Puzzle 6: Blocks
Overview
Implement a kernel that adds 10 to each position of vector a and stores it in
output.
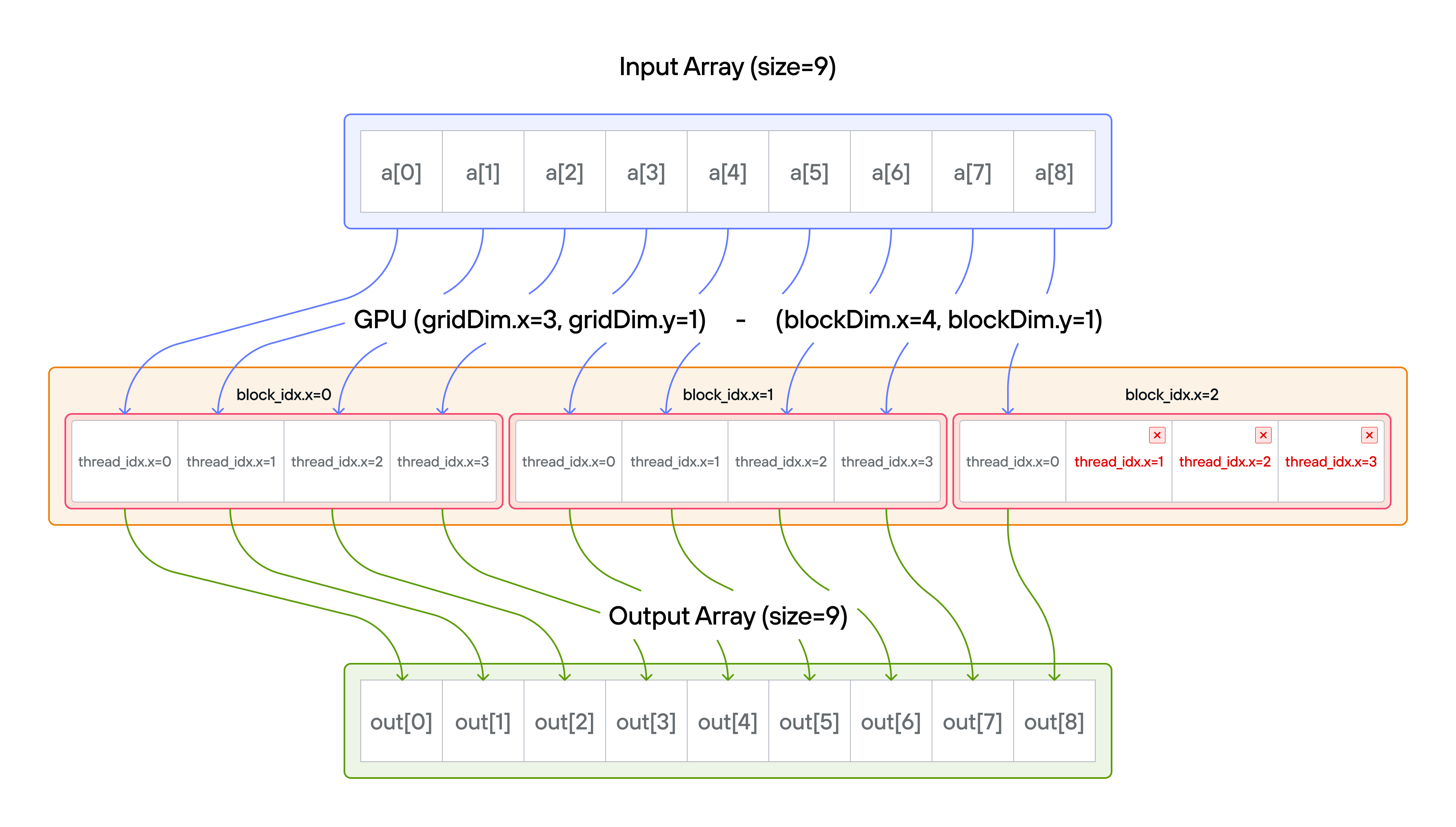
A thread block (or just block) is a group of threads that execute
together on a single GPU multiprocessor. All threads in a block share the same
shared memory and can synchronize with each other. When data is larger than one
block can handle, the GPU schedules multiple blocks — each block independently
processes its portion of the data. The global position of a thread is computed
from both its position within the block (thread_idx.x) and which block it
belongs to (block_idx.x):
global_i = block_dim.x * block_idx.x + thread_idx.x.
Note: You have fewer threads per block than the size of a.
Key concepts
This puzzle covers:
- Processing data larger than thread block size
- Coordinating multiple blocks of threads
- Computing global thread positions
The key insight is understanding how blocks of threads work together to process data that’s larger than a single block’s capacity, while maintaining correct element-to-thread mapping.
Code to complete
comptime SIZE = 9
comptime BLOCKS_PER_GRID = (3, 1)
comptime THREADS_PER_BLOCK = (4, 1)
comptime dtype = DType.float32
def add_10_blocks(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
size: Int,
):
var i = block_dim.x * block_idx.x + thread_idx.x
# FILL ME IN (roughly 2 lines)
View full file: problems/p06/p06.mojo
Note: The
TileTensorvariant of this puzzle is very similar so we leave it to the reader.
Tips
- Calculate global index:
i = block_dim.x * block_idx.x + thread_idx.x - Add guard:
if i < size - Inside guard:
output[i] = a[i] + 10.0
Running the code
To test your solution, run the following command in your terminal:
pixi run p06
pixi run -e amd p06
pixi run -e apple p06
uv run poe p06
Your output will look like this if the puzzle isn’t solved yet:
out: HostBuffer([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
expected: HostBuffer([10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0, 17.0, 18.0])
Solution
def add_10_blocks(
output: UnsafePointer[Scalar[dtype], MutAnyOrigin],
a: UnsafePointer[Scalar[dtype], MutAnyOrigin],
size: Int,
):
var i = block_dim.x * block_idx.x + thread_idx.x
if i < size:
output[i] = a[i] + 10.0
This solution covers key concepts of block-based GPU processing:
-
Global thread indexing
-
Combines block and thread indices:
block_dim.x * block_idx.x + thread_idx.x -
Maps each thread to a unique global position
-
Example for 3 threads per block:
Block 0: [0 1 2] Block 1: [3 4 5] Block 2: [6 7 8]
-
-
Block coordination
-
Each block processes a contiguous chunk of data
-
Block size (3) < Data size (9) requires multiple blocks
-
Automatic work distribution across blocks:
Data: [0 1 2 3 4 5 6 7 8] Block 0: [0 1 2] Block 1: [3 4 5] Block 2: [6 7 8]
-
-
Bounds checking
- Guard condition
i < sizehandles edge cases - Prevents out-of-bounds access when size isn’t perfectly divisible by block size
- Essential for handling partial blocks at the end of data
- Guard condition
-
Memory access pattern
- Coalesced memory access: threads in a block access contiguous memory
- Each thread processes one element:
output[i] = a[i] + 10.0 - Block-level parallelism provides efficient memory bandwidth utilization
This pattern forms the foundation for processing large datasets that exceed the size of a single thread block.