Puzzle 5: Broadcast
Overview
Implement a kernel that broadcast adds 1D TileTensor a and 1D TileTensor b
and stores it in 2D TileTensor output.
Broadcasting in parallel programming refers to the operation where lower-dimensional arrays are automatically expanded to match the shape of higher-dimensional arrays during element-wise operations. Instead of physically replicating data in memory, values are logically repeated across the additional dimensions. For example, adding a 1D vector to each row (or column) of a 2D matrix applies the same vector elements repeatedly without creating multiple copies.
Note: You have more threads than positions.
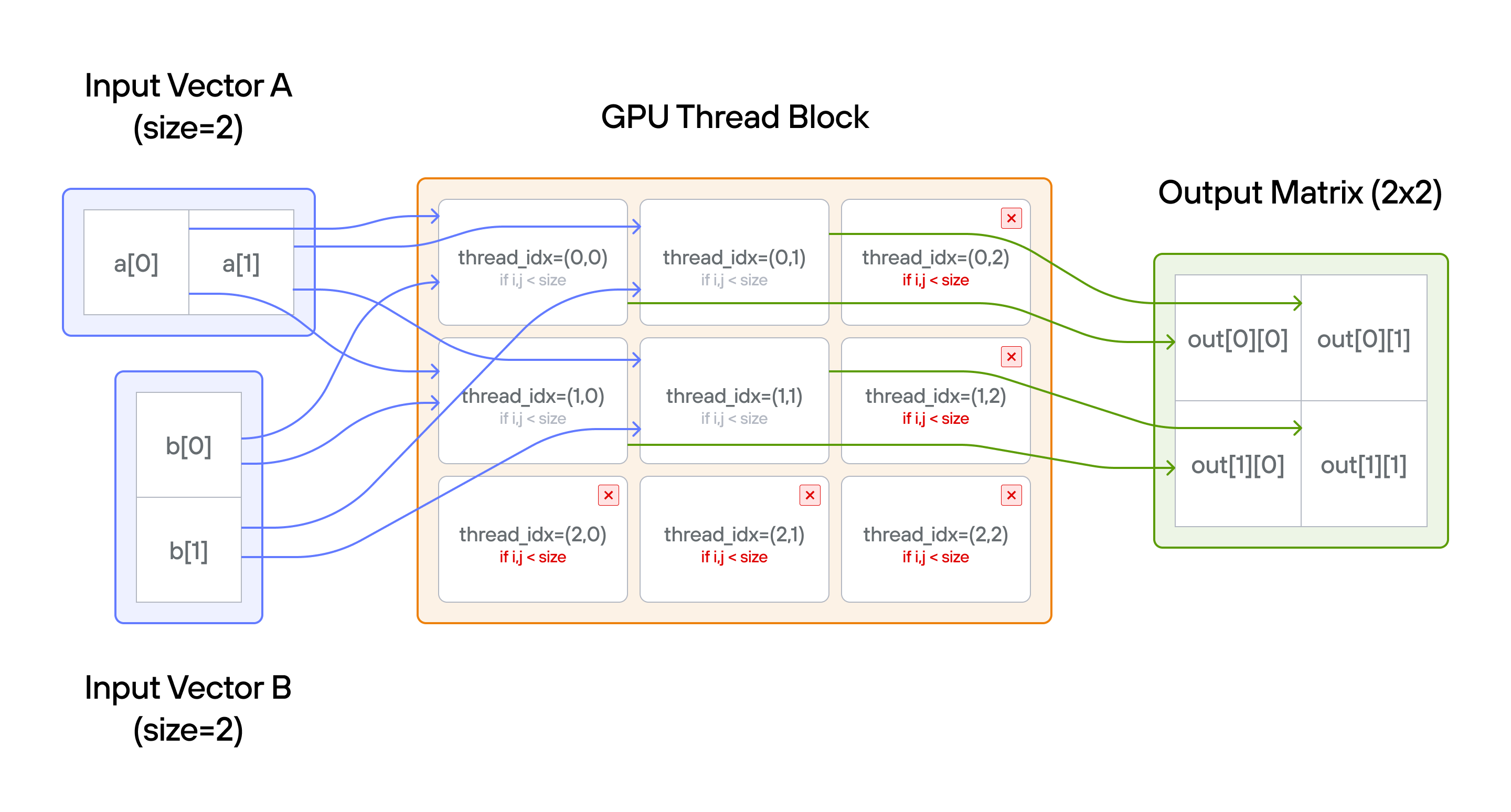
Key concepts
In this puzzle, you’ll learn about:
- Broadcasting 1D vectors across different dimensions with
TileTensor - Using 2D thread indices to map GPU threads to a 2D output matrix
- Working with different tensor shapes for mixed-dimension operations
- Handling boundary conditions in broadcast patterns
The key insight is that TileTensor allows natural broadcasting through
different tensor shapes: \((1, n)\) and \((n, 1)\) to \((n,n)\), while
still requiring bounds checking.
