper bounds checking with zero-padding for out-of-range elements
- Only thread 0 should initialize the mbarrier objects
- Set up separate barriers for different synchronization points
Iteration control
- Use
@parameter for iteration in range(STENCIL_ITERATIONS)for compile-time unrolling - Determine buffer roles using
iteration % 2to alternate read/write assignments - Apply stencil operation only within valid bounds with neighbor checking
Stencil computation
- Implement 3-point averaging:
(left + center + right) / 3 - Handle boundary conditions by only including valid neighbors in average
- Use adaptive counting to handle edge cases gracefully
Memory barrier coordination
- Call
mbarrier_arrive()after each thread completes its write operations - Use
mbarrier_test_wait()to ensure all threads finish before buffer swap - Reinitialize barriers between iterations for reuse:
mbarrier_init() - Only thread 0 should reinitialize barriers to avoid race conditions
Output selection
- Choose final active buffer based on
STENCIL_ITERATIONS % 2 - Even iteration counts end with data in buffer_A
- Odd iteration counts end with data in buffer_B
- Write final results to global output with bounds checking
Running the code
To test your solution, run the following command in your terminal:
pixi run p29 --double-buffer
pixi run -e amd p29 --double-buffer
uv run poe p29 --double-buffer
After completing the puzzle successfully, you should see output similar to:
Puzzle 29: GPU Synchronization Primitives
==================================================
TPB: 256
SIZE: 1024
STENCIL_ITERATIONS: 3
BUFFER_COUNT: 2
Testing Puzzle 29B: Double-Buffered Stencil Computation
============================================================
Double-buffered stencil completed
Input sample: 1.0 1.0 1.0
GPU output sample: 1.0 1.0 1.0
✅ Double-buffered stencil test PASSED!
Solution
def double_buffered_stencil_computation(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, MutAnyOrigin],
size: Int,
):
"""Double-buffered stencil computation with memory barrier coordination.
Iteratively applies 3-point stencil using alternating buffers.
Uses mbarrier APIs for precise buffer swap coordination.
"""
# Double-buffering: Two shared memory buffers
var buffer_A = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var buffer_B = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
# Memory barriers for coordinating buffer swaps
var init_barrier = stack_allocation[
dtype=DType.uint64, address_space=AddressSpace.SHARED
](row_major[1]())
var iter_barrier = stack_allocation[
dtype=DType.uint64, address_space=AddressSpace.SHARED
](row_major[1]())
var final_barrier = stack_allocation[
dtype=DType.uint64, address_space=AddressSpace.SHARED
](row_major[1]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Initialize barriers (only thread 0)
if local_i == 0:
mbarrier_init(init_barrier.ptr, TPB)
mbarrier_init(iter_barrier.ptr, TPB)
mbarrier_init(final_barrier.ptr, TPB)
# Initialize buffer_A with input data
if local_i < TPB and global_i < size:
buffer_A[local_i] = input[global_i]
else:
buffer_A[local_i] = 0.0
# Wait for buffer_A initialization
_ = mbarrier_arrive(init_barrier.ptr)
_ = mbarrier_test_wait(init_barrier.ptr, TPB)
# Iterative stencil processing with double-buffering
comptime for iteration in range(STENCIL_ITERATIONS):
comptime if iteration % 2 == 0:
# Even iteration: Read from A, Write to B
if local_i < TPB:
var stencil_sum: Scalar[dtype] = 0.0
var stencil_count: Int = 0
# 3-point stencil: [i-1, i, i+1]
for offset in range(-1, 2):
sample_idx = local_i + offset
if sample_idx >= 0 and sample_idx < TPB:
stencil_sum += rebind[Scalar[dtype]](
buffer_A[sample_idx]
)
stencil_count += 1
if stencil_count > 0:
buffer_B[local_i] = stencil_sum / Scalar[dtype](
stencil_count
)
else:
buffer_B[local_i] = buffer_A[local_i]
else:
# Odd iteration: Read from B, Write to A
if local_i < TPB:
var stencil_sum: Scalar[dtype] = 0.0
var stencil_count: Int = 0
# 3-point stencil: [i-1, i, i+1]
for offset in range(-1, 2):
sample_idx = local_i + offset
if sample_idx >= 0 and sample_idx < TPB:
stencil_sum += rebind[Scalar[dtype]](
buffer_B[sample_idx]
)
stencil_count += 1
if stencil_count > 0:
buffer_A[local_i] = stencil_sum / Scalar[dtype](
stencil_count
)
else:
buffer_A[local_i] = buffer_B[local_i]
# Memory barrier: wait for all writes before buffer swap
_ = mbarrier_arrive(iter_barrier.ptr)
_ = mbarrier_test_wait(iter_barrier.ptr, TPB)
# Reinitialize barrier for next iteration
if local_i == 0:
mbarrier_init(iter_barrier.ptr, TPB)
# Write final results from active buffer
if local_i < TPB and global_i < size:
comptime if STENCIL_ITERATIONS % 2 == 0:
# Even iterations end in buffer_A
output[global_i] = buffer_A[local_i]
else:
# Odd iterations end in buffer_B
output[global_i] = buffer_B[local_i]
# Final barrier
_ = mbarrier_arrive(final_barrier.ptr)
_ = mbarrier_test_wait(final_barrier.ptr, TPB)
The key insight is recognizing this as a double-buffering architecture problem with explicit memory barrier coordination:
- Design alternating buffer roles: Swap read/write responsibilities each iteration
- Implement explicit memory barriers: Use mbarrier APIs for precise synchronization control
- Coordinate iterative processing: Ensure complete iteration results before buffer swaps
- Optimize memory access patterns: Keep all processing in fast shared memory
Complete Solution with Detailed Explanation
The double-buffered stencil solution demonstrates sophisticated memory barrier coordination and iterative processing patterns. This approach enables safe iterative refinement algorithms that require precise control over memory access timing.
Double-buffering architecture design
The fundamental breakthrough in this puzzle is explicit memory barrier control rather than simple thread synchronization:
Traditional approach: Use basic
barrier() for
simple thread coordination
- All threads execute same operation on different data
- Single barrier call synchronizes thread completion
- No control over specific memory operation timing
This puzzle’s innovation: Different buffer roles coordinated with explicit memory barriers
- buffer_A and buffer_B alternate between read source and write target
- mbarrier APIs provide precise control over memory operation completion
- Explicit coordination prevents race conditions during buffer transitions
Iterative processing coordination
Unlike single-pass algorithms, this establishes iterative refinement with careful buffer management:
- Iteration 0: Read from buffer_A (initialized with input), write to buffer_B
- Iteration 1: Read from buffer_B (previous results), write to buffer_A
- Iteration 2: Read from buffer_A (previous results), write to buffer_B
- Continue alternating: Each iteration refines results from previous iteration
Memory barrier API usage
Understanding the mbarrier coordination pattern:
- mbarrier_init(): Initialize barrier for specific thread count (TPB)
- mbarrier_arrive(): Signal individual thread completion of write phase
- mbarrier_test_wait(): Block until all threads signal completion
- Reinitialization: Reset barrier state between iterations for reuse
Critical timing sequence:
- All threads write: Each thread updates its assigned buffer element
- Signal completion: Each thread calls
mbarrier_arrive() - Wait for all: All threads call
mbarrier_test_wait() - Safe to proceed: Now safe to swap buffer roles for next iteration
Stencil operation mechanics
The 3-point stencil operation with adaptive boundary handling:
Interior elements (indices 1 to 254):
# Average with left, center, and right neighbors
stencil_sum = buffer[i-1] + buffer[i] + buffer[i+1]
result[i] = stencil_sum / 3.0
Boundary elements (indices 0 and 255):
# Only include valid neighbors in average
stencil_count = 0
for neighbor in valid_neighbors:
stencil_sum += buffer[neighbor]
stencil_count += 1
result[i] = stencil_sum / Float32(stencil_count)
Buffer role alternation
The ping-pong buffer pattern ensures data integrity:
Even iterations (0, 2, 4…):
- Read source: buffer_A contains current data
- Write target: buffer_B receives updated results
- Memory flow: buffer_A → stencil operation → buffer_B
Odd iterations (1, 3, 5…):
- Read source: buffer_B contains current data
- Write target: buffer_A receives updated results
- Memory flow: buffer_B → stencil operation → buffer_A
Race condition prevention
Memory barriers eliminate multiple categories of race conditions:
Without barriers (broken):
# Thread A writes to buffer_B[10]
buffer_B[10] = stencil_result_A
# Thread B immediately reads buffer_B[10] for its stencil
# RACE CONDITION: Thread B might read old value before Thread A's write completes
stencil_input = buffer_B[10] // Undefined behavior!
With barriers (correct):
# All threads write their results
buffer_B[local_i] = stencil_result
# Signal write completion
mbarrier_arrive(barrier)
# Wait for ALL threads to complete writes
mbarrier_test_wait(barrier, TPB)
# Now safe to read - all writes guaranteed complete
stencil_input = buffer_B[neighbor_index] // Always sees correct values
Output buffer selection
Final result location depends on iteration parity:
Mathematical determination:
- STENCIL_ITERATIONS = 3 (odd number)
- Final active buffer: Iteration 2 writes to buffer_B
- Output source: Copy from buffer_B to global memory
Implementation pattern:
@parameter
if STENCIL_ITERATIONS % 2 == 0:
# Even total iterations end in buffer_A
output[global_i] = buffer_A[local_i]
else:
# Odd total iterations end in buffer_B
output[global_i] = buffer_B[local_i]
Performance characteristics
Memory hierarchy optimization:
- Global memory: Accessed only for input loading and final output
- Shared memory: All iterative processing uses fast shared memory
- Register usage: Minimal due to shared memory focus
Synchronization overhead:
- mbarrier cost: Higher than basic barrier() but provides essential control
- Iteration scaling: Overhead increases linearly with iteration count
- Thread efficiency: All threads remain active throughout processing
Real-world applications
This double-buffering pattern is fundamental to:
Iterative solvers:
- Gauss-Seidel and Jacobi methods for linear systems
- Iterative refinement for numerical accuracy
- Multigrid methods with level-by-level processing
Image processing:
- Multi-pass filters (bilateral, guided, edge-preserving)
- Iterative denoising algorithms
- Heat diffusion and anisotropic smoothing
Simulation algorithms:
- Cellular automata with state evolution
- Particle systems with position updates
- Fluid dynamics with iterative pressure solving
Key technical insights
Memory barrier philosophy:
- Explicit control: Precise timing control over memory operations vs automatic synchronization
- Race prevention: Essential for any algorithm with alternating read/write patterns
- Performance trade-off: Higher synchronization cost for guaranteed correctness
Double-buffering benefits:
- Data integrity: Eliminates read-while-write hazards
- Algorithm clarity: Clean separation between current and next iteration state
- Memory efficiency: No need for global memory intermediate storage
Iteration management:
- Compile-time unrolling:
@parameter forenables optimization opportunities - State tracking: Buffer role alternation must be deterministic
- Boundary handling: Adaptive stencil operations handle edge cases gracefully
This solution demonstrates how to design iterative GPU algorithms that require precise memory access control, moving beyond simple parallel loops to sophisticated memory management patterns used in production numerical software.
Puzzle 30: GPU Performance Profiling
Beyond Correct Code
Note: This part is specific to compatible NVIDIA GPUs
This chapter introduces systematic performance analysis that transforms working GPU code into high-performance code. Unlike previous puzzles that focused on correctness and GPU features, these challenges explore profiling methodologies used in production GPU software development.
What you’ll learn:
- Professional profiling tools: NSight Systems and NSight Compute for comprehensive performance analysis
- Performance detective work: Using profiler data to identify bottlenecks and optimization opportunities
- Memory system insights: Understanding how memory access patterns dramatically impact performance
- Counter-intuitive discoveries: Learning when “good” metrics actually indicate performance problems
- Evidence-based optimization: Making optimization decisions based on profiler data, not assumptions
Why this matters: Most GPU tutorials teach basic performance concepts, but real-world GPU development requires systematic profiling methodologies to identify actual bottlenecks, understand memory system behavior, and make informed optimization decisions. These skills bridge the gap between academic examples and production GPU computing.
Overview
GPU performance profiling transforms correct code into high-performance code through systematic analysis. This chapter explores professional profiling tools and detective methodologies used in production GPU development.
Core learning objectives:
- Learn profiling tool selection and understand when to use NSight Systems vs NSight Compute
- Develop performance detective skills using real profiler output to identify bottlenecks
- Discover counter-intuitive insights about GPU memory systems and caching behavior
- Learn evidence-based optimization based on profiler data rather than assumptions
Key concepts
Professional profiling tools:
- NSight Systems (
nsys): System-wide timeline analysis for CPU-GPU coordination and memory transfers - NSight Compute (
ncu): Detailed kernel analysis for memory efficiency and compute utilization - Systematic methodology: Evidence-based bottleneck identification and optimization validation
Key insights you’ll discover:
- Counter-intuitive behavior: When high cache hit rates actually indicate poor performance
- Memory access patterns: How coalescing dramatically impacts bandwidth utilization
- Tool-guided optimization: Using profiler data to make decisions rather than performance assumptions
Configuration
Requirements:
- NVIDIA GPU: CUDA-compatible hardware with profiling enabled
- CUDA Toolkit: NSight Systems and NSight Compute tools
- Build setup: Optimized code with debug info (
--debug-level=full)
Methodology:
- System-wide analysis with NSight Systems to identify major bottlenecks
- Kernel deep-dives with NSight Compute for memory system analysis
- Evidence-based conclusions using profiler data to guide optimization
Puzzle structure
This chapter contains two interconnected components that build upon each other:
NVIDIA Profiling Basics Tutorial
Learn the essential NVIDIA profiling ecosystem through hands-on examples with actual profiler output.
You’ll learn:
- NSight Systems for system-wide timeline analysis and bottleneck identification
- NSight Compute for detailed kernel analysis and memory system insights
- Professional profiling workflows and best practices from production GPU development
The Cache Hit Paradox Detective Case
Apply profiling skills to solve a performance mystery where three identical vector addition kernels have dramatically different performance.
The challenge: Discover why the kernel with the highest cache hit rates has the worst performance - a counter-intuitive insight that challenges traditional CPU-based performance thinking.
Detective skills: Use real NSight Systems and NSight Compute data to understand memory coalescing effects and evidence-based optimization.
Getting started
Learning path:
- Profiling Basics Tutorial - Learn NSight Systems and NSight Compute
- Cache Hit Paradox Detective Case - Apply skills to solve performance mysteries
Prerequisites:
- GPU memory hierarchies and access patterns
- GPU programming fundamentals (threads, blocks, warps, shared memory)
- Command-line profiling tools experience
Learning outcome: Professional-level profiling skills for systematic bottleneck identification and evidence-based optimization used in production GPU development.
This chapter teaches that systematic profiling reveals truths that intuition misses - GPU performance optimization requires tool-guided discovery rather than assumptions.
Additional resources:
- NVIDIA CUDA Best Practices Guide - Profiling
- NSight Systems User Guide
- NSight Compute CLI User Guide
📚 NVIDIA Profiling Basics
Overview
You’ve learned GPU programming fundamentals and advanced patterns. Part II
taught you debugging techniques for correctness using compute-sanitizer
and cuda-gdb, while other parts covered different GPU features like warp
programming, memory systems, and block-level operations. Your kernels work
correctly - but are they fast?
This tutorial follows NVIDIA’s recommended profiling methodology from the CUDA Best Practices Guide.
Key Insight: A correct kernel can still be orders of magnitude slower than optimal. Profiling bridges the gap between working code and high-performance code.
The profiling toolkit
Since you have cuda-toolkit via pixi, you have access to NVIDIA’s professional
profiling suite:
NSight Systems (nsys) - the “big picture” tool
Purpose: System-wide performance analysis (NSight Systems Documentation)
- Timeline view of CPU-GPU interaction
- Memory transfer bottlenecks
- Kernel launch overhead
- Multi-GPU coordination
- API call tracing
Available interfaces: Command-line (nsys) and GUI (nsys-ui)
Use when:
- Understanding overall application flow
- Identifying CPU-GPU synchronization issues
- Analyzing memory transfer patterns
- Finding kernel launch bottlenecks
# See the help
pixi run nsys --help
# Basic system-wide profiling
pixi run nsys profile --trace=cuda,nvtx --output=timeline mojo your_program.mojo
# Interactive analysis
pixi run nsys stats --force-export=true timeline.nsys-rep
NSight Compute (ncu) - the “kernel deep-dive” tool
Purpose: Detailed single-kernel performance analysis (NSight Compute Documentation)
- Roofline model analysis
- Memory hierarchy utilization
- Warp execution efficiency
- Register/shared memory usage
- Compute unit utilization
Available interfaces: Command-line (ncu) and GUI (ncu-ui)
Use when:
- Optimizing specific kernel performance
- Understanding memory access patterns
- Analyzing compute vs memory bound kernels
- Identifying warp divergence issues
# See the help
pixi run ncu --help
# Detailed kernel profiling
pixi run ncu --set full --output kernel_profile mojo your_program.mojo
# Focus on specific kernels
pixi run ncu --kernel-name regex:your_kernel_name mojo your_program.mojo
Tool selection decision tree
Performance Problem
|
v
Know which kernel?
| |
No Yes
| |
v v
NSight Kernel-specific issue?
Systems | |
| No Yes
v | |
Timeline | v
Analysis <----+ NSight Compute
|
v
Kernel Deep-Dive
Quick Decision Guide:
- Start with NSight Systems (
nsys) if you’re unsure where the bottleneck is - Use NSight Compute (
ncu) when you know exactly which kernel to optimize - Use both for comprehensive analysis (common workflow)
Hands-on: system-wide profiling with NSight Systems
Let’s profile the Matrix Multiplication implementations from Puzzle 16 to understand performance differences.
GUI Note: The NSight Systems and Compute GUIs (
nsys-ui,ncu-ui) require a display and OpenGL support. On headless servers or remote systems without X11 forwarding, use the command-line versions (nsys,ncu) with text-based analysis viansys statsandncu --import --page details. You can also transfer.nsys-repand.ncu-repfiles to local machines for GUI analysis.
Step 1: Prepare your code for profiling
Critical: For accurate profiling, build with full debug information while keeping optimizations enabled:
pixi shell -e nvidia
# Build with full debug info (for comprehensive source mapping) with optimizations enabled
mojo build --debug-level=full solutions/p16/p16.mojo -o solutions/p16/p16_optimized
# Test the optimized build
./solutions/p16/p16_optimized --naive
Why this matters:
- Full debug info: Provides complete symbol tables, variable names, and source line mapping for profilers
- Comprehensive analysis: Enables NSight tools to correlate performance data with specific code locations
- Optimizations enabled: Ensures realistic performance measurements that match production builds
Step 2: Capture system-wide profile
# Profile the optimized build with comprehensive tracing
nsys profile \
--trace=cuda,nvtx \
--output=matmul_naive \
--force-overwrite=true \
./solutions/p16/p16_optimized --naive
Command breakdown:
--trace=cuda,nvtx: Capture CUDA API calls and custom annotations--output=matmul_naive: Save profile asmatmul_naive.nsys-rep--force-overwrite=true: Replace existing profiles- Final argument: Your Mojo program
Step 3: Analyze the timeline
# Generate text-based statistics
nsys stats --force-export=true matmul_naive.nsys-rep
# Key metrics to look for:
# - GPU utilization percentage
# - Memory transfer times
# - Kernel execution times
# - CPU-GPU synchronization gaps
What you’ll see (actual output from a 2×2 matrix multiplication):
** CUDA API Summary (cuda_api_sum):
Time (%) Total Time (ns) Num Calls Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name
-------- --------------- --------- --------- -------- -------- -------- ----------- --------------------
81.9 8617962 3 2872654.0 2460.0 1040 8614462 4972551.6 cuMemAllocAsync
15.1 1587808 4 396952.0 5965.5 3810 1572067 783412.3 cuMemAllocHost_v2
0.6 67152 1 67152.0 67152.0 67152 67152 0.0 cuModuleLoadDataEx
0.4 44961 1 44961.0 44961.0 44961 44961 0.0 cuLaunchKernelEx
** CUDA GPU Kernel Summary (cuda_gpu_kern_sum):
Time (%) Total Time (ns) Instances Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name
-------- --------------- --------- -------- -------- -------- -------- ----------- ----------------------------------------
100.0 1920 1 1920.0 1920.0 1920 1920 0.0 p16_naive_matmul_Layout_Int6A6AcB6A6AsA6A6A
** CUDA GPU MemOps Summary (by Time) (cuda_gpu_mem_time_sum):
Time (%) Total Time (ns) Count Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Operation
-------- --------------- ----- -------- -------- -------- -------- ----------- ----------------------------
49.4 4224 3 1408.0 1440.0 1312 1472 84.7 [CUDA memcpy Device-to-Host]
36.0 3072 4 768.0 528.0 416 1600 561.0 [CUDA memset]
14.6 1248 3 416.0 416.0 416 416 0.0 [CUDA memcpy Host-to-Device]
Key Performance Insights:
- Memory allocation dominates: 81.9% of total time spent on
cuMemAllocAsync - Kernel is lightning fast: Only 1,920 ns (0.000001920 seconds) execution time
- Memory transfer breakdown: 49.4% Device→Host, 36.0% memset, 14.6% Host→Device
- Tiny data sizes: All memory operations are < 0.001 MB (4 float32 values = 16 bytes)
Step 4: Compare implementations
Profile different versions and compare:
# Make sure you've in pixi shell still `pixi run -e nvidia`
# Profile shared memory version
nsys profile --trace=cuda,nvtx --force-overwrite=true --output=matmul_shared ./solutions/p16/p16_optimized --single-block
# Profile tiled version
nsys profile --trace=cuda,nvtx --force-overwrite=true --output=matmul_tiled ./solutions/p16/p16_optimized --tiled
# Profile idiomatic tiled version
nsys profile --trace=cuda,nvtx --force-overwrite=true --output=matmul_idiomatic_tiled ./solutions/p16/p16_optimized --idiomatic-tiled
# Analyze each implementation separately (nsys stats processes one file at a time)
nsys stats --force-export=true matmul_shared.nsys-rep
nsys stats --force-export=true matmul_tiled.nsys-rep
nsys stats --force-export=true matmul_idiomatic_tiled.nsys-rep
How to compare the results:
- Look at GPU Kernel Summary - Compare execution times between implementations
- Check Memory Operations - See if shared memory reduces global memory traffic
- Compare API overhead - All should have similar memory allocation patterns
Manual comparison workflow:
# Run each analysis and save output for comparison
nsys stats --force-export=true matmul_naive.nsys-rep > naive_stats.txt
nsys stats --force-export=true matmul_shared.nsys-rep > shared_stats.txt
nsys stats --force-export=true matmul_tiled.nsys-rep > tiled_stats.txt
nsys stats --force-export=true matmul_idiomatic_tiled.nsys-rep > idiomatic_tiled_stats.txt
Fair Comparison Results (actual output from profiling):
Comparison 1: 2 x 2 matrices
| Implementation | Memory Allocation | Kernel Execution | Performance |
|---|---|---|---|
| Naive | 81.9% cuMemAllocAsync | ✅ 1,920 ns | Baseline |
Shared (--single-block) | 81.8% cuMemAllocAsync | ✅ 1,984 ns | +3.3% slower |
Comparison 2: 9 x 9 matrices
| Implementation | Memory Allocation | Kernel Execution | Performance |
|---|---|---|---|
| Tiled (manual) | 81.1% cuMemAllocAsync | ✅ 2,048 ns | Baseline |
| Idiomatic Tiled | 81.6% cuMemAllocAsync | ✅ 2,368 ns | +15.6% slower |
Key Insights from Fair Comparisons:
Both Matrix Sizes Are Tiny for GPU Work!:
- 2×2 matrices: 4 elements - completely overhead-dominated
- 9×9 matrices: 81 elements - still completely overhead-dominated
- Real GPU workloads: Thousands to millions of elements per dimension
What These Results Actually Show:
- All variants dominated by memory allocation (>81% of time)
- Kernel execution is irrelevant compared to setup costs
- “Optimizations” can hurt: Shared memory adds 3.3% overhead, async_copy adds 15.6%
- The real lesson: For tiny workloads, algorithm choice doesn’t matter - overhead dominates everything
Why This Happens:
- GPU setup cost (memory allocation, kernel launch) is fixed regardless of problem size
- For tiny problems, this fixed cost dwarfs computation time
- Optimizations designed for large problems become overhead for small ones
Real-World Profiling Lessons:
- Problem size context matters: Both 2×2 and 9×9 are tiny for GPUs
- Fixed costs dominate small problems: Memory allocation, kernel launch overhead
- “Optimizations” can hurt tiny workloads: Shared memory, async operations add overhead
- Don’t optimize tiny problems: Focus on algorithms that scale to real workloads
- Always benchmark: Assumptions about “better” code are often wrong
Understanding Small Kernel Profiling: This 2×2 matrix example demonstrates a classic small-kernel pattern:
- The actual computation (matrix multiply) is extremely fast (1,920 ns)
- Memory setup overhead dominates the total time (97%+ of execution)
- This is why real-world GPU optimization focuses on:
- Batching operations to amortize setup costs
- Memory reuse to reduce allocation overhead
- Larger problem sizes where compute becomes the bottleneck
Hands-on: kernel deep-dive with NSight Compute
Now let’s dive deep into a specific kernel’s performance characteristics.
