Puzzle 4: 2D Map
Overview
Implement a kernel that adds 10 to each position of 2D square matrix a and
stores it in 2D square matrix output.
Note: You have more threads than positions.
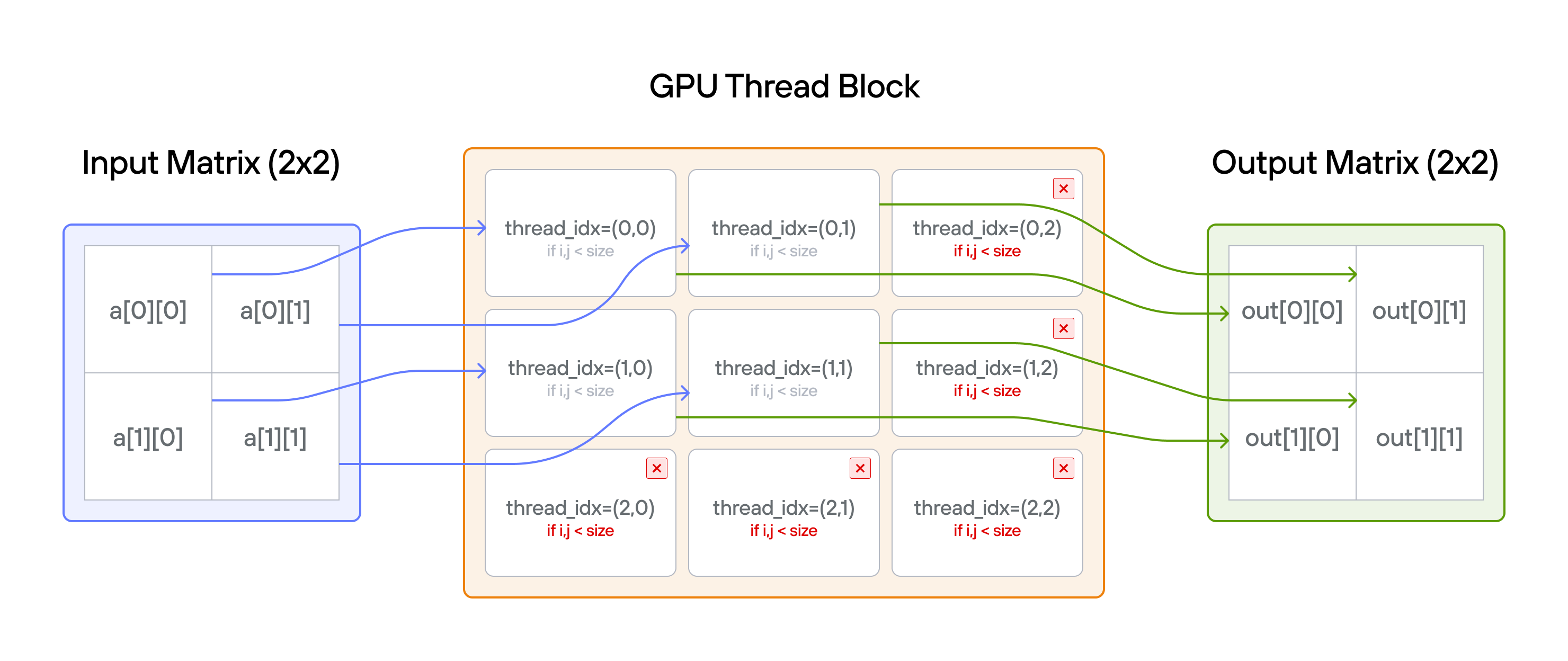
Key concepts
- 2D thread indexing
- Matrix operations on GPU
- Handling excess threads
- Memory layout patterns
For each position \((i,j)\): \[\Large output[i,j] = a[i,j] + 10\]
Thread indexing convention
When working with 2D matrices in GPU programming, we follow a natural mapping between thread indices and matrix coordinates:
thread_idx.ycorresponds to the row indexthread_idx.xcorresponds to the column index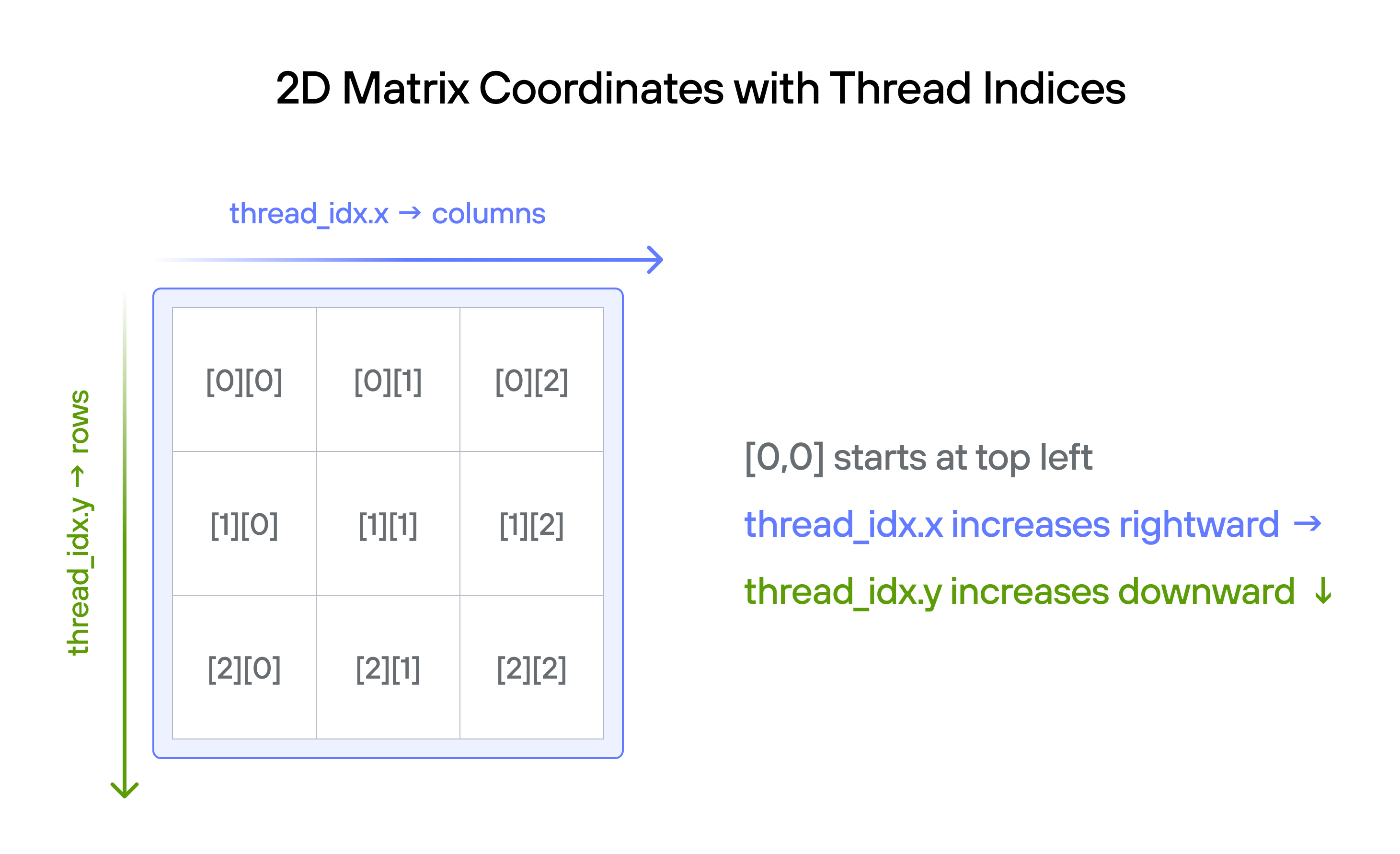
This convention aligns with:
- The standard mathematical notation where matrix positions are specified as (row, column)
- The visual representation of matrices where rows go top-to-bottom (y-axis) and columns go left-to-right (x-axis)
- Common GPU programming patterns where thread blocks are organized in a 2D grid matching the matrix structure
Historical origins
While graphics and image processing typically use \((x,y)\) coordinates, matrix operations in computing have historically used (row, column) indexing. This comes from how early computers stored and processed 2D data: line by line, top to bottom, with each line read left to right. This row-major memory layout proved efficient for both CPUs and GPUs, as it matches how they access memory sequentially. When GPU programming adopted thread blocks for parallel processing, it was natural to map
thread_idx.yto rows andthread_idx.xto columns, maintaining consistency with established matrix indexing conventions.
Implementation approaches
🔰 Raw memory approach
Learn how 2D indexing works with manual memory management.
📚 Learn about TileTensor
Discover a powerful abstraction that simplifies multi-dimensional array operations and memory management on GPU.
🚀 Modern 2D operations
Put TileTensor into practice with natural 2D indexing and automatic bounds checking.
💡 Note: From this puzzle onward, we’ll primarily use TileTensor for cleaner, safer GPU code.