- Tensor shapes: Input vectors have shapes \((1, n)\) and \((n, 1)\)
- Broadcasting: Each element of
acombines with each element ofb; output expands both dimensions to \((n,n)\) - Access patterns:
a[0, col]broadcasts horizontally across rows;b[row, 0]broadcasts vertically across columns - Guard condition: Still need bounds checking for output size
- Thread bounds: More threads \((3 \times 3)\) than tensor elements \((2 \times 2)\)
Code to complete
comptime SIZE = 2
comptime BLOCKS_PER_GRID = 1
comptime THREADS_PER_BLOCK = (3, 3)
comptime dtype = DType.float32
comptime out_layout = row_major[SIZE, SIZE]()
comptime a_layout = row_major[1, SIZE]()
comptime b_layout = row_major[SIZE, 1]()
comptime OutLayout = type_of(out_layout)
comptime ALayout = type_of(a_layout)
comptime BLayout = type_of(b_layout)
def broadcast_add(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, ALayout, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, BLayout, ImmutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
# FILL ME IN (roughly 2 lines)
View full file: problems/p05/p05.mojo
Tips
- Get 2D indices:
row = thread_idx.y,col = thread_idx.x - Add guard:
if row < size and col < size - Inside guard: think about how to broadcast values of
aandbas TileTensors
Running the code
To test your solution, run the following command in your terminal:
pixi run p05
pixi run -e amd p05
pixi run -e apple p05
uv run poe p05
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([1.0, 2.0, 11.0, 12.0])
Solution
def broadcast_add(
output: TileTensor[mut=True, dtype, OutLayout, MutAnyOrigin],
a: TileTensor[mut=False, dtype, ALayout, ImmutAnyOrigin],
b: TileTensor[mut=False, dtype, BLayout, ImmutAnyOrigin],
size: Int,
):
var row = thread_idx.y
var col = thread_idx.x
if row < size and col < size:
output[row, col] = a[0, col] + b[row, 0]
This solution demonstrates key concepts of TileTensor broadcasting and GPU thread mapping:
-
Thread to matrix mapping
- Uses
thread_idx.yfor row access andthread_idx.xfor column access - Natural 2D indexing matches the output matrix structure
- Excess threads (3×3 grid) are handled by bounds checking
- Uses
-
Broadcasting mechanics
- Input
ahas shape(1,n):a[0,col]broadcasts across rows - Input
bhas shape(n,1):b[row,0]broadcasts across columns - Output has shape
(n,n): Each element is sum of corresponding broadcasts
[ a0 a1 ] + [ b0 ] = [ a0+b0 a1+b0 ] [ b1 ] [ a0+b1 a1+b1 ] - Input
-
Bounds Checking
- Guard condition
row < size and col < sizeprevents out-of-bounds access - Handles both matrix bounds and excess threads efficiently
- No need for separate checks for
aandbdue to broadcasting
- Guard condition
This pattern forms the foundation for more complex tensor operations we’ll explore in later puzzles.