Step 1: Profile a specific kernel
# Make sure you're in an active shell
pixi shell -e nvidia
# Profile the naive MatMul kernel in detail (using our optimized build)
ncu \
--set full \
-o kernel_analysis \
--force-overwrite \
./solutions/p16/p16_optimized --naive
Common Issue: Permission Error
If you get
ERR_NVGPUCTRPERM - The user does not have permission to access NVIDIA GPU Performance Counters, try these > solutions:# Add NVIDIA driver option (safer than rmmod) echo 'options nvidia "NVreg_RestrictProfilingToAdminUsers=0"' | sudo tee -a /etc/modprobe.d/nvidia-kernel-common.conf # Set kernel parameter sudo sysctl -w kernel.perf_event_paranoid=0 # Make permanent echo 'kernel.perf_event_paranoid=0' | sudo tee -a /etc/sysctl.conf # Reboot required for driver changes to take effect sudo reboot # Then run the ncu command again ncu \ --set full \ -o kernel_analysis \ --force-overwrite \ ./solutions/p16/p16_optimized --naive
Step 2: Analyze key metrics
# Generate detailed report (correct syntax)
ncu --import kernel_analysis.ncu-rep --page details
Real NSight Compute Output (from your 2×2 naive MatMul):
GPU Speed Of Light Throughput
----------------------- ----------- ------------
DRAM Frequency Ghz 6.10
SM Frequency Ghz 1.30
Elapsed Cycles cycle 3733
Memory Throughput % 1.02
DRAM Throughput % 0.19
Duration us 2.88
Compute (SM) Throughput % 0.00
----------------------- ----------- ------------
Launch Statistics
-------------------------------- --------------- ---------------
Block Size 9
Grid Size 1
Threads thread 9
Waves Per SM 0.00
-------------------------------- --------------- ---------------
Occupancy
------------------------------- ----------- ------------
Theoretical Occupancy % 33.33
Achieved Occupancy % 2.09
------------------------------- ----------- ------------
Critical Insights from Real Data:
Performance analysis - the brutal truth
- Compute Throughput: 0.00% - GPU is completely idle computationally
- Memory Throughput: 1.02% - Barely touching memory bandwidth
- Achieved Occupancy: 2.09% - Using only 2% of GPU capability
- Grid Size: 1 block - Completely underutilizing 80 multiprocessors!
Why performance is so poor
- Tiny problem size: 2×2 matrix = 4 elements total
- Poor launch configuration: 9 threads in 1 block (should be multiples of 32)
- Massive underutilization: 0.00 waves per SM (need thousands for efficiency)
Key optimization recommendations from NSight Compute
- “Est. Speedup: 98.75%” - Increase grid size to use all 80 SMs
- “Est. Speedup: 71.88%” - Use thread blocks as multiples of 32
- “Kernel grid is too small” - Need much larger problems for GPU efficiency
Step 3: The reality check
What This Profiling Data Teaches Us:
- Tiny problems are GPU poison: 2×2 matrices completely waste GPU resources
- Launch configuration matters: Wrong thread/block sizes kill performance
- Scale matters more than algorithm: No optimization can fix a fundamentally tiny problem
- NSight Compute is honest: It tells us when our kernel performance is poor
The Real Lesson:
- Don’t optimize toy problems - they’re not representative of real GPU workloads
- Focus on realistic workloads - 1000×1000+ matrices where optimizations actually matter
- Use profiling to guide optimization - but only on problems worth optimizing
For our tiny 2×2 example: All the sophisticated algorithms (shared memory, tiling) just add overhead to an already overhead-dominated workload.
Reading profiler output like a performance detective
Common performance patterns
Pattern 1: Memory-bound kernel
NSight Systems shows: Long memory transfer times NSight Compute shows: High memory throughput, low compute utilization Solution: Optimize memory access patterns, use shared memory
Pattern 2: Low occupancy
NSight Systems shows: Short kernel execution with gaps NSight Compute shows: Low achieved occupancy Solution: Reduce register usage, optimize block size
Pattern 3: Warp divergence
NSight Systems shows: Irregular kernel execution patterns NSight Compute shows: Low warp execution efficiency Solution: Minimize conditional branches, restructure algorithms
Profiling detective workflow
Performance Issue
|
v
NSight Systems: Big Picture
|
v
GPU Well Utilized?
| |
No Yes
| |
v v
Fix CPU-GPU NSight Compute: Kernel Detail
Pipeline |
v
Memory or Compute Bound?
| | |
Memory Compute Neither
| | |
v v v
Optimize Optimize Check
Memory Arithmetic Occupancy
Access
Profiling best practices
For comprehensive profiling guidelines, refer to the Best Practices Guide - Performance Metrics.
Do’s
- Profile representative workloads: Use realistic data sizes and patterns
- Build with full debug info: Use
--debug-level=fullfor comprehensive profiling data and source mapping with optimizations - Warm up the GPU: Run kernels multiple times, profile later iterations
- Compare alternatives: Always profile multiple implementations
- Focus on hotspots: Optimize the kernels that take the most time
Don’ts
- Don’t profile without debug info: You won’t be able to map performance
back to source code (
mojo build --help) - Don’t profile single runs: GPU performance can vary between runs
- Don’t ignore memory transfers: CPU-GPU transfers often dominate
- Don’t optimize prematurely: Profile first, then optimize
Common pitfalls and solutions
Pitfall 1: Cold start effects
# Wrong: Profile first run
nsys profile mojo your_program.mojo
# Right: Warm up, then profile
nsys profile --delay=5 mojo your_program.mojo # Let GPU warm up
Pitfall 2: Wrong build configuration
# Wrong: Full debug build (disables optimizations) i.e. `--no-optimization`
mojo build -O0 your_program.mojo -o your_program
# Wrong: No debug info (can't map to source)
mojo build your_program.mojo -o your_program
# Right: Optimized build with full debug info for profiling
mojo build --debug-level=full your_program.mojo -o optimized_program
nsys profile ./optimized_program
Pitfall 3: Ignoring memory transfers
# Look for this pattern in NSight Systems:
CPU -> GPU transfer: 50ms
Kernel execution: 2ms
GPU -> CPU transfer: 48ms
# Total: 100ms (kernel is only 2%!)
Solution: Overlap transfers with compute, reduce transfer frequency (covered in Part IX)
Pitfall 4: Single kernel focus
# Wrong: Only profile the "slow" kernel
ncu --kernel-name regex:slow_kernel program
# Right: Profile the whole application first
nsys profile mojo program.mojo # Find real bottlenecks
Best practices and advanced options
Advanced NSight Systems profiling
For comprehensive system-wide analysis, use these advanced nsys flags:
# Production-grade profiling command
nsys profile \
--gpu-metrics-devices=all \
--trace=cuda,osrt,nvtx \
--trace-fork-before-exec=true \
--cuda-memory-usage=true \
--cuda-um-cpu-page-faults=true \
--cuda-um-gpu-page-faults=true \
--opengl-gpu-workload=false \
--delay=2 \
--duration=30 \
--sample=cpu \
--cpuctxsw=process-tree \
--output=comprehensive_profile \
--force-overwrite=true \
./your_program
Flag explanations:
--gpu-metrics-devices=all: Collect GPU metrics from all devices--trace=cuda,osrt,nvtx: Comprehensive API tracing--cuda-memory-usage=true: Track memory allocation/deallocation--cuda-um-cpu/gpu-page-faults=true: Monitor Unified Memory page faults--delay=2: Wait 2 seconds before profiling (avoid cold start)--duration=30: Profile for 30 seconds max--sample=cpu: Include CPU sampling for hotspot analysis--cpuctxsw=process-tree: Track CPU context switches
Advanced NSight Compute profiling
For detailed kernel analysis with comprehensive metrics:
# Full kernel analysis with all metric sets
ncu \
--set full \
--import-source=on \
--kernel-id=:::1 \
--launch-skip=0 \
--launch-count=1 \
--target-processes=all \
--replay-mode=kernel \
--cache-control=all \
--clock-control=base \
--apply-rules=yes \
--check-exit-code=yes \
--export=detailed_analysis \
--force-overwrite \
./your_program
# Focus on specific performance aspects
ncu \
--set=@roofline \
--section=InstructionStats \
--section=LaunchStats \
--section=Occupancy \
--section=SpeedOfLight \
--section=WarpStateStats \
--metrics=sm__cycles_elapsed.avg,dram__throughput.avg.pct_of_peak_sustained_elapsed \
--kernel-name regex:your_kernel_.* \
--export=targeted_analysis \
./your_program
Key NSight Compute flags:
--set full: Collect all available metrics (comprehensive but slow)--set @roofline: Optimized set for roofline analysis--import-source=on: Map results back to source code--replay-mode=kernel: Replay kernels for accurate measurements--cache-control=all: Control GPU caches for consistent results--clock-control=base: Lock clocks to base frequencies--section=SpeedOfLight: Include Speed of Light analysis--metrics=...: Collect specific metrics only--kernel-name regex:pattern: Target kernels using regex patterns (not--kernel-regex)
Profiling workflow best practices
1. Progressive profiling strategy
# Step 1: Quick overview (fast)
nsys profile --trace=cuda --duration=10 --output=quick_look ./program
# Step 2: Detailed system analysis (medium)
nsys profile --trace=cuda,osrt,nvtx --cuda-memory-usage=true --output=detailed ./program
# Step 3: Kernel deep-dive (slow but comprehensive)
ncu --set=@roofline --kernel-name regex:hotspot_kernel ./program
2. Multi-run analysis for reliability
# Profile multiple runs and compare
for i in {1..5}; do
nsys profile --output=run_${i} ./program
nsys stats run_${i}.nsys-rep > stats_${i}.txt
done
# Compare results
diff stats_1.txt stats_2.txt
3. Targeted kernel profiling
# First, identify hotspot kernels
nsys profile --trace=cuda,nvtx --output=overview ./program
nsys stats overview.nsys-rep | grep -A 10 "GPU Kernel Summary"
# Then profile specific kernels
ncu --kernel-name="identified_hotspot_kernel" --set full ./program
Environment and build best practices
Optimal build configuration
# For profiling: optimized with full debug info
mojo build --debug-level=full --optimization-level=3 program.mojo -o program_profile
# Verify build settings
mojo build --help | grep -E "(debug|optimization)"
Profiling environment setup
# Disable GPU boost for consistent results
sudo nvidia-smi -ac 1215,1410 # Lock memory and GPU clocks
# Set deterministic behavior
export CUDA_LAUNCH_BLOCKING=1 # Synchronous launches for accurate timing
# Increase driver limits for profiling
echo 0 | sudo tee /proc/sys/kernel/perf_event_paranoid
echo 'options nvidia "NVreg_RestrictProfilingToAdminUsers=0"' | sudo tee -a /etc/modprobe.d/nvidia-kernel-common.conf
Memory and performance isolation
# Clear GPU memory before profiling
nvidia-smi --gpu-reset
# Disable other GPU processes
sudo fuser -v /dev/nvidia* # Check what's using GPU
sudo pkill -f cuda # Kill CUDA processes if needed
# Run with high priority
sudo nice -n -20 nsys profile ./program
Analysis and reporting best practices
Comprehensive report generation
# Generate multiple report formats
nsys stats --report=cuda_api_sum,cuda_gpu_kern_sum,cuda_gpu_mem_time_sum --format=csv --output=. profile.nsys-rep
# Export for external analysis
nsys export --type=sqlite profile.nsys-rep
nsys export --type=json profile.nsys-rep
# Generate comparison reports
nsys stats --report=cuda_gpu_kern_sum baseline.nsys-rep > baseline_kernels.txt
nsys stats --report=cuda_gpu_kern_sum optimized.nsys-rep > optimized_kernels.txt
diff -u baseline_kernels.txt optimized_kernels.txt
Performance regression testing
#!/bin/bash
# Automated profiling script for CI/CD
BASELINE_TIME=$(nsys stats baseline.nsys-rep | grep "Total Time" | awk '{print $3}')
CURRENT_TIME=$(nsys stats current.nsys-rep | grep "Total Time" | awk '{print $3}')
REGRESSION_THRESHOLD=1.10 # 10% slowdown threshold
if (( $(echo "$CURRENT_TIME > $BASELINE_TIME * $REGRESSION_THRESHOLD" | bc -l) )); then
echo "Performance regression detected: ${CURRENT_TIME}ns vs ${BASELINE_TIME}ns"
exit 1
fi
Next steps
Now that you understand profiling fundamentals:
- Practice with your existing kernels: Profile puzzles you’ve already solved
- Prepare for optimization: Puzzle 31 will use these insights for occupancy optimization
- Understand the tools: Experiment with different NSight Systems and NSight Compute options
Remember: Profiling is not just about finding slow code - it’s about understanding your program’s behavior and making informed optimization decisions.
For additional profiling resources, see:
🕵 The Cache Hit Paradox
Overview
Welcome to your first profiling detective case! You have three GPU kernels
that all compute the same simple vector addition: output[i] = a[i] + b[i].
They should all perform identically, right?
Wrong! These kernels have dramatically different performance - one is orders of magnitude slower than the others. Your mission: use the profiling tools you just learned to discover why.
The challenge
Welcome to a performance mystery that will challenge everything you think you know about GPU optimization! You’re confronted with three seemingly identical vector addition kernels that compute the exact same mathematical operation:
output[i] = a[i] + b[i] // Simple arithmetic - what could go wrong?
The shocking reality:
- All three kernels produce identical, correct results
- One kernel runs ~50x slower than the others
- The slowest kernel has the highest cache hit rates (counterintuitive!)
- Standard performance intuition completely fails
Your detective mission:
- Identify the performance culprit - Which kernel is catastrophically slow?
- Uncover the cache paradox - Why do high cache hits indicate poor performance?
- Decode memory access patterns - What makes identical operations behave so differently?
- Learn profiling methodology - Use NSight tools to gather evidence, not guesses
Why this matters: This puzzle reveals a fundamental GPU performance principle that challenges CPU-based intuition. The skills you develop here apply to real-world GPU optimization where memory access patterns often matter more than algorithmic complexity.
The twist: We approach this without looking at the source code first - using only profiling tools as your guide, just like debugging production performance issues. After we obtained the profiling results, we look at the code for further analysis.
Your detective toolkit
From the profiling tutorial, you have:
- NSight Systems (
nsys) - Find which kernels are slow - NSight Compute (
ncu) - Analyze why kernels are slow - Memory efficiency metrics - Detect poor access patterns
Getting started
Step 1: Run the benchmark
pixi shell -e nvidia
mojo problems/p30/p30.mojo --benchmark
You’ll see dramatic timing differences between kernels! One kernel is much slower than the others. Your job is to figure out why using profiling tools without looking at the code.
Example output:
| name | met (ms) | iters |
| ------- | --------- | ----- |
| kernel1 | 171.85 | 11 |
| kernel2 | 1546.68 | 11 | <- This one is much slower!
| kernel3 | 172.18 | 11 |
Step 2: Prepare your code for profiling
Critical: For accurate profiling, build with full debug information while keeping optimizations enabled:
mojo build --debug-level=full problems/p30/p30.mojo -o problems/p30/p30_profiler
Why this matters:
- Full debug info: Provides complete symbol tables, variable names, and source line mapping for profilers
- Comprehensive analysis: Enables NSight tools to correlate performance data with specific code locations
- Optimizations enabled: Ensures realistic performance measurements that match production builds
Step 3: System-wide investigation (NSight Systems)
Profile each kernel to see the big picture:
# Profile each kernel individually using the optimized build (with warmup to avoid cold start effects)
nsys profile --trace=cuda,osrt,nvtx --delay=2 --output=./problems/p30/kernel1_profile ./problems/p30/p30_profiler --kernel1
nsys profile --trace=cuda,osrt,nvtx --delay=2 --output=./problems/p30/kernel2_profile ./problems/p30/p30_profiler --kernel2
nsys profile --trace=cuda,osrt,nvtx --delay=2 --output=./problems/p30/kernel3_profile ./problems/p30/p30_profiler --kernel3
# Analyze the results
nsys stats --force-export=true ./problems/p30/kernel1_profile.nsys-rep > ./problems/p30/kernel1_profile.txt
nsys stats --force-export=true ./problems/p30/kernel2_profile.nsys-rep > ./problems/p30/kernel2_profile.txt
nsys stats --force-export=true ./problems/p30/kernel3_profile.nsys-rep > ./problems/p30/kernel3_profile.txt
Look for:
- GPU Kernel Summary - Which kernels take longest?
- Kernel execution times - How much do they vary?
- Memory transfer patterns - Are they similar across implementations?
Step 4: Kernel deep-dive (NSight Compute)
Once you identify the slow kernel, analyze it with NSight Compute:
# Deep-dive into memory patterns for each kernel using the optimized build
ncu --set=@roofline --section=MemoryWorkloadAnalysis -f -o ./problems/p30/kernel1_analysis ./problems/p30/p30_profiler --kernel1
ncu --set=@roofline --section=MemoryWorkloadAnalysis -f -o ./problems/p30/kernel2_analysis ./problems/p30/p30_profiler --kernel2
ncu --set=@roofline --section=MemoryWorkloadAnalysis -f -o ./problems/p30/kernel3_analysis ./problems/p30/p30_profiler --kernel3
# View the results
ncu --import ./problems/p30/kernel1_analysis.ncu-rep --page details
ncu --import ./problems/p30/kernel2_analysis.ncu-rep --page details
ncu --import ./problems/p30/kernel3_analysis.ncu-rep --page details
When you run these commands, you’ll see output like this:
Kernel1: Memory Throughput: ~308 Gbyte/s, Max Bandwidth: ~51%
Kernel2: Memory Throughput: ~6 Gbyte/s, Max Bandwidth: ~12%
Kernel3: Memory Throughput: ~310 Gbyte/s, Max Bandwidth: ~52%
Key metrics to investigate:
- Memory Throughput (Gbyte/s) - Actual memory bandwidth achieved
- Max Bandwidth (%) - Percentage of theoretical peak bandwidth utilized
- L1/TEX Hit Rate (%) - L1 cache efficiency
- L2 Hit Rate (%) - L2 cache efficiency
🤔 The Counterintuitive Result: You’ll notice Kernel2 has the highest cache hit rates but the lowest performance! This is the key mystery to solve.
Step 5: Detective questions
Use your profiling evidence to answer these questions by looking at the kernel code problems/p30/p30.mojo:
Performance analysis
- Which kernel achieves the highest Memory Throughput? (Look at Gbyte/s values)
- Which kernel has the lowest Max Bandwidth utilization? (Compare percentages)
- What’s the performance gap in memory throughput? (Factor difference between fastest and slowest)
The cache paradox
- Which kernel has the highest L1/TEX Hit Rate?
- Which kernel has the highest L2 Hit Rate?
- 🤯 Why does the kernel with the BEST cache hit rates perform the WORST?
Memory access detective work
- Can high cache hit rates actually indicate a performance problem?
- What memory access pattern would cause high cache hits but low throughput?
- Why might “efficient caching” be a symptom of “inefficient memory access”?
The “Aha!” Moment
- Based on the profiling evidence, what fundamental GPU memory principle does this demonstrate?
Key insight to discover: Sometimes high cache hit rates are a red flag, not a performance victory!
Solution
The mystery reveals a fundamental GPU performance principle: memory access patterns dominate performance for memory-bound operations, even when kernels perform identical computations.
The profiling evidence reveals:
- Performance hierarchy: Kernel1 and Kernel3 are fast, Kernel2 is catastrophically slow (orders of magnitude difference)
- Memory throughput tells the story: Fast kernels achieve high bandwidth utilization, slow kernel achieves minimal utilization
- The cache paradox: The slowest kernel has the highest cache hit rates
- revealing that high cache hits can indicate poor memory access patterns
- Memory access patterns matter more than algorithmic complexity for memory-bound GPU workloads
Complete Solution with Enhanced Explanation
This profiling detective case demonstrates how memory access patterns create orders-of-magnitude performance differences, even when kernels perform identical mathematical operations.
Performance evidence from profiling
NSight Systems Timeline Analysis:
- Kernel 1: Short execution time - EFFICIENT
- Kernel 3: Similar to Kernel 1 - EFFICIENT
- Kernel 2: Dramatically longer execution time - INEFFICIENT
NSight Compute Memory Analysis (Hardware-Agnostic Patterns):
- Efficient kernels (1 & 3): High memory throughput, good bandwidth utilization, moderate cache hit rates
- Inefficient kernel (2): Very low memory throughput, poor bandwidth utilization, extremely high cache hit rates
The cache paradox revealed
🤯 The Counterintuitive Discovery:
- Kernel2 has the HIGHEST cache hit rates but WORST performance
- This challenges conventional wisdom: “High cache hits = good performance”
- The truth: High cache hit rates can be a symptom of inefficient memory access patterns
Why the Cache Paradox Occurs:
Traditional CPU intuition (INCORRECT for GPUs):
- Higher cache hit rates always mean better performance
- Cache hits reduce memory traffic, improving efficiency
GPU memory reality (CORRECT understanding):
- Coalescing matters more than caching for memory-bound workloads
- Poor access patterns can cause artificial cache hit inflation
- Memory bandwidth utilization is the real performance indicator
Root cause analysis - memory access patterns
Actual Kernel Implementations from p30.mojo:
Kernel 1 - Efficient Coalesced Access:
def kernel1(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
var i = block_dim.x * block_idx.x + thread_idx.x
if i < size:
output[i] = a[i] + b[i]
Standard thread indexing - adjacent threads access adjacent memory
Kernel 2 - Inefficient Strided Access:
def kernel2(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
var tid = block_idx.x * block_dim.x + thread_idx.x
var stride = 512
var i = tid
while i < size:
output[i] = a[i] + b[i]
i += stride
Large stride=512 creates memory access gaps - same operation but scattered access
Kernel 3 - Efficient Reverse Access:
def kernel3(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
var tid = block_idx.x * block_dim.x + thread_idx.x
var total_threads = (SIZE // 1024) * 1024
for step in range(0, size, total_threads):
var forward_i = step + tid
if forward_i < size:
var reverse_i = size - 1 - forward_i
output[reverse_i] = a[reverse_i] + b[reverse_i]
Reverse indexing but still predictable - adjacent threads access adjacent addresses (just backwards)
Pattern Analysis:
- Kernel 1: Classic coalesced access - adjacent threads access adjacent memory
- Kernel 2: Catastrophic strided access - threads jump by 512 elements
- Kernel 3: Reverse but still coalesced within warps - predictable pattern
Understanding the memory system
GPU Memory Architecture Fundamentals:
- Warp execution: 32 threads execute together
- Cache line size: 128 bytes (32 float32 values)
- Coalescing requirement: Adjacent threads should access adjacent memory
p30.mojo Configuration Details:
comptime SIZE = 16 * 1024 * 1024 # 16M elements (64MB of float32 data)
comptime THREADS_PER_BLOCK = (1024, 1) # 1024 threads per block
comptime BLOCKS_PER_GRID = (SIZE // 1024, 1) # 16,384 blocks total
comptime dtype = DType.float32 # 4 bytes per element
Why these settings matter:
- Large dataset (16M): Makes memory access patterns clearly visible
- 1024 threads/block: Maximum CUDA threads per block
- 32 warps/block: Each block contains 32 warps of 32 threads each
Memory Access Efficiency Visualization:
KERNEL 1 (Coalesced): KERNEL 2 (Strided by 512):
Warp threads 0-31: Warp threads 0-31:
Thread 0: Memory[0] Thread 0: Memory[0]
Thread 1: Memory[1] Thread 1: Memory[512]
Thread 2: Memory[2] Thread 2: Memory[1024]
... ...
Thread 31: Memory[31] Thread 31: Memory[15872]
Result: 1 cache line fetch Result: 32 separate cache line fetches
Status: ~308 GB/s throughput Status: ~6 GB/s throughput
Cache: Efficient utilization Cache: Same lines hit repeatedly!
KERNEL 3 (Reverse but Coalesced):
Warp threads 0-31 (first iteration):
Thread 0: Memory[SIZE-1] (reverse_i = SIZE-1-0)
Thread 1: Memory[SIZE-2] (reverse_i = SIZE-1-1)
Thread 2: Memory[SIZE-3] (reverse_i = SIZE-1-2)
...
Thread 31: Memory[SIZE-32] (reverse_i = SIZE-1-31)
Result: Adjacent addresses (just backwards)
Status: ~310 GB/s throughput (nearly identical to Kernel 1)
Cache: Efficient utilization despite reverse order
The cache paradox explained
Why Kernel2 (stride=512) has high cache hit rates but poor performance:
The stride=512 disaster explained:
# Each thread processes multiple elements with huge gaps:
Thread 0: elements [0, 512, 1024, 1536, 2048, ...]
Thread 1: elements [1, 513, 1025, 1537, 2049, ...]
Thread 2: elements [2, 514, 1026, 1538, 2050, ...]
...
Why this creates the cache paradox:
- Cache line repetition: Each 512-element jump stays within overlapping cache line regions
- False efficiency illusion: Same cache lines accessed repeatedly = artificially high “hit rates”
- Bandwidth catastrophe: 32 threads × 32 separate cache lines = massive memory traffic
- Warp execution mismatch: GPU designed for coalesced access, but getting scattered access
Concrete example with float32 (4 bytes each):
- Cache line: 128 bytes = 32 float32 values
- Stride 512: Thread jumps by 512×4 = 2048 bytes = 16 cache lines apart!
- Warp impact: 32 threads need 32 different cache lines instead of 1
The key insight: High cache hits in Kernel2 are repeated access to inefficiently fetched data, not smart caching!
Profiling methodology insights
Systematic Detective Approach:
Phase 1: NSight Systems (Big Picture)
- Identify which kernels are slow
- Rule out obvious bottlenecks (memory transfers, API overhead)
- Focus on kernel execution time differences
Phase 2: NSight Compute (Deep Analysis)
- Analyze memory throughput metrics
- Compare bandwidth utilization percentages
- Investigate cache hit rates and patterns
Phase 3: Connect Evidence to Theory
PROFILING EVIDENCE → CODE ANALYSIS:
NSight Compute Results: Actual Code Pattern:
- Kernel1: ~308 GB/s → i = block_idx*block_dim + thread_idx (coalesced)
- Kernel2: ~6 GB/s, 99% L2 hits → i += 512 (catastrophic stride)
- Kernel3: ~310 GB/s → reverse_i = size-1-forward_i (reverse coalesced)
The profiler data directly reveals the memory access efficiency!
Evidence-to-Code Connection:
- High throughput + normal cache rates = Coalesced access (Kernels 1 & 3)
- Low throughput + high cache rates = Inefficient strided access (Kernel 2)
- Memory bandwidth utilization reveals true efficiency regardless of cache statistics
Real-world performance implications
This pattern affects many GPU applications:
Scientific Computing:
- Stencil computations: Neighbor access patterns in grid simulations
- Linear algebra: Matrix traversal order (row-major vs column-major)
- PDE solvers: Grid point access patterns in finite difference methods
Graphics and Image Processing:
- Texture filtering: Sample access patterns in shaders
- Image convolution: Filter kernel memory access
- Color space conversion: Channel interleaving strategies
Machine Learning:
- Matrix operations: Memory layout optimization in GEMM
- Tensor contractions: Multi-dimensional array access patterns
- Data loading: Batch processing and preprocessing pipelines
Fundamental GPU optimization principles
Memory-First Optimization Strategy:
- Memory patterns dominate: Access patterns often matter more than algorithmic complexity
- Coalescing is critical: Design for adjacent threads accessing adjacent memory
- Measure bandwidth utilization: Focus on actual throughput, not just cache statistics
- Profile systematically: Use NSight tools to identify real bottlenecks
Key Technical Insights:
- Memory-bound workloads: Bandwidth utilization determines performance
- Cache metrics can mislead: High hit rates don’t always indicate efficiency
- Warp-level thinking: Design access patterns for 32-thread execution groups
- Hardware-aware programming: Understanding GPU memory hierarchy is essential
Key takeaways
This detective case reveals that GPU performance optimization requires abandoning CPU intuition for memory-centric thinking:
Critical insights:
- High cache hit rates can indicate poor memory access patterns (not good performance)
- Memory bandwidth utilization matters more than cache statistics
- Simple coalesced patterns often outperform complex algorithms
- Profiling tools reveal counterintuitive performance truths
Practical methodology:
- Profile systematically with NSight Systems and NSight Compute
- Design for adjacent threads accessing adjacent memory (coalescing)
- Let profiler evidence guide optimization decisions, not intuition
The cache paradox demonstrates that high-level metrics can mislead without architectural understanding - applicable far beyond GPU programming.
Puzzle 31: GPU Occupancy Optimization
Why this puzzle matters
Building on Puzzle 30: You’ve just learned GPU profiling tools and discovered how memory access patterns can create dramatic performance differences. Now you’re ready for the next level: resource optimization.
The Learning Journey:
- Puzzle 30 taught you to diagnose performance problems using NSight
profiling (
nsysandncu) - Puzzle 31 teaches you to predict and control performance through resource management
- Together, they give you the complete toolkit for GPU optimization
What You’ll Discover: GPU performance isn’t just about algorithmic efficiency - it’s about how your code uses limited hardware resources. Every GPU has finite registers, shared memory, and execution units. Understanding occupancy - the ratio of active warps to maximum possible warps per SM - is crucial for:
- Latency hiding: Keeping the GPU busy while waiting for memory
- Resource allocation: Balancing registers, shared memory, and thread blocks
- Performance prediction: Understanding bottlenecks before they happen
- Optimization strategy: Knowing when to focus on occupancy vs other factors
Why This Matters Beyond GPUs: The principles you learn here apply to any parallel computing system where resources are shared among many execution units
- from CPUs with hyperthreading to distributed computing clusters.
Overview
GPU Occupancy is the ratio of active warps to the maximum possible warps per SM. It determines how well your GPU can hide memory latency through warp switching.
SAXPY is a mnemonic for Single-precision Alpha times X plus Y. This puzzle
explores three SAXPY kernels (y[i] = alpha * x[i] + y[i]) with identical math
but different resource usage:
comptime SIZE = 32 * 1024 * 1024 # 32M elements - larger workload to show occupancy effects
comptime THREADS_PER_BLOCK = (1024, 1)
comptime BLOCKS_PER_GRID = (SIZE // 1024, 1)
comptime dtype = DType.float32
comptime layout = row_major[SIZE]()
comptime LayoutType = type_of(layout)
comptime ALPHA = Scalar[dtype](2.5) # SAXPY coefficient
def minimal_kernel(
y: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
x: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
alpha: Float32,
size: Int,
):
"""Minimal SAXPY kernel - simple and register-light for high occupancy."""
var i = block_dim.x * block_idx.x + thread_idx.x
if i < size:
# Direct computation: y[i] = alpha * x[i] + y[i]
# Uses minimal registers (~8), no shared memory
y[i] = alpha * x[i] + y[i]
View full file: problems/p31/p31.mojo
def sophisticated_kernel(
y: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
x: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
alpha: Float32,
size: Int,
):
"""Sophisticated SAXPY kernel - over-engineered with excessive resource usage.
"""
# Maximum shared memory allocation (close to 48KB limit)
var shared_cache = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](
row_major[1024 * 12]()
) # 48KB
var i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
if i < size:
# REAL computational work that can't be optimized away - affects final result
var base_x = x[i]
var base_y = y[i]
# Simulate "precision enhancement" - multiple small adjustments that add up
# Each computation affects the final result so compiler can't eliminate them
# But artificially increases register pressure
var precision_x1 = base_x * 1.0001
var precision_x2 = precision_x1 * 0.9999
var precision_x3 = precision_x2 * 1.000001
var precision_x4 = precision_x3 * 0.999999
var precision_y1 = base_y * 1.000005
var precision_y2 = precision_y1 * 0.999995
var precision_y3 = precision_y2 * 1.0000001
var precision_y4 = precision_y3 * 0.9999999
# Multiple alpha computations for "stability" - should equal alpha
var alpha1 = alpha * 1.00001 * 0.99999
var alpha2 = alpha1 * 1.000001 * 0.999999
var alpha3 = alpha2 * 1.0000001 * 0.9999999
var alpha4 = alpha3 * 1.00000001 * 0.99999999
# Complex polynomial "optimization" - creates register pressure
var x_power2 = precision_x4 * precision_x4
var x_power3 = x_power2 * precision_x4
var x_power4 = x_power3 * precision_x4
var x_power5 = x_power4 * precision_x4
var x_power6 = x_power5 * precision_x4
var x_power7 = x_power6 * precision_x4
var x_power8 = x_power7 * precision_x4
# "Advanced" mathematical series that contributes tiny amount to result
var series_term1 = x_power2 * 0.0000001 # x^2/10M
var series_term2 = x_power4 * 0.00000001 # x^4/100M
var series_term3 = x_power6 * 0.000000001 # x^6/1B
var series_term4 = x_power8 * 0.0000000001 # x^8/10B
var series_correction = (
series_term1 - series_term2 + series_term3 - series_term4
)
# Over-engineered shared memory usage with multiple caching strategies
if local_i < 1024:
shared_cache[local_i] = precision_x4
shared_cache[local_i + 1024] = precision_y4
shared_cache[local_i + 2048] = alpha4
shared_cache[local_i + 3072] = series_correction
barrier()
# Load from shared memory for "optimization"
var cached_x = shared_cache[local_i] if local_i < 1024 else precision_x4
var cached_y = (
shared_cache[local_i + 1024] if local_i < 1024 else precision_y4
)
var cached_alpha = (
shared_cache[local_i + 2048] if local_i < 1024 else alpha4
)
var cached_correction = (
shared_cache[local_i + 3072] if local_i
< 1024 else series_correction
)
# Final "high precision" computation - all work contributes to result
var high_precision_result = (
cached_alpha * cached_x + cached_y + cached_correction
)
# Over-engineered result with massive resource usage but mathematically ~= alpha*x + y
y[i] = high_precision_result
View full file: problems/p31/p31.mojo
def balanced_kernel(
y: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
x: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
alpha: Float32,
size: Int,
):
"""Balanced SAXPY kernel - efficient optimization with moderate resources.
"""
# Reasonable shared memory usage for effective caching (16KB)
var shared_cache = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](
row_major[1024 * 4]()
) # 16KB total
var i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
if i < size:
# Moderate computational work that contributes to result
var base_x = x[i]
var base_y = y[i]
# Light precision enhancement - less than sophisticated kernel
var enhanced_x = base_x * 1.00001 * 0.99999
var enhanced_y = base_y * 1.00001 * 0.99999
var stable_alpha = alpha * 1.000001 * 0.999999
# Moderate computational optimization
var x_squared = enhanced_x * enhanced_x
var optimization_hint = x_squared * 0.000001
# Efficient shared memory caching - only what we actually need
if local_i < 1024:
shared_cache[local_i] = enhanced_x
shared_cache[local_i + 1024] = enhanced_y
barrier()
# Use cached values efficiently
var cached_x = shared_cache[local_i] if local_i < 1024 else enhanced_x
var cached_y = (
shared_cache[local_i + 1024] if local_i < 1024 else enhanced_y
)
# Balanced computation - moderate work, good efficiency
var result = stable_alpha * cached_x + cached_y + optimization_hint
# Balanced result with moderate resource usage (~15 registers, 16KB shared)
y[i] = result
View full file: problems/p31/p31.mojo
Your task
Use profiling tools to investigate three kernels and answer analysis questions about occupancy optimization. The kernels compute identical results but use resources very differently - your job is to discover why performance and occupancy behave counterintuitively!
The specific numerical results shown in this puzzle are based on NVIDIA A10G (Ampere 8.6) hardware. Your results will vary depending on your GPU vendor and architecture (NVIDIA: Pascal/Turing/Ampere/Ada/Hopper, AMD: RDNA/GCN, Apple: M1/M2/M3/M4/M5), but the fundamental concepts, methodology, and insights remain universally applicable across modern GPUs. Use
pixi run gpu-specsto get your specific hardware values.
Configuration
Requirements:
- NVIDIA GPU with CUDA toolkit
- NSight Compute from Puzzle 30
⚠️ GPU compatibility note: The default configuration uses aggressive settings that may fail on older or lower-capability GPUs:
comptime SIZE = 32 * 1024 * 1024 # 32M elements (~256MB memory per array) comptime THREADS_PER_BLOCK = (1024, 1) # 1024 threads per block comptime BLOCKS_PER_GRID = (SIZE // 1024, 1) # 32768 blocksIf you encounter launch failures, reduce these values in
problems/p31/p31.mojo:
- For older GPUs (Compute Capability < 3.0): Use
THREADS_PER_BLOCK = (512, 1)andSIZE = 16 * 1024 * 1024- For limited memory GPUs (< 2GB): Use
SIZE = 8 * 1024 * 1024orSIZE = 4 * 1024 * 1024- For grid dimension limits: The
BLOCKS_PER_GRIDwill automatically adjust withSIZE
Occupancy Formula:
Theoretical Occupancy = min(
Registers Per SM / (Registers Per Thread × Threads Per Block),
Shared Memory Per SM / Shared Memory Per Block,
Max Blocks Per SM
) × Threads Per Block / Max Threads Per SM
The investigation
Step 1: Test the kernels
pixi shell -e nvidia
mojo problems/p31/p31.mojo --all
All three should produce identical results. The mystery: why do they have different performance?
Step 2: Benchmark performance
mojo problems/p31/p31.mojo --benchmark
All three should produce identical results. The mystery: why do they have different performance?
Step 3: Build for profiling
mojo build --debug-level=full problems/p31/p31.mojo -o problems/p31/p31_profiler
Step 4: Profile resource usage
# Profile each kernel's resource usage
ncu --set=@occupancy --section=LaunchStats problems/p31/p31_profiler --minimal
ncu --set=@occupancy --section=LaunchStats problems/p31/p31_profiler --sophisticated
ncu --set=@occupancy --section=LaunchStats problems/p31/p31_profiler --balanced
Record the resource usage for occupancy analysis.
Step 5: Calculate theoretical occupancy
First, identify your GPU architecture and detailed specs:
pixi run gpu-specs
Note: gpu-specs automatically detects your GPU vendor (NVIDIA/AMD/Apple)
and shows all architectural details derived from your hardware - no lookup
tables needed!
Common Architecture Specs (Reference):
| Architecture | Compute Cap | Registers/SM | Shared Mem/SM | Max Threads/SM | Max Blocks/SM |
|---|---|---|---|---|---|
| Hopper (H100) | 9.0 | 65,536 | 228KB | 2,048 | 32 |
| Ada (RTX 40xx) | 8.9 | 65,536 | 128KB | 2,048 | 32 |
| Ampere (RTX 30xx, A100, A10G) | 8.0, 8.6 | 65,536 | 164KB | 2,048 | 32 |
| Turing (RTX 20xx) | 7.5 | 65,536 | 96KB | 1,024 | 16 |
| Pascal (GTX 10xx) | 6.1 | 65,536 | 96KB | 2,048 | 32 |
📚 Official Documentation:
- NVIDIA CUDA Compute Capability Table
- CUDA Programming Guide - Compute Capabilities
- Hopper Architecture In-Depth
- Ampere Architecture Whitepaper
⚠️ Note: These are theoretical maximums. Actual occupancy may be lower due to hardware scheduling constraints, driver overhead, and other factors.
Using your GPU specs and the occupancy formula:
- Threads Per Block: 1024 (from our kernel)
Use the occupancy formula and your hardware specifications to predict each kernel’s theoretical occupancy.
Step 6: Measure actual occupancy
# Measure actual occupancy for each kernel
ncu --metrics=smsp__warps_active.avg.pct_of_peak_sustained_active problems/p31/p31_profiler --minimal
ncu --metrics=smsp__warps_active.avg.pct_of_peak_sustained_active problems/p31/p31_profiler --sophisticated
ncu --metrics=smsp__warps_active.avg.pct_of_peak_sustained_active problems/p31/p31_profiler --balanced
Compare the actual measured occupancy with your theoretical calculations - this is where the mystery reveals itself!
Key insights
💡 Occupancy Threshold: Once you have sufficient occupancy for latency hiding (~25-50%), additional occupancy provides diminishing returns.
💡 Memory Bound vs Compute Bound: SAXPY is memory-bound. Memory bandwidth often matters more than occupancy for memory-bound kernels.
💡 Resource Efficiency: Modern GPUs can handle moderate register pressure (20-40 registers/thread) without dramatic occupancy loss.
Your task: Answer the following questions
After completing the investigation steps above, answer these analysis questions to solve the occupancy mystery:
Performance Analysis (Step 2):
- Which kernel is fastest? Which is slowest? Record the timing differences.
Resource Profiling (Step 4):
- Record for each kernel: Registers Per Thread, Shared Memory Per Block, Warps Per SM
Theoretical Calculations (Step 5):
- Calculate theoretical occupancy for each kernel using your GPU specs and the occupancy formula. Which should be highest/lowest?
Measured Occupancy (Step 6):
- How do the measured occupancy values compare to your calculations?
The Occupancy Mystery:
- Why do all three kernels achieve similar occupancy (~64-66% results may vary depending on gpu architecture) despite dramatically different resource usage?
- Why is performance nearly identical (<2% difference) when resource usage varies so dramatically (19 vs 40 registers, 0KB vs 49KB shared memory)?
- What does this reveal about the relationship between theoretical occupancy calculations and real-world GPU behavior?
- For this SAXPY workload, what is the actual performance bottleneck if it’s not occupancy?
Tips
Your detective toolkit:
- NSight Compute (
ncu) - Measure occupancy and resource usage - GPU architecture specs - Calculate theoretical limits using
pixi run gpu-specs - Occupancy formula - Predict resource bottlenecks
- Performance benchmarks - Validate theoretical analysis
Key optimization principles:
- Calculate before optimizing: Use the occupancy formula to predict resource limits before writing code
- Measure to validate: Theoretical calculations don’t account for compiler optimizations and hardware details
- Consider workload characteristics: Memory-bound workloads need less occupancy than compute-bound operations
- Don’t optimize for maximum occupancy: Optimize for sufficient occupancy + other performance factors
- Think in terms of thresholds: 25-50% occupancy is often sufficient for latency hiding
- Profile resource usage: Use NSight Compute to understand actual register and shared memory consumption
Investigation approach:
- Start with benchmarking - See the performance differences first
- Profile with NSight Compute - Get actual resource usage and occupancy data
- Calculate theoretical occupancy - Use your GPU specs and the occupancy formula
- Compare theory vs reality - This is where the mystery reveals itself!
- Think about workload characteristics - Why might theory not match practice?
Solution
Complete Solution with Enhanced Explanation
This occupancy detective case demonstrates how resource usage affects GPU performance and reveals the complex relationship between theoretical occupancy and actual performance.
The specific calculations below are for NVIDIA A10G (Ampere 8.6) - the GPU used for testing. Your results will vary based on your GPU architecture, but the methodology and insights apply universally. Use
pixi run gpu-specsto get your specific hardware values.
Profiling evidence from resource analysis
NSight Compute Resource Analysis:
Actual Profiling Results (NVIDIA A10G - your results will vary by GPU):
- Minimal: 19 registers, ~0KB shared → 63.87% occupancy, 327.7ms
- Balanced: 25 registers, 16.4KB shared → 65.44% occupancy, 329.4ms
- Sophisticated: 40 registers, 49.2KB shared → 65.61% occupancy, 330.9ms
Performance Evidence from Benchmarking:
- All kernels perform nearly identically (~327-331ms, <2% difference)
- All achieve similar occupancy (~64-66%) despite huge resource differences
- Memory bandwidth becomes the limiting factor for all kernels
Occupancy calculations revealed
Theoretical Occupancy Analysis (NVIDIA A10G, Ampere 8.6):
GPU Specifications (from pixi run gpu-specs):
- Registers Per SM: 65,536
- Shared Memory Per SM: 164KB (architectural maximum)
- Max Threads Per SM: 1,536 (hardware limit on A10G)
- Threads Per Block: 1,024 (our configuration)
- Max Blocks Per SM: 32
Minimal Kernel Calculation:
Register Limit = 65,536 / (19 × 1,024) = 3.36 blocks per SM
Shared Memory Limit = 164KB / 0KB = ∞ blocks per SM
Hardware Block Limit = 32 blocks per SM
Thread Limit = 1,536 / 1,024 = 1 block per SM (floor)
Actual Blocks = min(3, ∞, 1) = 1 block per SM
Theoretical Occupancy = (1 × 1,024) / 1,536 = 66.7%
Balanced Kernel Calculation:
Register Limit = 65,536 / (25 × 1,024) = 2.56 blocks per SM
Shared Memory Limit = 164KB / 16.4KB = 10 blocks per SM
Hardware Block Limit = 32 blocks per SM
Thread Limit = 1,536 / 1,024 = 1 block per SM (floor)
Actual Blocks = min(2, 10, 1) = 1 block per SM
Theoretical Occupancy = (1 × 1,024) / 1,536 = 66.7%
Sophisticated Kernel Calculation:
Register Limit = 65,536 / (40 × 1,024) = 1.64 blocks per SM
Shared Memory Limit = 164KB / 49.2KB = 3.33 blocks per SM
Hardware Block Limit = 32 blocks per SM
Thread Limit = 1,536 / 1,024 = 1 block per SM (floor)
Actual Blocks = min(1, 3, 1) = 1 block per SM
Theoretical Occupancy = (1 × 1,024) / 1,536 = 66.7%
Key Discovery: Theory Matches Reality!
- Theoretical: All kernels ~66.7% (limited by A10G’s thread capacity)
- Actual Measured: All ~64-66% (very close match!)
This reveals that A10G’s thread limit dominates - you can only fit 1 block of 1,024 threads per SM when the maximum is 1,536 threads. The small difference (66.7% theoretical vs ~65% actual) comes from hardware scheduling overhead and driver limitations.
Why theory closely matches reality
Why the small gap between theoretical (66.7%) and actual (~65%) occupancy:
- Hardware Scheduling Overhead: Real warp schedulers have practical limitations beyond theoretical calculations
- CUDA Runtime Reservations: Driver and runtime overhead reduce available SM resources slightly
- Memory Controller Pressure: A10G’s memory subsystem creates slight scheduling constraints
- Power and Thermal Management: Dynamic frequency scaling affects peak performance
- Instruction Cache Effects: Real kernels have instruction fetch overhead not captured in occupancy calculations
Key Insight: The close match (66.7% theoretical vs ~65% actual) shows that A10G’s thread limit truly dominates all three kernels, regardless of their register and shared memory differences. This is an excellent example of identifying the real bottleneck!
The occupancy mystery explained
The Real Mystery Revealed:
- All kernels achieve nearly identical occupancy (~64-66%) despite dramatic resource differences
- Performance is essentially identical (<2% variation) across all kernels
- Theory correctly predicts occupancy (66.7% theoretical ≈ 65% actual)
- The mystery isn’t occupancy mismatch - it’s why identical occupancy and performance despite huge resource differences!
Why Identical Performance Despite Different Resource Usage:
SAXPY Workload Characteristics:
- Memory-bound operation: Each thread does minimal computation
(
y[i] = alpha * x[i] + y[i]) - High memory traffic: Reading 2 values, writing 1 value per thread
- Low arithmetic intensity: Only 2 FLOPS per 12 bytes of memory traffic
Memory Bandwidth Analysis (A10G):
Single Kernel Pass Analysis:
- Input arrays: 32M × 4 bytes × 2 arrays = 256MB read
- Output array: 32M × 4 bytes × 1 array = 128MB write
- Total per kernel: 384MB memory traffic
Peak Bandwidth (A10G): 600 GB/s
Single-pass time: 384MB / 600 GB/s ≈ 0.64ms theoretical minimum
Benchmark time: ~328ms (includes multiple iterations + overhead)
The Real Performance Factors:
- Memory Bandwidth Utilization: All kernels saturate available memory bandwidth
- Computational Overhead: Sophisticated kernel does extra work (register pressure effects)
- Shared Memory Benefits: Balanced kernel gets some caching advantages
- Compiler Optimizations: Modern compilers minimize register usage when possible
Understanding the occupancy threshold concept
Critical Insight: Occupancy is About “Sufficient” Not “Maximum”
Latency Hiding Requirements:
- Memory latency: ~500-800 cycles on modern GPUs
- Warp scheduling: GPU needs enough warps to hide this latency
- Sufficient threshold: Usually 25-50% occupancy provides effective latency hiding
Why Higher Occupancy Doesn’t Always Help:
Resource Competition:
- More active threads compete for same memory bandwidth
- Cache pressure increases with more concurrent accesses
- Register/shared memory pressure can hurt individual thread performance
Workload-Specific Optimization:
- Compute-bound: Higher occupancy helps hide ALU pipeline latency
- Memory-bound: Memory bandwidth limits performance regardless of occupancy
- Mixed workloads: Balance occupancy with other optimization factors
Real-world occupancy optimization principles
Systematic Occupancy Analysis Approach:
Phase 1: Calculate Theoretical Limits
# Find your GPU specs
pixi run gpu-specs
Phase 2: Profile Actual Usage
# Measure resource consumption
ncu --set=@occupancy --section=LaunchStats your_kernel
# Measure achieved occupancy
ncu --metrics=smsp__warps_active.avg.pct_of_peak_sustained_active your_kernel
Phase 3: Performance Validation
# Always validate with actual performance measurements
ncu --set=@roofline --section=MemoryWorkloadAnalysis your_kernel
Evidence-to-Decision Framework:
OCCUPANCY ANALYSIS → OPTIMIZATION STRATEGY:
High occupancy (>70%) + Good performance:
→ Occupancy is sufficient, focus on other bottlenecks
Low occupancy (<30%) + Poor performance:
→ Increase occupancy through resource optimization
Good occupancy (50-70%) + Poor performance:
→ Look for memory bandwidth, cache, or computational bottlenecks
Low occupancy (<30%) + Good performance:
→ Workload doesn't need high occupancy (memory-bound)
Practical occupancy optimization techniques
Register Optimization:
- Use appropriate data types:
float32vsfloat64,int32vsint64 - Minimize intermediate variables: Let compiler optimize temporary storage
- Loop unrolling consideration: Balance occupancy vs instruction-level parallelism
Shared Memory Optimization:
- Calculate required sizes: Avoid over-allocation
- Consider tiling strategies: Balance occupancy vs data reuse
- Bank conflict avoidance: Design access patterns for conflict-free access
Block Size Tuning:
- Test multiple configurations: 256, 512, 1024 threads per block
- Consider warp utilization: Avoid partial warps when possible
- Balance occupancy vs resource usage: Larger blocks may hit resource limits
Key takeaways: From A10G mystery to universal principles
This A10G occupancy investigation reveals a clear progression of insights that apply to all GPU optimization:
The A10G Discovery Chain:
- Thread limits dominated everything - Despite 19 vs 40 registers and 0KB vs 49KB shared memory differences, all kernels hit the same 1-block-per-SM limit due to A10G’s 1,536-thread capacity
- Theory matched reality closely - 66.7% theoretical vs ~65% measured occupancy shows our calculations work when we identify the right bottleneck
- Memory bandwidth ruled performance - With identical 66.7% occupancy, SAXPY’s memory-bound nature (600 GB/s saturated) explained identical performance despite resource differences
Universal GPU Optimization Principles:
Identify the Real Bottleneck:
- Calculate occupancy limits from all resources: registers, shared memory, AND thread capacity
- The most restrictive limit wins - don’t assume it’s always registers or shared memory
- Memory-bound workloads (like SAXPY) are limited by bandwidth, not occupancy, once you have sufficient threads for latency hiding
When Occupancy Matters vs When It Doesn’t:
- High occupancy critical: Compute-intensive kernels (GEMM, scientific simulations) that need latency hiding for ALU pipeline stalls
- Occupancy less critical: Memory-bound operations (BLAS Level 1, memory copies) where bandwidth saturation occurs before occupancy becomes limiting
- Sweet spot: 60-70% occupancy often sufficient for latency hiding - beyond that, focus on the real bottleneck
Practical Optimization Workflow:
- Profile first (
ncu --set=@occupancy) - measure actual resource usage and occupancy - Calculate theoretical limits using your GPU’s specs
(
pixi run gpu-specs) - Identify the dominant constraint - registers, shared memory, thread capacity, or memory bandwidth
- Optimize the bottleneck - don’t waste time on non-limiting resources
- Validate with end-to-end performance - occupancy is a means to performance, not the goal
The A10G case perfectly demonstrates why systematic bottleneck analysis beats intuition - the sophisticated kernel’s high register pressure was irrelevant because thread capacity dominated, and identical occupancy plus memory bandwidth saturation explained the performance mystery completely.
Puzzle 32: Bank Conflicts
Why this puzzle matters
Completing the performance trilogy: You’ve learned GPU profiling tools in Puzzle 30 and understood occupancy optimization in Puzzle 31. Now you’re ready for the final piece of the performance optimization puzzle: shared memory efficiency.
The hidden performance trap: You can write GPU kernels with perfect occupancy, optimal global memory coalescing, and identical mathematical operations - yet still experience dramatic performance differences due to how threads access shared memory. Bank conflicts represent one of the most subtle but impactful performance pitfalls in GPU programming.
The learning journey:
- Puzzle 30 taught you to measure and diagnose performance with NSight profiling
- Puzzle 31 taught you to predict and control resource usage through occupancy analysis
- Puzzle 32 teaches you to optimize shared memory access patterns for maximum efficiency
Why this matters beyond GPU programming: The principles of memory banking, conflict detection, and systematic access pattern optimization apply across many parallel computing systems - from CPU cache hierarchies to distributed memory architectures.
Note: This puzzle is specific to NVIDIA GPUs
Bank conflict analysis uses NVIDIA’s 32-bank shared memory architecture and NSight Compute profiling tools. While the optimization principles apply broadly, the specific techniques and measurements are NVIDIA CUDA-focused.
Overview
Shared memory bank conflicts occur when multiple threads in a warp simultaneously access different addresses within the same memory bank, forcing the hardware to serialize these accesses. This can transform what should be a single-cycle memory operation into multiple cycles of serialized access.
What you’ll discover:
- How GPU shared memory banking works at the hardware level
- Why identical kernels can have vastly different shared memory efficiency
- How to predict and measure bank conflicts before they impact performance
- Professional optimization strategies for designing conflict-free algorithms
The detective methodology: This puzzle follows the same evidence-based approach as previous performance puzzles - you’ll use profiling tools to uncover hidden inefficiencies, then apply systematic optimization principles to eliminate them.
Key concepts
Shared memory architecture fundamentals:
- 32-bank design: NVIDIA GPUs organize shared memory into 32 independent banks
- Conflict types: No conflict (optimal), N-way conflicts (serialized), broadcast (optimized)
- Access pattern mathematics: Bank assignment formulas and conflict prediction
- Performance impact: From optimal 1-cycle access to worst-case 32-cycle serialization
Professional optimization skills:
- Pattern analysis: Mathematical prediction of banking behavior
- Profiling methodology: NSight Compute metrics for conflict measurement
- Design principles: Conflict-free algorithm patterns and prevention strategies
- Performance validation: Evidence-based optimization using systematic measurement
Puzzle structure
This puzzle contains two complementary sections that build your expertise progressively:
📚 Understanding Shared Memory Banks
Learn the theoretical foundations of GPU shared memory banking through clear explanations and practical examples.
You’ll learn:
- How NVIDIA’s 32-bank architecture enables parallel access
- The mathematics of bank assignment and conflict prediction
- Types of conflicts and their performance implications
- Connection to previous concepts (warp execution, occupancy, profiling)
Key insight: Understanding the hardware enables you to predict performance before writing code.
Conflict-Free Patterns
Apply your banking knowledge to solve a performance mystery using professional profiling techniques.
The detective challenge: Two kernels compute identical results but have dramatically different shared memory access efficiency. Use NSight Compute to uncover why one kernel experiences systematic bank conflicts while the other achieves optimal performance.
Skills developed: Pattern analysis, conflict measurement, systematic optimization, and evidence-based performance improvement.
Getting started
Learning path:
- Understanding Shared Memory Banks - Build theoretical foundation
- Conflict-Free Patterns - Apply detective skills to real optimization
Prerequisites:
- GPU profiling experience from Puzzle 30
- Resource optimization understanding from Puzzle 31
- Shared memory programming experience from Puzzle 8 and Puzzle 16
Hardware requirements:
- NVIDIA GPU with CUDA toolkit
- NSight Compute profiling tools
- The dependencies such as profiling are managed by
pixi - Compatible GPU architecture
The optimization impact
When bank conflicts matter most:
- Matrix multiplication with shared memory tiling
- Stencil computations using shared memory caching
- Parallel reductions with stride-based memory patterns
Professional development value:
- Systematic optimization: Evidence-based performance improvement methodology
- Hardware awareness: Understanding how software maps to hardware constraints
- Pattern recognition: Identifying problematic access patterns in algorithm design
Learning outcome: Complete your GPU performance optimization toolkit with the ability to design, measure, and optimize shared memory access patterns - the final piece for professional-level GPU programming expertise.
This puzzle demonstrates that optimal GPU performance requires understanding hardware at multiple levels - from global memory coalescing through occupancy management to shared memory banking efficiency.
📚 Understanding Shared Memory Banks
Building on what you’ve learned
You’ve come a long way in your GPU optimization journey. In Puzzle 8, you discovered how shared memory provides fast, block-local storage that dramatically outperforms global memory. Puzzle 16 showed you how matrix multiplication kernels use shared memory to cache data tiles, reducing expensive global memory accesses.
But there’s a hidden performance trap lurking in shared memory that can serialize your parallel operations: bank conflicts.
The performance mystery: You can write two kernels that access shared memory in seemingly identical ways - both use the same amount of data, both have perfect occupancy, both avoid race conditions. Yet one runs 32× slower than the other. The culprit? How threads access shared memory banks.
What are shared memory banks?
Think of shared memory as a collection of 32 independent memory units called banks, each capable of serving one memory request per clock cycle. This banking system exists for a fundamental reason: hardware parallelism.
When a warp of 32 threads needs to access shared memory simultaneously, the GPU can serve all 32 requests in parallel, if each thread accesses a different bank. When multiple threads try to access the same bank, the hardware must serialize these accesses, turning what should be a 1-cycle operation into multiple cycles.
Bank address mapping
Each 4-byte word in shared memory belongs to a specific bank according to this formula:
bank_id = (byte_address / 4) % 32
Here’s how the first 128 bytes of shared memory map to banks:
| Address Range | Bank ID | Example float32 Elements |
|---|---|---|
| 0-3 bytes | Bank 0 | shared[0] |
| 4-7 bytes | Bank 1 | shared[1] |
| 8-11 bytes | Bank 2 | shared[2] |
| … | … | … |
| 124-127 bytes | Bank 31 | shared[31] |
| 128-131 bytes | Bank 0 | shared[32] |
| 132-135 bytes | Bank 1 | shared[33] |
Key insight: The banking pattern repeats every 32 elements for float32
arrays, which perfectly matches the 32-thread warp size. This is not a
coincidence - it’s designed for optimal parallel access.
Types of bank conflicts
No conflict: the ideal case
When each thread in a warp accesses a different bank, all 32 accesses complete in 1 cycle:
# Perfect case: each thread accesses a different bank
shared[thread_idx.x] # Thread 0→Bank 0, Thread 1→Bank 1, ..., Thread 31→Bank 31
Result: 32 parallel accesses, 1 cycle total
N-way bank conflicts
When N threads access different addresses in the same bank, the hardware serializes these accesses:
# 2-way conflict: stride-2 access pattern
shared[thread_idx.x * 2] # Thread 0,16→Bank 0; Thread 1,17→Bank 1; etc.
Result: 2 accesses per bank, 2 cycles total (50% efficiency)
# Worst case: all threads access different addresses in Bank 0
shared[thread_idx.x * 32] # All threads→Bank 0
Result: 32 serialized accesses, 32 cycles total (3% efficiency)
The broadcast exception
There’s one important exception to the conflict rule: broadcast access. When all threads read the same address, the hardware optimizes this into a single memory access:
# Broadcast: all threads read the same value
constant = shared[0] # All threads read shared[0]
Result: 1 access broadcasts to 32 threads, 1 cycle total
This optimization exists because broadcasting is a common pattern (loading constants, reduction operations), and the hardware can duplicate a single value to all threads without additional memory bandwidth.
Why bank conflicts matter
Performance impact
Bank conflicts directly multiply your shared memory access time:
| Conflict Type | Access Time | Efficiency | Performance Impact |
|---|---|---|---|
| No conflict | 1 cycle | 100% | Baseline |
| 2-way conflict | 2 cycles | 50% | 2× slower |
| 4-way conflict | 4 cycles | 25% | 4× slower |
| 32-way conflict | 32 cycles | 3% | 32× slower |
Real-world context
From Puzzle 30, you learned that memory access patterns can create dramatic performance differences. Bank conflicts are another example of this principle operating at the shared memory level.
Just as global memory coalescing affects DRAM bandwidth utilization, bank conflicts affect shared memory throughput. The difference is scale: global memory latency is hundreds of cycles, while shared memory conflicts add only a few cycles per access. However, in compute-intensive kernels that heavily use shared memory, these “few cycles” accumulate quickly.
Connection to warp execution
Remember from Puzzle 24 that warps execute in SIMT (Single Instruction, Multiple Thread) fashion. When a warp encounters a bank conflict, all 32 threads must wait for the serialized memory accesses to complete. This waiting time affects the entire warp’s progress, not just the conflicting threads.
This connects to the occupancy concepts from Puzzle 31: bank conflicts can prevent warps from hiding memory latency effectively, reducing the practical benefit of high occupancy.
Detecting bank conflicts
Visual pattern recognition
You can often predict bank conflicts by analyzing access patterns:
Sequential access (no conflicts):
# Thread ID: 0 1 2 3 ... 31
# Address: 0 4 8 12 ... 124
# Bank: 0 1 2 3 ... 31 ✅ All different banks
Stride-2 access (2-way conflicts):
# Thread ID: 0 1 2 3 ... 15 16 17 18 ... 31
# Address: 0 8 16 24 ... 120 4 12 20 ... 124
# Bank: 0 2 4 6 ... 30 1 3 5 ... 31
# Conflict: Banks 0,2,4... have 2 threads each ❌
Stride-32 access (32-way conflicts):
# Thread ID: 0 1 2 3 ... 31
# Address: 0 128 256 384 ... 3968
# Bank: 0 0 0 0 ... 0 ❌ All threads→Bank 0
Profiling with NSight Compute (ncu)
Building on the profiling methodology from Puzzle 30, you can measure bank conflicts quantitatively:
# Key metrics for shared memory bank conflicts
ncu --metrics=l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld,l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_st your_kernel
# Additional context metrics
ncu --metrics=smsp__sass_average_branch_targets_threads_uniform.pct your_kernel
ncu --metrics=smsp__warps_issue_stalled_membar_per_warp_active.pct your_kernel
The l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld and
l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_st metrics directly count
the number of bank conflicts for load and store operations during kernel
execution. Combined with the number of shared memory accesses, these give you
the conflict ratio - a critical performance indicator.
When bank conflicts matter most
Compute-intensive kernels
Bank conflicts have the greatest impact on kernels where:
- Shared memory is accessed frequently within tight loops
- Computational work per shared memory access is minimal
- The kernel is compute-bound rather than memory-bound
Example scenarios:
- Matrix multiplication inner loops (like the tiled versions in Puzzle 16)
- Stencil computations with shared memory caching
- Parallel reduction operations
Memory-bound vs compute-bound trade-offs
Just as Puzzle 31 showed that occupancy matters less for memory-bound workloads, bank conflicts matter less when your kernel is bottlenecked by global memory bandwidth or arithmetic intensity is very low.
However, many kernels that use shared memory do so precisely because they want to shift from memory-bound to compute-bound execution. In these cases, bank conflicts can prevent you from achieving the performance gains that motivated using shared memory in the first place.
The path forward
Understanding shared memory banking gives you the foundation to:
- Predict performance before writing code by analyzing access patterns
- Diagnose slowdowns using systematic profiling approaches
- Design conflict-free algorithms that maintain high shared memory throughput
- Make informed trade-offs between algorithm complexity and memory efficiency
In the next section, you’ll apply this knowledge through hands-on exercises that demonstrate common conflict patterns and their solutions - turning theoretical understanding into practical optimization skills.
Conflict-Free Patterns
Note: This section is specific to NVIDIA GPUs
Bank conflict analysis and profiling techniques covered here apply specifically to NVIDIA GPUs. The profiling commands use NSight Compute tools that are part of the NVIDIA CUDA toolkit.
Building on your profiling skills
You’ve learned GPU profiling fundamentals in Puzzle 30 and understood resource optimization in Puzzle 31. Now you’re ready to apply those detective skills to a new performance mystery: shared memory bank conflicts.
The detective challenge: You have two GPU kernels that perform identical
mathematical operations ((input + 10) * 2). Both produce exactly the same
results. Both use the same amount of shared memory. Both have identical
occupancy. Yet one experiences systematic performance degradation due to how
it accesses shared memory.
Your mission: Use the profiling methodology you’ve learned to uncover this hidden performance trap and understand when bank conflicts matter in real-world GPU programming.
Overview
Shared memory bank conflicts occur when multiple threads in a warp simultaneously access different addresses within the same memory bank. This detective case explores two kernels with contrasting access patterns:
comptime SIZE = 8 * 1024 # 8K elements - small enough to focus on shared memory patterns
comptime TPB = 256 # Threads per block - divisible by 32 (warp size)
comptime THREADS_PER_BLOCK = (TPB, 1)
comptime BLOCKS_PER_GRID = (SIZE // TPB, 1)
comptime dtype = DType.float32
comptime layout = row_major[SIZE]()
comptime LayoutType = type_of(layout)
def no_conflict_kernel(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
"""Perfect shared memory access - no bank conflicts.
Each thread accesses a different bank: thread_idx.x maps to bank thread_idx.x % 32.
This achieves optimal shared memory bandwidth utilization.
"""
# Shared memory buffer - each thread loads one element
var shared_buf = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Load from global memory to shared memory - no conflicts
if global_i < size:
shared_buf[local_i] = (
input[global_i] + 10.0
) # Add 10 as simple operation
barrier() # Synchronize shared memory writes
# Read back from shared memory and write to output - no conflicts
if global_i < size:
output[global_i] = shared_buf[local_i] * 2.0 # Multiply by 2
barrier() # Ensure completion
def two_way_conflict_kernel(
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
size: Int,
):
"""Stride-2 shared memory access - creates 2-way bank conflicts.
Threads 0,16 -> Bank 0, Threads 1,17 -> Bank 1, etc.
Each bank serves 2 threads, doubling access time.
"""
# Shared memory buffer - stride-2 access pattern creates conflicts
var shared_buf = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TPB]())
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# CONFLICT: stride-2 access creates 2-way bank conflicts
var conflict_index = (local_i * 2) % TPB
# Load with bank conflicts
if global_i < size:
shared_buf[conflict_index] = (
input[global_i] + 10.0
) # Same operation as no-conflict
barrier() # Synchronize shared memory writes
# Read back with same conflicts
if global_i < size:
output[global_i] = (
shared_buf[conflict_index] * 2.0
) # Same operation as no-conflict
barrier() # Ensure completion
View full file: problems/p32/p32.mojo
The mystery: These kernels compute identical results but have dramatically different shared memory access efficiency. Your job is to discover why using systematic profiling analysis.
Configuration
Requirements:
- NVIDIA GPU with CUDA toolkit and NSight Compute from Puzzle 30
- Understanding of shared memory banking concepts from the previous section
Kernel specifications:
comptime SIZE = 8 * 1024 # 8K elements - focus on shared memory patterns
comptime TPB = 256 # 256 threads per block (8 warps)
comptime BLOCKS_PER_GRID = (SIZE // TPB, 1) # 32 blocks
Key insight: The problem size is deliberately smaller than previous puzzles to highlight shared memory effects rather than global memory bandwidth limitations.
The investigation
Step 1: Verify correctness
pixi shell -e nvidia
mojo problems/p32/p32.mojo --test
Both kernels should produce identical results. This confirms that bank conflicts affect performance but not correctness.
Step 2: Benchmark performance baseline
mojo problems/p32/p32.mojo --benchmark
Record the execution times. You may notice similar performance due to the workload being dominated by global memory access, but bank conflicts will be revealed through profiling metrics.
Step 3: Build for profiling
mojo build --debug-level=full problems/p32/p32.mojo -o problems/p32/p32_profiler
Step 4: Profile bank conflicts
Use NSight Compute to measure shared memory bank conflicts quantitatively:
# Profile no-conflict kernel
ncu --metrics=l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld,l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_st problems/p32/p32_profiler --no-conflict
and
# Profile two-way conflict kernel
ncu --metrics=l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld,l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_st problems/p32/p32_profiler --two-way
Key metrics to record:
l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld.sum- Load conflictsl1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_st.sum- Store conflicts
Step 5: Analyze access patterns
Based on your profiling results, analyze the mathematical access patterns:
No-conflict kernel access pattern:
# Thread mapping: thread_idx.x directly maps to shared memory index
shared_buf[thread_idx.x] # Thread 0→Index 0, Thread 1→Index 1, etc.
# Bank mapping: Index % 32 = Bank ID
# Result: Thread 0→Bank 0, Thread 1→Bank 1, ..., Thread 31→Bank 31
Two-way conflict kernel access pattern:
# Thread mapping with stride-2 modulo operation
shared_buf[(thread_idx.x * 2) % TPB]
# For threads 0-31: Index 0,2,4,6,...,62, then wraps to 64,66,...,126, then 0,2,4...
# Bank mapping examples:
# Thread 0 → Index 0 → Bank 0
# Thread 16 → Index 32 → Bank 0 (conflict!)
# Thread 1 → Index 2 → Bank 2
# Thread 17 → Index 34 → Bank 2 (conflict!)
Your task: solve the bank conflict mystery
After completing the investigation steps above, answer these analysis questions:
Performance analysis (Steps 1-2)
- Do both kernels produce identical mathematical results?
- What are the execution time differences (if any) between the kernels?
- Why might performance be similar despite different access patterns?
Bank conflict profiling (Step 4)
- How many bank conflicts does the no-conflict kernel generate for loads and stores?
- How many bank conflicts does the two-way conflict kernel generate for loads and stores?
- What is the total conflict count difference between the kernels?
Access pattern analysis (Step 5)
- In the no-conflict kernel, which bank does Thread 0 access? Thread 31?
- In the two-way conflict kernel, which threads access Bank 0? Which access Bank 2?
- How many threads compete for the same bank in the conflict kernel?
The bank conflict detective work
- Why does the two-way conflict kernel show measurable conflicts while the no-conflict kernel shows zero?
- How does the stride-2 access pattern
(thread_idx.x * 2) % TPBcreate systematic conflicts? - Why do bank conflicts matter more in compute-intensive kernels than memory-bound kernels?
Real-world implications
- When would you expect bank conflicts to significantly impact application performance?
- How can you predict bank conflict patterns before implementing shared memory algorithms?
- What design principles help avoid bank conflicts in matrix operations and stencil computations?
Tips
Bank conflict detective toolkit:
- NSight Compute metrics - Quantify conflicts with precise measurements
- Access pattern visualization - Map thread indices to banks systematically
- Mathematical analysis - Use modulo arithmetic to predict conflicts
- Workload characteristics - Understand when conflicts matter vs when they don’t
Key investigation principles:
- Measure systematically: Use profiling tools rather than guessing about conflicts
- Visualize access patterns: Draw thread-to-bank mappings for complex algorithms
- Consider workload context: Bank conflicts matter most in compute-intensive shared memory algorithms
- Think prevention: Design algorithms with conflict-free access patterns from the start
Access pattern analysis approach:
- Map threads to indices: Understand the mathematical address calculation
- Calculate bank assignments: Use the formula
bank_id = (address / 4) % 32 - Identify conflicts: Look for multiple threads accessing the same bank
- Validate with profiling: Confirm theoretical analysis with NSight Compute measurements
Common conflict-free patterns:
- Sequential access:
shared[thread_idx.x]- each thread different bank - Broadcast access:
shared[0]for all threads - hardware optimization - Power-of-2 strides: Stride-32 often maps cleanly to banking patterns
- Padded arrays: Add padding to shift problematic access patterns
Solution
Complete Solution with Bank Conflict Analysis
This bank conflict detective case demonstrates how shared memory access patterns affect GPU performance and reveals the importance of systematic profiling for optimization.
Investigation results from profiling
Step 1: Correctness Verification Both kernels produce identical mathematical results:
✅ No-conflict kernel: PASSED
✅ Two-way conflict kernel: PASSED
✅ Both kernels produce identical results
Step 2: Performance Baseline Benchmark results show similar execution times:
| name | met (ms) | iters |
| ---------------- | ------------------ | ----- |
| no_conflict | 2.1930616745886655 | 547 |
| two_way_conflict | 2.1978922967032966 | 546 |
Key insight: Performance is nearly identical (~2.19ms vs ~2.20ms) because this workload is global memory bound rather than shared memory bound. Bank conflicts become visible through profiling metrics rather than execution time.
Bank conflict profiling evidence
No-Conflict Kernel (Optimal Access Pattern):
l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld.sum 0
l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_st.sum 0
Result: Zero conflicts for both loads and stores - perfect shared memory efficiency.
Two-Way Conflict Kernel (Problematic Access Pattern):
l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld.sum 256
l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_st.sum 256
Result: 256 conflicts each for loads and stores - clear evidence of systematic banking problems.
Total conflict difference: 512 conflicts (256 + 256) demonstrate measurable shared memory inefficiency.
Access pattern mathematical analysis
No-conflict kernel access pattern
Thread-to-index mapping:
shared_buf[thread_idx.x]
Bank assignment analysis:
Thread 0 → Index 0 → Bank 0 % 32 = 0
Thread 1 → Index 1 → Bank 1 % 32 = 1
Thread 2 → Index 2 → Bank 2 % 32 = 2
...
Thread 31 → Index 31 → Bank 31 % 32 = 31
Result: Perfect bank distribution - each thread accesses a different bank within each warp, enabling parallel access.
Two-way conflict kernel access pattern
Thread-to-index mapping:
shared_buf[(thread_idx.x * 2) % TPB] # TPB = 256
Bank assignment analysis for first warp (threads 0-31):
Thread 0 → Index (0*2)%256 = 0 → Bank 0
Thread 1 → Index (1*2)%256 = 2 → Bank 2
Thread 2 → Index (2*2)%256 = 4 → Bank 4
...
Thread 16 → Index (16*2)%256 = 32 → Bank 0 ← CONFLICT with Thread 0
Thread 17 → Index (17*2)%256 = 34 → Bank 2 ← CONFLICT with Thread 1
Thread 18 → Index (18*2)%256 = 36 → Bank 4 ← CONFLICT with Thread 2
...
Conflict pattern: Each bank serves exactly 2 threads, creating systematic 2-way conflicts across all 32 banks.
Mathematical explanation: The stride-2 pattern with modulo 256 creates a repeating access pattern where:
- Threads 0-15 access banks 0,2,4,…,30
- Threads 16-31 access the same banks 0,2,4,…,30
- Each bank collision requires hardware serialization
Why this matters: workload context analysis
Memory-bound vs compute-bound implications
This workload characteristics:
- Global memory dominant: Each thread performs minimal computation relative to memory transfer
- Shared memory secondary: Bank conflicts add overhead but don’t dominate total execution time
- Identical performance: Global memory bandwidth saturation masks shared memory inefficiency
When bank conflicts matter most:
- Compute-intensive shared memory algorithms - Matrix multiplication, stencil computations, FFT
- Tight computational loops - Repeated shared memory access within inner loops
- High arithmetic intensity - Significant computation per memory access
- Large shared memory working sets - Algorithms that heavily utilize shared memory caching
Real-world performance implications
Applications where bank conflicts significantly impact performance:
Matrix Multiplication:
# Problematic: All threads in warp access same column
for k in range(tile_size):
acc += a_shared[local_row, k] * b_shared[k, local_col] # b_shared[k, 0] conflicts
Stencil Computations:
# Problematic: Stride access in boundary handling
shared_buf[thread_idx.x * stride] # Creates systematic conflicts
Parallel Reductions:
# Problematic: Power-of-2 stride patterns
if thread_idx.x < stride:
shared_buf[thread_idx.x] += shared_buf[thread_idx.x + stride] # Conflict potential
Conflict-free design principles
Prevention strategies
1. Sequential access patterns:
shared[thread_idx.x] # Optimal - each thread different bank
2. Broadcast optimization:
constant = shared[0] # All threads read same address - hardware optimized
3. Padding techniques:
shared = stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[TPB + 1]()) # Shift access patterns
4. Access pattern analysis:
- Calculate bank assignments before implementation
- Use modulo arithmetic:
bank_id = (address_bytes / 4) % 32 - Visualize thread-to-bank mappings for complex algorithms
Systematic optimization workflow
Design Phase:
- Plan access patterns - Sketch thread-to-memory mappings
- Calculate bank assignments - Use mathematical analysis
- Predict conflicts - Identify problematic access patterns
- Design alternatives - Consider padding, transpose, or algorithm changes
Implementation Phase:
- Profile systematically - Use NSight Compute conflict metrics
- Measure impact - Compare conflict counts across implementations
- Validate performance - Ensure optimizations improve end-to-end performance
- Document patterns - Record successful conflict-free algorithms for reuse
Key takeaways: from detective work to optimization expertise
The Bank Conflict Investigation revealed:
- Measurement trumps intuition - Profiling tools reveal conflicts invisible to performance timing
- Pattern analysis works - Mathematical prediction accurately matched NSight Compute results
- Context matters - Bank conflicts matter most in compute-intensive shared memory workloads
- Prevention beats fixing - Designing conflict-free patterns easier than retrofitting optimizations
Universal shared memory optimization principles:
When to worry about bank conflicts:
- High-computation kernels using shared memory for data reuse
- Iterative algorithms with repeated shared memory access in tight loops
- Performance-critical code where every cycle matters
- Memory-intensive operations that are compute-bound rather than bandwidth-bound
When bank conflicts are less critical:
- Memory-bound workloads where global memory dominates performance
- Simple caching scenarios with minimal shared memory reuse
- One-time access patterns without repeated conflict-prone operations
Professional development methodology:
- Profile before optimizing - Measure conflicts quantitatively with NSight Compute
- Understand access mathematics - Use bank assignment formulas to predict problems
- Design systematically - Consider banking in algorithm design, not as afterthought
- Validate optimizations - Confirm that conflict reduction improves actual performance
This detective case demonstrates that systematic profiling reveals optimization opportunities invisible to performance timing alone - bank conflicts are a perfect example of where measurement-driven optimization beats guesswork.
Puzzle 33: Tensor Core Operations
Introduction
Welcome to the final frontier of GPU matrix multiplication optimization! In this puzzle, we’ll explore Tensor Cores - specialized hardware units designed to accelerate mixed-precision matrix operations at unprecedented speeds.
Building on everything we’ve learned so far, especially from Puzzle 16’s idiomatic tiled matrix multiplication, we’ll see how modern GPUs provide dedicated silicon to make matrix operations blazingly fast.
What are tensor cores?
Tensor Cores (also known as Matrix Cores on AMD hardware) are specialized processing units that can perform mixed-precision matrix-matrix operations in a single instruction. These units are available on modern GPU architectures:
- NVIDIA: Tensor Cores (Volta, Turing, Ampere, Hopper)
- AMD: Matrix Cores (CDNA/CDNA2/CDNA3 architectures)
Think of them as hardware-accelerated GEMM (General Matrix Multiply) engines built directly into the GPU.
Key characteristics
- Warp-level operations: Each instruction operates on data from an entire warp (32 threads on NVIDIA, 32 or 64 on AMD)
- Fixed tile sizes: Operations work on specific matrix fragment sizes (e.g., 16×8×8 for FP32)
- Mixed precision: Can mix input and output precisions for optimal performance
- Massive throughput: Can achieve 10-100x speedup over regular compute cores for matrix operations
From tiled to tensor cores
Let’s trace our journey from basic matrix multiplication to Tensor Cores:
- Puzzle 16: We learned idiomatic tiled matrix multiplication using shared memory
- Shared memory optimization: We used
copy_dram_to_sram_asyncfor efficient memory transfers - Thread cooperation: We coordinated warps using barriers and async operations
- Now: We’ll use specialized hardware (Tensor Cores) to accelerate the core computation
The tensor core programming model
Tensor Cores expose a different programming paradigm:
Traditional compute core approach
# Each thread computes one element
acc += a_shared[local_row, k] * b_shared[k, local_col]
Tensor core approach
# Entire warp cooperates on matrix fragments
a_reg = mma_op.load_a(A_mma_tile) # Load 16×8 fragment
b_reg = mma_op.load_b(B_mma_tile) # Load 8×8 fragment
c_reg = mma_op.load_c(C_mma_tile) # Load 16×8 accumulator
d_reg = mma_op.mma_op(a_reg, b_reg, c_reg) # D = A×B + C
mma_op.store_d(C_mma_tile, d_reg) # Store result
Tensor core API in Mojo
Mojo provides a clean interface to Tensor Cores through the
TensorCore
type:
from layout.tensor_core import TensorCore
# Create a Tensor Core operator for specific tile sizes
mma_op = TensorCore[A.dtype, C.dtype, Index(MMA_M, MMA_N, MMA_K)]()
# Core operations:
# - load_a(): Load matrix A fragment from shared memory
# - load_b(): Load matrix B fragment from shared memory
# - load_c(): Load matrix C fragment (accumulator)
# - mma_op(): Perform D = A×B + C operation
# - store_d(): Store result fragment to memory
Advanced features: The TensorCore API also supports quantized operations, different swizzle patterns for memory access optimization, and mixed-precision arithmetic. For complete documentation of all supported shapes, data types, and methods, see the official TensorCore API reference.
Matrix fragment sizes
The TensorCore API supports different shapes and data types depending on the GPU hardware:
NVIDIA GPUs:
- float32: 16×8×8 or 16×8×4
- half-precision: 16×8×16
- float8: 16×8×32
AMD GPUs:
- float32: 16×16×4
- half-precision: 16×16×16 or 32×32×8
This puzzle uses FP32 with 16×8×8 fragments:
- MMA_M = 16: Matrix A height (and output height)
- MMA_N = 8: Matrix B width (and output width)
- MMA_K = 8: Inner dimension (A width = B height)
What is MMA? MMA stands for “Mixed-precision Matrix-Multiply-Accumulate” -
the fundamental operation that Tensor Cores perform. Each MMA instruction
computes: D = A × B + C where A, B, C, and D are matrix fragments.
Fragment visualization:
A fragment (16×8) × B fragment (8×8) + C fragment (16×8) = D fragment (16×8)
16 rows 8 rows 16 rows 16 rows
8 cols 8 cols 8 cols 8 cols
| | | |
[A data] × [B data] + [C data] = [D result]
This means each Tensor Core instruction computes a 16×8 output tile by multiplying a 16×8 tile from A with an 8×8 tile from B, then adding it to the existing 16×8 accumulator.
Warp organization for tensor cores
What is a warp? A warp is a group of threads (32 on NVIDIA, 32 or 64 on AMD) that execute instructions together in lockstep. Tensor Cores require all threads in a warp to cooperate on a single matrix operation.
Why warp-level? Unlike regular operations where each thread works independently, Tensor Cores need the entire warp to collectively load matrix fragments, perform the MMA operation, and store results.
Since Tensor Cores operate at warp-level, we need to organize our threads differently:
# Calculate warp coordinates within the block
warp_id = thread_idx.x // WARP_SIZE
warps_in_n = BN // WN # Number of warps along N dimension
warps_in_m = BM // WM # Number of warps along M dimension
warp_y = warp_id // warps_in_n # Warp's row
warp_x = warp_id % warps_in_n # Warp's column
# Each warp handles a WM×WN tile of the output
C_warp_tile = C_block_tile.tile[WM, WN](warp_y, warp_x)
Warp organization example (with BM=128, BN=64, WM=32, WN=32):
Block (128×64) contains 8 warps arranged as:
32 cols 32 cols
| |
[ Warp 0 ][ Warp 1 ] ← 32 rows each
[ Warp 2 ][ Warp 3 ] ← 32 rows each
[ Warp 4 ][ Warp 5 ] ← 32 rows each
[ Warp 6 ][ Warp 7 ] ← 32 rows each
Total: 4×2 = 8 warps, each handling 32×32 output region
Memory hierarchy with tensor cores
Tensor Cores add another layer to our memory optimization:
- Global Memory → Shared Memory: Use
copy_dram_to_sram_async(from Puzzle 16) - Shared Memory → Register Fragments: Use
mma_op.load_a/load_b - Computation: Use
mma_op.mma_opon register fragments - Register Fragments → Global Memory: Use
mma_op.store_d
The challenge
Your task is to complete the tensor_core_matrix_multiplication function. The
skeleton builds on the tiled approach but uses actual Tensor Core hardware
operations.
Key requirements
- Use the actual Tensor Core API: Don’t simulate - use real
mma_op.load_a(),mma_op.mma_op(), etc. - Maintain correctness: Your result must match the CPU reference implementation
- Proper warp coordination: Handle multiple warps per block correctly (works on both NVIDIA and AMD)
- Memory efficiency: Use the same async copy patterns from Puzzle 16
- Cross-platform compatibility: Ensure tiling parameters are multiples of
WARP_SIZE
Configuration
- Matrix size: \(\text{SIZE} = 1024\)
- Block tiling: \(\text{BM} = 128, \text{BN} = 64, \text{BK} = 32\)
- Warp tiling: \(\text{WM} = 32, \text{WN} = 32\) (multiples of
WARP_SIZE) - MMA fragments: \(16 \times 8 \times 8\) for FP32
- Threads per block: \(8 \times \text{WARP_SIZE}\) (8 warps per block)
- Grid dimensions: Covers full matrix with block tiles
Layout configuration:
- Input A:
row_major[SIZE, SIZE]() - Input B:
row_major[SIZE, SIZE]() - Output C:
row_major[SIZE, SIZE]() - Shared Memory: Block-sized tiles with async copy operations
The challenge
In this puzzle, you’ll transform the idiomatic tiled matrix multiplication from Puzzle 16 into a Tensor Core implementation. Let’s break this down step by step:
Step 1: Understanding your tiled baseline
The puzzle provides a complete idiomatic tiled implementation as your reference:
def matmul_idiomatic_tiled[
size: Int
](
output: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
a: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
):
# Use block_dim to get actual tile size dynamically
var tile_size_x = block_dim.x
var tile_size_y = block_dim.y
var local_row = thread_idx.y
var local_col = thread_idx.x
var tiled_row = block_idx.y * tile_size_y + local_row
var tiled_col = block_idx.x * tile_size_x + local_col
# Get the tile of the output matrix that this thread block is responsible for
var out_tile = output.tile[TILE_SIZE, TILE_SIZE](block_idx.y, block_idx.x)
var a_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TILE_SIZE, TILE_SIZE]())
var b_shared = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[TILE_SIZE, TILE_SIZE]())
var acc: output.ElementType = 0
comptime load_a_layout = row_major[1, TILE_SIZE]() # Coalesced loading
comptime load_b_layout = row_major[1, TILE_SIZE]() # Coalesced loading
# Note: Both matrices stored in same orientation for correct matrix multiplication
# Transposed loading would be useful if B were pre-transposed in global memory
for idx in range(size // TILE_SIZE): # Iterate over K tiles
# Get tiles from A and B matrices
var a_tile = a.tile[TILE_SIZE, TILE_SIZE](block_idx.y, idx)
var b_tile = b.tile[TILE_SIZE, TILE_SIZE](idx, block_idx.x)
# Asynchronously copy tiles to shared memory with consistent orientation
copy_dram_to_sram_async[
thread_layout=load_a_layout,
num_threads=TILE_SIZE * TILE_SIZE,
block_dim_count=BLOCK_DIM_COUNT,
](a_shared, a_tile)
copy_dram_to_sram_async[
thread_layout=load_b_layout,
num_threads=TILE_SIZE * TILE_SIZE,
block_dim_count=BLOCK_DIM_COUNT,
](b_shared, b_tile)
async_copy_wait_all()
barrier()
# Compute partial matrix multiplication for this tile
for k in range(TILE_SIZE):
if (
local_row < TILE_SIZE
and local_col < TILE_SIZE
and k < TILE_SIZE
):
acc += a_shared[local_row, k] * b_shared[k, local_col]
barrier()
# Write final result to output tile
if tiled_row < size and tiled_col < size:
out_tile[local_row, local_col] = acc
What this baseline does:
- Correctness: This implementation works perfectly and passes all tests
- Thread cooperation: Uses
copy_dram_to_sram_asyncfor efficient memory transfers - Shared memory: Coordinates threads with barriers and async operations
- Tiled computation: Each thread computes one output element using shared memory tiles
Step 2: Your tensor core mission
Transform the above approach using specialized hardware acceleration:
- From: Thread-level computation → To: Warp-level matrix fragments
- From: Standard FP32 arithmetic → To: Hardware-accelerated GEMM operations
- From: Individual element results → To: 16×8 matrix fragment results
Step 3: Configuration understanding
The tensor core version uses different tiling parameters optimized for hardware:
- Block tiling:
BM=128, BN=64, BK=32(larger blocks for better occupancy) - Warp tiling:
WM=32, WN=32(each warp handles a 32×32 output region) - MMA fragments:
16×8×8(hardware-defined matrix fragment sizes) - Warps per block: 8 warps (organized as 4×2 in the BM×BN block)
Why these specific sizes?
- BM=128, BN=64: Larger than tiled version (32×32) to better utilize Tensor Cores
- WM=WN=32: Multiple of WARP_SIZE and contains 2×4=8 MMA fragments (32÷16=2, 32÷8=4)
- MMA 16×8×8: Fixed by hardware - this is what the Tensor Cores physically compute
- 8 warps: BM÷WM × BN÷WN = 128÷32 × 64÷32 = 4×2 = 8 warps per block
How warps map to MMA fragments:
Each 32×32 warp tile contains multiple 16×8 MMA fragments:
16 cols 16 cols
| |
[ MMA 0,0 ][ MMA 0,1 ] ← 8 rows each (32÷8=4 fragments down)
[ MMA 1,0 ][ MMA 1,1 ] ← 8 rows each
[ MMA 2,0 ][ MMA 2,1 ] ← 8 rows each
[ MMA 3,0 ][ MMA 3,1 ] ← 8 rows each
2 fragments across (32÷16=2) × 4 fragments down (32÷8=4) = 8 MMA operations per warp per K-tile
Step 4: Code to complete
# Block and warp tiling sizes
comptime BM = 4 * WARP_SIZE # Block tile M (4 warps along M)
comptime BN = 2 * WARP_SIZE # Block tile N (2 warps along N)
comptime BK = WARP_SIZE # Block tile K (stay within SMEM limit)
comptime WM = WARP_SIZE # Warp tile M
comptime WN = WARP_SIZE # Warp tile N
# MMA tile sizes for tensor cores
comptime MMA_M = 16
comptime MMA_N = 8
comptime MMA_K = 8
comptime THREADS_PER_BLOCK_TENSOR_CORE = (8 * WARP_SIZE, 1) # 8 warps per block
# grid_dim is (x, y). We want x to sweep N (columns) and y to sweep M (rows)
comptime BLOCKS_PER_GRID_TENSOR_CORE = (
(SIZE + BN - 1) // BN,
(SIZE + BM - 1) // BM,
)
def tensor_core_matrix_multiplication[
dtype: DType,
BM: Int,
BN: Int,
BK: Int,
WM: Int,
WN: Int,
MMA_M: Int,
MMA_N: Int,
MMA_K: Int,
](
A: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
B: TileTensor[mut=False, dtype, LayoutType, ImmutAnyOrigin],
C: TileTensor[mut=True, dtype, LayoutType, MutAnyOrigin],
):
comptime M = C.dim[0]()
comptime N = C.dim[1]()
comptime K = A.dim[1]()
var warp_id = thread_idx.x // WARP_SIZE
var warps_in_n = BN // WN
var warps_in_m = BM // WM
var warp_y = warp_id // warps_in_n
var warp_x = warp_id % warps_in_n
var warp_is_active = warp_y < warps_in_m
var C_block_tile = C.tile[BM, BN](block_idx.y, block_idx.x)
var C_warp_tile = C_block_tile.tile[WM, WN](warp_y, warp_x)
var mma_op = TensorCore[A.dtype, C.dtype, Index(MMA_M, MMA_N, MMA_K)]()
# Shared SRAM tiles (no padding to stay under shared memory limit)
var A_sram_tile = stack_allocation[
dtype=A.dtype, address_space=AddressSpace.SHARED
](row_major[BM, BK]())
var B_sram_tile = stack_allocation[
dtype=B.dtype, address_space=AddressSpace.SHARED
](row_major[BK, BN]())
# One per-warp accumulator tile of shape [WM, WN]
var C_warp_accum = stack_allocation[
dtype=C.dtype, address_space=AddressSpace.GENERIC
](row_major[WM, WN]())
# Zero initialize accumulator (only for active warps)
if warp_is_active:
comptime for i in range(WM):
comptime for j in range(WN):
C_warp_accum[i, j] = 0.0
# Sweep across K in BK chunks (single-buffered)
for k_i in range(K // BK):
barrier()
var A_dram_tile = A.tile[BM, BK](block_idx.y, k_i)
var B_dram_tile = B.tile[BK, BN](k_i, block_idx.x)
copy_dram_to_sram_async[
thread_layout=row_major[4, 8](),
num_threads=256,
block_dim_count=BLOCK_DIM_COUNT,
](A_sram_tile.vectorize[1, 4](), A_dram_tile.vectorize[1, 4]())
copy_dram_to_sram_async[
thread_layout=row_major[4, 8](),
num_threads=256,
block_dim_count=BLOCK_DIM_COUNT,
](B_sram_tile.vectorize[1, 4](), B_dram_tile.vectorize[1, 4]())
async_copy_wait_all()
barrier()
if warp_is_active:
var A_warp_tile = A_sram_tile.tile[WM, BK](warp_y, 0)
var B_warp_tile = B_sram_tile.tile[BK, WN](0, warp_x)
comptime for mma_k in range(BK // MMA_K):
comptime for mma_m in range(WM // MMA_M):
comptime for mma_n in range(WN // MMA_N):
# FILL IN (roughly 8 lines)
...
# Store the final per-warp accumulation to the output warp tile
if warp_is_active:
comptime for mma_m in range(WM // MMA_M):
comptime for mma_n in range(WN // MMA_N):
var C_mma_tile = C_warp_tile.tile[MMA_M, MMA_N](mma_m, mma_n)
var Acc_mma_tile = C_warp_accum.tile[MMA_M, MMA_N](mma_m, mma_n)
var frag = mma_op.load_c(Acc_mma_tile)
mma_op.store_d(C_mma_tile, frag)
View full file: problems/p33/p33.mojo
Your task: Complete the missing section (marked with
# FILL IN (roughly 8 lines)) inside the triple nested loops.
What you need to understand:
- The skeleton handles all memory management, warp organization, and synchronization
- You only need to implement the core Tensor Core computation
- The loops iterate over MMA fragments:
mma_k,mma_m,mma_n - Each iteration processes one 16×8×8 matrix fragment
Understanding the triple nested loops:
@parameter
for mma_k in range(BK // MMA_K): # 32÷8 = 4 iterations (K dimension)
@parameter
for mma_m in range(WM // MMA_M): # 32÷16 = 2 iterations (M dimension)
@parameter
for mma_n in range(WN // MMA_N): # 32÷8 = 4 iterations (N dimension)
# YOUR CODE HERE: Process one 16×8×8 MMA fragment
What each loop does:
mma_k: Iterates through K-slices of the current K-tile (4 slices of 8 elements each)mma_m: Iterates through M-slices of the warp’s output (2 slices of 16 rows each)mma_n: Iterates through N-slices of the warp’s output (4 slices of 8 columns each)- Total: 4×2×4 = 32 MMA operations per warp per K-tile
Tips
Think about the Tensor Core workflow - you need to:
-
Get the right matrix fragments:
- From the warp tiles (
A_warp_tile,B_warp_tile,C_warp_accum), extract the specific MMA-sized fragments - Use the loop indices (
mma_m,mma_k,mma_n) to get the correct tile coordinates - Remember: A needs [MMA_M, MMA_K], B needs [MMA_K, MMA_N], C needs [MMA_M, MMA_N]
- From the warp tiles (
-
Load fragments into Tensor Core registers:
- The
mma_opobject has methods to load each matrix type - Each load method takes a tile and returns register fragments
- Think:
load_a(),load_b(),load_c()- what do they each take?
- The
-
Perform the hardware operation and store:
- Use the MMA operation to compute the result
- Store the result back to the accumulator tile
- The operation follows the pattern: result = A × B + C
Key insight: You’re replacing 128 individual multiply-add operations with a single hardware instruction!
Debugging tip: If you get dimension errors, double-check your tile indexing
- the order of
mma_m,mma_k,mma_nmatters for getting the right fragments.
Running the code
To test your solution, run the following command in your terminal:
pixi run p33 --test
uv run poe p33 --test
Your output will show accuracy test results once completed:
=== Running All Accuracy Tests ===
--- Test 1: Tensor Core vs CPU Reference ---
✅ TENSOR CORE ACCURACY TEST PASSED!
--- Test 2: Idiomatic Tiled vs CPU Reference ---
✅ IDIOMATIC TILED ACCURACY TEST PASSED!
ALL TESTS PASSED!
Solution
def tensor_core_matrix_multiplication[
dtype: DType,
layout_a: Layout,
layout_b: Layout,
layout_c: Layout,
BM: Int,
BN: Int,
BK: Int,
WM: Int,
WN: Int,
MMA_M: Int,
MMA_N: Int,
MMA_K: Int,
](
A: LayoutTensor[dtype, layout_a, ImmutAnyOrigin],
B: LayoutTensor[dtype, layout_b, ImmutAnyOrigin],
C: LayoutTensor[dtype, layout_c, MutAnyOrigin],
):
comptime M = C.shape[0]()
comptime N = C.shape[1]()
comptime K = A.shape[1]()
var warp_id = thread_idx.x // WARP_SIZE
var warps_in_n = BN // WN
var warps_in_m = BM // WM
var warp_y = warp_id // warps_in_n
var warp_x = warp_id % warps_in_n
var warp_is_active = warp_y < warps_in_m
var C_block_tile = C.tile[BM, BN](block_idx.y, block_idx.x)
var C_warp_tile = C_block_tile.tile[WM, WN](warp_y, warp_x)
var mma_op = TensorCore[A.dtype, C.dtype, Index(MMA_M, MMA_N, MMA_K)]()
# Shared SRAM tiles (no padding to stay under shared memory limit)
var A_sram_tile = LayoutTensor[
A.dtype,
Layout.row_major(BM, BK),
MutAnyOrigin,
address_space=AddressSpace.SHARED,
].stack_allocation()
var B_sram_tile = LayoutTensor[
B.dtype,
Layout.row_major(BK, BN),
MutAnyOrigin,
address_space=AddressSpace.SHARED,
].stack_allocation()
# One per-warp accumulator tile of shape [WM, WN]
var C_warp_accum = LayoutTensor[
C.dtype,
Layout.row_major(WM, WN),
MutAnyOrigin,
address_space=AddressSpace.LOCAL,
].stack_allocation()
# Zero initialize accumulator (only for active warps)
if warp_is_active:
comptime for i in range(WM):
comptime for j in range(WN):
C_warp_accum[i, j] = 0.0
# (Removed shared C accumulator to reduce shared usage)
# Sweep across K in BK chunks (single-buffered)
for k_i in range(K // BK):
barrier()
var A_dram_tile = A.tile[BM, BK](block_idx.y, k_i)
var B_dram_tile = B.tile[BK, BN](k_i, block_idx.x)
copy_dram_to_sram_async[
thread_layout=Layout.row_major(4, 8),
num_threads=256,
block_dim_count=BLOCK_DIM_COUNT,
](A_sram_tile.vectorize[1, 4](), A_dram_tile.vectorize[1, 4]())
copy_dram_to_sram_async[
thread_layout=Layout.row_major(4, 8),
num_threads=256,
block_dim_count=BLOCK_DIM_COUNT,
](B_sram_tile.vectorize[1, 4](), B_dram_tile.vectorize[1, 4]())
async_copy_wait_all()
barrier()
if warp_is_active:
var A_warp_tile = A_sram_tile.tile[WM, BK](warp_y, 0)
var B_warp_tile = B_sram_tile.tile[BK, WN](0, warp_x)
comptime for mma_k in range(BK // MMA_K):
comptime for mma_m in range(WM // MMA_M):
comptime for mma_n in range(WN // MMA_N):
var A_mma_tile = A_warp_tile.tile[MMA_M, MMA_K](
mma_m, mma_k
)
var B_mma_tile = B_warp_tile.tile[MMA_K, MMA_N](
mma_k, mma_n
)
C_mma_tile = C_warp_accum.tile[MMA_M, MMA_N](
mma_m, mma_n
)
var a_reg = mma_op.load_a(A_mma_tile)
var b_reg = mma_op.load_b(B_mma_tile)
var c_reg = mma_op.load_c(C_mma_tile)
var d_reg = mma_op.mma_op(a_reg, b_reg, c_reg)
mma_op.store_d(C_mma_tile, d_reg)
# Store the final per-warp accumulation to the output warp tile
if warp_is_active:
comptime for mma_m in range(WM // MMA_M):
comptime for mma_n in range(WN // MMA_N):
var C_mma_tile = C_warp_tile.tile[MMA_M, MMA_N](mma_m, mma_n)
var Acc_mma_tile = C_warp_accum.tile[MMA_M, MMA_N](mma_m, mma_n)
var frag = mma_op.load_c(Acc_mma_tile)
mma_op.store_d(C_mma_tile, frag)
This solution demonstrates the Tensor Core programming model:
-
Warp organization
- Calculates warp coordinates within the block using
warp_id = thread_idx.x // WARP_SIZE - Maps warps to output tiles: each warp handles a
WM×WNregion - Uses
warp_is_activeguards to handle blocks with fewer than expected warps
- Calculates warp coordinates within the block using
-
Memory hierarchy optimization
- Global → Shared: Uses
copy_dram_to_sram_asyncfor efficient block-level transfers - Shared → Registers: Uses
mma_op.load_a/load_bfor warp-level fragment loading - Register computation: Uses
mma_op.mma_opfor hardware-accelerated matrix operations - Registers → Global: Uses
mma_op.store_dfor efficient result storage
- Global → Shared: Uses
-
Tensor Core operations
load_a(A_mma_tile): Loads 16×8 matrix A fragment into registersload_b(B_mma_tile): Loads 8×8 matrix B fragment into registersload_c(C_mma_tile): Loads 16×8 accumulator fragmentmma_op(a_reg, b_reg, c_reg): Computes D = A×B + C using specialized hardwarestore_d(C_mma_tile, d_reg): Stores 16×8 result fragment
-
Cross-platform compatibility
- All tiling parameters are multiples of
WARP_SIZE(32 on NVIDIA, 64 on AMD) - Mojo abstracts hardware differences through the
TensorCoreinterface - Same code works on both NVIDIA Tensor Cores and AMD Matrix Cores
- All tiling parameters are multiples of
The key insight is that Tensor Cores operate on entire matrix fragments at the warp level, rather than individual elements at the thread level. This enables massive parallelism and specialized hardware acceleration.
Performance analysis: Are we done?
Now let’s see if Tensor Cores deliver their promised performance advantage over the idiomatic tiled approach.
Building for profiling
uv run mojo build problems/p33/p33.mojo -o problems/p33/p33_profiler
pixi run mojo build problems/p33/p33.mojo -o problems/p33/p33_profiler
Profiling with NVIDIA Nsight Compute (NVIDIA only)
First, enter the CUDA environment for ncu access:
# Enter CUDA environment
pixi shell -e nvidia
# Profile tensor core version
ncu --set full --metrics sm__cycles_elapsed.avg,smsp__cycles_active.avg.pct_of_peak_sustained_elapsed,dram__throughput.avg.pct_of_peak_sustained_elapsed,smsp__inst_executed_pipe_tensor_op_hmma.sum ./problems/p33p33_profiler --tensor-core
# Profile tiled version for comparison
ncu --set full --metrics sm__cycles_elapsed.avg,smsp__cycles_active.avg.pct_of_peak_sustained_elapsed,dram__throughput.avg.pct_of_peak_sustained_elapsed ./problems/p33p33_profiler --tiled
Key metrics to compare
Performance metrics:
- Duration: Total kernel execution time (lower is better)
- SM Active %: Streaming multiprocessor utilization (higher is better)
- DRAM Throughput: Memory bandwidth utilization (shows if memory-bound)
- Tensor Op Instructions: Number of actual tensor core operations (tensor core only)
What the results typically show:
Tensor Core version (slower):
- Duration: ~13.9 ms (much slower!)
- SM Active: 83.7% (good utilization)
- DRAM Throughput: 72.5% (memory-bound!)
- Occupancy: 26.3% (poor - limited by registers)
- Tensor Op Instructions: 1,048,576 (confirms tensor cores are working)
Tiled version (faster):
- Duration: ~1.62 ms (8.6× faster!)
- SM Active: 98.0% (excellent utilization)
- DRAM Throughput: 1.7% (compute-bound, as expected)
- Occupancy: 66.7% (much better)
- L2 Hit Rate: 96.9% vs 29.7% (much better cache locality)
Why is Tensor Core slower?
- Memory bottleneck: 72% DRAM usage shows it’s memory-bound, not compute-bound
- Poor occupancy: 26% vs 67% - high register usage (68 vs 38 per thread) limits concurrent warps
- Cache misses: 29% L2 hit rate vs 97% shows poor memory locality
- Shared memory conflicts: Bank conflicts from unoptimized access patterns
- Launch configuration: Suboptimal block/warp organization for this problem size
The performance reality
As you can see from the profiling results, the “specialized hardware” isn’t automatically faster! The Tensor Core version is significantly slower (~8.6×) than the simple tiled approach. This is a common reality in GPU optimization - raw hardware capability doesn’t guarantee better performance.
Key insights:
- Memory bottleneck: 72% DRAM usage shows tensor cores are memory-bound, not compute-bound
- Poor occupancy: 26% vs 67% due to high register usage limits concurrent warps
- Cache misses: 29% vs 97% L2 hit rate shows poor memory locality
- Resource waste: Shared memory bank conflicts and suboptimal launch configuration
The lesson: Understanding performance bottlenecks and systematic optimization matter more than using the “latest and greatest” APIs. Hardware features are tools that require careful tuning, not magic bullets.
Next step
Ready for a rewarding GPU optimization challenge? Head to the 🎯 Performance Bonus Challenge to learn how to transform your memory-bound Tensor Core implementation into something that actually beats the simple tiled version!
🎯 Performance Bonus Challenge
The discovery
You’ve just completed Puzzle 33 and implemented
actual Tensor Core matrix multiplication using Mojo’s TensorCore API. The
implementation works correctly, passes all accuracy tests, and uses real
hardware-accelerated matrix operations. But when you profile it against the
simple idiomatic tiled version from Puzzle 16…
The “specialized hardware” is orders of magnitude slower!
What went wrong?
Your profiling with (NVIDIA only) ncu revealed the brutal truth (if you need a
refresher on profiling techniques, see
Puzzle 10’s memory error detection and
Puzzle 30’s GPU profiling):
Tensor Core version (the disappointment):
- Duration: ~13.9 ms
- Memory bound: 72.5% DRAM throughput (should be compute-bound!)
- Poor occupancy: 26.3% (wasted hardware)
- Cache disaster: 29.7% L2 hit rate
- Register pressure: 68 registers per thread
- Shared memory conflicts: Bank conflicts destroying performance
Tiled version (the winner):
- Duration: ~1.62 ms (8.6x faster!)
- Compute bound: 1.7% DRAM throughput (as expected)
- Excellent occupancy: 66.7%
- Cache friendly: 96.9% L2 hit rate
- Efficient: 38 registers per thread
- Clean memory: No significant bank conflicts
The harsh reality
This is a common story in GPU optimization: raw hardware capability ≠ actual performance. Tensor Cores are incredibly powerful, but they’re also incredibly demanding:
- Memory wall: They’re so fast they expose every memory bottleneck
- Resource hungry: High register usage kills occupancy
- Access sensitive: Poor memory patterns destroy cache behavior
- Configuration critical: Launch parameters must be perfectly tuned
Your mission: Fix the tensor core performance
The challenge: Transform your memory-bound, low-occupancy Tensor Core implementation into something that actually beats the simple tiled version.
What you need to beat:
- Target duration: < 1.62 ms
- Occupancy: > 26.3% baseline
- DRAM pressure: < 72.5% baseline
- Cache performance: > 29.7% L2 hit rate baseline
Optimization strategies to explore:
-
Register pressure reduction
- Use smaller accumulator tiles
- Minimize intermediate storage
- Consider mixed-precision to reduce register footprint
- Review Puzzle 16’s tiled approach for efficient accumulation patterns
-
Memory pattern optimization
- Add shared memory padding to eliminate bank conflicts (see shared memory concepts)
- Optimize
copy_dram_to_sram_asynclayouts - Improve coalescing patterns (memory access fundamentals from early puzzles)
-
Occupancy improvements
- Tune block sizes for better warp utilization
- Balance shared memory vs register usage
- Optimize warp-to-SM mapping
- Apply thread coordination lessons from Puzzle 11-20 series
-
Cache optimization
- Improve data reuse patterns
- Optimize tile sizes for cache hierarchy
- Consider data layout transformations
- Build on memory hierarchy concepts from puzzle progression
-
Advanced techniques
- Implement double buffering to overlap memory and compute
- Use software pipelining
- Explore async execution patterns
- Apply advanced coordination from sanitization puzzles
Success criteria
- Correctness: All accuracy tests still pass
- Performance: Tensor Core duration < 1.62 ms
- Efficiency: Higher occupancy (>26.3%)
- Memory: Lower DRAM pressure (<72.5%)
- Cache: Better hit rates (>29.7% L2)
The deeper lesson
This bonus challenge teaches the most important lesson in GPU optimization: understanding bottlenecks matters more than using the latest APIs.
The goal isn’t just to make Tensor Cores faster - it’s to understand why they can be slower, how to systematically diagnose performance problems, and how to apply principled optimization techniques.
Complete this challenge, and you’ll have the skills to optimize any GPU workload, regardless of the hardware features available.
Puzzle 34: GPU Cluster Programming (SM90+)
Introduction
Hardware requirement: ⚠️ NVIDIA SM90+ Only
This puzzle requires NVIDIA Hopper architecture (H100, H200) or newer GPUs with SM90+ compute capability. The cluster programming APIs are hardware-accelerated and will raise errors on unsupported hardware. If you’re unsure about the underlying architecture, run
pixi run gpu-specsand must have at leastCompute Cap: 9.0(see GPU profiling basics for hardware identification)
Building on your journey from warp-level programming (Puzzles 24-26) through block-level programming (Puzzle 27), you’ll now learn cluster-level programming - coordinating multiple thread blocks to solve problems that exceed single-block capabilities.
What are thread block clusters?
Thread Block Clusters are a revolutionary SM90+ feature that enable multiple thread blocks to cooperate on a single computational task with hardware-accelerated synchronization and communication primitives.
Key capabilities:
- Inter-block synchronization: Coordinate multiple blocks with
cluster_sync,cluster_arrive,cluster_wait - Block identification: Use
block_rank_in_clusterfor unique block coordination - Efficient coordination:
elect_one_syncfor optimized warp-level cooperation - Advanced patterns:
cluster_mask_basefor selective block coordination
The cluster programming model
Traditional GPU programming hierarchy
Grid (Multiple Blocks)
├── Block (Multiple Warps) - barrier() synchronization
├── Warp (32 Threads) - SIMT lockstep execution
│ ├── Lane 0 ─┐
│ ├── Lane 1 │ All execute same instruction
│ ├── Lane 2 │ at same time (SIMT)
│ │ ... │ warp.sum(), warp.broadcast()
│ └── Lane 31 ─┘
└── Thread (SIMD operations within each thread)
New: Cluster programming hierarchy:
Grid (Multiple Clusters)
├── 🆕 Cluster (Multiple Blocks) - cluster_sync(), cluster_arrive()
├── Block (Multiple Warps) - barrier() synchronization
├── Warp (32 Threads) - SIMT lockstep execution
│ ├── Lane 0 ─┐
│ ├── Lane 1 │ All execute same instruction
│ ├── Lane 2 │ at same time (SIMT)
│ │ ... │ warp.sum(), warp.broadcast()
│ └── Lane 31 ─┘
└── Thread (SIMD operations within each thread)
Execution Model Details:
- Thread Level: SIMD operations within individual threads
- Warp Level: SIMT execution - 32 threads in lockstep coordination
- Block Level: Multi-warp coordination with shared memory and barriers
- 🆕 Cluster Level: Multi-block coordination with SM90+ cluster APIs
Learning progression
This puzzle follows a carefully designed 3-part progression that builds your cluster programming expertise:
🔰 Multi-Block Coordination Basics
Focus: Understanding fundamental cluster synchronization patterns
Learn how multiple thread blocks coordinate their execution using
cluster_arrive()
and
cluster_wait()
for basic inter-block communication and data distribution.
Key APIs:
block_rank_in_cluster(),
cluster_arrive(),
cluster_wait()
📊 Cluster-Wide Collective Operations
Focus: Extending block-level patterns to cluster scale
Learn cluster-wide reductions and collective operations that extend familiar
block.sum() concepts to coordinate across multiple thread blocks for
large-scale computations.
Key APIs:
cluster_sync(),
elect_one_sync()
for efficient cluster coordination
🚀 Advanced Cluster Algorithms
Focus: Production-ready multi-level coordination patterns
Implement sophisticated algorithms combining warp-level, block-level, and cluster-level coordination for maximum GPU utilization and complex computational workflows.
Key APIs:
elect_one_sync(),
cluster_arrive(),
advanced coordination patterns
Why cluster programming matters
Problem Scale: Modern AI and scientific workloads often require computations that exceed single thread block capabilities:
- Large matrix operations requiring inter-block coordination (like matrix multiplication from Puzzle 16)
- Multi-stage algorithms with producer-consumer dependencies from Puzzle 29
- Global statistics across datasets larger than shared memory from Puzzle 8
- Advanced stencil computations requiring neighbor block communication
Hardware Evolution: As GPUs gain more compute units (see GPU architecture profiling in Puzzle 30), cluster programming becomes essential for utilizing next-generation hardware efficiently.
Educational value
By completing this puzzle, you’ll have learned the complete GPU programming hierarchy:
- Thread-level: Individual computation units with SIMD operations
- Warp-level: 32-thread SIMT coordination (Puzzles 24-26)
- Block-level: Multi-warp coordination with shared memory (Puzzle 27)
- 🆕 Cluster-level: Multi-block coordination (Puzzle 34)
- Grid-level: Independent block execution across multiple streaming multiprocessors
This progression prepares you for next-generation GPU programming and large-scale parallel computing challenges, building on the performance optimization techniques from Puzzles 30-32.
Getting started
Prerequisites:
- Complete understanding of block-level programming (Puzzle 27)
- Experience with warp-level programming (Puzzles 24-26)
- Familiarity with GPU memory hierarchy from shared memory concepts (Puzzle 8)
- Understanding of GPU synchronization from barriers (Puzzle 29)
- Access to NVIDIA SM90+ hardware or compatible environment
Recommended approach: Follow the 3-part progression sequentially, as each part builds essential concepts for the next level of complexity.
Hardware note: If running on non-SM90+ hardware, the puzzles serve as educational examples of cluster programming concepts and API usage patterns.
Ready to learn the future of GPU programming? Start with Multi-Block Coordination Basics to learn fundamental cluster synchronization patterns!
Multi-Block Coordination Basics
Overview
Welcome to your first cluster programming challenge! This section introduces the fundamental building blocks of inter-block coordination using SM90+ cluster APIs.
The Challenge: Implement a multi-block histogram algorithm where 4 thread blocks coordinate to process different ranges of data and store results in a shared output array.
Key Learning: Learn the essential cluster synchronization pattern:
cluster_arrive()
→ process →
cluster_wait(),
extending the synchronization concepts from
barrier() in Puzzle 29.
The problem: multi-block histogram binning
Traditional single-block algorithms like those in Puzzle 27 can only process data that fits within one block’s thread capacity (e.g., 256 threads). For larger datasets exceeding shared memory capacity from Puzzle 8, we need multiple blocks to cooperate.
Your task: Implement a histogram where each of 4 blocks processes a different data range, scales values by its unique block rank, and coordinates with other blocks using synchronization patterns from Puzzle 29 to ensure all processing completes before any block reads the final results.
Problem specification
Multi-Block Data Distribution:
- Block 0: Processes elements 0-255, scales by 1
- Block 1: Processes elements 256-511, scales by 2
- Block 2: Processes elements 512-767, scales by 3
- Block 3: Processes elements 768-1023, scales by 4
Coordination Requirements:
- Each block must signal completion using
cluster_arrive() - All blocks must wait for others using
cluster_wait() - Final output shows each block’s processed sum in a 4-element array
Configuration
- Problem Size:
SIZE = 1024elements (1D array) - Block Configuration:
TPB = 256threads per block(256, 1) - Grid Configuration:
CLUSTER_SIZE = 4blocks per cluster(4, 1) - Data Type:
DType.float32 - Memory Layout: Input
row_major[SIZE](), Outputrow_major[CLUSTER_SIZE]()
Thread Block Distribution:
- Block 0: threads 0-255 → elements 0-255
- Block 1: threads 0-255 → elements 256-511
- Block 2: threads 0-255 → elements 512-767
- Block 3: threads 0-255 → elements 768-1023
Code to complete
def cluster_coordination_basics[
tpb: Int
](
output: TileTensor[mut=True, dtype, ClusterLayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, InLayoutType, ImmutAnyOrigin],
size: Int,
):
"""Real cluster coordination using SM90+ cluster APIs."""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Check what's happening with cluster ranks
var my_block_rank = Int(block_rank_in_cluster())
var block_id = block_idx.x
var shared_data = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[tpb]())
# FIX: Use block_idx.x for data distribution instead of cluster rank
# Each block should process different portions of the data
var data_scale = Scalar[dtype](
block_id + 1
) # Use block_idx instead of cluster rank
# Phase 1: Each block processes its portion
if global_i < size:
shared_data[local_i] = input[global_i] * data_scale
else:
shared_data[local_i] = 0.0
barrier()
# Phase 2: Use cluster_arrive() for inter-block coordination
# Signal this block has completed processing
# FILL IN 1 line here
# Block-level aggregation (only thread 0)
if local_i == 0:
# FILL IN 4 line here
...
# Wait for all blocks in cluster to complete
# FILL IN 1 line here
View full file: problems/p34/p34.mojo
Tips
Block identification patterns
- Use
block_rank_in_cluster()to get the cluster rank (0-3) - Use
Int(block_idx.x)for reliable block indexing in grid launch - Scale data processing by block position for distinct results
Shared memory coordination
- Allocate shared memory using
stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[tpb]())(see shared memory basics from Puzzle 8) - Process input data scaled by
block_id + 1to create distinct scaling per block - Use bounds checking when accessing input data (pattern from guards in Puzzle 3)
Cluster synchronization pattern
- Process: Each block works on its portion of data
- Signal:
cluster_arrive()announces processing completion - Compute: Block-local operations (reduction, aggregation)
- Wait:
cluster_wait()ensures all blocks complete before proceeding
Thread coordination within blocks
- Use
barrier()for intra-block synchronization before cluster operations (from barrier concepts in Puzzle 29) - Only thread 0 should write the final block result (single-writer pattern from block programming)
- Store results at
output[block_id]for reliable indexing
Running the code
pixi run p34 --coordination
uv run poe p34 --coordination
Expected Output:
Testing Multi-Block Coordination
SIZE: 1024 TPB: 256 CLUSTER_SIZE: 4
Block coordination results:
Block 0 : 127.5
Block 1 : 255.0
Block 2 : 382.5
Block 3 : 510.0
✅ Multi-block coordination tests passed!
Success Criteria:
- All 4 blocks produce non-zero results
- Results show scaling pattern: Block 1 > Block 0, Block 2 > Block 1, etc.
- No race conditions or coordination failures
Solution
Click to reveal solution
def cluster_coordination_basics[
tpb: Int
](
output: TileTensor[mut=True, dtype, ClusterLayout, MutAnyOrigin],
input: TileTensor[mut=False, dtype, InLayout, MutAnyOrigin],
size: Int,
):
"""Real cluster coordination using SM90+ cluster APIs."""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# Check what's happening with cluster ranks
var my_block_rank = Int(block_rank_in_cluster())
var block_id = block_idx.x
var shared_data = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[tpb]())
# FIX: Use block_idx.x for data distribution instead of cluster rank
# Each block should process different portions of the data
var data_scale = Scalar[dtype](
block_id + 1
) # Use block_idx instead of cluster rank
# Phase 1: Each block processes its portion
if global_i < size:
shared_data[local_i] = input[global_i] * data_scale
else:
shared_data[local_i] = 0.0
barrier()
# Phase 2: Use cluster_arrive() for inter-block coordination
cluster_arrive() # Signal this block has completed processing
# Block-level aggregation (only thread 0)
if local_i == 0:
var block_sum: Float32 = 0.0
for i in range(tpb):
block_sum += shared_data[i][0]
# FIX: Store result at block_idx position (guaranteed unique per block)
output[block_id] = block_sum
# Wait for all blocks in cluster to complete
cluster_wait()
The cluster coordination solution demonstrates the fundamental multi-block synchronization pattern using a carefully orchestrated two-phase approach:
Phase 1: Independent block processing
Thread and block identification:
global_i = block_dim.x * block_idx.x + thread_idx.x # Global thread index
local_i = thread_idx.x # Local thread index within block
my_block_rank = Int(block_rank_in_cluster()) # Cluster rank (0-3)
block_id = Int(block_idx.x) # Block index for reliable addressing
Shared memory allocation and data processing:
- Each block allocates its own shared memory workspace:
stack_allocation[dtype=dtype, address_space=AddressSpace.SHARED](row_major[tpb]()) - Scaling strategy:
data_scale = Float32(block_id + 1)ensures each block processes data differently- Block 0: multiplies by 1.0, Block 1: by 2.0, Block 2: by 3.0, Block 3: by 4.0
- Bounds checking:
if global_i < size:prevents out-of-bounds memory access - Data processing:
shared_data[local_i] = input[global_i] * data_scalescales input data per block
Intra-block synchronization:
barrier()ensures all threads within each block complete data loading before proceeding- This prevents race conditions between data loading and subsequent cluster coordination
Phase 2: Cluster coordination
Inter-block signaling:
cluster_arrive()signals that this block has completed its local processing phase- This is a non-blocking operation that registers completion with the cluster hardware
Local aggregation (Thread 0 only):
if local_i == 0:
var block_sum: Float32 = 0.0
for i in range(tpb):
block_sum += shared_data[i][0] # Sum all elements in shared memory
output[block_id] = block_sum # Store result at unique block position
- Only thread 0 performs the sum to avoid race conditions
- Results stored at
output[block_id]ensures each block writes to unique location
Final synchronization:
cluster_wait()blocks until ALL blocks in the cluster have completed their work- This ensures deterministic completion order across the entire cluster
Key technical insights
Why use block_id instead of my_block_rank?
block_idx.xprovides reliable grid-launch indexing (0, 1, 2, 3)block_rank_in_cluster()may behave differently depending on cluster configuration- Using
block_idguarantees each block gets unique data portions and output positions
Memory access pattern:
- Global memory: Each thread reads
input[global_i]exactly once - Shared memory: Used for intra-block communication and aggregation
- Output memory: Each block writes to
output[block_id]exactly once
Synchronization hierarchy:
barrier(): Synchronizes threads within each block (intra-block)cluster_arrive(): Signals completion to other blocks (inter-block, non-blocking)cluster_wait(): Waits for all blocks to complete (inter-block, blocking)
Performance characteristics:
- Compute complexity: O(TPB) per block for local sum, O(1) for cluster coordination
- Memory bandwidth: Each input element read once, minimal inter-block communication
- Scalability: Pattern scales to larger cluster sizes with minimal overhead
Understanding the pattern
The essential cluster coordination pattern follows a simple but powerful structure:
- Phase 1: Each block processes its assigned data portion independently
- Signal:
cluster_arrive()announces completion of processing - Phase 2: Blocks can safely perform operations that depend on other blocks’ results
- Synchronize:
cluster_wait()ensures all blocks finish before proceeding
Next step: Ready for more advanced coordination? Continue to
Cluster-Wide Collective Operations to learn
how to extend block.sum() patterns from Puzzle 27
to cluster scale, building on
warp-level reductions from Puzzle 24!
☸️ Cluster-Wide Collective Operations
Overview
Building on basic cluster coordination from the previous section, this challenge
teaches you to implement cluster-wide collective operations - extending the
familiar
block.sum
pattern from Puzzle 27 to coordinate across
multiple thread blocks.
The Challenge: Implement a cluster-wide reduction that processes 1024 elements across 4 coordinated blocks, combining their individual reductions into a single global result.
Key Learning: Learn
cluster_sync()
for full cluster coordination and
elect_one_sync()
for efficient final reductions.
The problem: large-scale global sum
Single blocks (as learned in Puzzle 27) are limited by their thread count and shared memory capacity from Puzzle 8. For large datasets requiring global statistics (mean, variance, sum) beyond single-block reductions, we need cluster-wide collective operations.
Your task: Implement a cluster-wide sum reduction where:
- Each block performs local reduction (like
block.sum()from Puzzle 27) - Blocks coordinate to combine their partial results using synchronization from Puzzle 29
- One elected thread computes the final global sum using warp election patterns
Problem specification
Algorithmic Flow:
Phase 1 - Local Reduction (within each block): \[R_i = \sum_{j=0}^{TPB-1} input[i \times TPB + j] \quad \text{for block } i\]
Phase 2 - Global Aggregation (across cluster): \[\text{Global Sum} = \sum_{i=0}^{\text{CLUSTER_SIZE}-1} R_i\]
Coordination Requirements:
- Local reduction: Each block computes partial sum using tree reduction
- Cluster sync:
cluster_sync()ensures all partial results are ready - Final aggregation: One elected thread combines all partial results
Configuration
- Problem Size:
SIZE = 1024elements - Block Configuration:
TPB = 256threads per block(256, 1) - Grid Configuration:
CLUSTER_SIZE = 4blocks per cluster(4, 1) - Data Type:
DType.float32 - Memory Layout: Input
row_major[SIZE](), Outputrow_major[1]() - Temporary Storage:
row_major[CLUSTER_SIZE]()for partial results
Expected Result: Sum of sequence 0, 0.01, 0.02, ..., 10.23 = 523,776
Code to complete
def cluster_collective_operations[
tpb: Int
](
output: TileTensor[mut=True, dtype, OutLayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, InLayoutType, ImmutAnyOrigin],
temp_storage: TileTensor[mut=True, dtype, ClusterLayoutType, MutAnyOrigin],
size: Int,
):
"""Cluster-wide collective operations using real cluster APIs."""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# FILL IN (roughly 24 lines)
View full file: problems/p34/p34.mojo
Tips
Local reduction pattern
- Use tree reduction pattern from Puzzle 27’s block sum
- Start with stride =
tpb // 2and halve each iteration (classic reduction from Puzzle 12) - Only threads with
local_i < strideparticipate in each step - Use
barrier()between reduction steps (from barrier concepts in Puzzle 29)
Cluster coordination strategy
- Store partial results in
temp_storage[block_id]for reliable indexing - Use
cluster_sync()for full cluster synchronization (stronger than arrive/wait) - Only one thread should perform the final global aggregation
Election pattern for efficiency
- Use
elect_one_sync()within the first block (my_block_rank == 0) (pattern from warp programming) - This ensures only one thread performs the final sum to avoid redundancy
- The elected thread reads all partial results from
temp_storage(similar to shared memory access from Puzzle 8)
Memory access patterns
- Each thread reads
input[global_i]with bounds checking (from guards in Puzzle 3) - Store intermediate results in shared memory for intra-block reduction
- Store partial results in
temp_storage[block_id]for inter-block communication - Final result goes to
output[0](single-writer pattern from block coordination)
Cluster APIs reference
From
gpu.primitives.cluster
module:
cluster_sync(): Full cluster synchronization - stronger than arrive/wait patternelect_one_sync(): Elects single thread within warp for efficient coordinationblock_rank_in_cluster(): Returns unique block identifier within cluster
Tree reduction pattern
Recall the tree reduction pattern from Puzzle 27’s traditional dot product:
Stride 128: [T0] += [T128], [T1] += [T129], [T2] += [T130], ...
Stride 64: [T0] += [T64], [T1] += [T65], [T2] += [T66], ...
Stride 32: [T0] += [T32], [T1] += [T33], [T2] += [T34], ...
Stride 16: [T0] += [T16], [T1] += [T17], [T2] += [T18], ...
...
Stride 1: [T0] += [T1] → Final result at T0
Now extend this pattern to cluster scale where each block produces one partial result, then combine across blocks.
Running the code
pixi run p34 --reduction
uv run poe p34 --reduction
Expected Output:
Testing Cluster-Wide Reduction
SIZE: 1024 TPB: 256 CLUSTER_SIZE: 4
Expected sum: 523776.0
Cluster reduction result: 523776.0
Expected: 523776.0
Error: 0.0
✅ Passed: Cluster reduction accuracy test
✅ Cluster-wide collective operations tests passed!
Success Criteria:
- Perfect accuracy: Result exactly matches expected sum (523,776)
- Cluster coordination: All 4 blocks contribute their partial sums
- Efficient final reduction: Single elected thread computes final result
Solution
Click to reveal solution
def cluster_collective_operations[
tpb: Int
](
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
input: TileTensor[mut=False, dtype, InLayout, MutAnyOrigin],
temp_storage: TileTensor[mut=True, dtype, ClusterLayout, MutAnyOrigin],
size: Int,
):
"""Cluster-wide collective operations using real cluster APIs."""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
var my_block_rank = Int(block_rank_in_cluster())
var block_id = block_idx.x
# Each thread accumulates its data
var my_value: Float32 = 0.0
if global_i < size:
my_value = input[global_i][0]
# Block-level reduction using shared memory
var shared_mem = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[tpb]())
shared_mem[local_i] = my_value
barrier()
# Tree reduction within block
var stride = tpb // 2
while stride > 0:
if local_i < stride and local_i + stride < tpb:
shared_mem[local_i] += shared_mem[local_i + stride]
barrier()
stride = stride // 2
# FIX: Store block result using block_idx for reliable indexing
if local_i == 0:
temp_storage[block_id] = shared_mem[0]
# Use cluster_sync() for full cluster synchronization
cluster_sync()
# Final cluster reduction (elect one thread to do the final work)
if elect_one_sync() and my_block_rank == 0:
var total: Float32 = 0.0
for i in range(CLUSTER_SIZE):
total += temp_storage[i][0]
output[0] = total
The cluster collective operations solution demonstrates the classic distributed computing pattern: local reduction → global coordination → final aggregation:
Phase 1: Local block reduction (traditional tree reduction)
Data loading and initialization:
var my_value: Float32 = 0.0
if global_i < size:
my_value = input[global_i][0] # Load with bounds checking
shared_mem[local_i] = my_value # Store in shared memory
barrier() # Ensure all threads complete loading
Tree reduction algorithm:
var stride = tpb // 2 # Start with half the threads (128)
while stride > 0:
if local_i < stride and local_i + stride < tpb:
shared_mem[local_i] += shared_mem[local_i + stride]
barrier() # Synchronize after each reduction step
stride = stride // 2
Tree reduction visualization (TPB=256):
Step 1: stride=128 [T0]+=T128, [T1]+=T129, ..., [T127]+=T255
Step 2: stride=64 [T0]+=T64, [T1]+=T65, ..., [T63]+=T127
Step 3: stride=32 [T0]+=T32, [T1]+=T33, ..., [T31]+=T63
Step 4: stride=16 [T0]+=T16, [T1]+=T17, ..., [T15]+=T31
Step 5: stride=8 [T0]+=T8, [T1]+=T9, ..., [T7]+=T15
Step 6: stride=4 [T0]+=T4, [T1]+=T5, [T2]+=T6, [T3]+=T7
Step 7: stride=2 [T0]+=T2, [T1]+=T3
Step 8: stride=1 [T0]+=T1 → Final result at shared_mem[0]
Partial result storage:
- Only thread 0 writes:
temp_storage[block_id] = shared_mem[0] - Each block stores its sum at
temp_storage[0],temp_storage[1],temp_storage[2],temp_storage[3]
Phase 2: Cluster synchronization
Full cluster barrier:
cluster_sync()provides stronger guarantees thancluster_arrive()/cluster_wait()- Ensures all blocks complete their local reductions before any block proceeds
- Hardware-accelerated synchronization across all blocks in the cluster
Phase 3: Final global aggregation
Thread election for efficiency:
if elect_one_sync() and my_block_rank == 0:
var total: Float32 = 0.0
for i in range(CLUSTER_SIZE):
total += temp_storage[i][0] # Sum: temp[0] + temp[1] + temp[2] + temp[3]
output[0] = total
Why this election strategy?
elect_one_sync(): Hardware primitive that selects exactly one thread per warpmy_block_rank == 0: Only elect from the first block to ensure single writer- Result: Only ONE thread across the entire cluster performs the final summation
- Efficiency: Avoids redundant computation across all 1024 threads
Key technical insights
Three-level reduction hierarchy:
- Thread → Warp: Individual threads contribute to warp-level partial sums
- Warp → Block: Tree reduction combines warps into single block result (256 → 1)
- Block → Cluster: Simple loop combines block results into final sum (4 → 1)
Memory access patterns:
- Input: Each element read exactly once (
input[global_i]) - Shared memory: High-speed workspace for intra-block tree reduction
- Temp storage: Low-overhead inter-block communication (only 4 values)
- Output: Single global result written once
Synchronization guarantees:
barrier(): Ensures all threads in block complete each tree reduction stepcluster_sync(): Global barrier - all blocks reach same execution point- Single writer: Election prevents race conditions on final output
Algorithm complexity analysis:
- Tree reduction: O(log₂ TPB) = O(log₂ 256) = 8 steps per block
- Cluster coordination: O(1) synchronization overhead
- Final aggregation: O(CLUSTER_SIZE) = O(4) simple additions
- Total: Logarithmic within blocks, linear across blocks
Scalability characteristics:
- Block level: Scales to thousands of threads with logarithmic complexity
- Cluster level: Scales to dozens of blocks with linear complexity
- Memory: Temp storage requirements scale linearly with cluster size
- Communication: Minimal inter-block data movement (one value per block)
Understanding the collective pattern
This puzzle demonstrates the classic two-phase reduction pattern used in distributed computing:
- Local aggregation: Each processing unit (block) reduces its data portion
- Global coordination: Processing units synchronize and exchange results
- Final reduction: One elected unit combines all partial results
Comparison to single-block approaches:
- Traditional
block.sum(): Works within 256 threads maximum - Cluster collective: Scales to 1000+ threads across multiple blocks
- Same accuracy: Both produce identical mathematical results
- Different scale: Cluster approach handles larger datasets
Performance benefits:
- Larger datasets: Process arrays that exceed single-block capacity
- Better utilization: Use more GPU compute units simultaneously
- Scalable patterns: Foundation for complex multi-stage algorithms
Next step: Ready for the ultimate challenge? Continue to Advanced Cluster Algorithms to learn hierarchical warp programming+block coordination+cluster synchronization, building on performance optimization techniques!
🧠 Advanced Cluster Algorithms
Overview
This final challenge combines all levels of GPU programming hierarchy from warp-level (Puzzles 24-26), block-level (Puzzle 27), and cluster coordination - to implement a sophisticated multi-level algorithm that maximizes GPU utilization.
The Challenge: Implement a hierarchical cluster algorithm using
warp-level optimization (elect_one_sync()), block-level aggregation,
and cluster-level coordination in a single unified pattern.
Key Learning: Learn the complete GPU programming stack with production-ready coordination patterns used in advanced computational workloads.
The problem: multi-level data processing pipeline
Real-world GPU algorithms often require hierarchical coordination where different levels of the GPU hierarchy (warps from Puzzle 24, blocks from Puzzle 27, clusters) perform specialized roles in a coordinated computation pipeline, extending multi-stage processing from Puzzle 29.
Your task: Implement a multi-stage algorithm where:
- Warp-level: Use
elect_one_sync()for efficient intra-warp coordination (from SIMT execution) - Block-level: Aggregate warp results using shared memory coordination
- Cluster-level: Coordinate between blocks using
cluster_arrive()/cluster_wait()staged synchronization from Puzzle 29
Algorithm specification
Multi-Stage Processing Pipeline:
- Stage 1 (Warp-level): Each warp elects one thread to sum 32 consecutive elements
- Stage 2 (Block-level): Aggregate all warp sums within each block
- Stage 3 (Cluster-level): Coordinate between blocks with
cluster_arrive()/cluster_wait()
Input: 1024 float values with pattern (i % 50) * 0.02 for testing
Output: 4 block results showing hierarchical processing effects
Configuration
- Problem Size:
SIZE = 1024elements - Block Configuration:
TPB = 256threads per block(256, 1) - Grid Configuration:
CLUSTER_SIZE = 4blocks(4, 1) - Warp Size:
WARP_SIZE = 32threads per warp (NVIDIA standard) - Warps per Block:
TPB / WARP_SIZE = 8warps - Data Type:
DType.float32 - Memory Layout: Input
row_major[SIZE](), Outputrow_major[CLUSTER_SIZE]()
Processing Distribution:
- Block 0: 256 threads → 8 warps → elements 0-255
- Block 1: 256 threads → 8 warps → elements 256-511
- Block 2: 256 threads → 8 warps → elements 512-767
- Block 3: 256 threads → 8 warps → elements 768-1023
Code to complete
def advanced_cluster_patterns[
tpb: Int
](
output: TileTensor[mut=True, dtype, ClusterLayoutType, MutAnyOrigin],
input: TileTensor[mut=False, dtype, InLayoutType, ImmutAnyOrigin],
size: Int,
):
"""Advanced cluster programming using cluster masks and relaxed synchronization.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
# FILL IN (roughly 26 lines)
View full file: problems/p34/p34.mojo
Tips
Warp-level optimization patterns
- Use
elect_one_sync()to select one thread per warp for computation (from warp programming basics) - The elected thread should process 32 consecutive elements (leveraging SIMT execution)
- Compute warp start with
(local_i // 32) * 32to find warp boundaries (lane indexing from warp concepts) - Store warp results back in shared memory at elected thread’s position
Block-level aggregation strategy
- After warp processing, aggregate across all warp results (extending block coordination from Puzzle 27)
- Read from elected positions: indices 0, 32, 64, 96, 128, 160, 192, 224
- Use loop
for i in range(0, tpb, 32)to iterate through warp leaders (pattern from reduction algorithms) - Only thread 0 should compute the final block total (single-writer pattern from barrier coordination)
Cluster coordination flow
- Process: Each block processes its data with hierarchical warp optimization
- Signal:
cluster_arrive()indicates completion of local processing - Store: Thread 0 writes the block result to output
- Wait:
cluster_wait()ensures all blocks complete before termination
Data scaling and bounds checking
- Scale input by
Float32(block_id + 1)to create distinct block patterns - Always check
global_i < sizebefore reading input (from guards in Puzzle 3) - Use
barrier()between processing phases within blocks (from synchronization patterns) - Handle warp boundary conditions carefully in loops (considerations from warp programming)
Advanced cluster APIs
From
gpu.primitives.cluster
module:
elect_one_sync(): Warp-level thread election for efficient computationcluster_arrive(): Signal completion for staged cluster coordinationcluster_wait(): Wait for all blocks to reach synchronization pointblock_rank_in_cluster(): Get unique block identifier within cluster
Hierarchical coordination pattern
This puzzle demonstrates three-level coordination hierarchy:
Level 1: Warp Coordination (Puzzle 24)
Warp (32 threads) → elect_one_sync() → 1 elected thread → processes 32 elements
Level 2: Block Coordination (Puzzle 27)
Block (8 warps) → aggregate warp results → 1 block total
Level 3: Cluster Coordination (This puzzle)
Cluster (4 blocks) → cluster_arrive/wait → synchronized completion
Combined Effect: 1024 threads → 32 warp leaders → 4 block results → coordinated cluster completion
Running the code
pixi run p34 --advanced
uv run poe p34 --advanced
Expected Output:
Testing Advanced Cluster Algorithms
SIZE: 1024 TPB: 256 CLUSTER_SIZE: 4
Advanced cluster algorithm results:
Block 0 : 122.799995
Block 1 : 247.04001
Block 2 : 372.72
Block 3 : 499.83997
✅ Advanced cluster patterns tests passed!
Success Criteria:
- Hierarchical scaling: Results show multi-level coordination effects
- Warp optimization:
elect_one_sync()reduces redundant computation - Cluster coordination: All blocks complete processing successfully
- Performance pattern: Higher block IDs produce proportionally larger results
Solution
Click to reveal solution
def advanced_cluster_patterns[
tpb: Int
](
output: TileTensor[mut=True, dtype, ClusterLayout, MutAnyOrigin],
input: TileTensor[mut=False, dtype, InLayout, MutAnyOrigin],
size: Int,
):
"""Advanced cluster programming using cluster masks and relaxed synchronization.
"""
var global_i = block_dim.x * block_idx.x + thread_idx.x
var local_i = thread_idx.x
var my_block_rank = Int(block_rank_in_cluster())
var block_id = block_idx.x
var shared_data = stack_allocation[
dtype=dtype, address_space=AddressSpace.SHARED
](row_major[tpb]())
# Compute cluster mask for advanced coordination
# base_mask = cluster_mask_base() # Requires cluster_shape parameter
# FIX: Process data with block_idx-based scaling for guaranteed uniqueness
var data_scale = Scalar[dtype](block_id + 1)
if global_i < size:
shared_data[local_i] = input[global_i] * data_scale
else:
shared_data[local_i] = 0.0
barrier()
# Advanced pattern: Use elect_one_sync for efficient coordination
if elect_one_sync(): # Only one thread per warp does this work
var warp_sum: Float32 = 0.0
var warp_start = (local_i // 32) * 32 # Get warp start index
for i in range(32): # Sum across warp
if warp_start + i < tpb:
warp_sum += shared_data[warp_start + i][0]
shared_data[local_i] = warp_sum
barrier()
# Use cluster_arrive for staged synchronization in sm90+
cluster_arrive()
# Only first thread in each block stores result
if local_i == 0:
var block_total: Float32 = 0.0
for i in range(0, tpb, 32): # Sum warp results
if i < tpb:
block_total += shared_data[i][0]
output[block_id] = block_total
# Wait for all blocks to complete their calculations in sm90+
cluster_wait()
The advanced cluster patterns solution demonstrates a sophisticated three-level hierarchical optimization that combines warp, block, and cluster coordination for maximum GPU utilization:
Level 1: Warp-Level Optimization (Thread Election)
Data preparation and scaling:
var data_scale = Float32(block_id + 1) # Block-specific scaling factor
if global_i < size:
shared_data[local_i] = input[global_i] * data_scale
else:
shared_data[local_i] = 0.0 # Zero-pad for out-of-bounds
barrier() # Ensure all threads complete data loading
Warp-level thread election:
if elect_one_sync(): # Hardware elects exactly 1 thread per warp
var warp_sum: Float32 = 0.0
var warp_start = (local_i // 32) * 32 # Calculate warp boundary
for i in range(32): # Process entire warp's data
if warp_start + i < tpb:
warp_sum += shared_data[warp_start + i][0]
shared_data[local_i] = warp_sum # Store result at elected thread's position
Warp boundary calculation explained:
- Thread 37 (in warp 1):
warp_start = (37 // 32) * 32 = 1 * 32 = 32 - Thread 67 (in warp 2):
warp_start = (67 // 32) * 32 = 2 * 32 = 64 - Thread 199 (in warp 6):
warp_start = (199 // 32) * 32 = 6 * 32 = 192
Election pattern visualization (TPB=256, 8 warps):
Warp 0 (threads 0-31): elect_one_sync() → Thread 0 processes elements 0-31
Warp 1 (threads 32-63): elect_one_sync() → Thread 32 processes elements 32-63
Warp 2 (threads 64-95): elect_one_sync() → Thread 64 processes elements 64-95
Warp 3 (threads 96-127): elect_one_sync() → Thread 96 processes elements 96-127
Warp 4 (threads 128-159):elect_one_sync() → Thread 128 processes elements 128-159
Warp 5 (threads 160-191):elect_one_sync() → Thread 160 processes elements 160-191
Warp 6 (threads 192-223):elect_one_sync() → Thread 192 processes elements 192-223
Warp 7 (threads 224-255):elect_one_sync() → Thread 224 processes elements 224-255
Level 2: Block-level aggregation (Warp Leader Coordination)
Inter-warp synchronization:
barrier() # Ensure all warps complete their elected computations
Warp leader aggregation (Thread 0 only):
if local_i == 0:
var block_total: Float32 = 0.0
for i in range(0, tpb, 32): # Iterate through warp leader positions
if i < tpb:
block_total += shared_data[i][0] # Sum warp results
output[block_id] = block_total
Memory access pattern:
- Thread 0 reads from:
shared_data[0],shared_data[32],shared_data[64],shared_data[96],shared_data[128],shared_data[160],shared_data[192],shared_data[224] - These positions contain the warp sums computed by elected threads
- Result: 8 warp sums → 1 block total
Level 3: Cluster-level staged synchronization
Staged synchronization approach:
cluster_arrive() # Non-blocking: signal this block's completion
# ... Thread 0 computes and stores block result ...
cluster_wait() # Blocking: wait for all blocks to complete
Why staged synchronization?
cluster_arrive()called before final computation allows overlapping work- Block can compute its result while other blocks are still processing
cluster_wait()ensures deterministic completion order- More efficient than
cluster_sync()for independent block computations
Advanced pattern characteristics
Hierarchical computation reduction:
- 256 threads → 8 elected threads (32x reduction per block)
- 8 warp sums → 1 block total (8x reduction per block)
- 4 blocks → staged completion (synchronized termination)
- Total efficiency: 256x reduction in redundant computation per block
Memory access optimization:
- Level 1: Coalesced reads from
input[global_i], scaled writes to shared memory - Level 2: Elected threads perform warp-level aggregation (8 computations vs 256)
- Level 3: Thread 0 performs block-level aggregation (1 computation vs 8)
- Result: Minimized memory bandwidth usage through hierarchical reduction
Synchronization hierarchy:
barrier(): Intra-block thread synchronization (after data loading and warp processing)cluster_arrive(): Inter-block signaling (non-blocking, enables work overlap)cluster_wait(): Inter-block synchronization (blocking, ensures completion order)
Why this is “advanced”:
- Multi-level optimization: Combines warp, block, and cluster programming techniques
- Hardware efficiency: Leverages
elect_one_sync()for optimal warp utilization - Staged coordination: Uses advanced cluster APIs for flexible synchronization
- Production-ready: Demonstrates patterns used in real-world GPU libraries
Real-world performance benefits:
- Reduced memory pressure: Fewer threads accessing shared memory simultaneously
- Better warp utilization: Elected threads perform focused computation
- Scalable coordination: Staged synchronization handles larger cluster sizes
- Algorithm flexibility: Foundation for complex multi-stage processing pipelines
Complexity analysis:
- Warp level: O(32) operations per elected thread = O(256) total per block
- Block level: O(8) aggregation operations per block
- Cluster level: O(1) synchronization overhead per block
- Total: Linear complexity with massive parallelization benefits
The complete GPU hierarchy
Congratulations! By completing this puzzle, you’ve learned the complete GPU programming stack:
✅ Thread-level programming: Individual execution units ✅ Warp-level programming: 32-thread SIMT coordination ✅ Block-level programming: Multi-warp coordination and shared memory ✅ 🆕 Cluster-level programming: Multi-block coordination with SM90+ APIs ✅ Coordinate multiple thread blocks with cluster synchronization primitives ✅ Scale algorithms beyond single-block limitations using cluster APIs ✅ Implement hierarchical algorithms combining warp + block + cluster coordination ✅ Utilize next-generation GPU hardware with SM90+ cluster programming
Real-world applications
The hierarchical coordination patterns from this puzzle are fundamental to:
High-Performance Computing:
- Multi-grid solvers: Different levels handle different resolution grids
- Domain decomposition: Hierarchical coordination across problem subdomains
- Parallel iterative methods: Warp-level local operations, cluster-level global communication
Deep Learning:
- Model parallelism: Different blocks process different model components
- Pipeline parallelism: Staged processing across multiple transformer layers
- Gradient aggregation: Hierarchical reduction across distributed training nodes
Graphics and Visualization:
- Multi-pass rendering: Staged processing for complex visual effects
- Hierarchical culling: Different levels cull at different granularities
- Parallel geometry processing: Coordinated transformation pipelines
Next steps
You’ve now learned the cutting-edge GPU programming techniques available on modern hardware!
Ready for more challenges? Explore other advanced GPU programming topics, revisit performance optimization techniques from Puzzles 30-32, apply profiling methodologies from NVIDIA tools, or build upon these cluster programming patterns for your own computational workloads!